こんにちは。食べログシステム本部技術部マイクロサービス化チームの @weakboson です。
今年の Advent Calendar では食べログに Debezium と Apache Kafka (以下 Kafka) を導入してレストラン検索インデックス同期システムのパフォーマンスを爆上げした事例を紹介します。
マイクロサービス化チームとは?
私の所属するマイクロサービス化チームには「巨大なモノリシックサービスにおける開発の辛さを解消し、少人数のチームが自律的に意思決定しながら開発するためのシステム基盤を作る」というミッションがあります。
食べログは2007年に Ruby on Rails でリプレイスしてから約15年の長期にわたって抜本的なアーキテクチャ刷新なしに開発と運用を継続しており、モノリシックで巨大なコード、かつ巨大なデータを持つ状態になっています。正直なところ現在の開発効率はあまりよくありません。この巨大なシステムを高凝集・疎結合にリファクタリングするには、開発エンジニアが業務ドメインから整理してゆく正攻法だけでは難しいものがあります。リファクタリング戦略をサポートする武器が必要です。"We Need a New Weapon !" 1
課題 - レストラン検索のインデックス同期システムがレガシーでパフォーマンスが悪い
食べログには業務データから導出データを生成するシステムの多くがレガシーなアーキテクチャで動いているという課題があります。その代表的なものが業務データとレストラン検索インデックスデータを同期するシステムでした。
食べログのレストラン検索は Apache Solr (以下 Solr) で構築されています。Solr の検索インデックスには非正規化されたデータが必要で、正規化されている業務データから非同期で更新しているシステムが多いと思われます。食べログも例に漏れず業務データの MySQL から非同期で更新しているのですが、同期システムのパフォーマンスが総合的に悪く、データメンテナンスのための大量更新や、インデックスが大きく変わる仕様変更が困難な状況になっていました。 2
