はじめに
Azure上でPaaSとしてApache Kafkaを動かす場合、オプションとして考えられるのはEvent HubのKafka互換APIを使用するか、HDInsightでKafka Clusterを動かす方法がある。Event Hubのほうがクラウドマネージの度合いが高く、HDInsightのほうはユーザーマネージの度合いが高い。いずれにしてもKafkaを利用するにはKafkaにデータを送信するProducerやKafkaからデータを取得するConsumerが必要になる。いろいろな方法があると思うが、今回はAzure Functionsを使ってスケーラブルなkafka Producerを構築することを試したのでそれをメモしておく。
構成
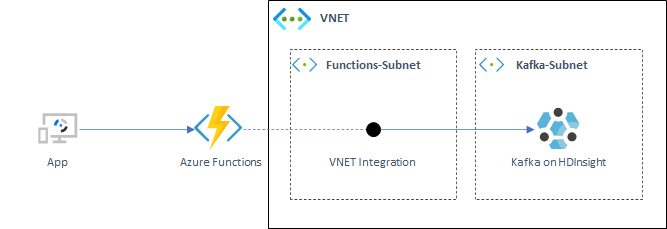
Azure FunctionsでKafka Producerを実行して、HDInsightのKafka Clusterにデータを送信するというもの。HDInsightのKafka ClusterはオプションでREST Proxyを立てることができるが、それを使用しない場合、仮想ネットワークの外からKafkaのエンドポイントに接続できない。そのため、Azure FunctionsでVNET Integrationの設定をして、仮想ネットワークと接続して、Functions用のサブネットからKafka Clusterのサブネット内にアクセスできるようにした。
環境設定
VNETとSubnet作成
上のダイアグラムに基づいて、仮想ネットワークとサブネットを作成。名前やIPアドレスはここでは適当に入れていることに注意。
export MyResourceGroup="myRG"
export vnetName="myVnet"
export VnetPrefix="10.10.0.0/16"
export FunctionsSubnet="Functions-Subnet"
export FunctionsSubnetPrefix="10.10.10.0/24"
export KafkaSubnet="Kafka-Subnet"
export KafkaSubnetPrefix="10.10.20.0/24"
export location="japaneast"
# Create Reource Group
az group create --name $MyResourceGroup --location $location
# Create VNET with a Subnet for Functions. More than /24 address range is required for VNet Integration
az network vnet create -g $MyResourceGroup -n $vnetName --address-prefix $VnetPrefix \
--subnet-name $FunctionsSubnet --subnet-prefix $FunctionsSubnetPrefix
# Create Subnet for Kafka on HDInsight
az network vnet subnet create -g $MyResourceGroup --vnet-name $vnetName -n $KafkaSubnet \
--address-prefixes $KafkaSubnetPrefix
Functionsの作成
VNET Integrationを使用する場合は、Standard、Premiumまたはの価格プランが必要となる。今回はPremium (EP1)を使用。
# Function app and storage account names must be unique.
export storageName=functionstor$RANDOM
export functionAppName=functionkafkaproducer
export premiumplanName=myappspremplan
# Create an azure storage account
az storage account create \
--name $storageName \
--location $location \
--resource-group $MyResourceGroup \
--sku Standard_LRS
# Create a Premium plan
az functionapp plan create \
--name $premiumplanName \
--resource-group $MyResourceGroup \
--location $location \
--sku EP1
# Create a Function App
az functionapp create \
--name $functionAppName \
--storage-account $storageName \
--plan $premiumplanName \
--resource-group $MyResourceGroup \
--runtime java \
--functions-version 3
HDInsight Kafka clusterの作成
事前に作成したサブネット内に接続することができるように、 --subnet オプションを指定する。ここでサブネット名を指定する場合は、仮想ネットワークとHDInsightクラスターのリソースグループが同じ場合には動作するが、リソースグループが異なる場合はサブネット名指定ではデプロイできない。リソースグループが異なる場合はサブネットIDを指定する必要がある。今回は同じリソースグループ内に作成するため、サブネット名の指定でOK。
export clusterName="mykafkacluster"
export storageAccount="myhdikafkastor1"
export httpPassword='<Your Cluster Admin Password>'
export sshPassword='<Your SSH Password>'
