この記事は Docker Advent Calendar 2017 の1日目の記事です。
こんにちは。Emotion Techの子安です。すっかり冬ですね。今日は夜の銀座からお送りします。

なんでもDockerで
Dockerに触れるようになって約2年ほど経ちました。最近は技術検証はもちろん、何かをちょっと試したいときなども、新しい環境が必要になるとまずはDockerで構築してみることが当たり前に(自分的には)なってきています。
で、今回はWebからちょこっと何か取ってきたいとき、いわゆるスクレイピングをしたいとき、Dockerがあれば簡単に環境が作れるぞという話をします。
※なお、スクレイピングは用法・用量を守って正しく行いましょう。あくまで自己責任でお願いしますね。
要件
- とあるサイトから情報を抜き出したい
- ブラウザを操作してサイトを巡回する
- Docker上に構築する
- プログラミング言語は問わない(やっぱりSeleniumが分かりやすいんじゃないだろうか)
PhantomJS
ヘッドレスブラウザと言えば PhantomJS ですよね。だからSeleniumとPhantomJSをインストールしたイメージを作って・・・と考えていたとき。
「やあ、みんな。Headless Chromeてのがそろそろ来るぜ。みんなそれを使うことになると思うんだ。Chromeは速いし安定しているからね。 〜(略)〜 というわけで、メンテナを下りることにした。今までありがとう。」
え、PhantomJSってオワなの!? がーん。しかもアナウンスは今年の春・・・(私のブラウザスキルが露呈してしまう・・・)。やはり時代はChromeなんですかね。
selenium/standalone-chrome
ではオススメに従ってChromeを使いましょう。Chromeの公式イメージがあると最高なんですが、調べた限りでは見つけられませんでした。自分でインストールするのは結構面倒だなあ、どうしたものかと悩みつつDocker Hubを徘徊していたところ、Seleniumの方の公式イメージ selenium/standalone-chrome を発見しました。これだ。これを使いましょう。
コンテナの中を見る
まずは、selenium/standalone-chromeのコンテナがどうなっているか確認しておきます。Dockerfileを見ても良いんですが、今回は手っ取り早く、実際起動したときにどんなプロセスが動くのかを見ることにします。
docker run -d --name selenium selenium/standalone-chrome
docker exec selenium ps auxfwww
docker rm --force selenium
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
seluser 45 0.0 0.0 34424 2784 ? Rs 05:02 0:00 ps auxfwww
seluser 1 1.5 0.0 18044 3008 ? Ss 05:02 0:00 /bin/bash /opt/bin/entry_point.sh
seluser 12 0.0 0.0 4508 1628 ? S 05:02 0:00 /bin/sh /usr/bin/xvfb-run -n 99 --server-args=-screen 0 1360x1020x24 -ac +extension RANDR java -jar /opt/selenium/selenium-server-standalone.jar
seluser 23 2.0 0.8 219572 35428 ? Sl 05:02 0:00 \_ Xvfb :99 -screen 0 1360x1020x24 -ac +extension RANDR -nolisten tcp -auth /tmp/xvfb-run.BvpE6L/Xauthority
seluser 30 115 1.5 3363500 60716 ? Sl 05:02 0:01 \_ java -jar /opt/selenium/selenium-server-standalone.jar
なるほど、selenium-standaloneサーバーを上げて(イメージ名のstandaloneってのはそういう意味ですね)、そこからChromeにつなぎに行くみたいですね。そしてChromeはXvfb上で動くようになっていると。ではこれでやってみましょう。
コード
以降のコードは、すべてGitHubにあります。実際のコードを参照したり動かしたりされる場合は、下記リポジトリをcloneしてください。
コンテナの構成
スクレイピングのコードを実行する環境とブラウザを起動する環境を分けておくと、後で使いまわしが利きそうなので、今回はこういう感じのコンテナを立てることにします。
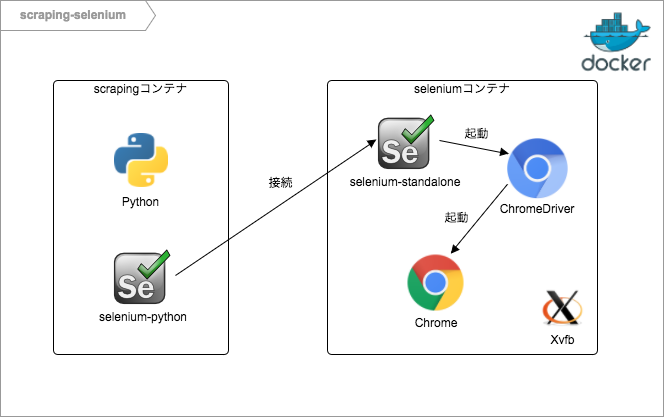
seleniumコンテナはselenium/standalone-chromeイメージをそのまま使います。scrapingコンテナの方は、Seleniumさえ動けば言語はなんでも良いので、Alpineのpython3イメージにselenium-pythonをインストールしましょう。
2つのコンテナを使うことになるので、docker-composeで立ち上げます。
version: "2.2"
services:
selenium:
image: selenium/standalone-chrome
volumes:
- /dev/shm:/dev/shm
scraping:
image: docker-scraping
build: ./build/scraping
volumes:
- .:/var/lib/python3
entrypoint:
- docker-entrypoint.sh
depends_on:
- selenium
注意点としては、ブラウズするページにもよるのでしょうが、デフォルトだと共有メモリが足りなくなることがある点ですね。共有メモリが足りなくなるとChromeがCrashメッセージを吐いて落ちます。shm_sizeを設定して割り当てを増やすか、ホスト側の/dev/shmをマウントしておくと良いと思います。
selenium-standaloneサーバーに接続してURLを開くコード(Python)はこちら。
from selenium import webdriver
from selenium.webdriver import DesiredCapabilities
if __name__ == '__main__':
driver = webdriver.Remote(command_executor='http://selenium:4444/wd/hub',
desired_capabilities=DesiredCapabilities.CHROME.copy())
