この記事の目的
自分は、とある会社様の元でソシャゲの API 開発をさせていただいています。
ソシャゲは、リリース時やイベント時などに集中アクセスされやすく、負荷軽減の知識がない状態で開発を行ってしまうと、運用時に緊急メンテ祭りになりやすいジャンルかなと思っています。
これまで培ってきた MySQL の知識ですが、脳内メモリ量の関係上、暗記できないのでメモしておこうというのが主目的です。
ここ数年ほどソシャゲ開発しかしていないため、偏っている感がある内容ですのでご注意ください。
概要
ストレージエンジンは InnoDB。メインで扱っている MySQL バージョンは 5.6。
記事の内容ですが、これらのキーワードを見て、おおよそ分かる方は読む必要はないかと思います。
- インデックス系
- クラスタインデックス
- カバリングインデックス
- EXPLAIN で注意するべき値
- トランザクション系
- MVCC
- ネクストキーロック&ギャップロック
- 設定系
- クエリキャッシュ
- ページサイズ
- バッファプール
1. インデックスの知識
1-1. クラスタインデックス と カバリングインデックス
1-1-1. クラスタインデックス とは?
MySQL は、PRIMARY KEY(以降 PK) インデックスの B-TREE リーフノードにレコードデータがセットされている構造になっています。
これを、クラスタインデックス といいます。

セカンダリインデックス には、リーフノードに PK 値のみセットされています。
このため、レコード全体の値が必要な場合は、更に PK インデックスの B-TREE にアクセスする必要があります。
例えば、この図は、name 列にセカンダリインデックスを貼った場合の走査イメージです。

MySQL の、このクラスタインデックスという仕組みにより、SQL の実行速度に差が出ることがあります。1
それが、カバリングインデックスです。
1-1-2. カバリングインデックス とは?
セカンダリインデックスのリーフノードにセットされた PK 値から、PKインデックスにアクセスすると書きましたが、アクセスする必要が無い場合があります。
セカンダリインデックスのリーフノードには PK 値があり、そしてインデックスに設定されている列値も分かっている状態です。

つまり、SELECT ステートメントで指定した列が、セカンダリインデックスに設定された列と PK 列のみの時は、PKインデックスにアクセスする必要がありません。
この様に、セカンダリインデックスのみでデータ取得が解決することを、カバリングインデックスといいます。
カバリングインデックスの場合、PKインデックスを走査する必要がなくなるので、ちょっとだけ速くなります。
1-1-3. カバリングインデックスかを確認する方法
カバリングインデックス 状態かどうかを確認するには、EXPLAIN ステートメントを使用します。
例えば、以下のテーブルとデータの状態で...
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(32) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
> INSERT INTO test (name, age) VALUES ('katou', 30), ('suzuki', 35), ('sato', 40);
> SELECT * FROM test;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | katou | 30 |
| 2 | suzuki | 35 |
| 3 | tanaka | 40 |
+----+--------+-----+
EXPLAIN を実行して Extra セクションに Using index と表示されれば、カバリングインデックス ということです。2
この例の場合、name カラムに貼られたインデックス(idx_name)が使われるので、name と id(PK) の SELECT のみ カバリングインデックス になります。
> EXPLAIN SELECT id, name FROM test WHERE name = "suzuki";
+----+-------------+-------+------+---------------+----------+---------+-------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+----------+---------+-------+------+--------------------------+
| 1 | SIMPLE | test | ref | idx_name | idx_name | 98 | const | 1 | Using where; Using index |
+----+-------------+-------+------+---------------+----------+---------+-------+------+--------------------------+
上記 SQL の SELECT ステートメントに、age カラムを追加すると カバリングインデックス ではなくなることが分かります。
Extra セクションには、Using index condition と表示されます。
これは、「インデックス が使われたが、カバリングインデックスではなかった」という意味です。
> EXPLAIN SELECT id, name, age FROM test WHERE name = "suzuki";
+----+-------------+-------+------+---------------+----------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+----------+---------+-------+------+-----------------------+
| 1 | SIMPLE | test | ref | idx_name | idx_name | 98 | const | 1 | Using index condition |
+----+-------------+-------+------+---------------+----------+---------+-------+------+-----------------------+
1-1-4. カバリングインデックスは狙うべき?インデックスが増えることのデメリット
では、「カバリングインデックスを狙ってインデックスをどんどん増やせばいいのか?」というと、そうではありません。
増やすことにもデメリットがあります。
1-1-4-1. [デメリット1] INSERT、UPDATEが遅くなる
INSERT 時や UPDATE 時には、インデックスも更新する必要があるので、メモリにロードします。
オンメモリなら問題ありませんが、インデックスサイズが大きくなりすぎて READ が発生したら急激に遅くなってしまいます。
1-1-4-2. [デメリット2] データサイズを圧迫する
インデックスはデータサイズが非常に大きいため、容量を圧迫する要因になります。
データサイズの確認は、以下の SQL で確認できます。3
SELECT
table_name,
engine,
table_rows AS 'レコード数',
sys.format_bytes(data_length + index_length) AS '総データサイズ',
sys.format_bytes(data_length) AS 'データファイルサイズ',
sys.format_bytes(index_length) AS 'セカンダリインデックスファイルサイズ'
