これまでの踏跡
目次
全体設計のまとめ
出力プログラムの微修正
手修正品を評価するプログラム
手修正プログラムの結果
プログラム全容
全体設計のまとめ
今回設計したプログラムの基本運用手段は下図のようなものである
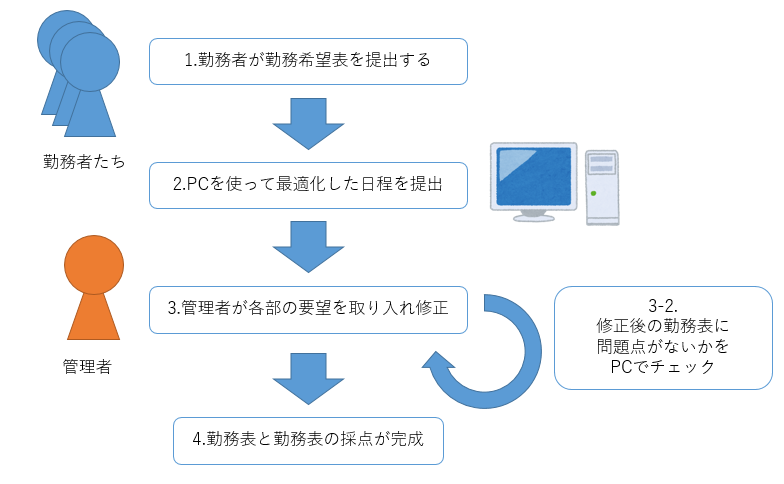
そして、これまでのプログラムは基本的に2.の部分を作ってきた。
今回は2.の部分の最終調整並びに4.の部分をメインに作成する。
4.まで行くとpulpにはあんまり関係がなくなっているが、まあ、後工程も含めて組合せ最適化と呼んでも差し支えはないだろう。知らんけど。
出力プログラムの微修正
まず、プログラムに放り込んだ勤務希望表は下記のようなものである。
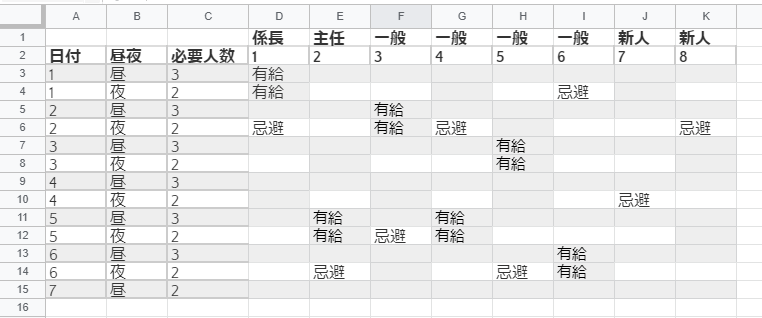
表1 勤務希望表
また、これまではプログラムでの容易さを重視して数値で大半を表していたが、現場で使うときには言語にしないと使いにくいので変更。
また、出力された際に実働だけでなく希望がどうだったかも併記したほうがシフト作成者が修正しやすい。
よって、下記のような表が出力されるように微調整を行った。
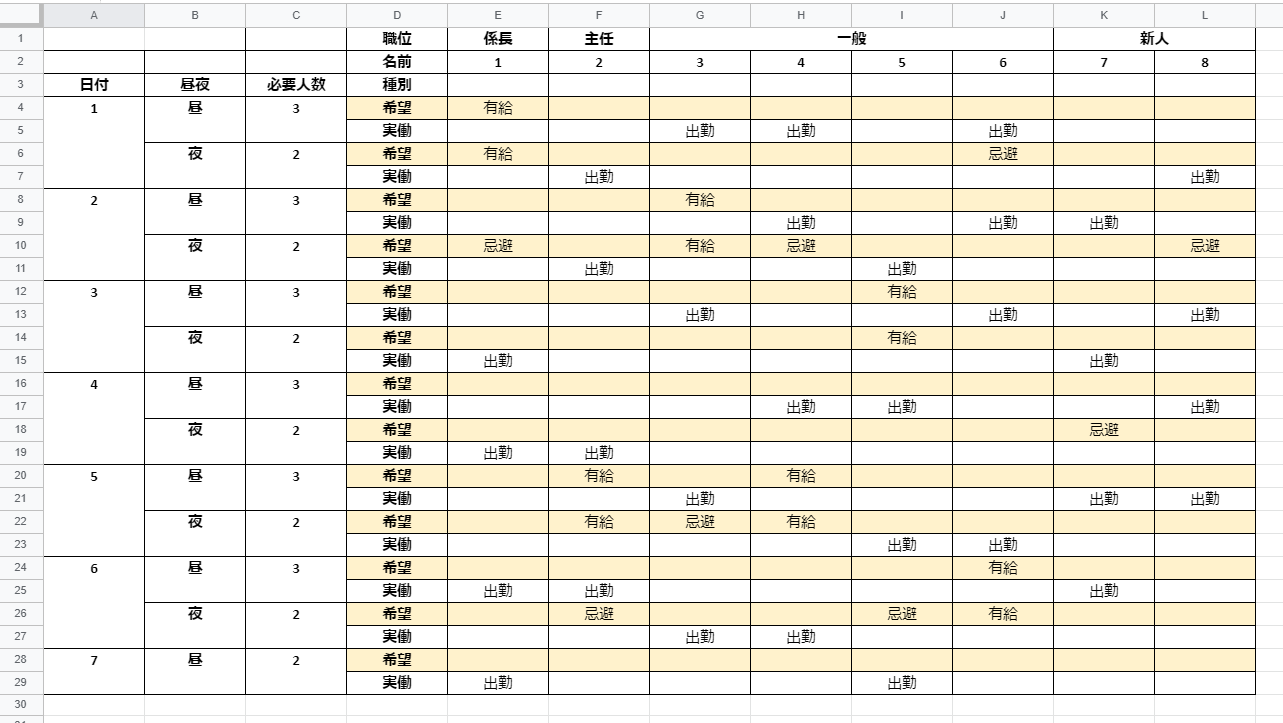
表2:勤務希望表を組合せ最適化プログラムに入れて出力されるもの
そして、今回はそれを管理者が手修正することを前提にしており、手修正後の表が下表となる。
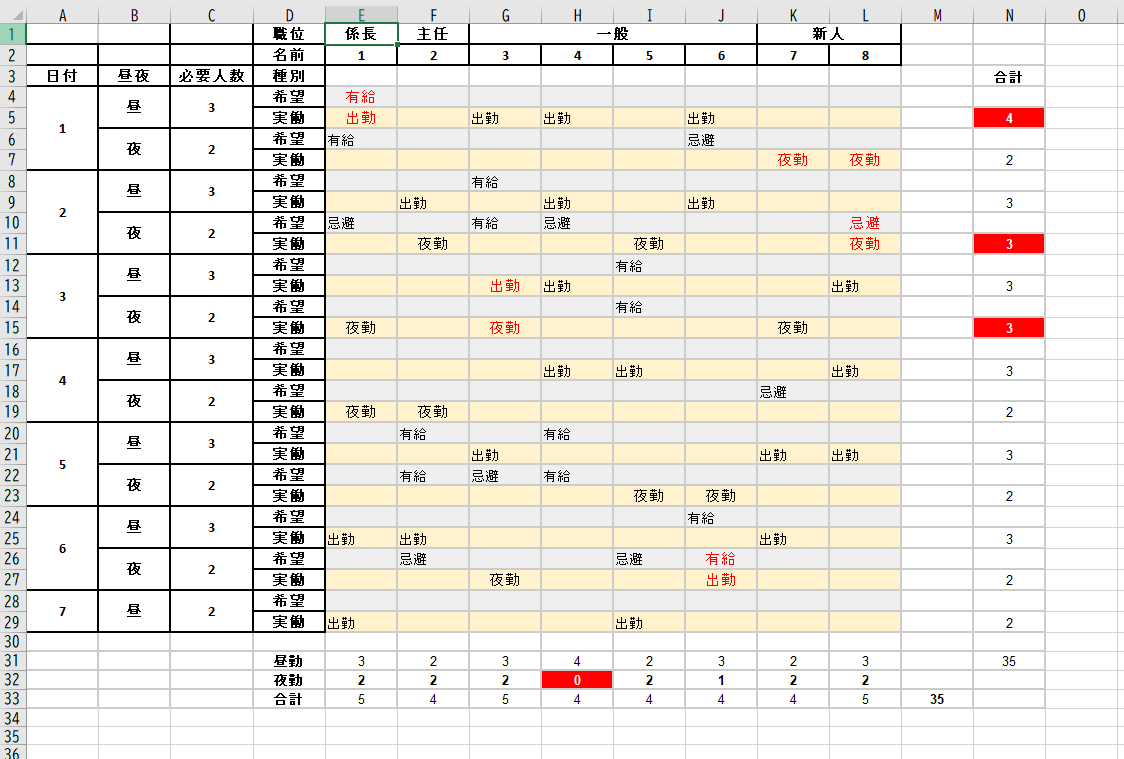
表3:管理者が直した表
昼勤夜勤の合計値や色分けは視認性を上げるために後から追加したものである。
この管理者の手直し表には問題をなるべく多数含むようにしてあり、
・出勤数が多すぎるシフトがある(必要数3のところに4人いるなど)
・夜勤してない勤務者がいる
・新人だけでシフトを埋めてしまったところがある
・有給、忌避の要望が無視されている
・連続勤務が発生している
の5つの問題を起こしている。
で、最終的にこれらの問題点をきっちり評価し、ここに問題がありますよということを指摘できればプログラム作成としての仕事は終わりである。
実際、AさんとBさんが同じシフトに入るのはマズい、などは管理者側で調整いただこう。
手修正品を評価するプログラム
マルチインデックスの処理をするだけなので、工夫したところだけ抜粋する
# 元表の段組みが多いので、まずは労務希望について除外したdataframeを作る
df_working=df_raw.groupby(["種別"]).get_group("実働")
# 分類欄が増えたのでリストも改定
list_danc = df_working.index.to_list()
list_pm = df_working.columns.to_list()
# リスト内タプルは「N個目の配列のM個目の数字を取り出す」事が大変なので、リスト内リストに変換する
list_danc=list(map(list,list_danc))
list_pm=list(map(list,list_pm))
このリスト内タプルをリスト内リストに変換する作業は、後で検証したら特に不要だった。
無くてもよいが、リスト内タプルは要素の追加と取り出しでエラーが起きた覚えがあるので、将来的な事を考えて変換したままにしておく。
# 各制約、目的に対して集計を取り、問題がないかどうかチェックする
# 出勤回数の過不足をチェックするため、まずは必要出勤回数をseriesで取得
sr_needs = df_working.reset_index(level=2).iloc[:,0].reset_index(drop=True)
# dataframeの行ごとの"出勤"の出現数の総和をSeries型で抜き取る
sr_count = (df_working=="出勤").sum(axis=1).reset_index(drop=True)
