第1章 事象と確率
1. 事象と確率
-
確率:試行によって起こりうるすべての結果を標本空間 $\Omega$ と定義し、$\Omega$ の部分集合から区間 [0,1] 上の実数への関数 $P$ を確率とみなす。
- 次の性質を満たす:
- $A \subset \Omega \Rightarrow P(A) \geq 0$
- $P(\Omega) = 1$
- $A_1$ と $A_2$ が排反ならば $P(A_1 \cup A_2) = P(A_1) + P(A_2)$
- 次の性質を満たす:
2. 条件付き確率とベイズの定理
- 条件付き確率:2つの事象 $A$ と $B$ があって、$P(B) > 0$ のとき、
$$
P(A|B) = \frac{P(A \cap B)}{P(B)}
$$
を$B$を与えたときの$A$の条件付き確率と呼ぶ。
- ベイズの定理:$B_1, ..., B_n$ を互いに排反な事象で、$P(B_k) > 0$、かつ $\bigcup_{k=1}^{n} B_k = \Omega$ を満たすとき、事象 $A$ に対して、$B_j$ の条件付き確率は
$$
P(B_j|A) = \frac{P(A|B_j)P(B_j)}{\sum_{i=1}^{n} P(A|B_i)P(B_i)}
$$
このとき、$P(A)$ を事前確率、$P(B_j|A)$ を事後確率とよぶ。
3. 確率変数と確率関数
-
確率変数:$\Omega$ を確率が定義されている標本空間とするとき、$\Omega$ から実数 $R$ への関数 $X$ を確率変数とよぶ。通常は $X$ と書く。
-
確率関数:確率変数 $X$ をとる範囲を $\chi$ とし、このとき $X$ 上に定義された確率を確率関数という。
4. 期待値と分散
- 期待値:確率変数 $X$ とその確率関数 $p(x)$ において $X$ の期待値は次の式で定義される。
$$
E[X] = \sum_{x} x p(x) = \mu
$$
- 分散:$X$ の分散は次の式で定義される。
$$
V[X] = E[(X-\mu)^2] = \sum_{x} (x-\mu)^2 p(x)
$$
- 分散の公式:分散の式を変形すると、以下の式が導出できる。
$$
V[X] = E[X^2] - E[X]^2
$$
- 連続確率変数:確率変数 $X$ が連続である場合、確率密度関数 $f(x)$ を次のように定義する。
$$
f(x) = \lim_{\epsilon \to 0} \frac{P(x-\epsilon < X \leq x+\epsilon)}{\epsilon}
$$
- 期待値と分散:連続確率変数 $X$ の期待値と分散は次の式で定義される。
$$
E[X] = \int_{-\infty}^{\infty} x f(x) , dx
$$
$$
V[X] = \int_{-\infty}^{\infty} (x-\mu)^2 f(x) , dx
$$
第2章 確率分布と母関数
1. 累積分布関数
-
累積分布関数:確率変数 $X$ の累積分布関数は $F(x) = P(X \leq x)$ と書く。
- これは $x_i \leq x$ を満たす、すべての $x$ について $P(x_i)$ を足し合わせたもの。
$$
F(x) = \sum_{x_i \leq x} P(x_i)
$$
- 連続確率変数:連続確率変数の場合、累積分布関数 $F(x_i)$ は次の式で定義される。
$$
F(x) = \int_{-\infty}^{x} f(x_i) , dx_i
$$
2. 生存関数
- 生存関数:生存時間を $t$ としたとき、$T$ 以上である確率を表すのが生存関数で、次の式で定義される。
$$
S(t) = P(T \geq t) = \int_{t}^{\infty} f(x) , dx
$$
3. ハザード関数
- ハザード関数:生存時間 $T$ において、ある時刻 $t$ まで生存した個体が、その後の微小時間 $\Delta t$ の間に死亡する条件付き確率がハザード関数 $h(t)$。
$$
h(t) = \lim_{\Delta t \to 0} \frac{P(t \leq T < t+\Delta t | T \geq t)}{\Delta t}
$$
- ハザード関数を確率密度関数と生存関数で表す:
$$
h(t) = \frac{f(t)}{S(t)} = -\frac{d}{dt} \log S(t)