FROM information_schema.tables
WHERE table_schema = database()
ORDER BY table_rows DESC;
例えばこれは、自分のローカルで実行した結果です。
先に出てきた test テーブル(セカンダリインデックスは name 列への1つのみ)を使っています。
データサイズは 41MB なのに対して、インデックスのデータサイズが 10MB と、かなり容量を使うことが分かります。
+------------+--------+-----------+---------------+--------------------+-----------------------------------+
| table_name | engine | レコード数 | 総データサイズ | データファイルサイズ | セカンダリインデックスファイルサイズ |
+------------+--------+-----------+---------------+--------------------+-----------------------------------+
| test | InnoDB | 527193 | 52.08 MiB | 41.56 MiB | 10.52 MiB |
+------------+--------+-----------+---------------+--------------------+-----------------------------------+
1-2. インデックス系で注意するべき EXPLAIN
カバリングインデックスかどうか確認した時に使った EXPLAIN ですが、SQLが インデックス を適切に使っているかどうかの確認にも使います。
レコード数が多いテーブルに対して、インデックスが全く使われない状態でデータを取得してしまうと、高負荷になるので要注意です。
色々な値が表示されますが、表示された場合に注意が必要なものだけ抜き出します。4
その他詳細はこちらをご確認ください。
explainした時の重要ポイント(実例つき)
1-2-1. type=ALL
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | test | ALL | NULL | NULL | NULL | NULL | 3 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
type セクションに ALL と表示された場合、『実行した SQL にインデックスが全く使用されず、テーブルの全データを走査した』という意味です。
これが表示されると、レコード数が多い場合、重大な速度低下につながりますので、修正必須です。
WHERE ステートメントに該当するインデックスを追加する必要があります。
1-2-2. type=index
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------+
| 1 | SIMPLE | test | index | NULL | PRIMARY | 4 | NULL | 3 | NULL |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------+
type セクションに index と表示された場合、『インデックスが使用されたのですが、フルインデックススキャンが発生した』ことを意味しています。
これもレコード数が多い場合、重大な速度低下につながりますので、修正必須です。
インデックスのカラムを見直す必要があります。
1-2-3. Extra=Using filesort
+----+-------------+-------+------+---------------+----------+---------+-------+------+----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+----------+---------+-------+------+----------------------------------------------------+
| 1 | SIMPLE | test | ref | idx_name | idx_name | 98 | const | 3 | Using index condition; Using where; Using filesort |
+----+-------------+-------+------+---------------+----------+---------+-------+------+----------------------------------------------------+
Extra セクションに Using filesort と表示された場合、『ORDER BY ステートメントのカラムにインデックスが効いておらず、MySQL がソートを行った』ことを意味しています。
修正必須ではありませんが、取得レコード数が多いと速度低下につながる可能性があるため、要注意です。
修正時は、ORDER BY ステートメントのカラムをインデックスに追加する必要があります。
これは、インデックスは、カラム値が昇順でセットされているので、インデックスからデータを取得した時点で順番に並んでおり、ソートを行う必要がなくなるからです。
また、MySQL 8.0 から降順インデックスがサポートされました。
昇順インデックスの場合でも、ORDER BY ... DESC が遅くなるということはありませんが、降順インデックスが使用されるとより高速になります。
1-2-4. Extra=Using temporary
+----+-------------+-------+------+---------------+----------+---------+-------+------+-----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+----------+---------+-------+------+-----------------------------------------------------+
| 1 | SIMPLE | test | ref | idx_name | idx_name | 98 | const | 1 | Using index condition; Using where; Using temporary |
+----+-------------+-------+------+---------------+----------+---------+-------+------+-----------------------------------------------------+
Extra セクションに Using temporary と表示された場合、『結果を取得するにあたりテンポラリテーブルを使用する必要があった』ことを意味しています。
インデックスを見直すか、テーブル構造を再考する必要があります。
1-3. カーディナリティ (Cardinality)
インデックスが適切かどうかの基準として、「カーディナリティ」という単位があります。
カーディナリティとは、英語で「濃度」という意味です。
「カーディナリティが高い」とは、全データ中の濃度が高い...つまり重複データが少ない状態。
「カーディナリティが低い」とは、全データ中の濃度が低い...つまり重複データが多い状態を表します。
カーディナリティがあまりに低い(重複データが多い)と、爆発的な速度の向上は見込めません。
1-3-1. なぜカーディナリティが低いと遅いのか?