# 理想値かどうか確認
sr_compare = (sr_needs==sr_count)
# 全てTrueなら問題なし。
if sr_compare.all() == True:
print(f"出勤回数は最小値の{sr_count.sum()}回です")
# Falseが残っているなら、対象の行を取得する
else:
list_false = list(sr_compare[sr_compare==False].index)
for i in list_false:
false_day = list_danc[i][0]
false_act = list_danc[i][1]
print(f"{false_day}日目の{false_act}の出勤回数は最小回数を{sr_count[i]-sr_needs[i]}回上回っています")
特に言うことはないが、マルチインデックスのindex列をそのまま抜き取りたい、と言うときは、
reset_indexで抜き取った列が0列目に入ることを利用してilocで抜き取ると比較的スムーズ。
# 新人だけでシフトが埋まっていないかをチェックする
# まずは新人だけ抜き取ったdataframeを作る
df_newbe = df_working.groupby(["職位"],axis=1).get_group("新人")
# 各シフトごとの新人の出勤回数和をseriesにする
sr_newbe = (df_newbe=="出勤").sum(axis=1).reset_index(drop=True)
# 行ごとの出勤総和と新人の出勤回数和が同じなら、新人だけでシフトを埋めていることになる
# 例:1日夜の出勤回数総和が2で、新人の総和も2など。よって、!=で全てTrueならば良しとする
sr_compare2 = sr_newbe!=sr_count
if sr_compare2.all() == True:
print(f"OK! 新人だけで埋まっているシフトはありません")
# Falseが残っているなら、対象の行を取得する
else:
list_false2 = list(sr_compare2[sr_compare2==False].index)
for i in list_false2:
false_day = list_danc[i][0]
false_act = list_danc[i][1]
print(f"Caution! {false_day}日目の{false_act}は新人だけでシフトを埋めています")
最初にindexをlist化しておくと、N行目で問題が在った、という情報さえあればfor N in list_indexで
簡単に必要な項目が取り出せるので気楽。
夜勤0回のチェックや、最多-最少出勤差などは上記例から簡単に作れるので割愛
# 有給と忌避の希望が潰された人がいるかどうかのチェック
# まず種別が希望となっているリストを作る
df_wish=df_raw.groupby(["種別"]).get_group("希望")
# 全データを一意に取り出したいので、stack()を使って整形する
df_wish =df_wish.stack(level=[0,1])
df_yukyu = df_wish[df_wish=="有給"]
list_yukyu = df_yukyu.index.to_list()
# 有給リストの「希望」を全部実働に書き換える
for i in range(len(list_yukyu)):
list_yukyu[i][3] = "実働"
# 有給を出していたけど実働が「出勤」になっている場合はコメントを出力
for d,a,n,c,p,m in list_yukyu:
A= df_working.at[(d,a,n,c),(p,m)]
if A=="出勤":
print(f"Alert! 勤務者{m}は{d}日目の{a}に有給が却下されています")