export storageContainer=$(echo $clusterName | tr "[:upper:]" "[:lower:]")
export workernodeCount=3
export clusterType=kafka
export clusterVersion=4.0
export componentVersion=kafka=2.1
export subnet="H"
# Create storage account
az storage account create \
--name $storageAccount \
--resource-group $resourceGroupName \
--https-only true \
--kind StorageV2 \
--location $location \
--sku Standard_LRS
# Export primary key of Storage Account
export storageAccountKey=$(az storage account keys list \
--account-name $storageAccount \
--resource-group $resourceGroupName \
--query [0].value -o tsv)
# Create blob container
az storage container create \
--name $storageContainer \
--account-key $storageAccountKey \
--account-name $storageAccount
# Create HDInsight Kafka clusterName
az hdinsight create \
--name $clusterName \
--resource-group $resourceGroupName \
--type $clusterType \
--component-version $componentVersion \
--http-password $httpPassword \
--http-user admin \
--location $location \
--ssh-password $sshPassword \
--ssh-user sshuser \
--storage-account $storageAccount \
--storage-account-key $storageAccountKey \
--storage-container $storageContainer \
--version $clusterVersion \
--workernode-count $workernodeCount \
--workernode-data-disks-per-node 2 \
--vnet $vnetName \
--subnet $KafkaSubnet
FunctionsでVNET Integration設定
次にFunctionsでVNET Integrationを設定する。下図のように、Functionsの管理画面から Networking を選び、VNet Integration の Click here to configure から設定に入る。
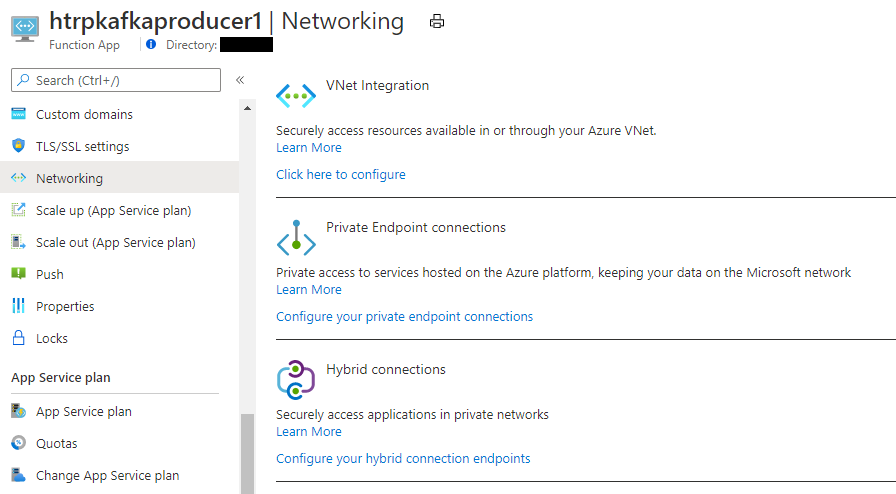
VNet Integrationの設定画面にて、接続する仮想ネットワークおよびサブネットを指定すれば設定完了。
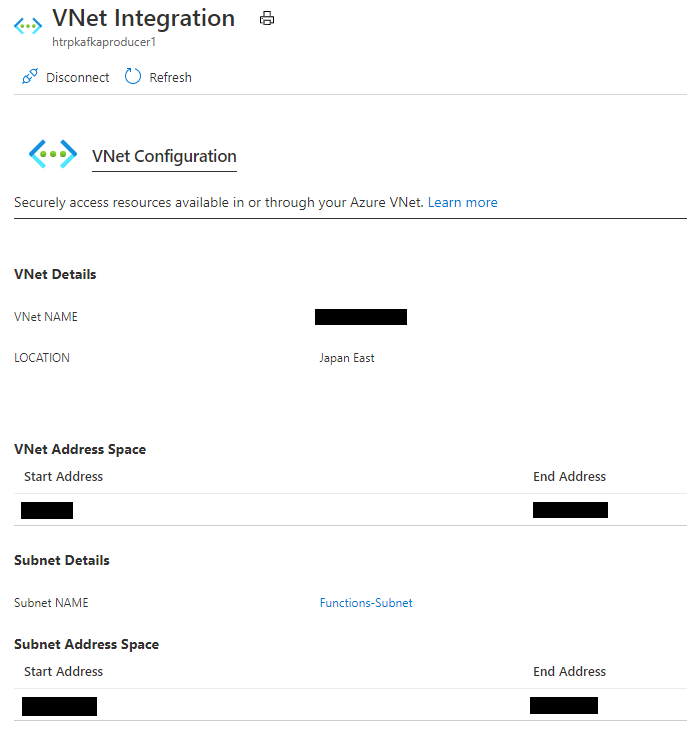
VNet Integrationを設定しただけでは、Functionsは仮想ネットワーク内の内部の名前解決をすることができないため、そのままではKafka Brokerに接続することができない。そのため、内部DNSを参照することができるように以下の設定を追加する必要がある。
| Name | Value | |
|---|---|---|
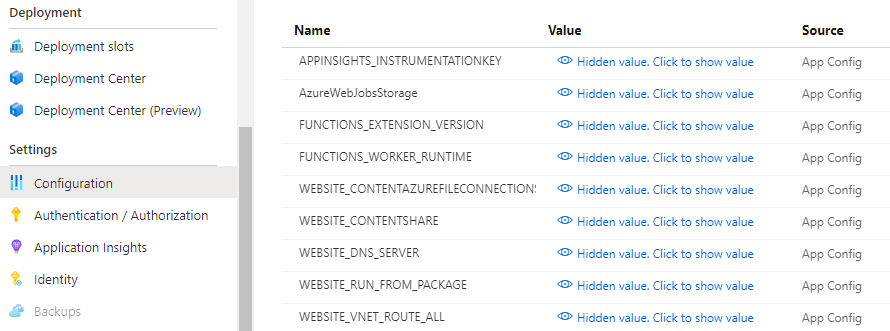
| WEBSITE_DNS_SERVER | 168.63.129.16 | 内部DNSのアドレスを指定 |
| WEBSITE_VNET_ROUTE_ALL | 1 | RFC1918以外の宛先もVNET経由にする |
| 設定した結果は以下のようになる。 | ||
 |
Kafka Producerの作成
環境の準備ができたら、Kafka Producerを作成にとりかかる。Kafka clientを使用するために、 mavenの依存関係に以下を追加する。今回はデプロイしたHDInsightのKafkaのバージョンに合わせて2.1.0を使用
pom.xmlの properties に以下を追加
<properties>
<kafka.version>2.1.0</kafka.version>
</properties>
pom.xmlの dependencies に以下を追加
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
Produerの処理の部分を作成。以下のコードは1メッセージがPOSTされたら都度Kafkaに送信して閉じるだけの簡易的なものだが、性能を出すためには数件まとめて処理するなどの工夫をしたほうが良いだろう。
※ビルドする環境からKafka Brokerの名前解決ができないといけないことに注意が必要。
package com.function;
import com.microsoft.azure.functions.ExecutionContext;
import com.microsoft.azure.functions.HttpMethod;
import com.microsoft.azure.functions.HttpRequestMessage;
import com.microsoft.azure.functions.HttpResponseMessage;
import com.microsoft.azure.functions.HttpStatus;
import com.microsoft.azure.functions.annotation.AuthorizationLevel;