データ検索時にインデックスが使われはしますので、インデックスが無い状態より速くはなります。
ですが、重複数に比例して多くのノードを走査する必要があるので高速ではありえません。
EXPLAIN すると、rows が多くなっているのが分かると思います。
1-3-2. カーディナリティが低い列をセカンダリインデックスに追加するかの基準
検索条件が『カーディナリティが低い列のみ』の場合、追加せざるを得ないかなと思いますが推奨できません。
レコード数が増えた時に徐々に遅くなっていってしまうので、他のカーディナリティが高い列を上の検索条件に入れて、件数を絞りこむ仕様にもっていくことが大事です。
件数が絞り込めてさえいれば、カーディナリティが低い列は追加する必要はないかなと思います。
(先に書いた通り、インデックスを追加するにもデメリットがあるので)
絶対に NG なのは、『カーディナリティが低い→高い』順のセカンダリインデックスを作ってしまうことです。
1-3-3. カーディナリティの確認方法
カーディナリティは、以下の SQL で確認可能です。
SHOW INDEX FROM table_name;
例えば以下の例だと、データは 5161476 件。インデックス idx_modifiedは、カーディナリティ = 6241 で「カーディナリティが低い(重複データが多い)」状態なので、インデックス としては、よろしくない状態だと分かります。
> SHOW INDEX FROM user;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| user | 0 | PRIMARY | 1 | id | A | 5161476 | NULL | NULL | | BTREE | | |
| user | 1 | idx_password | 1 | password | A | 5161476 | NULL | NULL | | BTREE | | |
| user | 1 | idx_modified | 1 | modified | A | 6241 | NULL | NULL | | BTREE | | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2. MySQL の特殊なロック
MySQLでは、多人数がアクセスする環境のみでロックが発生することがあります。
本番リリースまでこれに気づかないと、ロック待ち、もしくはデッドロックによって API の遅延やサーバ負荷になることがあるので、開発時に注意する必要があります。
(負荷試験が適切に行われていればそこで気付くはずですが、試験項目によっては発生しない可能性もありますので、開発時に潰しておくべきです)
2-0. 基礎知識
ロックについて書くにあたって、関係してきそうな基礎知識です。
以下のキーワードが分かっている人は、飛ばして『 2-1. ファントムリードを防ぐ 』から読んでください。
- ACID 特性
- トランザクション分離レベル
- ダーティリード / ファジーリード / ファントムリード
- MySQL のロックはインデックス単位
- supremum と infimum
2-0-1. (基礎知識) ACID 特性
トランザクション処理で必要な要素です。
- A (atomicity)
- 原子性。トランザクション内の操作が全て実行されるか/されないか。
- C (consistency)
- 一貫性(整合性)。DB内のデータに矛盾のない事。
- I(isolation)
- 独立性(分離性)。トランザクション中に行われる操作は他のトランザクションに影響を与えない事。
- 次で説明するトランザクション分離レベルはこれ。
- D(durability)
- 永続性。永続的(失われない) = システム障害に耐える。
2-0-2. (基礎知識) トランザクション分離レベル
InnoDB のデフォルト分離レベルである REPEATABLE READ の場合、特殊なロックが発生します。
その理由が、ここに関係しているので知っておいた方がいいかと思います。
| ダーティリード | ファジーリード | ファントムリード | |
|---|---|---|---|
| READ UNCOMMITTED | 発生する | 発生する | 発生する |
| READ COMMITTED | 発生しない | 発生する | 発生する |
| REPEATABLE READ | 発生しない | 発生しない | 発生する |
| SERIALIZABLE | 発生しない | 発生しない | 発生しない |
トランザクション分離レベルの詳細に関して興味がある人は、song_ss さんのこちらの記事がよくまとまっているのでご確認ください。
Qiita - トランザクション分離レベルについてのまとめ
また、余談ですが、Oracle や PostgreSQL、SQL Server などの DB はデフォルトが READ COMMITTED なので、InnoDB は高い目標を掲げていると分かります。
しかも、特殊なロックにより、実は SERIALIZABLE に該当する分離レベルの実装になっています。
2-0-3. (基礎知識) ダーティリード
別のトランザクションが、まだ COMMIT してないデータが読み取れる現象です。
分離レベル = READ UNCOMMITTED のみで発生します。
-- TRN_1 と TRN_2 のトランザクション分離レベルを READ UNCOMMITTED に変更する
TRN_1> SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
TRN_2> SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
TRN_1> SELECT * FROM test;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | katou | 30 |
+----+--------+-----+
-- TRN_1 のトランザクションを開始。データを INSERT、UPDATE する...が COMMIT はしない
TRN_1> BEGIN;
TRN_1> INSERT INTO test (name, age) VALUES ('baby', 1);
TRN_1> UPDATE test SET age = 40 WHERE name = 'katou';
-- TRN_2 で SELECT すると、TRN_1 の未COMMIT データが見えてしまう
TRN_2> BEGIN;
TRN_2> SELECT * FROM test;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | katou | 40 |
| 2 | baby | 1 |
+----+--------+-----+
2-0-4. (基礎知識) ファジーリード
別のトランザクションが UPDATE → COMMIT したデータが読み取れることにより、トランザクション内での一貫性がなくなる現象です。
分離レベル = READ UNCOMMITTED と READ COMMITTED で発生します。
-- TRN_1 と TRN_2 のトランザクション分離レベルを READ COMMITTED に変更する
TRN_1> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
TRN_2> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- TRN_2 のトランザクションを開始
TRN_2> BEGIN;
TRN_2> SELECT * FROM test;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | katou | 30 |
+----+--------+-----+
-- TRN_1 のトランザクションを開始。データを UPDATE(age = 30 → 40) して COMMIT
TRN_1> BEGIN;
TRN_1> UPDATE test SET age = 40 WHERE name = 'katou';
TRN_1> COMMIT;
-- TRN_2 で SELECT すると、TRN_1 が UPDATE したデータが見えてしまう
TRN_2> SELECT * FROM test;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | katou | 40 | /* ← 同トランザクション内なのに、age が 30 から 40 に変わっている */
+----+--------+-----+