ポイントになるのはstack()の扱いで、マルチインデックスの行ラベルを全てスタックすると、縦に長い一意の値を全て取り出せる。
視認性は悪くなるが、マルチインデックスの値からその時のインデックスとカラムを抜き取りたいときはだいたいこの処理でなんとかなる。
# 連続勤務のチェック
# 窓関数と.countを使って「縦に2個連続で出勤している箇所」を割り出す
df_continuous = df_working.rolling(2).count()
# 値が2となっていれば直前シフトと連続勤務になっていることを表す
df_continuous=df_continuous.stack(level=[0,1])
list_continuous = (df_continuous[df_continuous==2]).index.to_list()
list_continuous=list(map(list,list_continuous))
if df_continuous.all()<=1:
print("OK! 連続勤務に問題はありません")
else:
for d,a,n,c,p,m in list_continuous:
print(f"Caution! 勤務者{m}は{d}日目の{a}とその直前シフトが連続しています。修正ください")
連続勤務のチェックをする場合は、窓関数で全部countすればいいことに気づいたので、
ここがぐっと楽に終わってよかった。
.rolling(2).count()だと、0行0列には「"0行0列"+”0行-1列"」の個数データが入る。
-1列は存在しないため、0個扱いになるのが通常のdataframeと違うところ。
※dataframeに[-1]を指定すると、通常は最後尾になる。
手修正プログラムの結果
こんな感じで最終的にチェックをすると、下記のような出力が得られる。

・出勤数が多すぎるシフトがある(必要数3のところに4人いるなど)
・夜勤してない勤務者がいる
・新人だけでシフトを埋めてしまったところがある
・有給、忌避の要望が無視されている
・連続勤務が発生している
細かい表示調整などはしていないのでやや見づらいが、上記5点の問題は全てチェックされている。
また、組合せ最適化で自動生成したものをそのまま放り込んだら、「全て問題なし」と出力された。
後はもう現場とすり合わせで微調整していくだけなので、ひとまずこれにて完成。
めでたしめでたし。
ただ、完全に個人制作なので可読性と引き継ぎに問題が在っては困るので、後日にでも質問コーナーにて意見をもらおうと思う。
プログラム全容
import openpyxl
import pandas as pd
import numpy as np
import pulp
df_raw= pd.read_excel("/input.xlsx",index_col=[0,1,2],header=[0,1])
df_origin=df_raw.copy()
df_raw.rename(index={"昼":0,"夜":1},level=1,inplace=True)
df_raw.rename(columns={"係長":1,"主任":2,"一般":0,"新人":3},level=0,inplace=True)
df_raw.replace({np.NaN:0,"忌避":1,"有給":2},inplace=True)
df_raw.index.set_names(["date","action","needs"],inplace=True)
df_raw.columns.set_names(["position","member"],inplace=True)
list_dan = df_raw.index.to_list()
list_pm = df_raw.columns.to_list()
# 問題の定義
ShiftScheduling = pulp.LpProblem("ShiftScheduling", pulp.LpMinimize)
