概要
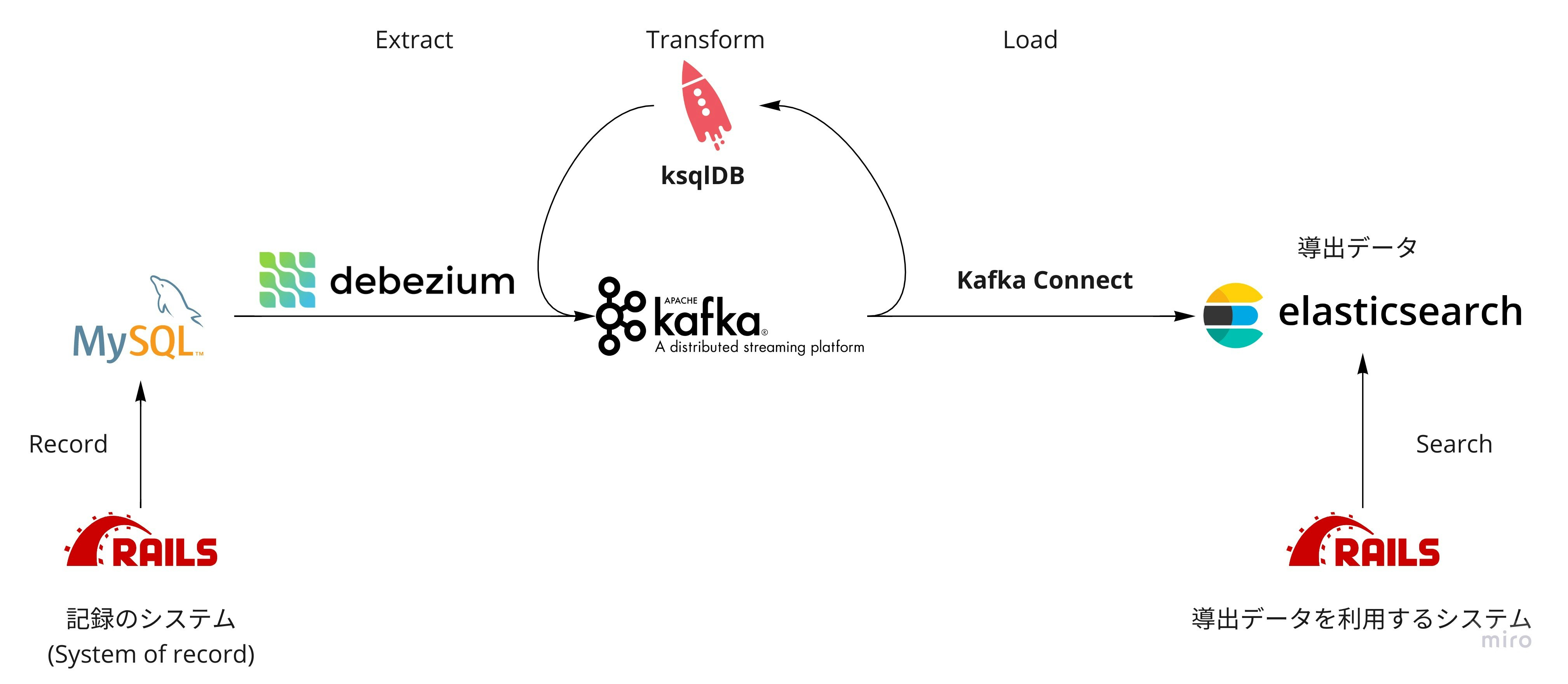
データパイプライン構築の技術スタックを業務システム構築に応用する Proof of Concept を紹介します。
私はデータ基盤技術の専門家ではないので間違った記述があるかもしれません。気が付かれましたらご指摘いただけると幸いです。
データパイプラインはデータ分析などの用途に使う印象が強いかもしれませんが、業務システムにおいても RDB と検索エンジンといったマルチデータストアのデータ一貫性を保証する、障害耐性を高める課題の解決に有効だと思います。
その課題を説明する前に、まずはこの記事で言及するプロダクトについて、データ基盤技術を代表するであろう概念 ETL - Extract, Transform, Load の要素に分類して紹介します。
Extract - Debezium
Debezium は Red Hat が大きく貢献している変更データキャプチャ(Change Data Capture, 以下 CDC)のプロダクトです。
CDC とは RDB の変更を抽出する技術で、 ETL の E, Extract を変更の差分の抽出に限定した概念と捉えることができます。
抽出対象を差分に限定するため当然のことながら全データのダンプよりは軽量で、データパイプライン全体の効率化につながります。1, 2
中でも Debezium は RDB のレプリケーションに使われるバイナリログを監視する仕組みにより低負荷、低レイテンシを実現した CDC で、RDB の更新を Apache Kafka のイベントストリームに変換します。
Transform - ksqlDB
Extract が差分、リアルタイムということは、自ずと Transform から先は(全データのバッチ処理ではなく)ストリーム処理ということになるでしょう。
ksqlDB は Kafka のストリーム処理を SQL ライクなシンタックスで記述できるプロダクトです。3
ETL の T, Transform が RDB のビューを定義するかのごとく宣言的に実装できるのが特徴です。
Load - Kafka Connect(Sink Connector)
最後のピースは ETL の L, Load です。
Kafka Connect は Kafka と他のデータソースを接続してリアルタイム転送するためのフレームワークです。4