ちなみに、「ファジーリードが発生しない」というのは、「トランザクション内で1度読み取ったデータが同トランザクション内で保証される」ということです。(全てのデータがトランザクション開始時の値になる。というわけではありません)
ファジーリードが発生しないトランザクション分離レベルであっても、1度も読んでないデータは更新後の値が表示されます。
-- TRN_1 と TRN_2 のトランザクション分離レベルを REPEATABLE READ に変更する(ファジーリードは発生しない分離レベル)
TRN_1> SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
TRN_2> SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- TRN_2 のトランザクションを開始
-- しかしデータは読み取らない。もしここでデータを読み取ってしまうとずっと 30 が取得される
TRN_2> BEGIN;
-- TRN_1 のトランザクションを開始。データを UPDATE(age = 30 → 40) して COMMIT
TRN_1> BEGIN;
TRN_1> UPDATE test SET age = 40 WHERE name = 'katou';
TRN_1> COMMIT;
-- TRN_2 で SELECT すると、TRN_1 が UPDATE したデータが見える
TRN_2> SELECT * FROM test;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | katou | 40 | /* ← age が TRN_1 の更新値 40 になっている */
+----+--------+-----+
2-0-5. (基礎知識) ファントムリード
別のトランザクションが INSERT → COMMIT したデータが読み取れることにより、トランザクション内での一貫性がなくなる現象です。
分離レベル = READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ (SERIALIZABLE 以外全て)で発生します。
-- TRN_1 と TRN_2 のトランザクション分離レベルを REPEATABLE READ に変更する
TRN_1> SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
TRN_2> SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- TRN_2 のトランザクションを開始
TRN_2> BEGIN;
TRN_2> SELECT * FROM test;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | katou | 30 |
+----+--------+-----+
-- TRN_1 のトランザクションを開始。データを INSERT して COMMIT
TRN_1> BEGIN;
TRN_1> INSERT INTO test (name, age) VALUES ('baby', 1);
TRN_1> COMMIT;
-- TRN_2 で SELECT すると、TRN_1 が INSERT したデータが見えてしまう
TRN_2> SELECT * FROM test;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | katou | 30 |
| 2 | baby | 1 |
+----+--------+-----+
2-0-5. (基礎知識) ロックはインデックスに対して行われる
ロックというと、実データに対して行うイメージがありますが、少なくとも MySQL は違います。
ロックは全て、インデックスに対して行われます。
以下のテーブルとデータで例を挙げます。
> CREATE TABLE `test_unique_name` (
`id` int(11) NOT NULL,
`name` varchar(32) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
> INSERT INTO `test_unique_name` (`id`, `name`, `age`) VALUES (1, 'sato', 21), (2, 'takagi', 25), (3, 'suzuki', 30), (4, 'tomita', 27), (5, 'tanaka', 32), (6, 'ukita', 20);
> SELECT * FROM `test_unique_name`;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | sato | 21 |
| 2 | takagi | 25 |
| 3 | suzuki | 30 |
| 4 | tomita | 27 |
| 5 | tanaka | 32 |
| 6 | ukita | 20 |
+----+--------+-----+
name 列を更新する時に、
> BEGIN;
> SELECT * FROM `test_unique_name` WHERE name = 'takagi' FOR UPDATE;
uniq_name インデックス と、PRIMARY インデックス にレコードロックがかかっているのが分かります。
---TRANSACTION 5421672, ACTIVE 1 sec
3 lock struct(s), heap size 360, 2 row lock(s)
MySQL thread id 2, OS thread handle 0x7f21e634e700, query id 23322 172.22.0.1 root init
SHOW ENGINE INNODB STATUS
TABLE LOCK table `test`.`test_unique_name` trx id 5421672 lock mode IX
RECORD LOCKS space id 4690 page no 4 n bits 80 index `uniq_name` of table `test`.`test_unique_name` trx id 5421672 lock_mode X locks rec but not gap
Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 6; hex 74616b616769; asc takagi;;
1: len 4; hex 80000002; asc ;;
RECORD LOCKS space id 4690 page no 3 n bits 80 index `PRIMARY` of table `test`.`test_unique_name` trx id 5421672 lock_mode X locks rec but not gap
Record lock, heap no 3 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
0: len 4; hex 80000002; asc ;;
1: len 6; hex 00000052ba62; asc R b;;
2: len 7; hex c200000166011d; asc f ;;
3: len 6; hex 74616b616769; asc takagi;;
4: len 4; hex 80000019; asc ;;
2-0-6. (基礎知識) supremum と infimum
MySQL はインデックスでロックをかける関係上、『先頭レコードよりも前にある疑似レコード』と、『末尾レコードより後にある疑似レコード』を持っています。
先頭レコードよりも前にある疑似レコードを infimum、末尾レコードより後にある疑似レコードを supremum と言います。
例えば、'tomita' → 'ukita' というデータが入っていて ukita が末尾データの場合、'ukita' 以降のデータの挿入を防ぎたい場合は、以下のように supremum に対してロックがかかります。(詳細は後述します)
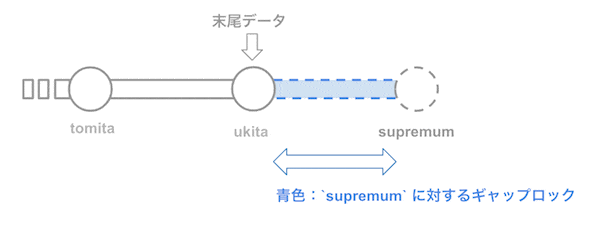
MySQL 5.6 以前の場合、インデックスは昇順のみなので supremum のみロックとして使用されます。
MySQL 5.8 から降順インデックスが実装されたので infimum もロックされるようになると思われます。(未確認)
2-1. ファントムリードを防ぐ
前述した通り、REPEATABLE READ は、ファントムリードが発生するトランザクション分離レベルです。
しかし、InnoDB は、REPEATABLE READ でありながらファントムリードをも発生させない仕組みを採用しています。