# 変数宣言
# x[p,m,d,a]で全パターンの0-1変数を作成する
x = {}
for p,m in list_pm:
for d,a,n in list_dan:
x[p,m,d,a] = pulp.LpVariable("x({:},{:},{:},{:})".format(p,m,d,a), 0, 1, pulp.LpInteger)
# 目的関数1 全員の出勤の合計値が小さい方が良い=全変数の総和が小さい方が良い
obj1= pulp.lpSum(x)
# 目的関数2 夜勤忌避の希望が通る方が良い
list_yakin=[]
for p,m in list_pm:
df_yakin = df_raw[df_raw.loc[:,(p,m)]==1]
for i in range(len(df_yakin)):
da_yakin = df_yakin.index
list_temp = [p,m,da_yakin[i][0],da_yakin[i][1]]
list_yakin.append(list_temp)
obj2 = pulp.lpSum(x[p,m,d,a] for p,m,d,a in list_yakin)
# 目的関数3 有給の希望が通る方が良い
list_yukyu=[]
for p,m in list_pm:
df_yukyu = df_raw[df_raw.loc[:,(p,m)]==2]
for i in range(len(df_yukyu)):
da_yukyu = df_yukyu.index
list_temp = [p,m,da_yukyu[i][0],da_yukyu[i][1]]
list_yukyu.append(list_temp)
obj3 = pulp.lpSum(x[p,m,d,a] for p,m,d,a in list_yukyu)
# 目的関数4 勤務者間の労働回数はなるべく近いほうが良い
# 勤務の最大回数を用いる。計算は後でするので先に変数を一個作っておく。
obj4 = pulp.LpVariable("workcount",lowBound=0)
# 目的関数の定義
ShiftScheduling += obj1 + obj2*10 +obj3 + obj4
# 制約条件
# 制約条件1:全員必ず3回以上出勤
# 制約条件4:勤務回数の偏りを減らす(最大値がobj4に格納されるようにする)
for p,m in list_pm:
ShiftScheduling += pulp.lpSum(x[p,m,d,a] for d,a,n in list_dan) >= 3
ShiftScheduling += pulp.lpSum(x[p,m,d,a] for d,a,n in list_dan) <= obj4
# 制約条件2:全シフトで必要人数以上出勤
for d,a,n in list_dan:
ShiftScheduling += pulp.lpSum(x[p,m,d,a] for p,m in list_pm) >= n
# 制約条件3:連続出勤不可
list_da1 = list_dan[:-1]
list_da2 = list_dan[1:]
for i in range(len(list_da1)):
list_da1[i]=list_da1[i]+list_da2[i]
for p,m in list_pm:
for d1,a1,n1,d2,a2,n2 in list_da1:
ShiftScheduling += x[p,m, d1, a1]+x[p,m,d2,a2] <=1
# 制約条件5:夜勤一回以上
df_yakin_min = df_raw.groupby(["action"]).get_group(1)
list_yakin_min = df_yakin_min.index.to_list()
for p,m in list_pm:
ShiftScheduling += pulp.lpSum(x[p,m,d,a] for d,a,n in list_yakin_min) >=1
# 制約条件6:新人だけでシフトを埋めてはいけない
df_newbe = df_raw.groupby(["position"],axis=1).get_group(3)
list_newbe = df_newbe.columns.to_list()
for d,a,n in list_dan:
ShiftScheduling += pulp.lpSum(x[p,m,d,a] for p,m in list_pm) >= pulp.lpSum(x[p,m,d,a] for p,m in list_newbe)+1
# 出力
results = ShiftScheduling.solve()
print("optimality = {:}, target value = {:}".format(pulp.LpStatus[results], pulp.value(ShiftScheduling.objective)))
df_results=df_raw.copy()
dict_x = ShiftScheduling.variablesDict()
for d,a,n in list_dan:
for p,m in list_pm:
keys_pmda = "x({},{},{},{})".format(p,m,d,a)
values_pmda=dict_x[keys_pmda]
r =pulp.value(values_pmda)
df_results.at[(d,a,n),(p,m)]=r
# 結果ファイルの言語化
df_results.rename(index={0:"昼",1:"夜"},level=1,inplace=True)
df_results.rename(columns={1:"係長",2:"主任",0:"一般",3:"新人"},level=0,inplace=True)
df_results.replace({0:"",1:"出勤"},inplace=True)
df_results.index.set_names(["日付","昼夜","必要人数"],inplace=True)
df_results.columns.set_names(["職位","名前"],inplace=True)
df_results["種別"]="実働"
df_results.set_index("種別",inplace=True,append=True)
df_origin.index.set_names(["日付","昼夜","必要人数"],inplace=True)
df_origin.columns.set_names(["職位","名前"],inplace=True)
df_origin.replace(np.nan,"",inplace=True)
df_origin["種別"]="希望"
df_origin.set_index("種別",inplace=True,append=True)
# 希望欄と実働欄を分けて作った後、一個の表として合体
df_results = df_results.append(df_origin)
df_results = df_results.sort_index(level=[0,1,3],ascending=[1,0,0])
df_results.to_excel("/output.xlsx")
import openpyxl
import pandas as pd
import numpy as np
df_raw= pd.read_excel("/output.xlsx",index_col=[0,1,2,3],header=[0,1])
# 最後にCautionとAlertの数を通知するため、先に変数を準備
x_caution=0
x_alert=0