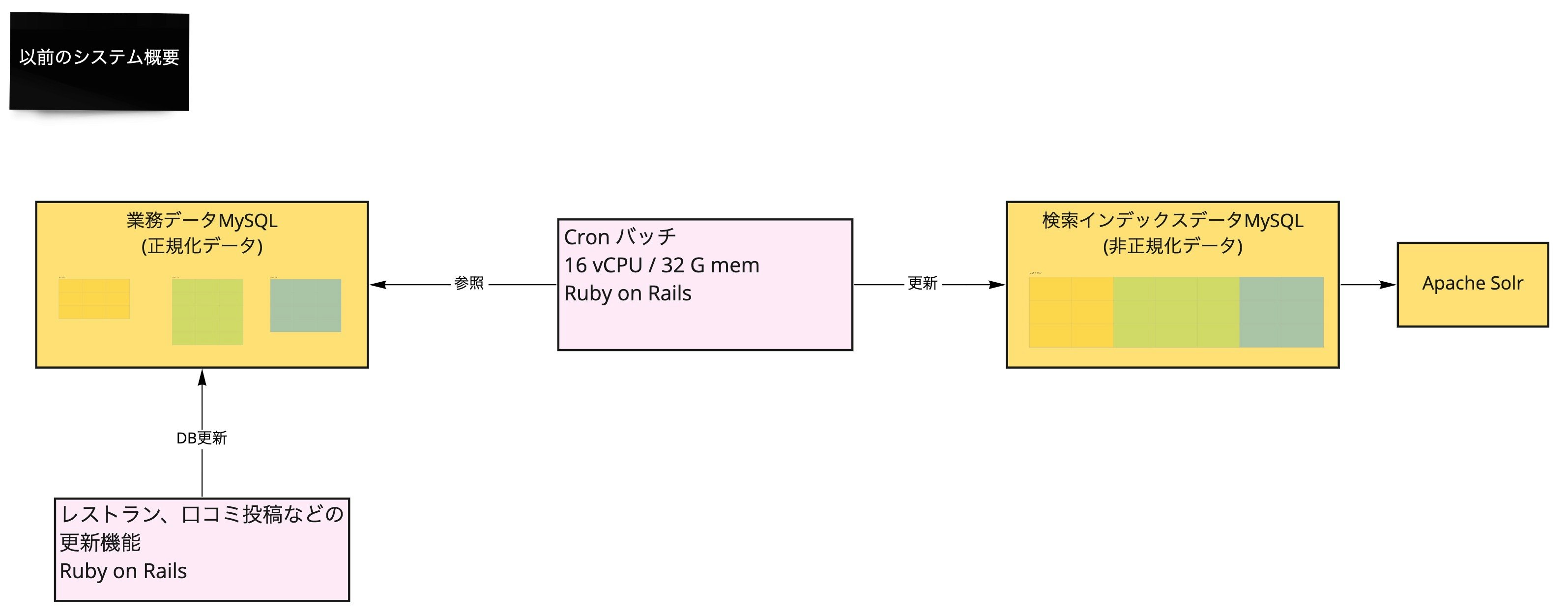
- 同期処理全体が cron バッチで稼働しており業務データの更新内容が検索インデックスデータに反映されるまでのレイテンシが悪い
- 業務データの更新タイムスタンプを WHERE 句で指定したクエリで更新を検知しており負荷が高いうえに遅い
- 検索インデックスデータの更新処理がシングルプロセスでスループットが低い
レストラン検索を担当する開発チームからちょくちょくこのパフォーマンス問題で困っている声が聞こえてきていたので、マイクロサービス化チームからアーキテクチャ刷新の話を持ちかけました。マイクロサービス化チームは導出データ生成基盤の実践検証ができて、開発チームは担当システムが改善される Win-Win の共同プロジェクトです。
課題に対する解像度を上げる
まずは課題に対する解像度を上げるために詳細を調査しました。
現状を定量的に把握することは「ちょっと手強いが無謀ではない」くらいの、モチベーションが上がる目標を設定するために不可欠だと思います。
過去数ヶ月分のログを解析して以下の実績グラフをプロットしました。横軸が検索インデックスデータの更新件数で、縦軸が処理時間を表します。青いドットが業務データ更新の検出時間(左の縦軸)で、オレンジのドットが検索インデックスデータの更新時間(右の縦軸)です。
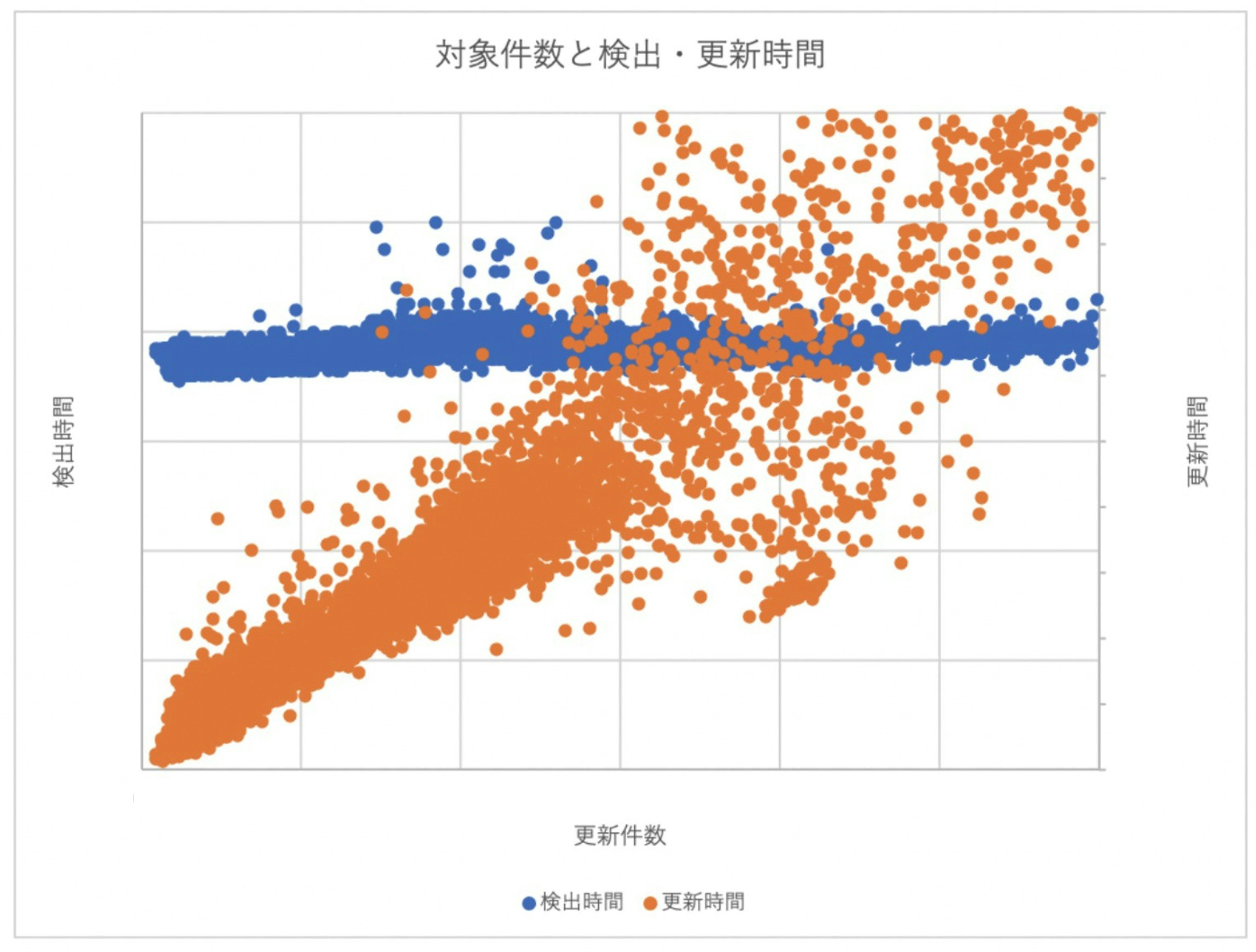
検出は更新件数に拘らず一定して結構な時間 かかることと、更新は概ね更新件数に比例した時間 かかることがわかりました。(具体的な単位時間は割愛させていただきます。) 検索インデックスデータに全件反映するには約16日かかる計算でした。
改善目標の設定
次に定量的な目標を設定しました。
個人的にリスペクト & ウォッチしているエンジニアの Tori Hira さんは、公演スライド「独りよがりのプラットフォーム」の中で次のように述べられています。
計測可能な(解決できたかを確認できる)課題設定が重要