そのための仕組みが、MVCC と ネクストキーロック です。
2-1-1. MVCC(Multi-Version Concurrency Controll)
MVCC とは、非ロック読み取り(Consistent Nonlocking Reads)を実現する機能です。
以下は、実際に MVCC によって、ファントムリードが発生しない例です。
別トランザクションで INSERT → COMMIT したデータが見えないことが分かります。
> select @@global.tx_isolation, @@session.tx_isolation;
+-----------------------+------------------------+
| @@global.tx_isolation | @@session.tx_isolation |
+-----------------------+------------------------+
| REPEATABLE-READ | REPEATABLE-READ |
+-----------------------+------------------------+
-- TRN_2 のトランザクションを開始
TRN_2> BEGIN;
TRN_2> SELECT * FROM test;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | katou | 30 |
+----+--------+-----+
-- TRN_1 のトランザクションを開始。データを INSERT して COMMIT
TRN_1> BEGIN;
TRN_1> INSERT INTO test (name, age) VALUES ('baby', 1);
TRN_1> COMMIT;
-- TRN_2 で SELECT しても、TRN_1 が INSERT したデータが見えない
TRN_2> SELECT * FROM test;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | katou | 31 |
+----+--------+-----+
MVCC をざっくりと説明すると、「トランザクション単位でバージョン番号を採番(インクリメント)し、見えるデータを制御する」というイメージです。
[MVCC イメージ]

2-1-2. ネクストキーロック
MVCC で完璧にファントムリードを防いでいるように見えますが、MVCC が使われない場合もあります。
Locking Reads の場合は MVCC が使われず、最新値を取得します。
これは、ロストアップデートを防ぐための仕様です。
2-1-2-1. ロストアップデート
ロストアップデート とは、値を取得して変数に保存し、変数値から加算した時に値のズレが発生する問題です。
以下の例は、Locking Reads を使用していないので MVCC が使われ、ロストアップデートが発生する例です。
> SELECT * FROM test WHERE name = 'sato';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 3 | sato | 40 |
+----+------+-----+
-- トランザクションA: 開始
TRN_1> BEGIN;
-- トランザクションB: 開始。既存データを取得して1加算
TRN_2> BEGIN;
TRN_2> SELECT age INTO $age FROM test WHERE name = 'sato'; /* $age = 40 */
TRN_2> UPDATE test SET age = @age + 1 WHERE name = 'sato'; /* age = 40 + 1 = 41 */
TRN_2> COMMIT;
-- トランザクションA: 既存データを取得して1加算
-- MVCCが効いているのでトランB更新前の値が取得される
TRN_1> SELECT age INTO $age FROM test WHERE name = 'sato'; /* $age = 40 (41であってほしいが...) */
TRN_1> UPDATE test SET age = @age + 1 WHERE name = 'sato'; /* age = 40 + 1 = 41 */
TRN_1> COMMIT;
-- 結果。age = 42 のはずが 41 になっている
> SELECT * FROM test WHERE name = 'sato';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 3 | sato | 41 |
+----+------+-----+
しかし、Locking Reads で取得した場合、MVCC が使われず、ロストアップデートは発生しません。
-- トランザクションA: 開始
TRN_1> BEGIN;
-- トランザクションB: 開始。既存データを取得して1加算
TRN_2> BEGIN;
TRN_2> SELECT age INTO $age FROM test WHERE name = 'sato' FOR UPDATE; /* $age = 40 */
TRN_2> UPDATE test SET age = @age + 1 WHERE name = 'sato'; /* age = 40 + 1 = 41 */
TRN_2> COMMIT;
-- トランザクションA: 既存データを取得して1加算
-- MVCC が効いていないのでトランBで更新した値が取得される
TRN_1> SELECT age INTO $age FROM test WHERE name = 'sato' FOR UPDATE; /* $age = 41 */
TRN_1> UPDATE test SET age = @age + 1 WHERE name = 'sato'; /* $age = 41 + 1 = 42 */
TRN_1> COMMIT;
-- 結果。age = 42 になっている
TRN_1> SELECT * FROM test WHERE name = 'sato';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 3 | sato | 42 |
+----+------+-----+
2-1-2-2. ネクストキーロック例
ネクストキーロック(とギャップロック)は、Locking Reads で取得した場合、かつ以下の条件で発生します。
- EXPLAIN した結果、type=ref の場合(非unique列に対する検索の場合)
- 対象データが存在しない場合
以下のテーブルとデータで、それぞれのロック例を確認していきます。
> CREATE TABLE `test_non_unique_name` (
`id` int(11) NOT NULL,
`name` varchar(32) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `non_uniq_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
> INSERT INTO `test_non_unique_name` (`id`, `name`, `age`) VALUES (1, 'sato', 21), (2, 'takagi', 25), (3, 'suzuki', 30), (4, 'tomita', 27), (5, 'tanaka', 32), (6, 'ukita', 20);
> SELECT * FROM `test_non_unique_name` ORDER BY `name`;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | sato | 21 |
| 3 | suzuki | 30 |
| 2 | takagi | 25 |
| 5 | tanaka | 32 |
| 4 | tomita | 27 |
| 6 | ukita | 20 |
+----+--------+-----+
2-1-2-2-1. type=ref の場合のロック例
ポイントは、セカンダリインデックス non_uniq_name がユニークKEY ではない点です。
なぜロックをかける必要があるかと言うと、例え対象データが存在していたとしても、トランザクション中に同値で INSERT される可能性があるからです。
> BEGIN;
> SELECT * FROM `test_non_unique_name` WHERE name = 'takagi' FOR UPDATE;