# 前準備として、労務希望を除外したdataframeを作り、indexとcolumnsもリスト化する
df_working=df_raw.groupby(["種別"]).get_group("実働")
list_danc = df_working.index.to_list()
list_pm = df_working.columns.to_list()
# リスト内タプルをリスト内リストに変換する(無くても動く)
list_danc=list(map(list,list_danc))
list_pm=list(map(list,list_pm))
# 各制約、目的に対して集計を取り、問題がないかどうかチェックする
# 1.出勤回数をカウントし、過不足をチェックする
sr_needs = df_working.reset_index(level=2).iloc[:,0].reset_index(drop=True)
sr_count = (df_working=="出勤").sum(axis=1).reset_index(drop=True)
# 理想値かどうか確認
sr_compare = (sr_needs==sr_count)
if sr_compare.all() == True:
print(f"OK! 出勤回数は最小値の{sr_count.sum()}回です")
else:
list_false = list(sr_compare[sr_compare==False].index)
for i in list_false:
false_day = list_danc[i][0]
false_act = list_danc[i][1]
print(f"{false_day}日目の{false_act}の出勤回数は最小回数を{sr_count[i]-sr_needs[i]}回上回っています")
# 新人だけでシフトが埋まっていないかをチェックする
df_newbe = df_working.groupby(["職位"],axis=1).get_group("新人")
sr_newbe = (df_newbe=="出勤").sum(axis=1).reset_index(drop=True)
sr_compare2 = sr_newbe!=sr_count
if sr_compare2.all() == True:
print(f"OK! 新人だけで埋まっているシフトはありません")
else:
list_false2 = list(sr_compare2[sr_compare2==False].index)
for i in list_false2:
false_day = list_danc[i][0]
false_act = list_danc[i][1]
print(f"Caution! {false_day}日目の{false_act}は新人だけでシフトを埋めています!修正ください")
x_caution =x_caution+1
# 勤務者の最多出勤回数と最小出勤回数を比較する
sr_eachcount = (df_working=="出勤").sum(axis=0).reset_index(drop=True)
print(f"最多出勤者と最少出勤者の出勤回数の差は{sr_eachcount.max()-sr_eachcount.min()}回でした")
# 夜勤0回の人はいるかどうかのチェック
df_noyakin = df_working.groupby(["昼夜"],axis=0).get_group("夜")
sr_noyakin = (df_noyakin=="出勤").sum(axis=0).reset_index(drop=True)
if sr_noyakin.all() >=1 :
print("OK! 全員が夜勤に1回以上出ています")
else:
list_noyakin = list(sr_noyakin[sr_noyakin == 0].index)