レストラン検索インデックス同期システムの改善は「多少マシになった」程度では駄目で「メンテナンスのための業務データの大量更新」や「検索インデックスデータが大きく変わる仕様変更」が厭われない状態にしなくてはなりません。
開発チームとディスカッションして「口コミ仕様変更などで大量更新が起きても業務時間内程度で収束できると嬉しいよねー」という話になり「8時間で全業務データを検索インデックスデータに同期できる」という目標を設定しました。これは前述の約16日かかるという見込みからすると約48倍のアグレッシブな目標です。 3
なかなか手強いですが「2部署が相応のコストをかけて新兵器を投入するのだからそれくらいの性能出したいよね!やったろうじゃない!」というマインドでプロジェクトはスタートしました。
We Choose New Weapons
技術選定1 Change Data Capture - 更新検知とイベント駆動化の主戦力
まず先のグラフにおいて青のドットでプロットされた「検出時間」の改善を考えました。検出が遅い理由は大きく分けて2つでした。
- 業務データには更新タイムスタンプにインデックスがないテーブルがありクエリが遅い
- 業務データにはレコードを物理削除しているテーブルがあり差分を検索インデックスデータと全件同士比較していて遅い
この2点に対応できるなんとも都合のよいソリューションが Change Data Capture です。RDB の更新を DELETE も含めてキャプチャーしてイベントストリームに変換する技術になります。
Change Data Capture の動作原理は何種類かありますが、多くは RDB のレプリケーションインタフェースを利用していて同じような特性があります。即ち低レイテンシ、低負荷で DELETE を含めたほとんどすべての更新イベントをキャプチャーできます。
Change Data Capture のプロダクトとしては最も成熟しているであろう Debezium を選択しました。Debezium はイベントストリームに Kafka を採用していることも高い評価ポイントでした。