try:
driver.get('https://qiita.com/advent-calendar/2017/docker')
print('title:', driver.title)
print('text:', driver.find_element_by_css_selector('article').text)
finally:
driver.quit()
driver.quit() を忘れずに! 忘れるとChromeのプロセスが終了しないので、繰り返し実行していると早晩リソースを食いつぶしてしまいます。
やってみる
docker-compose run --rm scraping app/scraping/by_selenium.py
title: Docker Advent Calendar 2017 - Qiita
text: Docker、もしくはその周辺技術に関することなら何でも。
うまく行きました。
これでひとまず、当初の目的は達成できたと言えます。docker-compose.ymlを用意して2つのコンテナを起動するだけで、スクレイピングできるようになりました。
Headless Chrome
先ほどコンテナの中を見たときにわかったように、selenium/standalone-chromeには今回の要求を満たす上では無くてよいものが2つ含まれています。1つはXvfb、もう1つはselenium-standaloneサーバーです。XvfbはHeadlessモードを使うなら必要ありませんし、selenium-standaloneサーバーはChromeDriverに直接接続すれば必要ありません。
コンテナの構成
不要なものを取り除くとこんなコンテナになるはずです。
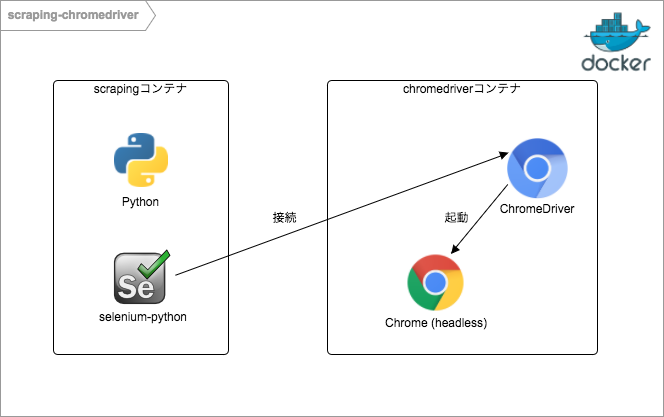
やってみましょう。さきほど面倒がってやらなかったChromeのインストールについては、 jess/chrome というイメージを使わせてもらうことにします。そのイメージにChromeDriverを追加すれば、chromedriverコンテナが出来上がります。
version: "2.2"
services:
chromedriver:
image: chromedriver
build: ./build/chromedriver
init: true
command:
- chromedriver
- --whitelisted-ips
volumes:
- /dev/shm:/dev/shm
scraping:
image: docker-scraping
build: ./build/scraping
volumes:
- .:/var/lib/python3
entrypoint:
- docker-entrypoint.sh
depends_on:
- chromedriver
shmについては先ほどと同様です。またChromeDriverはデフォルトでlocalhostからの接続のみ受け付けますので、 --whitelisted-ips オプションを値なしで渡して、他のホストからの接続を受け付けるように設定します。 init: true については、ChromeDriverから起動したChromeのプロセスがゾンビ化してしまうのを防ぐために設定しています。(根本的な原因は解明できてないのですが)
ChromeDriverに接続してURLを開くコード(Python)はこちら。
from selenium import webdriver
if __name__ == '__main__':
options = webdriver.ChromeOptions()
options.binary_location = '/usr/bin/google-chrome'
options.add_argument('--no-sandbox')
options.add_argument('--headless')
options.add_argument('--disable-gpu')
capabilities = options.to_capabilities()
driver = webdriver.Remote(command_executor='http://chromedriver:9515', desired_capabilities=capabilities)
try:
driver.get('https://qiita.com/advent-calendar/2017/docker')
print('title:', driver.title)
print('text:', driver.find_element_by_css_selector('article').text)
finally:
driver.quit()
chromeOptionsに --no-sandbox --headless --disable-gpu を追加します。( --no-sandboxをしない場合、docker-compose.yml側でchromedriverコンテナの security_opt: を調整するか、cap_add: で SYS_ADMIN する必要があります。) driver.quit() を忘れてはいけないのは先ほどと同様です。
やってみる
docker-compose run --rm scraping app/scraping/by_chromedriver.py
title: Docker Advent Calendar 2017 - Qiita
text: Docker、もしくはその周辺技術に関することなら何でも。
うまく行きました。あとはスクレイピングのためのコードを書くだけです。
まとめ
というわけで、docker-compose.ymlからコンテナを起動して、Seleniumコードを書けばスクレイピング出来るようになりました。副産物(?)としてChromeDriverから(Headless) Chromeを起動するコンテナを作ることもできました。スクレイピングに限らず、SeleniumからChromeを起動したいときには、このイメージをポータブルに使えそうです。
従来はディスプレイの無い環境でブラウザを起動しようとする(例えばCIでブラウザテストをするとか)と、まずXvfbを起動して・・・といったいくつかの手順が必要でしたが、Headless Chromeの登場でそこを省略して簡単に起動できるようになったことは大きいですね。
ありがとうございました。それでは、よいクリスマスを。
今回のコード
検証した環境
- OS: macOS High Sierra
- Docker: 17.06.0-ce-mac19
ChromeDriver on Docker
ChromeDriverから(Headless) Chromeを起動するコンテナイメージをPushしておきました。
https://hub.docker.com/r/akirakoyasu/chromedriver/