機械学習とは
データから機械がルールを学習するもの。
3つに大別される。深層学習はこれらに横断して活用できる。
- 教師なし学習
- 教師あり学習
- 強化学習
教師なし学習
正解情報をもたない学習。
特徴量に基づき、類似性の高いデータのクラスタリングを行う。
クラスタリングのアルゴリズムには以下のようなものがある
- k-means
- DBSCAN
k-means
非階層クラスター分析。k個のクラスタに分割する。
各クラスタはそのクラスタを構成するサンプルデータからなる重心をもち、それぞれのサンプルデータは最も近い重心のクラスタに属する、という関係が成り立つ。
DBSCAN
サンプルデータの密度に着目したクラスタリング手法。
指定距離内に同一クラスタに属する近接点が指定個数以上存在するコア点をクラスタ化し、コア点の指定距離内にあるボーダー点は最近傍のクラスタに加える。
指定距離、指定個数のパラメータを与える必要があるが、分割数を予め与える必要はない。
非階層クラスター分析
データ量が多くても計算が膨大になりにくい。
あらかじめいくつのクラスターに分けるかを決める必要がある。
教師あり学習
英語ではスーパーバイズドラーニング。
原因系Xと結果yがインプットとなり、関係性を学習し、高い汎化能力を獲得する。
yは解決する課題から定義する。
教師あり学習はさらに以下の様に分類ができる。
利用目的によって選択する。
- 回帰
- 分類
回帰
正解データが数値変数(連続量)の場合に利用。
利用例は株価予測、ボラリティー予測、広告パフォーマンス予測、物件価格予測
分類
正解データが2値、多値である場合の分類に利用。
利用例はデフォルト予測、解約会員予測、退職者予測、不良品予測
不良品予測の場合、不良品の発生はとても少ないため、不均衡データ(インバランスデータ)を扱うこととなる。
アルゴリズムの例
-
K近傍法
あるオブジェクトの分類は、その近傍k個のオブジェクト群に最も多く付けられている分類が割り当てられる -
ロジスティック回帰
「多変量解析」の一種。複数の変数をもとにある事象が発生する確率を予測する。以下の数式による。
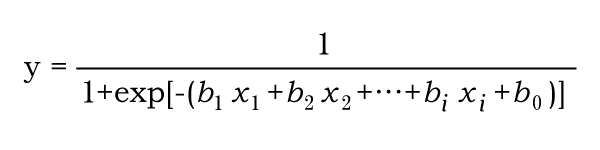
各変数の影響の大きさはオッズ比によって示される。 -
ニューラルネットワーク
人工ニューロン(ノード)が、学習によってシナプスの結合強度を変化させ、問題解決能力を持つようなモデル -
サポートベクターマシン
境界から最も近いベクトルからのマージンが最大化されるような分割を行う超平面をひくモデル -
ランダムフォレスト
決定木を弱学習器とするアンサンブル学習モデル。
各ツリーのデータは元データからブートストラップサンプリングにより選ばれる。
また、ツリーの分岐で利用される特徴量もランダムに選択されるため、多様なツリーが構築される。 -
勾配ブースティング
逐次的に弱学習器を構築するアンサンブル学習モデル。
前ステップの損失関数を最小化するように誤判定したデータに対するウェイトを次ステップで変更し、損失を最小化する。
計算を並列化できず学習に時間がかかる。
汎化能力とは
未知のデータに対する結果の予測能力。
汎化能力の向上
- データ量が多く、かつ多様なデータであることが汎化能力向上に必要。
- 正解予測に必要な適切な特徴量が選択されていること。(予測対象に対する知識が必要)
- 適切な前処理が行われていること
- 適切なアルゴリズムの選択が行われていること
モデリング
原因系Xと結果yとをインプットとして学習済みのモデルを作成する工程
スコアリング
学習済みモデルに未知のデータを適用し、その汎化能力を測る工程
教師なし学習とは
アンスーパーバイズドラーニング。
正解がない。データのパターン化をする。
教師なし学習により区分けされたデータを人間が解釈する必要がある。
主だった利用方法として、以下のようなものがある。
- データの見える化
- 異常検知(区分けできないデータ→異常データ)