上記のような SQL を実行した時、トランザクションログを見ると、以下のロックがかかっていることが分かります。
---TRANSACTION 6557031, ACTIVE 5 sec
4 lock struct(s), heap size 1184, 3 row lock(s)
MySQL thread id 1438, OS thread handle 0x7f11b8b7f700, query id 15625 172.19.0.1 root
TABLE LOCK table `test`.`test_non_unique_name` trx id 6557031 lock mode IX
RECORD LOCKS space id 5118 page no 4 n bits 80 index `non_uniq_name` of table `test`.`test_non_unique_name` trx id 6557031 lock_mode X
Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 6; hex 74616b616769; asc takagi;;
1: len 4; hex 80000002; asc ;;
RECORD LOCKS space id 5118 page no 3 n bits 80 index `PRIMARY` of table `test`.`test_non_unique_name` trx id 6557031 lock_mode X locks rec but not gap
Record lock, heap no 3 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
0: len 4; hex 80000002; asc ;;
1: len 6; hex 0000006409b0; asc d ;;
2: len 7; hex d9000001a3011d; asc ;;
3: len 6; hex 74616b616769; asc takagi;;
4: len 4; hex 80000019; asc ;;
RECORD LOCKS space id 5118 page no 4 n bits 80 index `non_uniq_name` of table `test`.`test_non_unique_name` trx id 6557031 lock_mode X locks gap before rec
Record lock, heap no 6 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 6; hex 74616e616b61; asc tanaka;;
1: len 4; hex 80000005; asc ;;
-
non_uniq_nameインデックスの 'takagi' レコードをネクストキーロック -
PRIMARYインデックス(PK)の 'takagi' レコードをレコードロック -
non_uniq_nameインデックス の 'tanaka' レコードをギャップロック
図にするとこんな感じです。
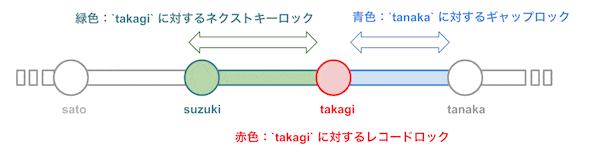
つまり、文章で表すと、「'suzuki' 以上 'tanaka' 未満のデータにロックがかかっている」状態です。
実際に、ロックの状態を別トランザクションで確認してみます。
-- 'suzuki' の直前にはロックがかかっていないことを確認
mysql> INSERT INTO `test_non_unique_name` (name, age) VALUES ('suzukh', 2); -- 'suzuki' の一文字前。最後 `i -> h` にしてある
Query OK, 1 row affected (0.00 sec)
-- 'suzuki' にロックがかかっていることを確認
mysql> INSERT INTO `test_non_unique_name` (name, age) VALUES ('suzuki', 2);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
-- 'tanaka' の直前にロックがかかっていることを確認
mysql> INSERT INTO `test_non_unique_name` (name, age) VALUES ('tanak', 2); -- 'tanaka' の一文字前。最後の 'a' を抜いている
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
-- 'tanaka' にはロックがかかっていないことを確認
mysql> INSERT INTO `test_non_unique_name` (name, age) VALUES ('tanaka', 2);
Query OK, 1 row affected (0.00 sec)
2-1-2-2-2. 対象データが存在しない場合のロック例
> BEGIN;
> SELECT * FROM `test_non_unique_name` WHERE name = 'tamaki' FOR UPDATE;
存在していない name 列値に対して SQL を実行すると、以下のロックがかかっていることが分かります。
---TRANSACTION 6557036, ACTIVE 7 sec
2 lock struct(s), heap size 360, 1 row lock(s)
MySQL thread id 1438, OS thread handle 0x7f11b8b7f700, query id 15693 172.19.0.1 root
TABLE LOCK table `test`.`test_non_unique_name` trx id 6557036 lock mode IX
RECORD LOCKS space id 5118 page no 4 n bits 80 index `non_uniq_name` of table `test`.`test_non_unique_name` trx id 6557036 lock_mode X locks gap before rec
Record lock, heap no 6 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 6; hex 74616e616b61; asc tanaka;;
1: len 4; hex 80000005; asc ;;
-
non_uniq_nameインデックスの 'tanaka' レコードをギャップロック
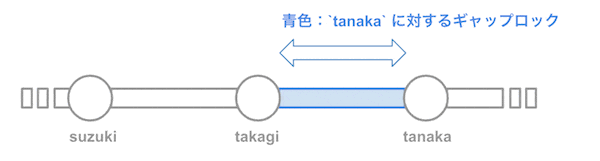
文章で表すと、「'takagi' を超えて 'tanaka' 未満のデータにロックがかかっている」状態です。
こちらも実際に、ロックの状態を別トランザクションで確認してみます。
-- 'takagi' にはロックがかかっていないことを確認
mysql> INSERT INTO `test_non_unique_name` (name, age) VALUES ('takagi', 2);
Query OK, 1 row affected (0.00 sec)
-- 'takagi' の直後にロックがかかっていることを確認
mysql> INSERT INTO `test_non_unique_name` (name, age) VALUES ('takagj', 2); -- 'takagi' の一文字後。最後を 'i' -> 'j' にしてある
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
-- 'tanaka' の直前にロックがかかっていることを確認
mysql> INSERT INTO `test_non_unique_name` (name, age) VALUES ('tanak', 2); -- 'tanaka' の一文字前。最後の 'a' を抜いている
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
-- 'tanaka' にはロックがかかっていないことを確認
mysql> INSERT INTO `test_non_unique_name` (name, age) VALUES ('tanaka', 2);
Query OK, 1 row affected (0.00 sec)
2-1-2-2-3. (おまけ) ちょっと不思議な supremum へのロック例
supremum に対してロックをかけると、ログ上はネクストキーロックですが、ギャップロックになるようです。
最後尾のデータ以降に対して、FOR UPDATE をかけてみると...