RedHat 社の技術ブログに大変よくまとまった Debezium の特長説明があるので引用させていただきます。
既存DBに対するデータ操作をKafkaのメッセージに変換することができますので、レガシーシステムなどでアプリケーションに手を入れたくないけどデータだけ抜き出してリアルタイム処理したいとか、別システムにデータを流用したいという場合に便利なソフトウェアです
(中略)
Kafkaという汎用的なメッセージバスに乗せることで、単純なデータレプリケーションだけでなく、同じメッセージストリームを複数の目的で再利用することができます。 レガシーマイグレーションの手段の一つとして、いろいろ使い所がありそうですね。
この数年 Better Kafka を目指すプロダクトがいくつか登場していますが、周辺エコシステムの充実度はまだまだ Kafka がダントツであるという認識です。持続可能性の高い Kafka にのっかっておけば、数年足らずで陳腐化してしまうこともないだろうという目論見がありました。
Debezium でキャプチャーした更新イベントのサンプルは JSON 4 で表現すると以下のようになります。更新前後のフィールドがすべてわかるので、例えばタイムスタンプしか更新されていない不要なイベントのフィルタ処理なども可能です。INSERT の場合は "before" フィールドが、DELETE の場合は "after" フィールドが null になります。
{
"before": { // DBの更新前の値
"id": 47048985,
"restaurant_id": 1234567,
"hogehoge_status": 2,
},
"after": { // DBの更新後の値
"id": 47048985,
"restaurant_id": 1234567,
"hogehoge_status": 1,
},
"op": "u", // 操作の種別 "u" は UPDATE
"ts_ms": 1633865473919,
}
