ChatGPT,使っていますか?
ChatGPTは文章を要約したり、プログラム作ってくれたり、一緒にブレストしてくれたりして本当に便利なのですが、社内情報などの独自データに関する情報については回答してくれません。
プロンプトに情報を記述して、そこに書かれている情報から回答してもらう方法もありますが、最大トークン4000の壁がありますので、限界があるかと思います。
この課題についてなんとかならないかと考えて色々と調べて見たところ、解決する方法が見つかり、いろいろと検証をして見ましたのでその結果をシェアしたいと思います。
サンプルコード(GoogleColab)
百聞は一見にしかずということで、実際に試したサンプルは以下にありますので、まずは動かしてみることをお勧めします。
このコードを上から順番に動かすと、実際にインターネット上から取得したPDFファイルに関する内容をChatGPTが回答してくれるということを確認することができます。
実際に動かすためには、3番目のダイアログにOpenAIのAPI_KEYを登録する必要があることだけご注意ください。
(以下のコードをコピーして動かせばキーが外部に漏れることはないはずです)
全体の構成
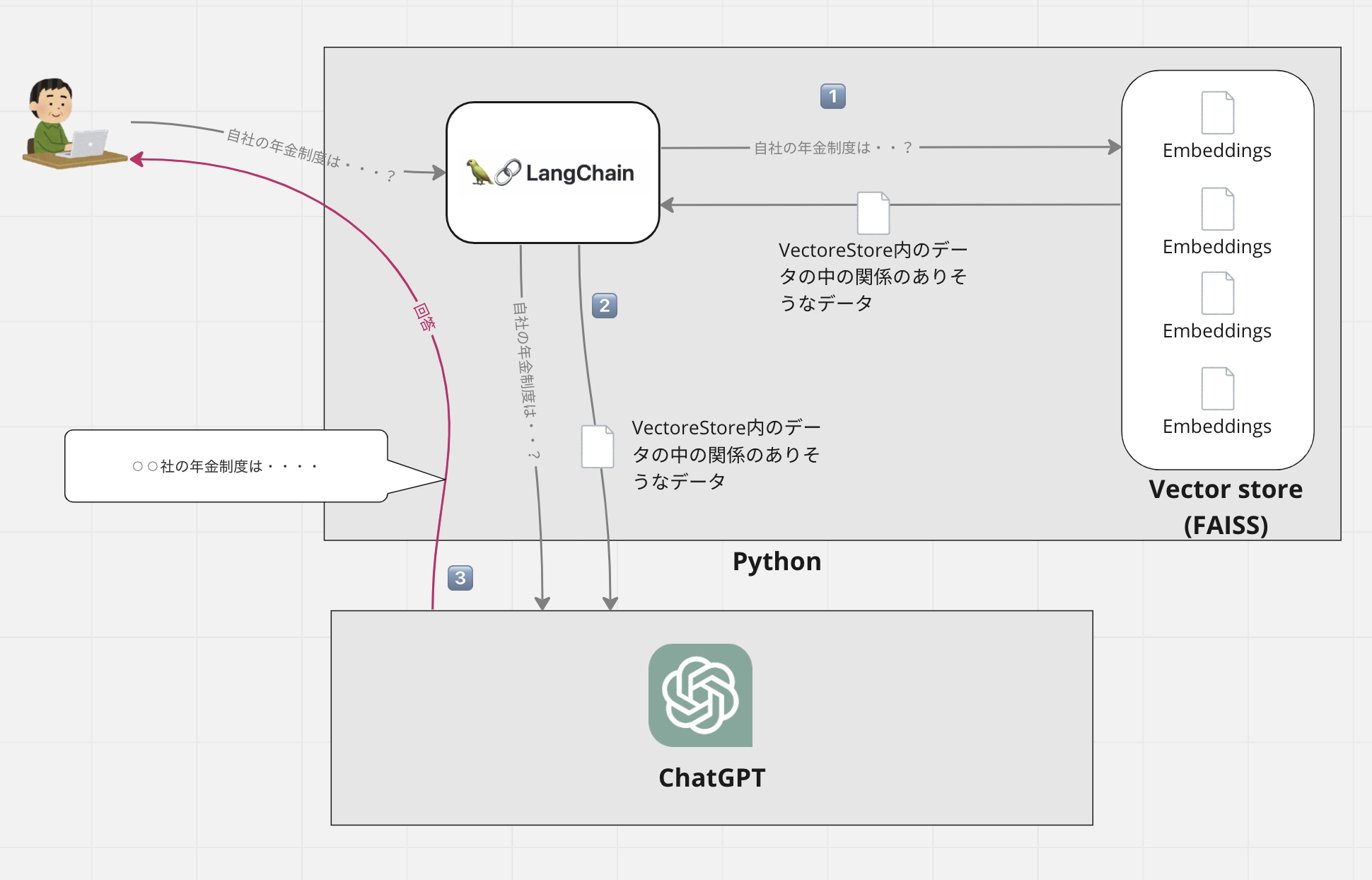
この仕組みはあらかじめVectoreStoreに検索に利用したい独自データを登録しておき、検索時はlangchainというライブラリを使って、ユーザからの質問に該当しそうな情報を独自データベースから取り出し、その情報と一緒にChatGPTに渡して回答を得るといった流れとなります。
それでは、データ保管時と検索時を別々に見ていきましょう。
データ保管時
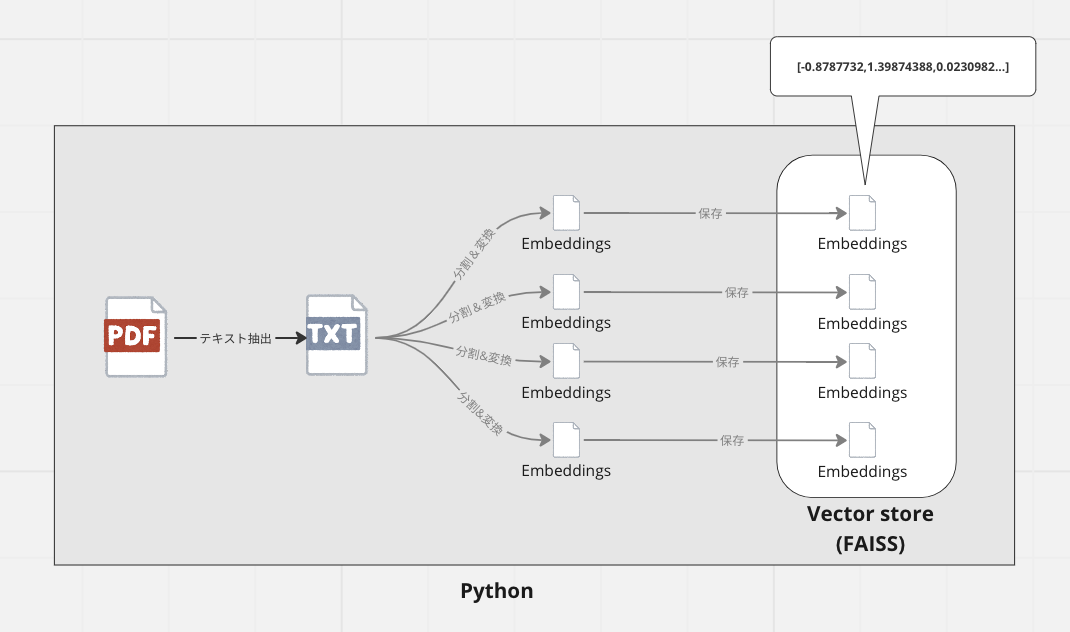
ChatGPTに全てのデータを渡すことはできないので、独自情報をVectorStoreというデータベースに保管します。
VectorStoreとは、AIで利用しやすい様に、データを文字列としてではなく、言葉の意味を数値で示したEmbeddingsと呼ばれるベクター形式のデータで保管するデータベースのことを指します。
今回はFaceBook(メタ)社が作ったFAISSを使います。
今回は独自の情報を持ったPDFドキュメントを登録する前提で話を進めます。
データを保管する際は、そのままのテキストデータを保管するのではなく、後でAIが必要なデータを検索しやすい様な形式にデータを分割・変換して保管します。
具体的にはEmbedding形式という、文章の意味を数値で表した形式で、こうしておくことにより、ユーザからの指示に関連しそうなデータを高速に抽出することが可能となります。
概念図
図にするとこんな感じです。
コード
データをチャンクに分割するコードはこのあたりです。
