公開中サイト
開発環境
| Server | lightSail |
| Language | Python3.11 |
| Framework | Django |
| DB | sqlite3 |
ローカル環境ではPythonのvenvを使用。エディタはvs codeです。
目的
WEB画面上でChatGPTと会話ができるアプリを作りたいと思っています。TTS(テキストを自然な音声にするAPI)とwhispar(音声をテキストにするAPI)を使えば、会話ができるはず。その第一弾として、whisparで音声を文字起こしするアプリを作りました。
うまくいけば、ブラウザ画面上で自然言語を話しながら人工知能と会話できるはずです。chatGPTと音声で会話したい。その目的のための文字起こしアプリです。
コード
def index(request):
OPENAI_API_KEY = os.environ['OPENAI_API_IMAGE_KEY']
chat_results = ""
if request.method == "POST":
form = TranscribeForm(request.POST)
if form.is_valid():
client = OpenAI(
api_key = OPENAI_API_KEY,
)
audio_file_path = settings.BASE_DIR / "uploads/uploads/recording.wav"
audio_file= open(audio_file_path , "rb")
transcription = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file
)
chat_results = transcription.text
else:
form = TranscribeForm()
domain = request.build_absolute_uri('/')
template = loader.get_template('whispar/index.html')
context = {
'domain': domain,
'chat_results': chat_results
}
return HttpResponse(template.render(context, request))
アプリ画面
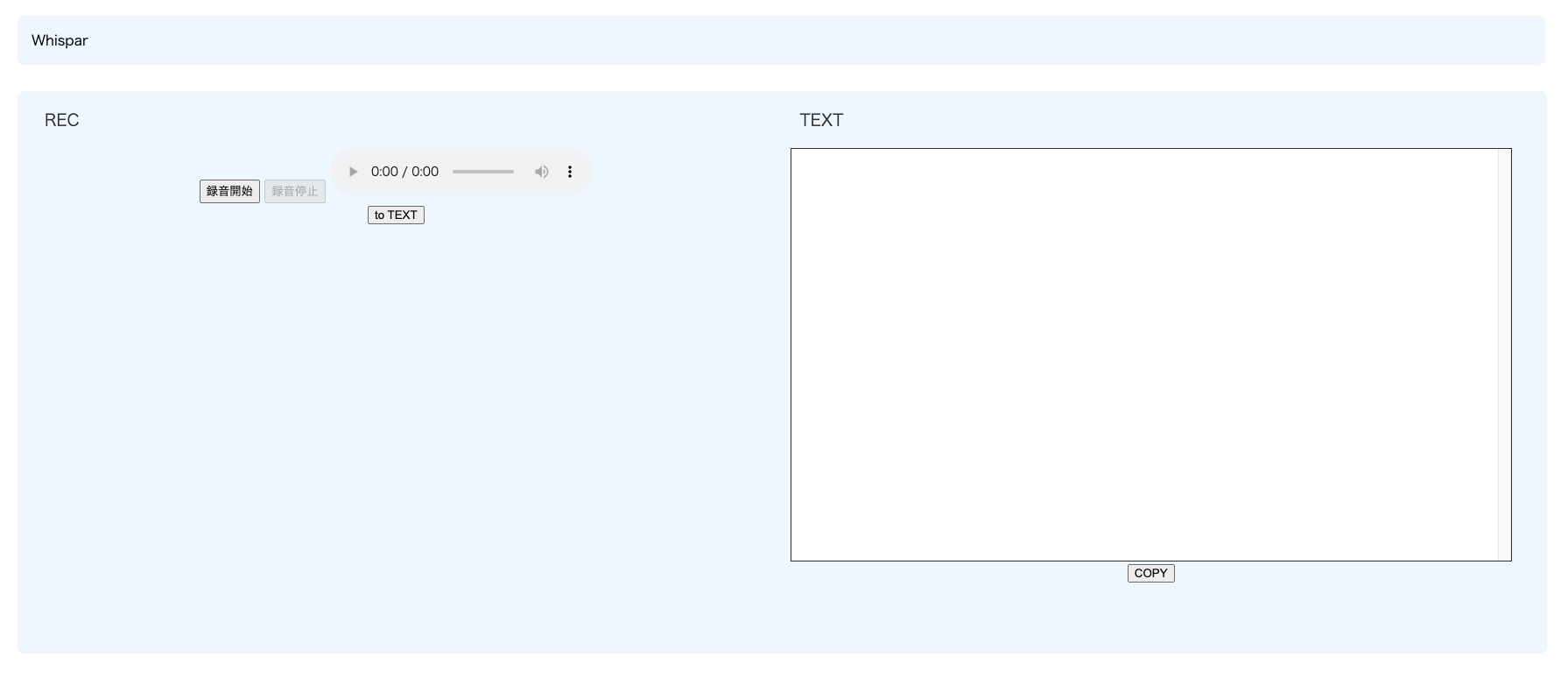
感想
文字起こし処理で力尽きてしまいました。デザインレイアウトは後で修正します。もちろん、音声データを保存し。そのデータを元に文字起こしまでは完成しました。人工知能とリアムタイム会話まであと一歩。テキストを音声化させれば、会話できます。音声を早見沙織にしたいです。「軽く死ねますね!」
苦労したのは、音声保存まではJSでわりとスムーズにいけましたが、その音声をどう処理するかが、ネットで検索してもわからなかったので、chatGPT先生(転スラでいうところのシエル先生)に相談して解決しました。ネットには虚言癖しかいないのか、と悲しくなります。やはり、コードの説明なんてしないで、公式のマニュアルに任せるべきなのでしょう。
ローカルではなにもかもうまく行きましたが、サーバでは苦労しました。音声をアップするディレクトリに権限がない状態でgit pull をしたものだから。サーバのmain branch が remote から離れてdetch状態に。音声以外のディレクトリはpullしてきているので、見たこともない変更処理が増えており、焦りました。gitでミスしても周りに迷惑をかけないのが個人開発のメリットでもあるので、普段では仕事で使ったことないような復旧方法を使ってなんとか復帰。権限がない状態でgit pull すると、こんなエラーになるのか、と初体験。もしかして、これが1番の収穫かもしれない。仕事の本番環境で同じことが起こったら、焦ってしまうこと間違いなし。
いやー、chatGPTとの会話まで一歩すすめました。
ちなみにトップページのアプリアイコンはすべて画像生成したものです。