こんにちは。データソリューションスタジオの西尾です。
今回は検索システムの大まかな流れについて、初めて検索システムに触る方に向けてわかりやすくご紹介できたらと思います!
この記事は、Supershipグループ Advent Calendar 2023の17日目の記事になります。
検索システムって何?
ある目的に合致する情報やデータを一定の手順や方法で探し出すシステムとなります。
例えば、有名人について調べたいとき、皆さんがよく使うブラウザから有名人についてのwebページを検索したりしないでしょうか?
このように、より噛み砕くと何か探したい情報・データを探してくれるシステムになりそうです。
専門用語 ドキュメント・キーワード・インデックス
ここではいくつかの専門用語が出てきます。大きく三つです。
ドキュメント
webサイトの文章や商品情報などの検索対象のデータとして考えてほしいです。
キーワード
索引で扱う単語という意味で扱っています。ドキュメントを解析した後で出現している単語のことをキーワードとしています。
インデックス
ドキュメントを検索システムのデータベースに保存して検索できるようにする状態を示しています。
索引を作成してキーワードからドキュメントを検索できるようにする状態と考えてもらえればと思います。
検索システムの種類
検索の方法にも大きく2つあり。逐次検索と索引検索が挙げられます。
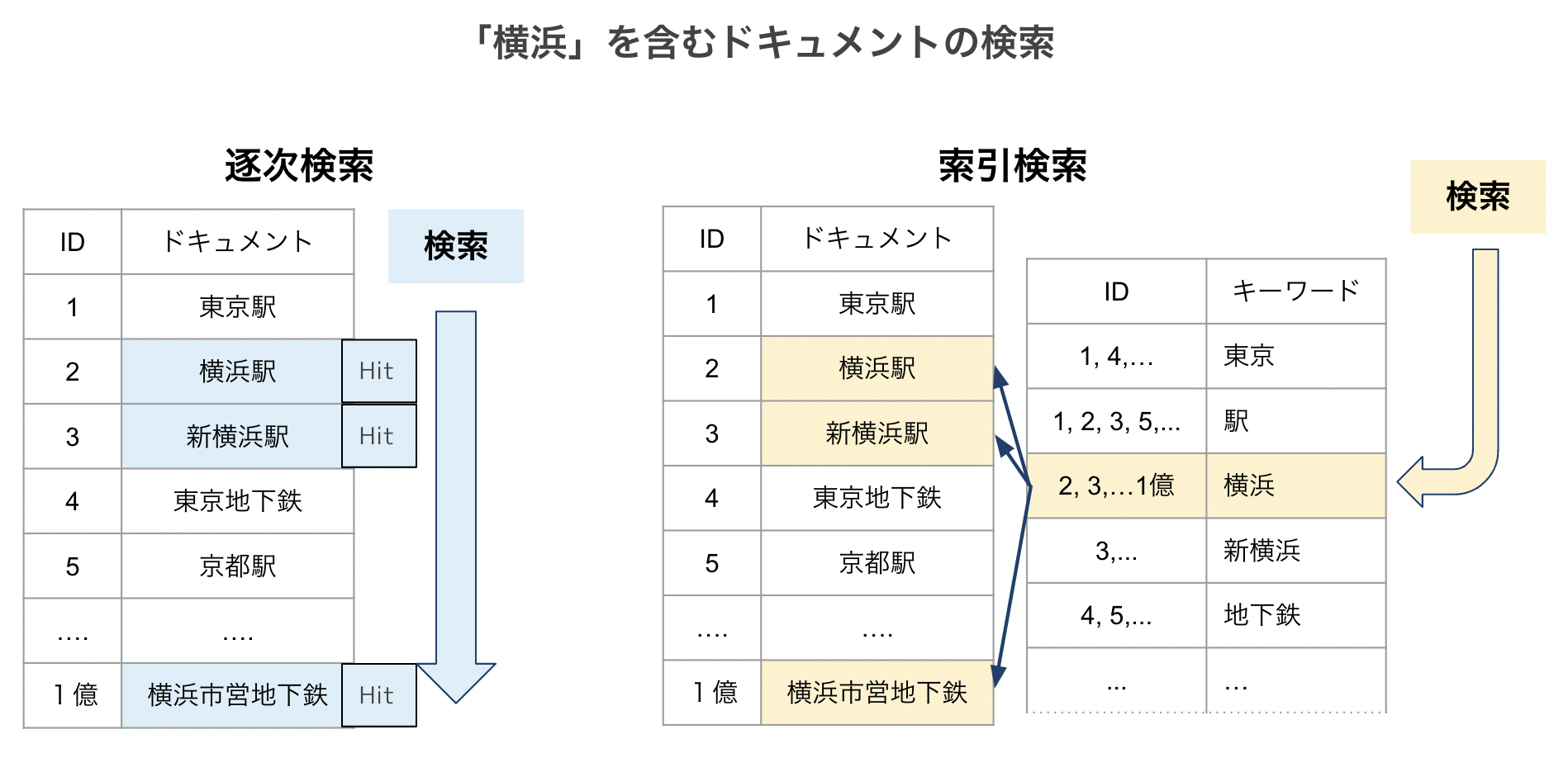
逐次検索
- ドキュメントを先頭から順に見て、検索したい単語と一致するドキュメントを探す方法です。
- シンプルな検索方法ではあり、ドキュメントの量が少なければ問題はありませんが、莫大なドキュメントの量だと検索に時間がかかってしまう。
索引検索
- あらかじめ索引を作っておき、検索時に索引からドキュメントを探す方法です。
- 逐次検索よりも早い検索が可能であり、検索システムではこちらの方法が使われることが多いです。問題点として索引の作成に時間がかかる点があります。
逐次検索に対して索引検索の検索スピードや柔軟性が評価されて検索システムには索引検索が利用されることが多いです。
索引検索を含めて検索システムでどのように検索できるようになるかを説明していきます。
検索システムの全体
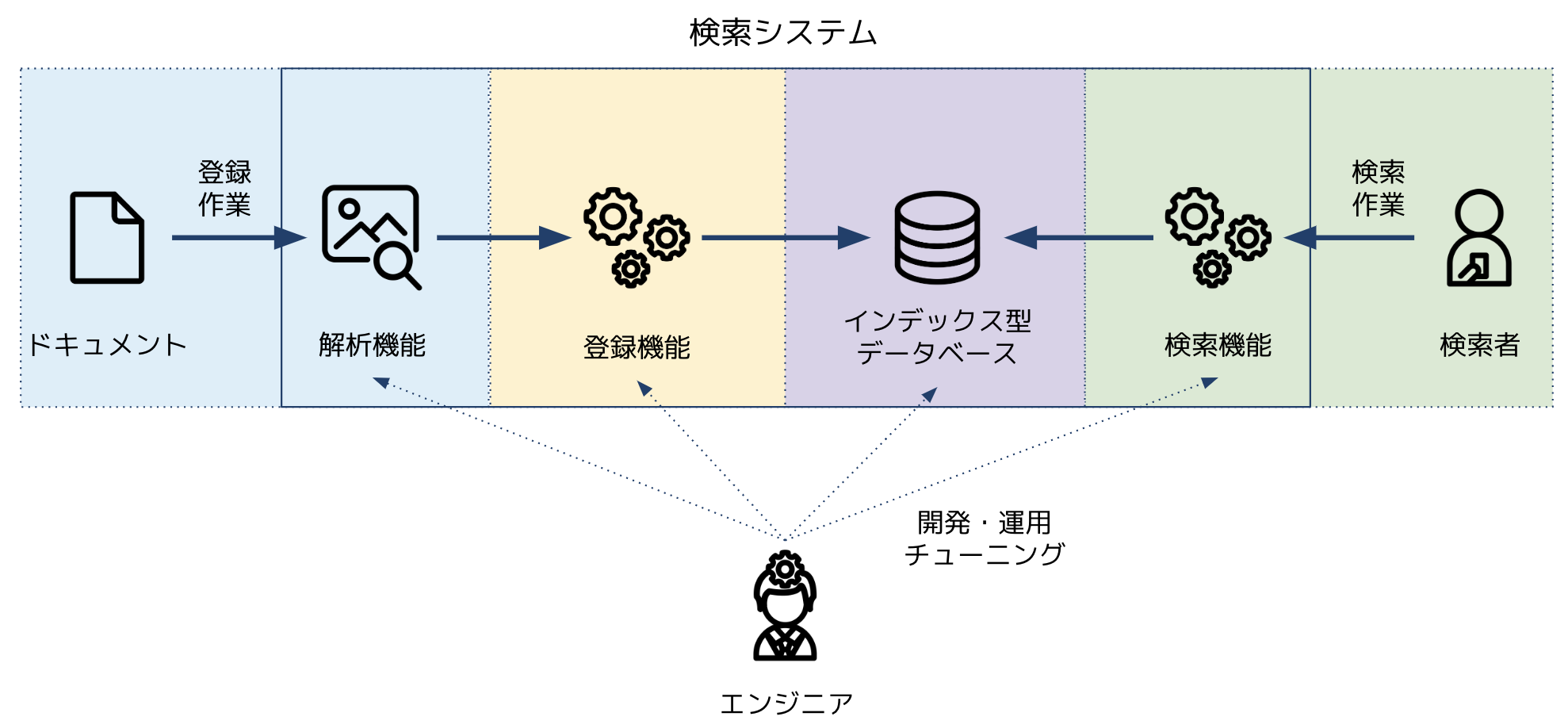
検索システムの区分としては①ドキュメントの解析と登録を行い、②インデックスとしてドキュメントを保存し、③検索を行うの大きく3つあります。