$$
- 導出:
-
条件付き確率の定義により、
$$
P(t \leq T < t+\Delta t | T \geq t) = \frac{P(t \leq T < t+\Delta t \cap T \geq t)}{P(T \geq t)}
$$$$
= \frac{P(t \leq T < t+\Delta t)}{P(T \geq t)} = \frac{F(t+\Delta t) - F(t)}{S(t)}
$$$$
P(t \leq T)\text{:累積分布関数}
$$$$
P(T \geq t)\text{:生存関数}
$$よって、
$$
h(t) = \lim_{\Delta t \to 0} \frac{P(t \leq T < t+\Delta t | T \geq t)}{\Delta t} = \lim_{\Delta t \to 0} \frac{F(t+\Delta t) - F(t)}{\Delta t S(t)} = \frac{f(t)}{S(t)}
$$ -
生存関数 $S(t)$ の対数微分をとると、
$$
\frac{d}{dt} \log S(t) = \frac{1}{S(t)} \frac{dS(t)}{dt}
$$したがって、
$$
h(t) = -\frac{d}{dt} \log S(t)
$$
4. 同時確率関数と条件付き確率密度関数
-
同時確率関数:
- 2つの確率変数 $X,Y$ について、$X=x$ かつ $Y=y$ となる同時確率関数を以下のように定義する。
$$
p(x,y) = P(X=x,Y=y)
$$
- 右辺の式は以下を意味する
$$
P(X=x, Y=y) = P(X=x \cap Y=y)
$$
-
周辺確率関数:
- 周辺確率関数 $P_X(x)$ は、全ての $y$ についての $P(x,y)$ の和を取ることで求められる。($y$を消去する)
$$
P_X(x) = \sum_y P(x, y)
$$
-
条件付き確率関数:
- $X = x$ が与えられたときの $Y$ の条件付き確率関数は以下のように定義される。
$$
P_{Y|X}(y|x) = \frac{P(x, y)}{P_X(x)}
$$
-
連続確率変数の場合:
- 同時確率密度関数は、範囲 $x_1 \leq X \leq x_2, y_1 \leq Y \leq y_2$ において以下のようになる。
$$
P(x_1 \leq X \leq x_2, y_1 \leq Y \leq y_2) = \int_{x_1}^{x_2} \int_{y_1}^{y_2} f(x,y) , dx , dy
$$
- $X$ に関する周辺確率密度関数 $f_X(x)$ は次のように定義される。
$$
f_X(x) = \int_{-\infty}^\infty f(x, y) , dy
$$
- $X=x$ で与えられたときの $Y$ の条件付き確率密度関数 $f_{Y|X}(y|x)$ は以下のように定義される。
$$
f_{Y|X}(y|x) = \frac{f(x, y)}{f_X(x)}
$$
第3章 分布の特性値
1. 同時分布の特性値
- 共分散:2つの確率変数 $X$, $Y$ の間の関係性を示す指標であり、次の式で定義される。
$$
\mathrm{Cov}[X, Y] = E[(X - E[X])(Y - E[Y])]
$$
- 公式:上記の定義を頑張って計算すると以下が導出できる。
$$
\mathrm{Cov}[X, Y] = E[XY] - E[X]E[Y]
$$
- 相関係数:各確率変数を標準化して計算したものを相関係数といい、次の式で定義される。
$$
\rho_{X,Y} = \frac{\mathrm{Cov}[X, Y]}{\sigma_X \sigma_Y}
$$
2. 条件付き特性値
- 条件付き期待値:$X$ が与えられたときの $Y$ の条件付き期待値は次の式で定義される。
$$
E[Y|X] = \int_{-\infty}^{\infty} y f_{Y|X}(y|x) , dy
$$
- 条件付き分散:$X$ が与えられたときの $Y$ の条件付き分散は次の式で定義される。
$$
V[Y|X] = E[Y^2|X] - (E[Y|X])^2
$$
3. 期待値と分散の性質
- 期待値の性質:確率変数 $X$, $Y$ と定数 $a$, $b$, $c$ について
$$