Kafka から他に送る Connect は Sink Connector と呼ばれていて Elasticsearch, Amazon S3, Google BigQuery と様々なデータソース向け Production Ready な実装が公開されています。5
これらのプロダクトを組み合わせると、とても小さいコード量でストリーミング処理のデータパイプラインを構築できます。
題材とするゲームレビューサイトとその課題
導入シチュエーションとしてゲームのレビューサイトを題材にします。
ユーザはゲームのレビュー投稿と、タイトル、レビューコメント、平均スコアなどで検索することができるとします。
レビュー投稿機能は以下の ER 図で示すテーブル設計の RDB に保存します。
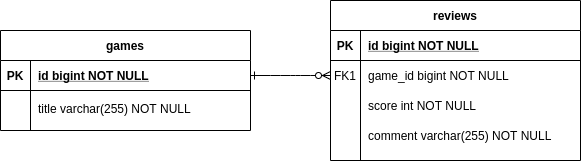
RDB はレビューコメントのようなテキストの全文検索や、数値項目であっても任意のカラムを条件とする検索には不向きです。
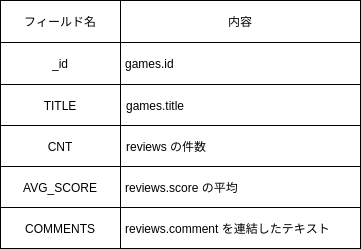
検索機能は以下のインデックスを持った検索エンジンで実現することにします。
さて、このサイトを構築するにあたってどんな課題があるのでしょうか?
最初の課題 - 一貫性と耐障害性 - Consistency, Durability
以下のようにレビューを (1) RDB に保存してから (2) 検索エンジンに保存するコードを考えます。
def create
# 1) レビューを RDB に保存
review = Review.create(params)
# 2) レビューを検索エンジンに保存
review.update_search_engine
end
(1) と (2) の間でプロセスがクラッシュすると RDB と検索エンジンのデータに不整合が生じてしまいます。

実際には RDB と検索エンジンの両方を同期処理するとレイテンシが大きくなりがちなので、検索エンジン更新は Delayed Job など非同期処理として実装している事例が多いと思います。それにしても本質的な RDB とメッセージ発行を一貫性を持って行うことが困難という課題は依然として解決しません。
(誰かが傍若無人に RDB の CLI から直接データ更新しても一貫性がなくなりますよね……)
解決案 - RDB のデータから検索エンジンのデータを導出する
RDB と検索エンジンを同時に一貫性を保ちながら更新する分散トランザクションではなく、定期的に RDB と検索エンジンの差分を検出して反映する方式はどうでしょう?