エンジニアの方はそれぞれの機能について開発・運用・チューニングを行い、日々の検索結果を改善しています。
検索システムの流れ
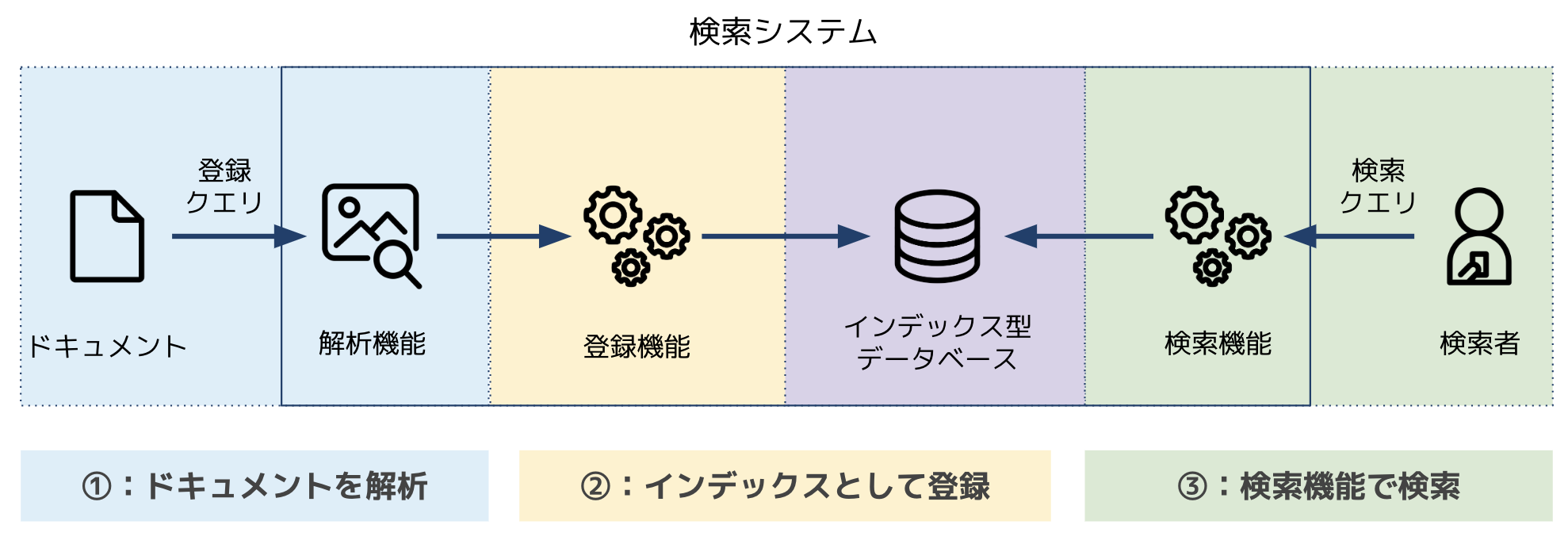
流れとしては
- ドキュメントの解析を行い索引のためのキーワードを取得を行う。
- キーワードとドキュメントをインデックスとしてデータベースに保存する。
- 検索者(ユーザー)がデータベースに検索を行い、検索結果が返ってくる。
の三つの流れに沿って検索システムは動いています。
なので大きく分けると、前半の検索システムの作成と、後半の検索システムで検索を行うのが基本になります。
まず前半の検索システムの作成について説明します。
ドキュメントの解析とキーワード取得
ここではドキュメントを解析してキーワードを取得する流れを説明します。
ドキュメントとして登録される物には文字や数字以外にも文章などもあります。
特に文章の検索を行う際に必要になってくるのですが、どのように文章からキーワードを取り出すのでしょうか?

解析と取得には以下の3つの流れがあり、それぞの具体的に何をしているかというと
- ドキュメントの正規化。例では 「、」や「。」などのキーワードに不必要な単語を排除しています。