Change Data Capture の導入により 一定して結構な時間かかっていた検出タイムラグがほぼゼロになります。さらに駆動系全体を cron バッチから Kafka メッセージを処理するイベント駆動に切り替えることができます。
技術選定2 Kafka Consumer による並列処理化
次に「検索インデックスデータ更新」のスループット向上を検討しました。
Ruby のプロファイリングツール stackprof と rblineprof を使うとメソッド呼び出し回数と所要時間、行単位の所要時間がわかります。
開発サーバでプロファイルすると検索インデックスデータ更新時間の上位3件を占めるのは以下の通りでした。
- ActiveModel のメソッド呼び出し時間
- メタプログラミングでメソッドを動的に定義する
define_methodの処理時間 - レストラン周辺駅の事前計算時間 (これだけは MySQL 処理も含む)
つまり MySQL の処理時間よりも Ruby コードの処理時間が支配的であるとわかりました。
以下に再掲するようにバッチサーバは 16 vCPU / 32 G mem の大変贅沢なスペックですが、Ruby は原則 1 プロセスで 1 CPU しか活用できないため、シングルプロセスのバッチではこのスペックを活用できません。 5 処理の並列化が必要です。
Kafka のトピックにはパーティションという内部の区分け構造があり、最大でパーティションと同数の Consumer で並列処理できます。6 開発環境のデータで試したところ概ね Consumer 数に比例したスループットの向上が確認できました。
また Kafka にはもう一点、同一のキーを持つメッセージは毎回同じパーティションに入るという特性もあります。(Kafka は RDB ではなくイベントストリームなので、同一キーのメッセージも上書きされないで全て保持されます。)この特性が地味に重要で、メッセージのキーと検索インデックスデータのキーを合わせると、Consumer プロセスの間で同じキーのレコードを更新する競合が発生しません。並列化しても競合が起きないということは、論理的には純粋に掛け算でスケールアウトできることになります。