RDB のデータを(ある時点の)真実として検索エンジンを更新するので、同じ結果に収束する結果整合性が保証できます。(途中の更新順序が入れ替わる可能性はあります。)
データ指向アプリケーションデザインにはシステムとデータを「記録のシステム(System of record)」と「導出データ」に分類する考え方があり、6 この題材に当てはめるとレビュー投稿機能が「記録のシステム」でレビュー検索機能が「導出データシステム」になります。
新たな課題 - レイテンシ - Latency
しかし RDB 更新から検索エンジンに反映されるまでのレイテンシが大きくなる新たな課題が生じます。
今回の題材では 1 ゲームにレビューが 1,000 件というように非常に多く投稿されているときは、差分の検出に時間がかかりってしまいそうです。
新たな課題の解決策 - RDB 更新が確定したことをイベントにできないか?
もしも RDB の更新を逐次検知することができれば、差分検出のレイテンシが大きくなりがちという問題は解消できそうです。Rails の ActiveRecord にある after_save のような callback イベントを、 RDB 直接更新でもキャッチできないでしょうか?
これこそが CDC から始まるデータパイプライン技術を導入する動機となります。
Proof of Concept
- レビュー投稿機能(記録のシステム)は MySQL の
reviewsテーブルを更新する - MySQL の更新イベントを Debezium で Kafka のメッセージに変換する
- ksqlDB で Kafka のメッセージをストリーム処理して検索エンジンのインデックスに変換する
- Kafka Connect で検索エンジンのインデックスを Elasticsearch に同期する
- レビュー検索機能は Elasticsearch で検索する(導出データシステム)
実装の概要説明
Docker Compose で実装しました。
コードは weakboson/etl-applyed-app にあります。git clone して若干の操作で PoC が再現できます。
ターミナル 1 からコンテナを起動します。
$ docker-compose up
すべてのコンテナが正常に起動すると以下のようになります。
$ docker-compose ps
Name Command State Ports
---------------------------------------------------------------------------------------------------------
broker /etc/confluent/docker/run Up 0.0.0.0:29092->29092/tcp, 9092/tcp
elasticsearch /usr/local/bin/docker-entr ... Up 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp
kibana /usr/local/bin/dumb-init - ... Up 0.0.0.0:5601->5601/tcp
ksqldb-cli /bin/sh Up
ksqldb-server /usr/bin/docker/run Up 0.0.0.0:8088->8088/tcp
mysql docker-entrypoint.sh mysqld Up 0.0.0.0:3306->3306/tcp, 33060/tcp
rails /bin/bash Up 0.0.0.0:3000->3000/tcp
schema-registry /etc/confluent/docker/run Up 0.0.0.0:8081->8081/tcp
zookeeper /etc/confluent/docker/run Up 0.0.0.0:2181->2181/tcp, 2888/tcp, 3888/tcp
ターミナル 2 から Rails 経由で MySQL 初期データ構築します。
$ docker exec -it -u ${UID}:${GID} rails bash
# コンテナ内で
bundle exec rake db:create
bundle exec rake db:migrate