> BEGIN;
> SELECT * FROM `test_non_unique_name` WHERE name = 'watanabe' FOR UPDATE;
---TRANSACTION 6555909, ACTIVE 3 sec
2 lock struct(s), heap size 360, 1 row lock(s)
MySQL thread id 64, OS thread handle 0x7f11b876f700, query id 3547 172.19.0.1 root
TABLE LOCK table `test`.`test_non_unique_name` trx id 6555909 lock mode IX
RECORD LOCKS space id 4689 page no 4 n bits 80 index `non_uniq_name` of table `test`.`test_non_unique_name` trx id 6555909 lock_mode X
Record lock, heap no 1 PHYSICAL RECORD: n_fields 1; compact format; info bits 0
0: len 8; hex 73757072656d756d; asc supremum;;
ログ上は、なぜか、supremum に対してのネクストキーロックになっていますが...
実際には、ギャップロックがかかっています。(いや、目的上は正しいのでいいんですが...)
文章で表すと、「'ukita' を超えて以降全てのデータにロックがかかっている」状態です。
ロックの状態を別トランザクションで確認してみます。
-- 'ukita' にはロックがかかっていないことを確認
mysql> INSERT INTO `test_non_unique_name` (name, age) VALUES ('ukita', 2);
Query OK, 1 row affected (0.00 sec)
-- 'ukita' の直後にロックがかかっていることを確認
mysql> INSERT INTO `test_non_unique_name` (name, age) VALUES ('ukitb', 2); -- 'ukita' の一文字後。最後を 'a' -> 'b' にしてある
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
さっきも書いたとおり、目的上は正しいので全然問題ないのですが、ログを見て「あれ??」と思ったので、忘れないための単なるメモです。
3. 設定系
3-1. クエリキャッシュ
ソシャゲは更新が多いので、クエリキャッシュのヒット率が低いことが多く、メモリが無駄ですし、更新時にグローバルなロックを取得するので OFF にしておいた方がいいかもしれません。
[mysqld]
query_cache_type = 0
ちなみに、MySQL 5.6.8 からはデフォルトでOFFになりました。
MySQL 5.6 Reference Manual - サーバーのデフォルト値への変更
3-1-1. キャッシュ HIT 率の求め方
サーバーステータス変数(GLOBAL STATUS)の以下の値を使用します。
- QCACHE HITS ... クエリキャッシュの HIT 数 (※1)
- COM SELECT ... SELECT ステートメント実行数 (※2)
※1 + ※2 が総 SELECT 実行数ということになるので、※1 ÷ (※1 + ※2) で HIT 率が算出できることになります。
SELECT Qcache_hits.VARIABLE_VALUE / (Qcache_hits.VARIABLE_VALUE + Com_select.VARIABLE_VALUE) * 100 AS 'キャッシュHIT率(%)' FROM
(SELECT VARIABLE_VALUE FROM information_schema.GLOBAL_STATUS WHERE VARIABLE_NAME = 'QCACHE_HITS') AS Qcache_hits,
(SELECT VARIABLE_VALUE FROM information_schema.GLOBAL_STATUS WHERE VARIABLE_NAME = 'COM_SELECT') AS Com_select;
ちなみに、サーバーステータス変数の確認方法はコチラを参照してください。
GLOBAL VARIABLE と GLOBAL STATUS を確認する方法あれこれ
3-1-2. (メモ) INSERTによってクエリキャッシュが消える検証
参考までに INSERT によってクエリキャッシュが消えることを確認した時のメモを貼っておきます。
-- SELECT ステートメントを実行することによってクエリキャッシュに乗せる
> SELECT `name`, `age` FROM `test_unique_name` WHERE `name` = 'sato';
> SELECT `name`, `age` FROM `test_unique_name` WHERE `name` = 'tanaka';
-- クエリキャッシュに乗ったことを確認
> SHOW STATUS LIKE 'Qcache_queries_in_cache';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| Qcache_queries_in_cache | 2 |
+-------------------------+-------+
-- クエリキャッシュと関係ないデータをINSERT
> INSERT INTO `test_unique_name` (`name`, `age`) values ('test', 1);
-- クエリキャッシュが消えたことを確認
> SHOW STATUS LIKE 'Qcache_queries_in_cache';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| Qcache_queries_in_cache | 0 |