- ドキュメントをキーワード単位に分割。例では日本語の単位ごとに分割しています。
- キーワードそれぞれに加工。例ではキーワードに相応しくない「から」「に」「で」を削除したり「新横浜駅」を1単語ごとに分割したりしています。
このように解析と取得を行なっています。以上は一例に過ぎず、漢字をひらがなやローマ字にしたり、分割の手法も多くあります。
インデックスとしてデータベースに登録する
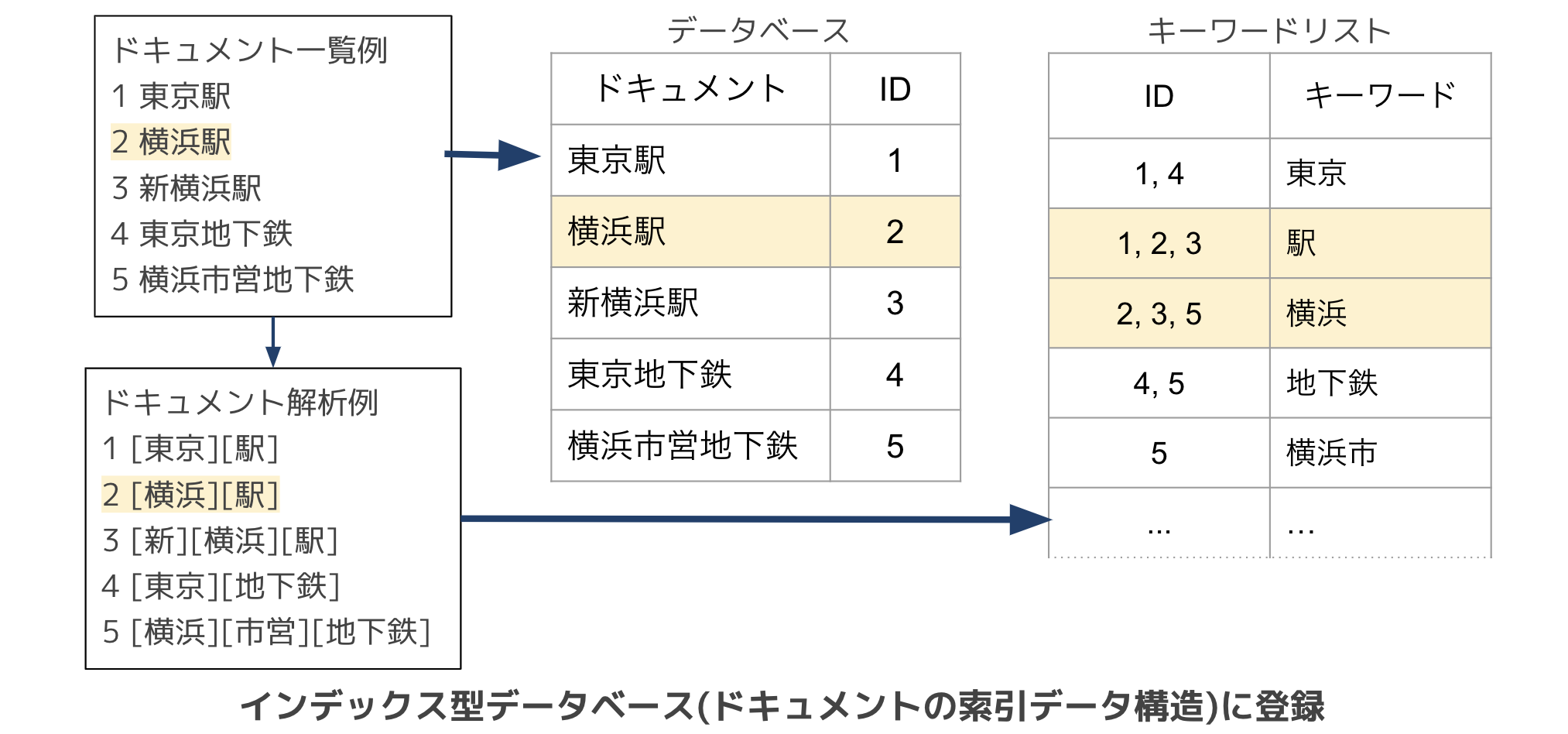
ドキュメントをインデックスとして登録する部分で大きく二つ流れがあります
- 特定ドキュメントと特定ドキュメントに紐づけられたIDを保存します。
- ドキュメントで解析・取得したキーワードとキーワードが出現するドキュメントのID群を保存します。
特に2に関して具体例を含めて説明します。
-
ドキュメントを解析・取得したキーワードを取得します。
例では横浜駅から「横浜」と「駅」の2キーワードを取得しました。 -
キーワードをドキュメントのID群と保存します。
例では「横浜」というキーワードはドキュメントの「横浜駅」だけでなく「新横浜駅」や「横市営地下鉄」のキーワードとしてあるため、3つのIDとキーワード「横浜」が保存されます。