bundle exec rake db:reset
PoC の説明図では ETL の各プロセスに分類して整理しましたが、実際には中心に位置する ksqlDB のコンテナにエンベデッドモードで Debezium と Kafka Connect をインストールする構成にしました。
ksqlDB はこのように開発フェーズにおいて Kafka Connect を ksqlDB のインタフェースでかんたんに管理できることもメリットに一つとして挙げています。7
後は ksqlDB の CLI から設定してゆきます。
1. Extract 部分
以降はほとんど ksqlDB の CLI から操作します。
ターミナル 3 から ksqlDB の CLI を起動します。
$ docker exec -it ksqldb-cli ksql http://ksqldb-server:8088
何かしら失敗したときのために「やり直す際は最初から」という設定にしておきます。
ksql> SET 'auto.offset.reset' = 'earliest';
次に Debezium を設定して MySQL の更新イベントを Kafka のメッセージに流し込むようにします。
ksql> CREATE SOURCE CONNECTOR `my-service-reader` WITH (
'connector.class' = 'io.debezium.connector.mysql.MySqlConnector',
'database.hostname' = 'mysql',
'database.port' = '3306',
'database.user' = 'root',
'database.password' = 'my-root-pw',
'database.allowPublicKeyRetrieval' = 'true',
'database.server.id' = '1',
'database.server.name' = 'my-service-db',
'database.whitelist' = 'my-service',
'database.history.kafka.bootstrap.servers' = 'broker:9092',
'database.history.kafka.topic' = 'my-service',
'include.schema.changes' = 'false'
);
うまく設定できると MySQL のテーブルそれぞれに対応する Kafka のトピックが生成して、レコードが初期状態のメッセージとして確認できます。
ksql> show topics;
Kafka Topic | Partitions | Partition Replicas
---------------------------------------------------------------------------------
default_ksql_processing_log | 1 | 1
ksql-connect-configs | 1 | 1
ksql-connect-offsets | 25 | 1
ksql-connect-statuses | 5 | 1
my-service | 1 | 1
my-service-db.my-service.ar_internal_metadata | 1 | 1
my-service-db.my-service.games | 1 | 1
my-service-db.my-service.reviews | 1 | 1
my-service-db.my-service.schema_migrations | 1 | 1
---------------------------------------------------------------------------------
ksqlDB CLI は Kafka のトピック内容も直接参照できます。
ksql> PRINT 'my-service-db.my-service.reviews' FROM BEGINNING;
1.5. Transform, の前に ksqlDB の概要説明
ksqlDB の基本的なオブジェクトはストリーム(STREAM)とテーブル(TABLE)です。