- 教師あり学習の欠損値補完
- 話者識別
具体例
エンジンの排気量や車高等のデータを利用して、車をカテゴライズし、車種に基づいた分類結果を得る。
強化学習
Reinforcement learning(レインフォースメントラーニング)。
以下を繰り返しながら報酬を最大化する行動ルールを目指す。
- エージェントが対象システム(環境、エンバイオロメント)からデータの提供を受ける
- エージェントはそのデータをもとにアクションを環境に返す
- 環境はアクションに対するリワードをエージェントに返す
深層学習と組み合わせた深層強化学習はグーグルブレインやその他の研究所でも研究が盛ん。
強化学習の枠組みの中で深層学習を利用する。アクションの生成に深層学習を利用する。
例、自動運転や碁などのゲームストラテジー作成
アマゾン×ロボティクスによる向上の半自動化
ディープマインドによるデータセンターの省エネ
機械学習活用の流れ
- ローデータの取得
- 前処理
- フィーチャーエンジニアリング
- モデル選択
- パラメータオプティマイゼーション
- モデル評価
- デプロイ
- モニタリング
データの質が重要
フィーチャーエンジニアリングとは機械学習モデルのパフォーマンスと精度を向上させるために、追加の変数(特徴量)を構築してデータセットに追加すること。
例えば、すでにある日付情報から曜日情報を抽出し追加すること。
前処理
クリーニング
データの型を整えたり、スペース文字のトリムをしたり。
カテゴリカル変数の処理
文字列データを数値に変換。OneHotEncoding、Label Encoding等。
どちらを適用できるかはアルゴリズムによる。ツリー系であればLabel Encodingでも良い。
OneHotEncoding
カテゴリ変数を数値に変換する手法。
多くの機械学習アルゴリズムは入力が数値である必要があるため。
カテゴリ変数の種類の数に対応した列が作成され、それぞれの列に0or1が入力された状態に変換される。
また、該当のカテゴリ変数内に欠損があれば、欠損を示す列も作成され、カテゴリ変数が欠損している行はその列に1が入力される。
欠損値の処理
連続変数の欠損はsklearnのSimpleImputerやfancyimputeを利用して欠損値に対して平均値、中央値等を補完する方法がある。
標準化
各列のスケール(標準偏差、平均値)を揃える処理。
各列の平均値が0となるように加減し、標準偏差が1となるように乗除する。
損失関数の値を最小化する最適化計算が適切に実施できるようにするのが目的。
フィーチャーエンジニアリング
特徴量の追加
予測に必要な特徴量を追加する。
追加データを準備する他、以下のように既存の特徴量をより予測に寄与できる形式へ変換も行う。
- 価格を面積単価に変換
- 日付データを時刻データに変換
- 日付データを経過期間に変換
- 時刻データをsin関数に変換、
次元削減
特徴次元が大きくなるにつれて汎化誤差が大きくなる傾向があるため、次元を削減する。
以下の方法がある。
- 特徴選択
- 特徴抽出
特徴選択
重要性の低い特徴量を予測から除外する。
sklearnのRFEを利用して、各特徴量の重要度を測り、その結果に基づき予測に寄与する特徴量を選択する、等の方法がある。
RFE(Recursive Feature Elimination)
各特徴量の予測能力に基づき不要な特徴量を削減し、その状態で再度予測を行う。
この処理を再帰的に行うことで、予測能力の高い特徴量を選択することができる。
特徴抽出
主成分分析(PCA)により、元データの写像を得ることで特徴量の圧縮をおこなう。
ただ、元データを変換しているため、変換後のデータを構成する特徴量が何を示しているのかは人間が直感的に理解することはできない。
不均衡データへの処理
サンプルが多いクラスへの学習に偏り、ローサンプルクラスへの学習が十分に反映されず、予測精度に影響を及ぼす可能性がある。
