Deep Learningで猫の品種識別

('British_Shorthair', 0.22552991563514049),
('Abyssinian', 0.057159848358045016),
('Bombay', 0.043851502320485049),
('Egyptian_Mau', 0.030686072815385441)])]
OpenCVで猫検出では猫の顔検出をしましたが、今回はディープラーニングの技術を使って猫の品種を識別しようと思います。
技術的な内容詳細についてはブログの方に書いてありますので興味があれば。
- [ねこと画像処理 part 3 – Deep Learningで猫の品種識別] (http://rest-term.com/archives/3172/)

ここでは Deep Convolutional Neural Network (DCNN) と呼ばれる手法を一般物体認識に適用して猫の品種識別を行います。この領域の問題は Fine-Grained Visual Categorization (FGVC) と呼ばれていて、対象となるドメイン(今回は猫の品種)を絞って分類を行います。視覚的に似ているものを扱うため高い精度を出すのは難しいです。
実装
DCNNの実装はいくつかありますが、ここでは Caffe というライブラリを使います(※ ライブラリ自体はオープンソース BSD 2-Clause license ですが、ImageNetのデータは非商用なので注意)。DCNNの中間層(隠れ層)の出力を4096次元の特徴量として抽出、それを素性として適当な分類器を作って予測を行います。分類器は scikit-learn の実装を使うと楽かと思います。
ソースコードはGitHubに上げてありますので興味があればご参照ください。以下の処理を実装しています。
(ライブラリではなく殴り書きのコマンドラインツールです。。)
 cat-fancier/classifier at master · wellflat/cat-fancier
cat-fancier/classifier at master · wellflat/cat-fancier
- DCNNで特徴抽出 (出力はlibsvmテキスト形式かNumPyのnpyバイナリ形式)
- SVM/Logistic Regression/Random Forestで分類モデル作成 (マルチプロセスでGrid Search + Cross Validation)
- 精度評価 (precision/recall, f1-score, confusion matrix)
- Fine-tuning(ファインチューニング)用のネットワーク定義/ソルバー設定ファイル等
検証
オックスフォード大学が公開している動物画像のデータセットでベンチマークを取ってみます。

12クラスなので軽めのタスクになります。今回は学習用に1800枚、検証用に600枚使います。学習用画像は1クラスにつき150枚で少ないようにも思えますが、12クラス程度であればこの枚数でもそこそこの精度が出せます。データ数も少ないので安物のVPS上でグリッドサーチしても数十分程度で学習は終わります。ここではSVM-RBFでの分類結果だけ載せておきます。
## SVM RBF Kernel
SVC(C=7.7426368268112693, cache_size=200, class_weight=None, coef0=0.0,
degree=3, gamma=7.7426368268112782e-05, kernel='rbf', max_iter=-1,
probability=False, random_state=None, shrinking=True, tol=0.001,
verbose=False)
precision recall f1-score support
Abyssinian 0.84 0.91 0.88 47
Bengal 0.84 0.83 0.84 46
Birman 0.72 0.79 0.75 52
Bombay 0.98 0.98 0.98 46
British_Shorthair 0.82 0.75 0.78 53
Egyptian_Mau 0.87 0.87 0.87 61
Maine_Coon 0.87 0.89 0.88 45
Persian 0.85 0.91 0.88 45
Ragdoll 0.76 0.76 0.76 41
Russian_Blue 0.84 0.82 0.83 57
Siamese 0.81 0.69 0.75 55
Sphynx 0.94 0.96 0.95 52
avg / total 0.85 0.84 0.84 600
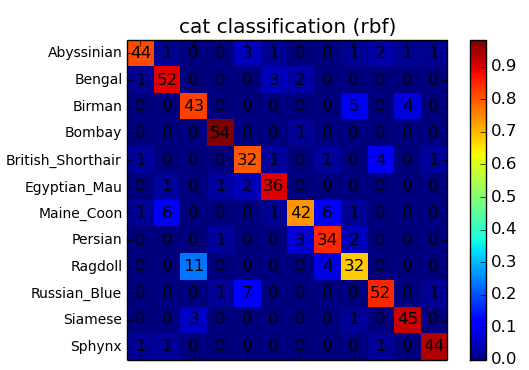
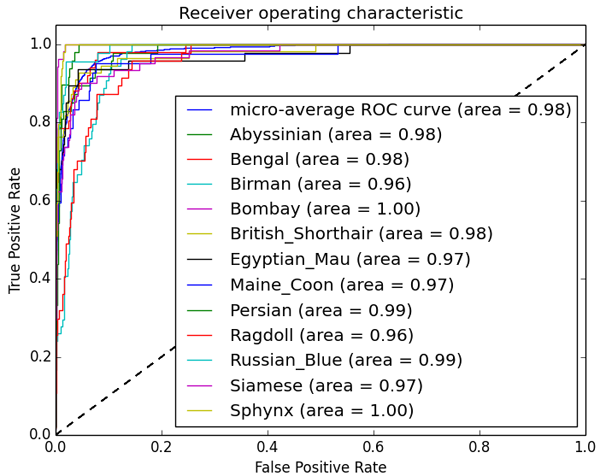
SVM-RBFの場合で Accuracy 84.5% となりました。ラグドールなど一部の長毛種は精度が低めになっていますが、学習データ1800枚でここまでの精度が出ればまあまあかなと思います。ブログの方では他の分類器での結果も載せていますが、大規模データを対象にするなら予測速度の問題から線形SVMあるいはロジスティック回帰を使った方が現実的かと思います。
注目すべきは、人が設計した(hand-crafted)特徴量を用いず、ニューラルネットワークが認識に有効な特徴量を自動的に見つけている(学習している)という点です。今回はDCNNを特徴抽出器として使いましたが、ImageNetなどの大規模な教師データを基に学習したモデルのパラメータを初期値として、他の教師データを使ってネットワーク全体を微調整する Fine-tuning (ファインチューニング)という手法を使って作成したモデルを利用すると、より高い精度で分類できる可能性があります。一応手元でもいろいろ試してみましたが、今回のタスクではモデル作成にかかる時間(とメモリ使用量)の割には有意な精度向上が見られませんでした。Fine-tuningの手順についてはCaffe公式サイトのチュートリアル通りに実行すれば難しいところはないと思います。
Deep CNNはILSVRCなどの有名なコンペなどでも頻繁に名前を見るようになりました。今後はWebサービスやアプリなどの製品レベルでDeep Learningが活用される事例がどんどん増えていくんだろうなと思います。実用レベルの手法が確立されたら、後はいかにデータを集めるかというところにお金が使われるようになるのでしょう。

[('Abyssinian', 0.621), ('Bengal', 0.144), ('Sphynx', 0.087)]
アビシニアンの確率 62.1% , ベンガルの確率 14.4% , スフィンクスの確率 8.7%
- ねこと画像処理 part 1 – 素材集め
- ねこと画像処理 part 2 – 猫検出 (モデル配布)
- [ねこと画像処理 part 3 – Deep Learningで猫の品種識別] (http://rest-term.com/archives/3172/)