ストリームはアクセスログのようなイミュータブルなデータで、対するテーブルは RDB のテーブルのごとくミュータブルなデータです。どちらも Kafka のトピックから作成できます。以下はストリームを定義するシンタックスです。
ksql> CREATE STREAM s WITH (
kafka_topic = 'some-topic',
value_format = 'avro'
);
更に Transform プロセスの真骨頂としてストリームの一部を抽出したり集計して、新しいストリームまたはテーブルが定義できます。
ksql> CREATE STREAM s2 AS
SELECT s1.id,
sum(s1.price)
FROM s1
GROUP BY s1.id;
これを SQL で宣言的に定義するのが ksqlDB による Transform 実装となります。
題材のゲームサイトではゲームごとにレビューを集計した、ミュータブルな検索インデックスが欲しいので、最終生成物はテーブルになります。
(このようなテーブルをマテリアライズドビューと称します。集計クエリの結果がキャッシュされている ≒ 実体を持っているという意味合いになります。)
ところで私がハマって理解に時間を要したことがありまして、今回の要件では正本のデータストアが RDB なので Kafka のトピックから作成すべきはテーブルのような気がします。しかし CDC により Kafka に転送されるのは「RDB 更新イベントのストリーム」なので、最初に作成すべきはストリームです。
「ストリームではレコード更新できなくて困るのでは……」と思われるかもしれませんが「CDC のイベントストリームを RDB のキーで集計した最新の値(LATEST)」という体でテーブルを定義することで解決します。(と、私は理解しました。)
2. Transform 部分
というわけで前述のように reviews, games 共にストリームからテーブルを定義するところからはじめてゆきます。
同じような名前のストリームとテーブルが登場するので、ストリームは s_ テーブルは t_ から始める規約で命名します。最終的に欲しいマテリアライズドビューは特別に v_ で始まる名前にします。
-
t_games,t_reviesを定義します -
t_reviewsをgame_idごとに集計したt_review_summariesを定義します。このテーブルにはまだゲームタイトルがありません -
t_review_summariesとt_gamesを JOIN してゲームタイトルも検索できるv_game_review_indexを定義します
t_games, t_reviews 定義
まず Kafka のメッセージをそのままストリームとして定義します。
ksql> CREATE STREAM s_games WITH (
kafka_topic = 'my-service-db.my-service.games',
value_format = 'avro'
);
次に s_games を最新で集計した体で t_games を定義します。
CDC イベントは更新前が before, 更新後が after という親階層の下に RDB のカラムがある構造で、 after->title のようにアロー演算子で指定できます。
ksql> CREATE TABLE t_games AS
SELECT after->id as game_id,
latest_by_offset(after->title) AS title
FROM s_games
GROUP BY after->id
EMIT CHANGES;
ここまでの実装がうまくいってるか一旦確認しましょう。
ksqlDB のテーブルに対しては「更新された行がサーバから返り続けるプッシュクエリ」か、「キー指定して 1 回で終了するプルクエリ」が実行できます。
まずキーを指定したプルクエリです。
ksql> SELECT * FROM t_games WHERE game_id = 1;
+-----------------------------+-----------------------------------------+
|GAME_ID |TITLE |
+-----------------------------+-----------------------------------------+