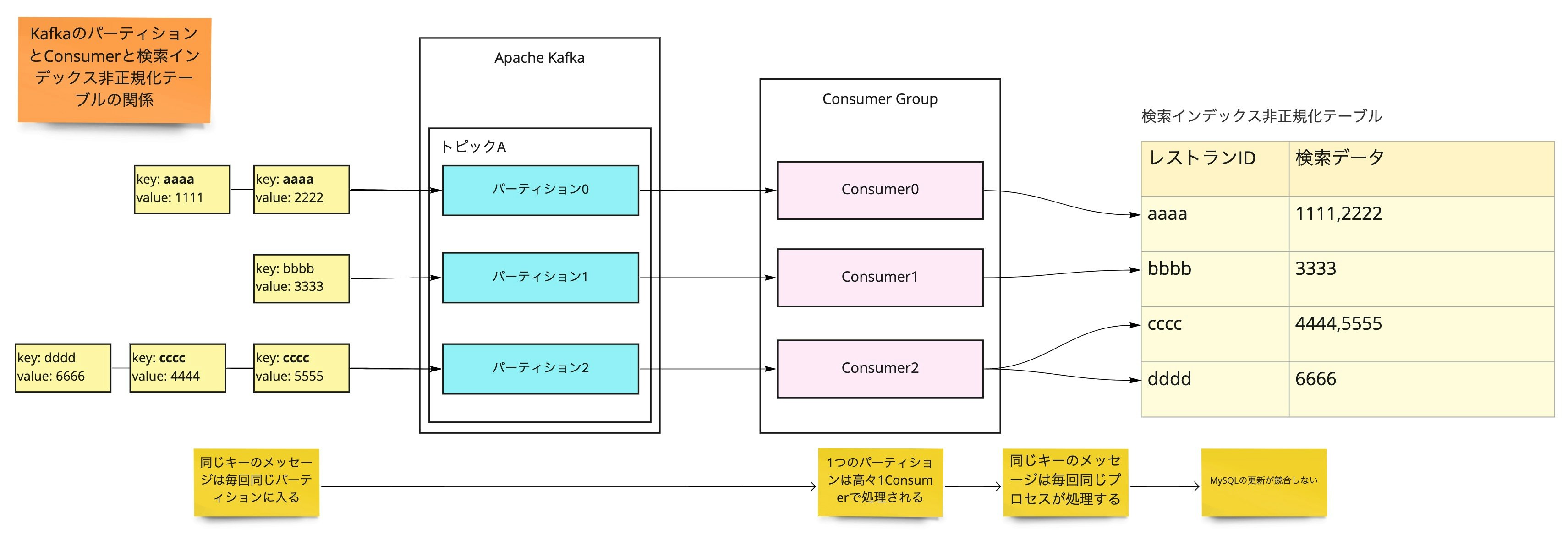
本番データでもそんなうまくいくかと思いつつ 2 vCPU * 2 VM の構成を用意したところ、実際にバッチの約4倍のスループットが出ました。こうなると後はやったれ!というノリで 8 vCPU * 6 VM の構成で本稼働の Consumer クラスタを構築しました。
新・レストラン検索インデックス同期システム全体の概要
ここまで紹介してきた Change Data Capture と Kafka Consumer によるシステム全体は下図の構成になります。(図をわかりやすくするため Kafka Consumer の並列構成は省略しています。)一連の流れは所謂 ETL 処理の Extract のステップを Change Data Capture による差分抽出にしたものになぞらえるとわかりやすいので、各ステップに Extract, Transofrm, Load の区分を示しています。
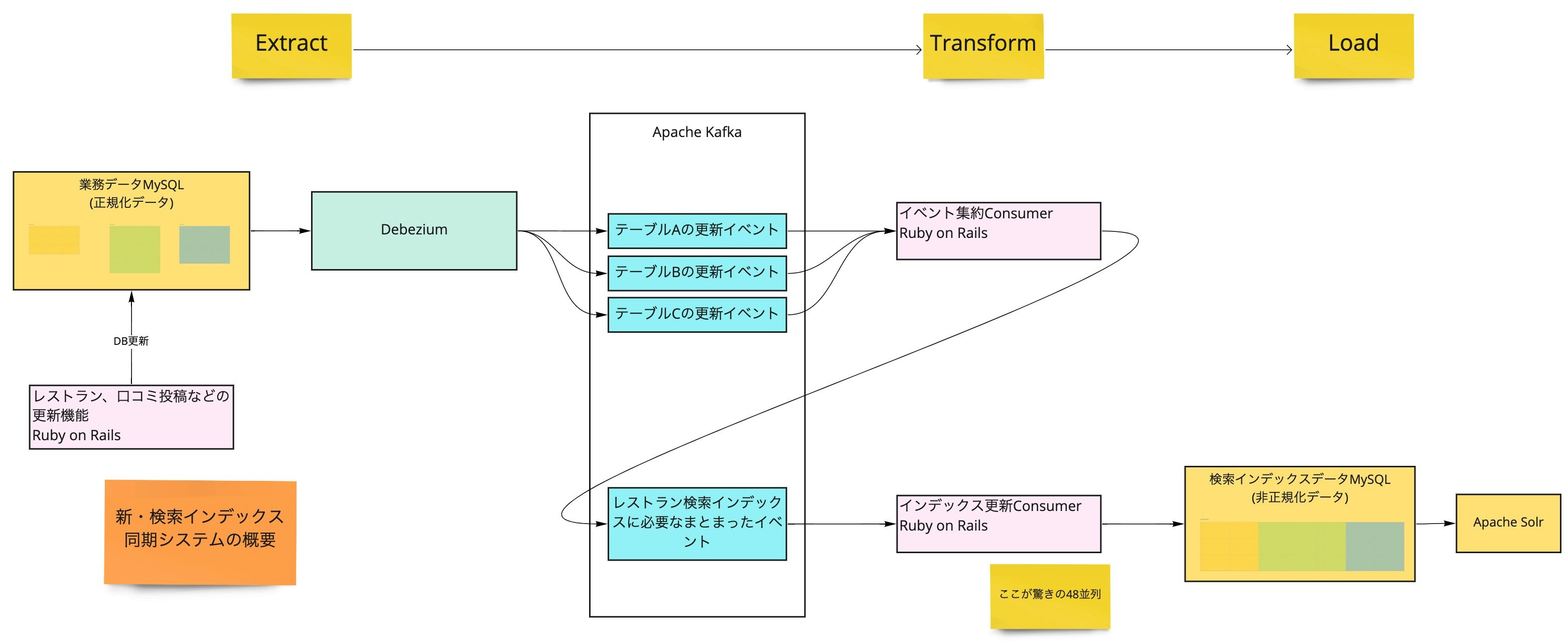
このシステムのパフォーマンスは目標を大きく上回り、なんと 全業務データが約 3.5 時間で同期できる ようになりました。7 これは例えば大きな仕様変更を午前9時頃にリリースすると、お昼ちょっと過ぎには新しい仕様の検索インデックスデータが生成できている計算になります。設計したマイクロサービス化チームでも内心びっくりです。
一番重要な改善目標を達成できたことをお伝えできたので、ここまで触れてなかった要素を落ち穂拾い的に説明します。
Change Data Capture の構成管理
Change Data Capture は今後のレストラン検索インデックス同期以外での利用も考えたいシステム基盤です。しかし初めて導入する技術なので最初はミニマルにレストラン検索インデックスに必要なテーブルだけキャプチャーして、イベントデータの保持は容量が想定しづらい期間指定ではなく、トピックごとの容量上限を設定する運用から始めました。