import com.microsoft.azure.functions.annotation.FunctionName;
import com.microsoft.azure.functions.annotation.HttpTrigger;
import java.util.Optional;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.DescribeTopicsResult;
import org.apache.kafka.clients.admin.KafkaAdminClient;
import org.apache.kafka.clients.CommonClientConfigs;
import org.apache.kafka.clients.admin.TopicDescription;
import java.util.Collection;
import java.util.Collections;
import java.util.concurrent.ExecutionException;
import java.util.Properties;
import java.util.Random;
import java.io.IOException;
/**
* Azure Functions with HTTP Trigger.
*/
public class Function {
/**
* This function listens at endpoint "/api/FunctionKafkaProducerJava?". Two ways to invoke it using "curl" command in bash:
* $ curl -XPOST {your host}/api/FunctionKafkaProducerJava?name={topicName} -d 'JSONBODY'
*/
@FunctionName("FunctionKafkaProducerJava")
public HttpResponseMessage run(
@HttpTrigger(
name = "req",
methods = {HttpMethod.GET, HttpMethod.POST},
authLevel = AuthorizationLevel.FUNCTION)
HttpRequestMessage<Optional<String>> request,
final ExecutionContext context) {
context.getLogger().info("Java HTTP trigger processed a request.");
// Parse query parameter
final String topicName = request.getQueryParameters().get("name");
final String reqBody = request.getBody().orElse("");
// Set properties used to configure the producer
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "<KAFKABROKERS>");
// Set how to serialize key/value pairs
properties.setProperty("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
// Create Kafka Producer
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
// Send message to Kafka
try
{
producer.send(new ProducerRecord<String, String>(topicName, reqBody)).get();
}
catch (Exception e)
{
System.out.print(e.getMessage());
}
// Close Kafka producer
producer.flush();
producer.close();
return request.createResponseBuilder(HttpStatus.OK).body(reqBody).build();
}
}
性能面について上記で述べたが、例えばメッセージを送信するクライアント側から一回のPOSTでデータをリストでまとめて送信するようにして、Functions側でそれを一回のKafka Producerの接続で送信することで改善するという方法も考えられる。
// Create Kafka Producer
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
// Send message to Kafka
String jsonLine;
for (int i=0; i < reqBodyArray.length; i++) {
try {
producer.send(new ProducerRecord<String, String>(topicName, reqBodyArray[i])).get();
}
catch (Exception e) {
System.out.print(e.getMessage());
}
}
// Close Kafka producer
producer.flush();
producer.close();
送信テスト
今回の例ではHTTP Triggerで作成しているため、POSTでデータを送信することでFunctionsで受け取りKafkaに送信することができる。Functionsの認証方法に合わせてリクエストを送信したうえで、Kafka側にデータが送られていることを確認できればOK。
curl -XPOST {your host}/api/FunctionKafkaProducerJava?name={topicName} -d '{<JSONBODY>}'