E[aX + bY + c] = aE[X] + bE[Y] + c
$$
- 分散の性質:確率変数 $X$, $Y$ と定数 $a$, $b$ について
$$
V[X + Y] = V[X] + V[Y] + \mathrm{Cov}[X, Y] \text{(独立なら共分散=0)}
$$
- 条件付き期待値の性質:確率変数 $X$, $Y$ について
$$
E[E[X|Y]] = E[X]
$$
- 条件付き分散:確率変数 $X$, $Y$ について
$$
V[X] = E[V[X|Y]] + V[E[X|Y]]
$$
第4章 変数変換
1. 重積分の変数変換
- 1次元の場合:1変数関数の積分では変数変換 = 置換積分。$t_1, t_2$ を $x(t)$ がそれぞれ $x_1, x_2$ になる $t$ の値とし、$x = x(t)$ と変数変換すると、以下のように表せる。
$$
\int_{x_1}^{x_2} f(x) , dx = \int_{t_1}^{t_2} f(x(t)) x'(t) , dt
$$
座標が変換された伸縮率を調整するために $x'(t)$ が必要。
- 2次元の場合:$x, y$ から新しい座標 $u, v$ に移ることを考える。ここで新しい座標系が $x, y$ と $u, v$ の関係を以下のように表せるとする。
$$
\Phi(u, v) = (x(u, v), y(u, v))
$$
このとき、$x, y$ でみた時の積分領域 $D$ が、$u, v$ では $E$ になるとする。また、変数変換をしたものを $g(u, v)$ と表す。
$$
g(u, v) = f(x(u, v), y(u, v))
$$
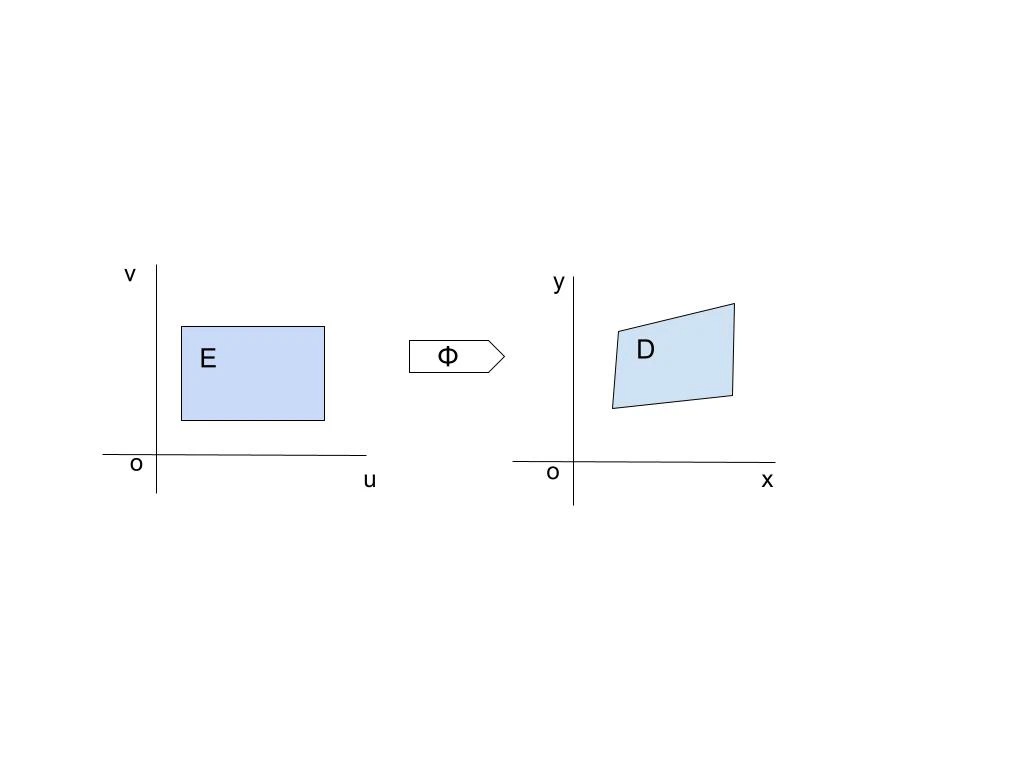
このとき、重積分
$$
\iint_D f(x, y) , dx , dy
$$
は、ヤコビアンを用いて $u, v$ での重積分として、以下のように表せる。
$$
\iint_D f(x, y) , dx , dy = \iint_E f(x(u, v), y(u, v)) |J(u, v)| , du , dv = \iint_E g(u, v) |J(u, v)| , du , dv
$$
ヤコビアンと呼ばれる関数 $J(u, v)$ は以下の行列式で表す:
$$
J(u, v) \equiv \frac{\partial (x, y)}{\partial (u, v)} = \det \begin{vmatrix}
\frac{\partial x}{\partial u} & \frac{\partial x}{\partial v} \
\frac{\partial y}{\partial u} & \frac{\partial y}{\partial v}
\end{vmatrix}
$$
💡行列式の役割は体積拡大率を表すもので、ヤコビアン行列は変換することで比率が変化した面積(体積)の倍率調整の役割を果たす。
2. データの変換
-
対数変換:対数変換(Logarithmic Transformation)は、データの分布を正規化したり、外れ値の影響を軽減したりするために使用される。特に、右に歪んだ(右裾が長い)データ分布に適用されます。
- 数式
通常の対数変換は次の式で行う: $y = \log(x)$ - 条件
- $x > 0$、データが正である必要がある
- 数式
-
Box-Cox変換: Box-Cox変換(Box-Cox Transformation)は、データの分布を正規化するために使われます。対数変換の一般化バージョンであり、対数変換を含む様々な変換を行います。
- 数式
$$
y(\lambda) = \begin{cases}
\frac{x^{\lambda} - 1}{\lambda} & \text{ if } \lambda \neq 0 \
\log(x) & \text{ if } \lambda = 0
\end{cases}
$$
- 条件
- $x > 0$: データが正である必要がある
※ロジット、プロビット変換は第18章で記載する。
参考文献
- 日本統計学会公式認定 統計検定準1級対応 統計学実践ワークブック
- データ解析のための数理統計入門 (著者:久保川 達也)
- 数研講座シリーズ 大学教養 微分積分(著者:加藤 文元)
- 統計学のための数学入門30講 (科学のことばとしての数学)(著者:永田 靖)