以下の様な手法でデータの偏りを緩和する。
- ランダムアンダーサンプリング
- ランダムオーバーサンプリング
- SMOTE
スコアリングに対する前処理の注意点
以下の注意点がある。
- 学習データに存在しないカテゴリ変数がスコアリングデータに存在する場合、該当のカテゴリ変数はNullとする。
- 欠損値の補完は学習データの分布(平均値、中央値等)に基づいた補完を行う
- 標準化処理は学習データの分布に基づいた調整を行う。
- 標準化処理は学習データの分布に基づいた調整を行う。
- 不均衡データへの処理はスコアリングデータには行わない。
パラメータオプティマイゼーション
ディシジョンツリーの深さ、ツリーの数、アルゴリズムのハイパーパラメータをチューニングする。
チューニングの方法にはグリッドサーチ、ランダムサーチがある。
また、Optuna、HyperOpt等のライブラリがある。
ハイパーパラメータ
推論や予測の枠組みの中で決定されないパラメータのことを指す。
損失関数の正則化項の影響度を表す係数などが該当する。
グリッドサーチ
各パラメータの探索候補値の全組み合わせでモデルを生成、評価する。
計算量が各パラメータ候補値数分の積となるので、探索候補となるパラメータが増えるにつれて計算時間が急増する。
ランダムサーチ
パラメータの探索候補からランダムに選択したパラメータの組み合わせでモデルを生成、評価する。
探索総数を指定できるメリットがあるが、運が悪いと適切なパラメータの組み合わせにたどり着かない。
モデル評価
学習に利用したデータとは別のデータを用い、モデルの汎化性能を測る。
以下の方法がある。
- ホールドアウト検証
- 交差検証
ホールドアウト検証
手元に存在する原因系Xと結果yを備えたデータをモデルを作るための学習データと、モデルを評価するテストデータに分割する。
学習データのみを学習に用い、作成されたモデルの汎化性能をテストデータを用いて測る。
交差検証
手元のデータをk個に分割し、学習データとテストデータを入れ替えながらk回ホールドアウト検証を行い、その平均を用いる。
すべてのデータが重複なく検証に利用されるため、学習データとテストデータに選択されるデータの偏りによって生じる結果のブレが緩和され、ホールドアウト検証よりも結果の信頼性が高い。
検証回数がホールドアウト検証のk倍となるため処理時間がかかるが、並列処理により回避可能。
sklearnではcross_val_scoreを用いて実施可能。
混同行列(Confusion Matrix)
混同行列は分類器による予測値を、真陽性(True Positive )、真陰性 True Negative )、偽陽性( False Positive )、偽陰性 False Negative )の 4区分に表現した行列。
正解率(Accuracy)
予測値の全数と正解数との比率。
ただ、正例、負例の不均衡度合いが大きいほど、当てずっぽうでも指標の値が良くなるデメリットが有る。
ACC = (TP+TN)/(TP+FP+FN+TN)
適合率(Precision)
PRE = TP/(TP+FP)
再現率(Recall)
REC =TP/(TP+FN)
F値(F measure)
F1 = 2PREREC/(PRE+REC)
その他
深層学習
伝統的な機械学習と比較した場合、フィーチャーエンジニアリングの一部がモデルに含まれているとも言える。
ラベル付けされたデータ量が多く必要。
画像、音声、自然言語で古典的機械学習手法との性能差が特に大きい。
実務応用
インバランスドデータ
Automated ML
時間のかかる反復的な機械学習モデルの開発タスクを自動化するプロセス。
前処理、特徴量抽出、特徴量選択、モデル選択を自動化する。
サービス、ツール
DataRobot
Amazon SageMaker
Azure Machine Learning
SMAC
AutoSklearn
BOHB
Featuretools