+-------------------------+-------+
3-2. ページサイズ
ページサイズは、MySQL 5.5 までは 16KB 固定でしたが、SSD が増えてきた5こともあり、細かく設定できるようになりました。
MySQL 5.6 から 4KB、8KB、16KB が、MySQL 5.7.6 からは 32KB、64KB もサポートされるようになっています。
ソシャゲでは、大量データの一括 UPDATE はあまりなく、テーブルレコードも少なめ。ページサイズが大きいとバッファプールを無駄に圧迫するので、4KB でいいことが多いかと思います。
ですが、1レコードの最大サイズは『ページサイズの 1/2』になるため、1レコードに大きなデータを保存するテーブルが存在してしまう場合は注意が必要です。
(デフォルトの 16KB だと、1レコード最大サイズは 8KB。『8KBの壁』で有名)
innodb_page_size=4k
ページサイズの変更は、インスタンス作成時のみ可能です。
インスタンス作成後、後からページサイズを変更することや、テーブル単位でページサイズを変更することはできません。
3-3. バッファプール
データが、バッファプールに乗っているかどうかで取得速度は大幅に変わります。
デフォルトだと再起動時にバッファプールはクリアされますが、ソシャゲの場合、メンテ明け直後など、ただでさえアクセスが集中しがちなので再起動してもバッファプールが引き継がれるようにした方がいいかもしれません。
[mysqld]
:
innodb_buffer_pool_dump_at_shutdown = 1
innodb_buffer_pool_load_at_startup = 1
ちなみに、MySQL 5.7.7 以降はデフォルトで引き継がれるようになっています。
MySQL 5.7 Reference Manual - InnoDB Startup Options and System Variables
3-4. slow query log
インデックスが適切ではない場合、データ量が多くなるにつれて、SQL 実行速度が遅くなっていきます。
それを察知することが出来るので、ON にしておくのは重要です。
ファイルに出力することも出来ますが、本番サーバの場合、ssh でログインして確認する必要が発生します。(ファイルをどこかに流す仕組みを作っていなければ)
テーブル出力の方が、緊急時なども即座に確認できるので好みです。
[mysqld]
:
slow_query_log = 1
log_output = TABLE # mysql.slow_log テーブルに格納される
long_query_time = 0.1 # 0.1 秒以上かかった SQL を検出
蛇足ですが、1回の SQL は速いのに、ロジックのループで SQL 実行回数が多くなってしまっている場合は全く察知できないので、Newrelic などのアプリケーション監視ツールも重要です。
4. Tips
4-1. テーブルデータを最適化する
MySQL は、レコードを削除(DELETE ステートメントの実行)しても実データサイズは小さくなりません。
実データ上は残ったままなので、削除→登録が頻繁に行われるテーブルは、フラグメンテーションが発生しまくってパフォーマンスに影響が出る可能性があります。
4-1-1. フラグメンテーションが多く発生しているテーブルの見つけ方
information_schema の TABLES テーブルに、data_free カラムがあり、ここで「割り当てられているのに未使用のデータサイズ」が分かります。
つまり、data_free カラムの値が大きいテーブルがフラグメンテーションしていると考えられます。
SELECT
table_schema,
table_name,
sys.format_bytes(data_free) AS '割り当て済未使用データサイズ'
FROM information_schema.tables
ORDER BY data_free DESC
LIMIT 10;
4-1-2. 最適化を行う方法
最適化を行うには、以下の SQL を実行します。
OPTIMIZE TABLE table_name;
これにより、実データからも削除され、フラグメンテーションも解消されます。
4-2. mysql-sys
information_schema データベースの各テーブル値を見やすく整形してくれる VIEW です。
色々と便利な VIEW がありますが、テーブルのデータサイズはよく確認するので、sys.format_bytes() プロシージャだけでも使用する価値はあるかなと思います。
MySQL 5.7 からは標準バンドルされていますが、5.6 以前の場合は以下の手順で sys データベースが作られ、その中に VIEW とプロシージャが作られます。
$ cd /tmp
$ git clone https://github.com/mysql/mysql-sys.git
$ cd mysql-sys/
$ mysql -u root -p < ./sys_56.sql
-
ちなみに、他の DB はどうなっているかと言うと、例えば Oracle は、全てのインデックスのリーフノードに ROWID がセットされていて、該当する ROWID を使ってデータを取得することができるようになっているので速度差はありません。 ↩
-
Using where;と表示されているのは、使用されたインデックスが Unique Key ではないからなので気にしないでください... ↩ -
セカンダリインデックスを追加した直後はサイズが反映されません。その場合は
OPTIMIZE TABLE [table name];を実行してください。 ↩ -
ある程度データ量がないと、オプティマイザが全件走査の方が速いと判断して、意図したインデックスを使わないことがありますので注意してください。その場合、どうしてもインデックスを使用させたい場合はヒント句を使うのもいいかもしれません。 ↩
-
ランダムアクセス時の速度の問題です。HDD はシークタイムがあるので低速ですが、SDD は電気信号でサーチするので高速です。 ↩