for i in list_noyakin:
false_member = list_pm[i][1]
print(f"Caution! 勤務者名:{false_member}は夜勤に出ていません!修正を推奨します")
x_caution =x_caution+1
# 有給と忌避の希望が潰された人がいるかどうかのチェック
df_wish=df_raw.groupby(["種別"]).get_group("希望")
# 全データを一意に取り出したいので、stack()を使って整形する
df_wish =df_wish.stack(level=[0,1])
df_yukyu = df_wish[df_wish=="有給"]
list_yukyu = df_yukyu.index.to_list()
list_yukyu=list(map(list,list_yukyu))
# 有給リストの「希望」を全部実働に書き換える
for i in range(len(list_yukyu)):
list_yukyu[i][3] = "実働"
# 有給を出していたけど実働が「出勤」になっている場合はコメントを出力
for d,a,n,c,p,m in list_yukyu:
A= df_working.at[(d,a,n,c),(p,m)]
if A=="出勤":
print(f"Alert! 勤務者{m}は{d}日目の{a}に有給が却下されています")
x_alert = x_alert+1
# 夜勤忌避も同じことをする
df_kihi = df_wish[df_wish=="忌避"]
list_kihi = df_kihi.index.to_list()
list_kihi=list(map(list,list_kihi))
for i in range(len(list_kihi)):
list_kihi[i][3] = "実働"
for d,a,n,c,p,m in list_kihi:
A= df_working.at[(d,a,n,c),(p,m)]
if A=="出勤":
print(f"Alert! 勤務者{m}は{d}日目の{a}に夜勤忌避が却下されています")
x_alert = x_alert+1
# 連続勤務のチェック
# 窓関数と.countを使って「縦に2個連続で出勤している箇所」を割り出す
df_continuous = df_working.rolling(2).count()
# あとは有給と同じようにstackで整形してからdancpmを抜き取り、注意文を作れば完成
df_continuous=df_continuous.stack(level=[0,1])
list_continuous = (df_continuous[df_continuous==2]).index.to_list()
list_continuous=list(map(list,list_continuous))
if df_continuous.all()<=1:
print("OK! 連続勤務に問題はありません")
else:
for d,a,n,c,p,m in list_continuous:
print(f"Caution! 勤務者{m}は{d}日目の{a}とその直前シフトが連続しています。修正ください")
x_caution = x_caution+1
print("\n")
if x_caution == x_alert ==0:
print("シフト上の大きな問題はありませんでした")
if x_caution >=1:
print(f"チェックの結果、危険なシフト配置が{x_caution}個ありました。Caution!を確認ください")
if x_alert >=1:
print(f"チェックの結果、要望を満たせなかったシフト配置が{x_alert}個ありました。Alert!を確認ください")