|1 |DARK SOULS |
Query terminated
1 件返って終了します。
次がプッシュクエリで、その時点の t_games 全データが返ってから待ち状態になります。
ksql> SELECT * FROM t_games EMIT CHANGES;
+-----------------------------+----------------------------------------------+
|GAME_ID |TITLE |
+-----------------------------+----------------------------------------------+
|1 |DARK SOULS |
|2 |Bloodborne |
|3 |SEKIRO: SHADOWS DIE TWICE | 隻狼 |
Press CTRL-C to interrupt
ターミナルをもう一つ開いて rails のコンテナで Rails Console を起動して、適当に好きなゲームのレビューを作成したり、更新したりしてみましょう。
Transform をせずともこの時点で RDB 更新がイベント駆動で流れてくるという結構おもしろい挙動が確認できます。
プッシュクエリを終了させるには Ctrl + c します。
t_games 同様に t_reviews を定義します。
ksql> CREATE STREAM s_reviews WITH (
kafka_topic = 'my-service-db.my-service.reviews',
value_format = 'avro'
);
ksql> CREATE TABLE t_reviews AS
SELECT after->id AS review_id,
latest_by_offset(after->game_id) AS game_id,
latest_by_offset(after->score) AS score,
latest_by_offset(after->comment) AS comment
FROM s_reviews
GROUP BY after->id
EMIT CHANGES;
集計結果 t_review_summaries 定義
t_reviews の集計結果である t_review_summaries を定義します。
下記の通り感覚的というか SQL ほぼそのままに書けることがわかると思います。
ksql> CREATE TABLE t_review_summaries AS
SELECT game_id,
avg(score) AS avg_score,
count(review_id) AS cnt,
collect_list(comment) AS comments
FROM t_reviews
GROUP BY game_id
EMIT CHANGES;
ゲームタイトルを含む v_game_review_index を定義
後は JOIN するだけです。
ksql> CREATE TABLE v_game_review_index AS
SELECT r.game_id AS game_id,
g.title AS title,
r.cnt AS cnt,
r.avg_score AS avg_score,
r.comments AS comments
FROM t_review_summaries AS r
JOIN t_games AS g
ON r.game_id = g.game_id
EMIT CHANGES;
このマテリアライズドビューにプッシュクエリを発行してから、Rails Console でいろいろ操作をしてみましょう。
更新結果がリアルタイムで返ってくるのが確認できるはずです。
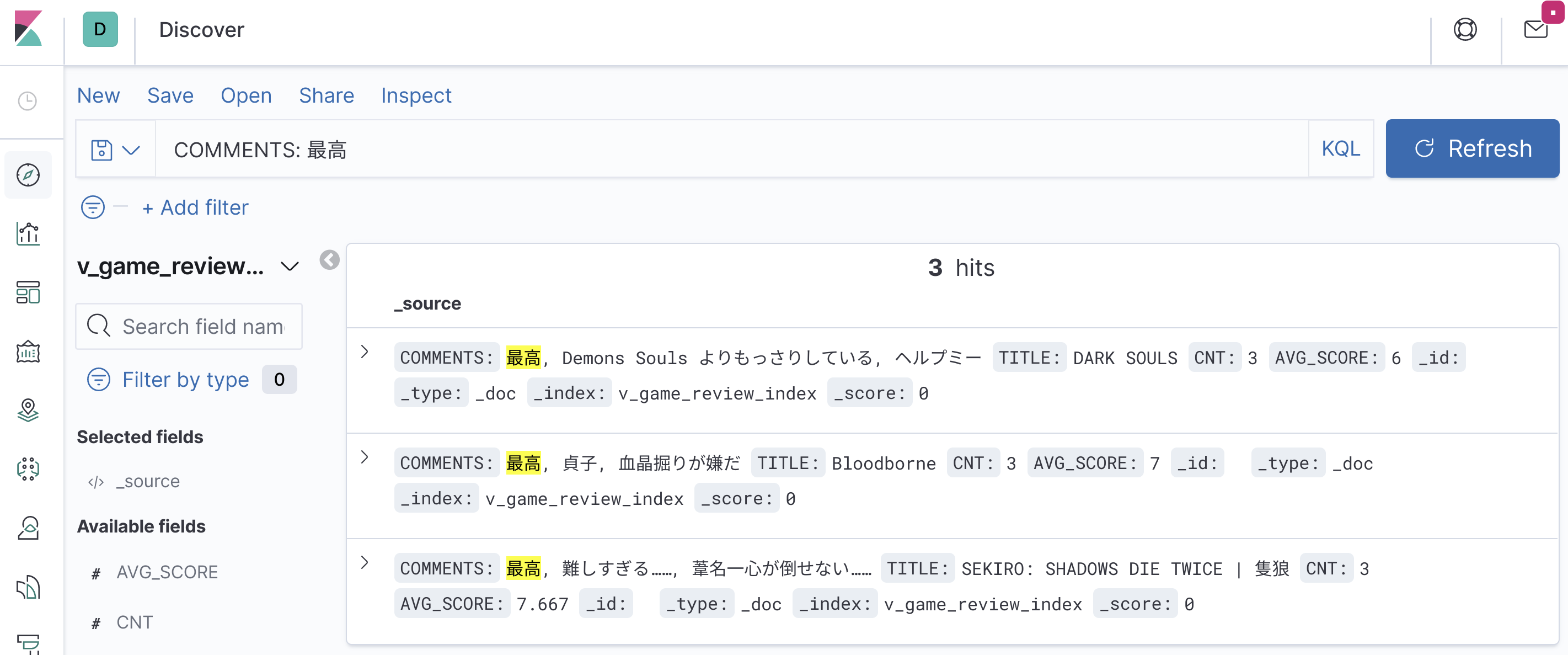
ksql> SELECT * FROM v_game_review_index EMIT CHANGES;
+----------------+--------------------------------+------+--------------+--------------------------------------------------------+