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 512,
chunk_overlap = 24,
length_function = count_tokens,
)
chunks2 = text_splitter.create_documents([text])
チャンクのサイズとチャンク同士のオーバラップする量を指定することができます。
このサイズは大きくしたりもしてみましたが、1000などにすると後のデータ検索時にChatGPTのトークンサイズ(4000)を超えてしまってエラーになったりすることが頻発したので、これくらいのサイズがちょうど良いのかもしれません。
以下で分割したチャンクをVectoreStoreに保管しています。
この例では、PDFファイルを2つと、インターネット上の情報を1つの合計3つのデータを登録しているため、chunkが3つあります。
# Get embedding model
embeddings = OpenAIEmbeddings()
# vector databaseの作成
db = FAISS.from_documents(chunks+chunks2+chunks3, embeddings)
データ検索時
次にデータ検索です。
これまでの手順でVectoreStoreに独自情報が保管されていますので、ユーザが入力してきた問い合わせに対して関係のありそうなデータを取得し、得られた情報と問い合わせ情報を合わせてChatGPTに回答させるということをやっています。
概念図
図にするとこんな感じです。
Langchain
これを実現するために、Langchainというライブラリを利用します。
このライブラリを利用することで、今回行う様なVectorStoreの情報を利用するだけでなく、Google検索やAPI検索、DB検索なども行ってそこにあるデータを使ってChatGPTに回答させるといったことができるそうです。(とマニュアルに書いてある)
今回はPython版を利用していますが、Javascript版も提供されているため、環境に合わせて使い分けることができそうです。ただ、現時点ではPython版の方が機能やドキュメントがやや充実している感じがします。インターネット上に公開されているサンプルコードもほとんどがPython版となっていますので、現時点ではPython版の方が良さそうです。
VectoreStoreを検索
試しに、このコードを実行すると、下記にある様なレスポンスが返ってきます。
これは単にPDFファイルに含まれていた文言をそのまま返してきているだけですが、関係ありそうなテキスト情報であることが確認できると思います。
query = "ランプが点滅しているが、これは何が原因か?"
