はじめに
上記で作成したプログラムが改良できたので取りまとめる。
エクセル上に入力せず、python上で全部計算して結果だけエクセルに放り込めばいいんじゃね?
という、当たり前すぎる事に気づいたのでだいぶコンパクトになった気がする。
これまではopenpyxlを用いていたが、今回はpandasを使用。両者の差は未だによく分かっていない。
9/30 追記:コメント欄にて@nkay 様より本方式より洗練された方式が提示されたので、載せておきます。
出力はほぼ同じ(「区分+業務」列が追加生成されるのみ)。
import pandas as pd
df_master = pd.read_excel('/content/drive/My Drive/Colab Notebooks/table.xlsx')
df_test = pd.read_excel('/content/drive/My Drive/Colab Notebooks/data5.xlsx')
out = df_test.merge(df_master, on=['区分', '業務'], how='left')
out.to_excel('/content/drive/My Drive/Colab Notebooks/data6.xlsx', index=False)
成果
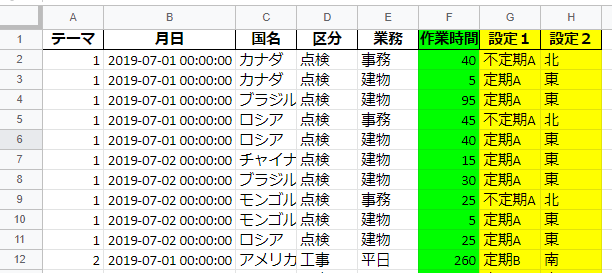
図:出力されたエクセル(色分けは後で塗った)
区分+業務の内容から設定1・設定2に該当するものを検索し、出力できているので良しとする。
最終提出時に不要になる無駄な行も無く、スッキリ。
https://qiita.com/wellwell3176/items/e6a17609c7398dd7d496
の図2と比べると、使い物になるレベルの出力がされているのがよく分かる。
import pandas as pd
df_master=pd.read_excel('/content/drive/My Drive/Colab Notebooks/table.xlsx')
df_test=pd.read_excel('/content/drive/My Drive/Colab Notebooks/data5.xlsx')
row_count=len(df_test.index) #for文のループ回数を決めるために表の長さを取得
for i in range(0,row_count): #.iterrowsは何故か上手く動かなかった
kubun = df_test.at[(i,"区分")]
gyomu = df_test.at[(i,"業務")]
kubun_gyomu=(df_master['区分'] == kubun) & (df_master["業務"] == gyomu) #区分と業務が一致する行をBoolで判定
row_true=df_master[kubun_gyomu] #データフレームの中からtrue行だけを抜き取り
set1_val=row_true.iat[0,3]
set2_val=row_true.iat[0,4] #設定1/2の位置は一意に定まるので位置は数値で指定。0行目”設定2”列みたいな事はできなかった。
# 変数が多すぎる気もするが、これくらい分割しないと後で何してるかさっぱりになりそうだったので分けた。
df_test.at[(i,"設定1")]=set1_val
df_test.at[(i,"設定2")]=set2_val #こっちの指定はi行目”設定2”列が可能。よく分からん。
df_test.to_excel('/content/drive/My Drive/Colab Notebooks/data6.xlsx',index=False)
作成中に見かけたエラーメッセージと失敗
ValueError: At based indexing on an integer index can only have integer indexers
for i in df_test.iterrows():
kubun = df_test.at[(i,"区分")]
gyomu = df_test.at[(i,"業務")]
-->ValueError: At based indexing on an integer index can only have integer indexers
#i=[0]から[データフレーム最終行数]まで、という指定で動いてくれるかと思ったが、ダメ
#理由はまだ分かっていない。iに整数値が入っていないらしいのだが・・・
#完成品のようにrange関数で長さを指定して解決した
.at[0,"hogehoge"]を使ったときのkey error
for i in range(0,45):
kubun = df_test.at[(i,"区分")] #テストファイルから区分の値を引っ張り出す
kubun_correct=(df_master['区分'] == kubun) #マスターファイルと検索して引っ掛ける
row_true=df_master[kubun_correct] #true行だけ引っ張り出す
set1_val=row_true.at[0,"設定1"] #trueを出した先頭行”設定1”列のデータを出そうとして、ここで引っかかった
df_test.at[(i,"設定1")]=set1_val #該当する設定1のデータをエクセルに代入したかった
-->key error 0
# 原因は.atが文字列参照だという点への不理解。i=10(区分=工事)のときにエラーが起きた。
# その時のprint(kubun_correct)の結果が下記
0 False
1 False
2 True
3 True
# print(row_true)すると下記のようになる
区分 業務 設定1 設定2
2 工事 平日 定期B 南
3 工事 休日 不定期B 北
# このとき、row_true.at[0,"設定1"]は、”0”行の”設定1”列を読み込みに行くが、0行はあるものの"0"行がないため参照不可
# よって、完成品のように.iatで0行3列を参照するようにして解決
参考文献
Pandas DataFrame のセルの値を取得する方法
https://www.delftstack.com/ja/howto/python-pandas/how-to-get-a-value-from-a-cell-of-a-dataframe/
Pandasで抽出したデータから値だけを取り出す方法
https://tipstour.net/python-pandas-get-value
pandasで複数条件のAND, OR, NOTから行を抽出(選択)
https://note.nkmk.me/python-pandas-multiple-conditions/