|GAME_ID |TITLE |CNT |AVG_SCORE |COMMENTS |
+----------------+--------------------------------+------+--------------+--------------------------------------------------------+
|1 |DARK SOULS |3 |6.0 |[最高, Demons Souls よりもっさりしている, ヘルプミー] |
|2 |Bloodborne |3 |7.0 |[最高, 貞子, 血晶掘りが嫌だ] |
|3 |SEKIRO: SHADOWS DIE TWICE | 隻狼 |3 |6.0 |[最高, 難しすぎる……, 葦名一心が倒せない……] |
Press CTRL-C to interrupt
3. Load 部分
最後に Transform で定義したマテリアライズドビューのデータがある Kafka のトピックを Kafka Connect(Sink Connector)で Elasticsearch に Load すれば完成です。
以下のステートメントで game_id を Elasticsearch の _id として同期する Kafka Connect が定義されます。
ksql> CREATE SINK CONNECTOR `game-review-index-connect` WITH(
'connector.class'='io.confluent.connect.elasticsearch.ElasticsearchSinkConnector',
'connection.url'='http://elasticsearch:9200',
'topics'='V_GAME_REVIEW_INDEX',
'key.ignore' = 'false',
'type.name' = '_doc',
'write.method' = 'upsert',
'errors.tolerance' = 'all',
'errors.deadletterqueue.topic.name' = 'V_GAME_REVIEW_INDEX_DEAD',
'errors.deadletterqueue.topic.replication.factor' = '-1'
);
動作検証
通しの動作検証をしてみましょう。
Kibana にアクセスして Index Patterns → Create index pattern と操作してインデックス作成します。
初期データから作成されたインデックスが既に生成しているでしょう。
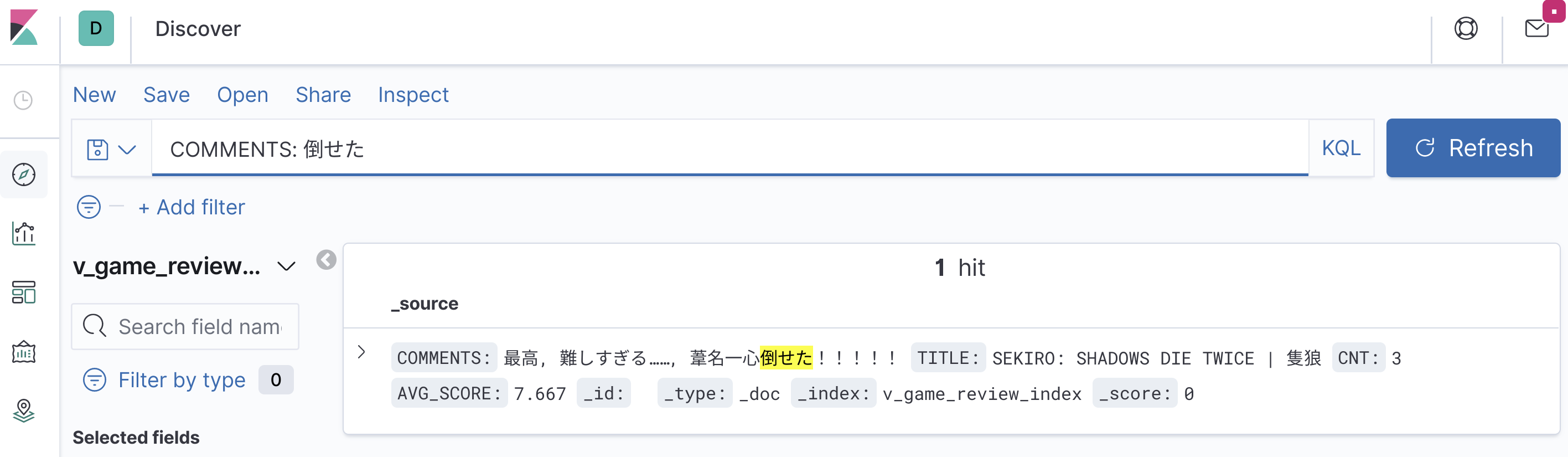
Rails にアクセスして Game, Review モデルから作成、更新すると検索インデックスも低レイテンシで更新されるのが確認できると思います。

最後に種明かし
実はこの PoC 設計はトランザクショナル・メッセージングの問題領域に対するマイクロサービス実装パターン、 Transactional outbox によく似ています。8
ここまで大きく参考にしてきた書籍「データ指向アプリケーションデザイン」には「マイクロサービスの文脈」というように敢えて区別したかのような表記が度々登場しますが、9 マイクロサービス化を実現する方法論は様々なパラダイムを取り込み進化し続けていて、境界を設ける意味はあまりないのでは思いました。
ところでこの PoC には Kafka をプロダクションでスケールするには避けて通れないパーティションに際して shuffling という問題ありそうです。10 この問題の説明までしようと思いましたが、説明するだけでこの記事のボリュームが倍くらいになりそうだったので、解決策の検証と併せて後日公開しようと思います。
明日は @gggk さんの「Railsアプリのパフォーマンス調査をしよう」です。お楽しみに!
-
How to use change data capture to optimize the ETL process ↩
-
ksqlDB - Event Streaming Database Built for Stream Processing ↩
-
データ指向アプリケーションデザイン - O'Reilly 12.2.2.4 ストリームプロセッサとサービス他数箇所 ↩