docs = db.similarity_search(query)
docs # ここで関係のありそうなデータが返ってきていることを確認できる
レスポンス
[Document(page_content='電源ランプが点滅したまま点灯に変わらない\n1 電源ボタンを約3秒間長押しして、 本製品の電源をOFFにします。\n2 ファンクションボタンを押したまま、 電源ボタンを押します。 電源ボタンを放した後も、 ファンクション\nボタンは約10秒間押し続けてください。\n3 電源ランプが点滅から点灯に変わったら、 NAS Navigator2で本製品を検索し、 設定画面を開きます。.....
LangChainを使ってChatGPTに検索
今度はlangchainを使って検索を行います。先ほどの検索結果とユーザから受け取ったqueryを渡してChatGPTに回答をさせます。
# langchainをロードする。
chain = load_qa_chain(OpenAI(temperature=0.2,max_tokens=1000), chain_type="stuff")
query = "ランプが点滅しているが、これは何が原因か?"
# VectoreStoreを検索
docs = db.similarity_search(query)
# VectoreStoreの検索結果とqueryを渡してChatGPTに回答させる
chain.run(input_documents=docs, question=query)
返ってきた結果がこちらです。
故障したドライブの電源がONの状態です。ドライブを抜かないでください。
VectoreStoreの検索結果に以下の様にありますので、回答結果は正しそうです。大量(300ページ以上)のPDFファイルから必要な情報を得ることができました。

まとめ
今回は一つのプログラムでロードと検索を行いましたが、この方法を使えば1つのPDFだけではなくもっと多くのドキュメントを登録しておくことができます。
VectoreStoreの検索精度に依存はしてしまいますが、普通に文字列検索するよりも効率的に関連情報が抽出できそうです。
input_documentsに登録する情報を変えることで、DBやAPIから取得するデータをもとに返答を返すことも確かにできそうだという感触を掴むことができました。
このプログラムをWebサーバ上で動かしてクライアントサイドのプログラムからのクエリに対して回答する様にするなど、応用をすれば活用の案は色々と考えられるかと思います。
ChatGPTはチャット以外にも活用方法はたくさんありそうですので、色々と情報を調べて活用していきましょう!
5/10 追記:
ChatGPT+LangChainを使った新たな検証記事をアップしました。