キーワードは一つだけのドキュメントだけでなく、複数の他のドキュメントにも存在することがあります。
キーワードをどのドキュメントで出現するかとして複数のIDを保存することで、特定のキーワードはこのIDのこのドキュメントに出現することがわかるようになります。
ここまでがドキュメントを登録するまでの流れになります。
インデックス型データベースに検索を行う

ここから検索者(ユーザー)が検索する流れになります。
インデックス型データベースを用いて検索を行います。
検索者が入力した、検索対象の単語が検索システムに送られます。
検索対象の単語に関してキーワードリストで検索を行います。
検索対象の単語と一致するキーワードが見つかると関連づけられているドキュメントのIDがわかります。
そのIDから検索結果の対象になる複数のドキュメントがわかります。
このドキュメントを検索結果として検索者(ユーザー)に返すというのが基本的な流れになります。
検索システムの全体と流れのまとめ
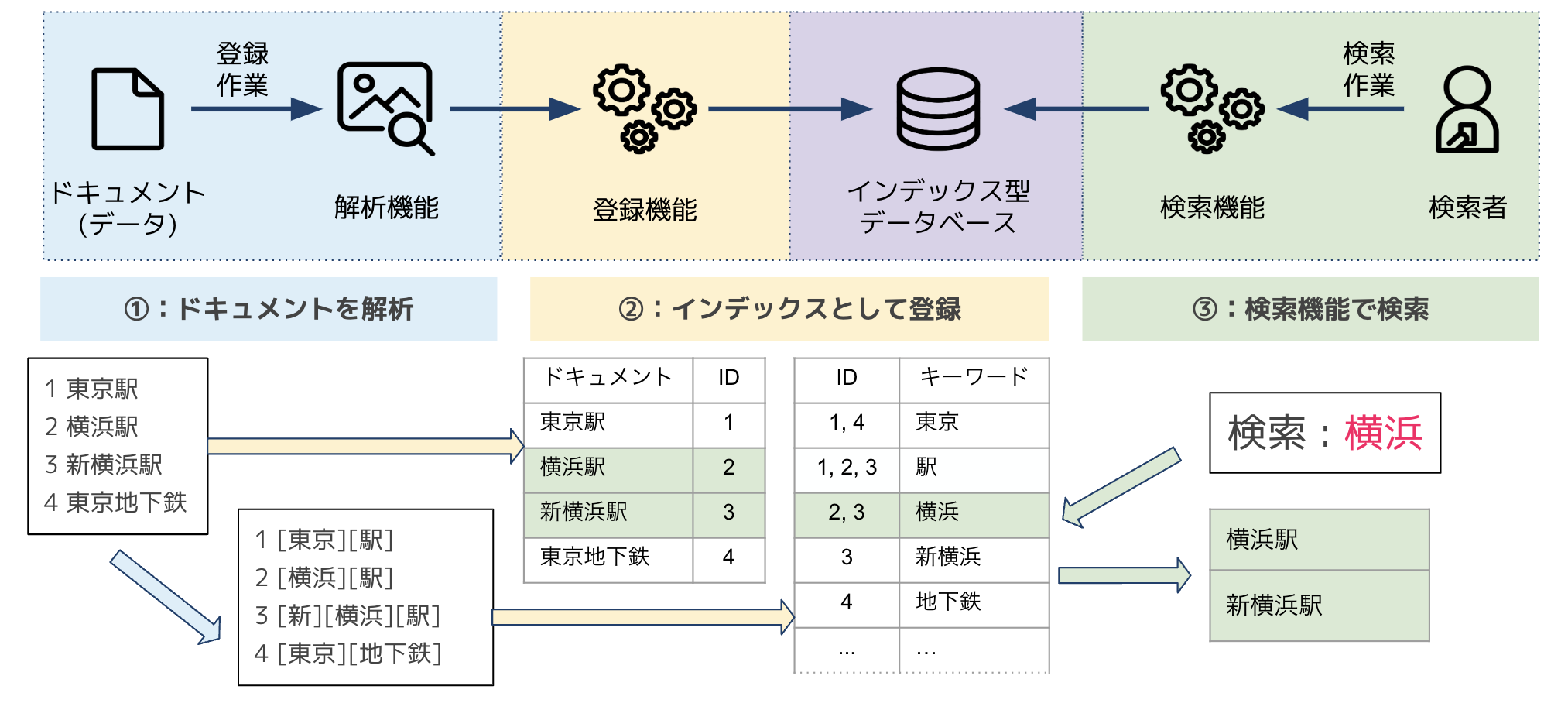
検索システムについてのまとめです。改めて流れを確認すると、大きく3つの流れです。
- 解析機能でドキュメントの解析を行い、キーワードの取得を行います。
- ドキュメントとキーワードをIDに関連付けながら索引できるようにインデックスとしてデータベースに保存する.
- 検索者が入力した検索対象の単語からキーワードり→ID→ドキュメントの流れで検索を行い、検索結果を返す
の流れになります。
検索システムをもっと知りたい・開発したい方へ
以上までがふんわりした感じでの説明になりましたが、より厳密にどう動いているか知りたい方は、以下のサイトや本が参考になると思います。
検索システムであればElasticsearchやopensearchから色々探してみるのがいいじゃないかと思います。
おわりに
私が初めて検索システムを触るときに、このような資料あればより検索システムについての理解のとっかかりができたかなと思ったりしています。
なのでどんどんインプットとアウトプットをしていきたいなと思っています!
またこのように図解にしていくと私自身も検索の流れというものがよくわかってくるように感じます。
他の記事としてサジェスト(オートコンプリート)について記事にできればと思います!
最後に宣伝です。
Supershipではプロダクト開発やサービス開発に関わる人を絶賛募集しております。
ご興味がある方は以下リンクよりご確認ください。
Supership 採用サイト
是非ともよろしくお願いします。