そうするとレストラン検索の仕様変更や Change Data Capture の応用範囲拡大に伴う設定変更の手法を確立する必要が出てきます。
Debezium は Kafka のデータ同期エコシステムである Kafka Connect の一種で、構成管理には Terraform の Kafka Provider が利用できます。
Kafka のトピック設定と Debezium のキャプチャー対象テーブルは Terraform の variable.tf ファイルとして GitHub リポジトリで管理されており、 Terraform に詳しくないエンジニアでも Pull request を出してキャプチャー対象を追加できるようになっています。
因みに Kafka Consumer は食べログ本体と同じ CI/CD パイプラインでデプロイ・再起動されています。検索インデックスデータの更新ロジックは従来のコードを完全に流用しているので、新システムでも開発チームのエンジニアは以前と変わらない開発体験を実現できています。
イベント集約 Consumer
この図で初めて登場する要素の「イベント集約 Consumer」は、正規化されている業務データのテーブルに対応して多数のトピックに分かれているイベントを、レストラン ID をキーとする1つのトピックに集約するコンポーネントです。キャプチャーした後でキーを変換すると正確な更新順序が失われるデメリットがあるのですが、業務データにはレストラン ID を持たないテーブルもあるので仕方なく設けています。検索インデックスデータ更新は結果整合性で充分なので正確な順序が維持されなくても問題はありません。 8
監視
安心して運用するには監視が不可欠です。
Kafka を中心としたエコシステムはモニタリングのソリューションも充分に揃っているので、特に大きな苦労はなく監視も構築できています。
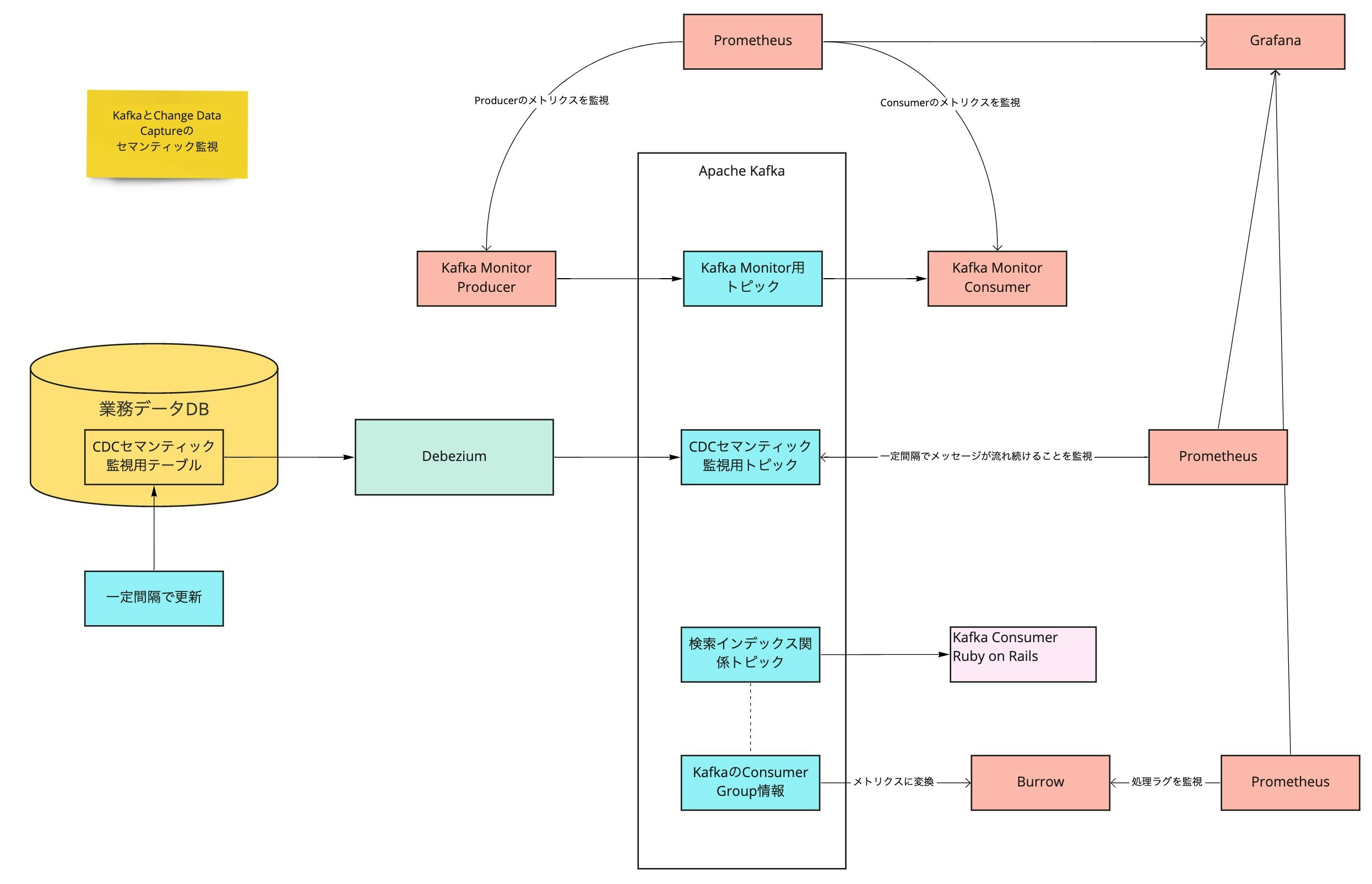
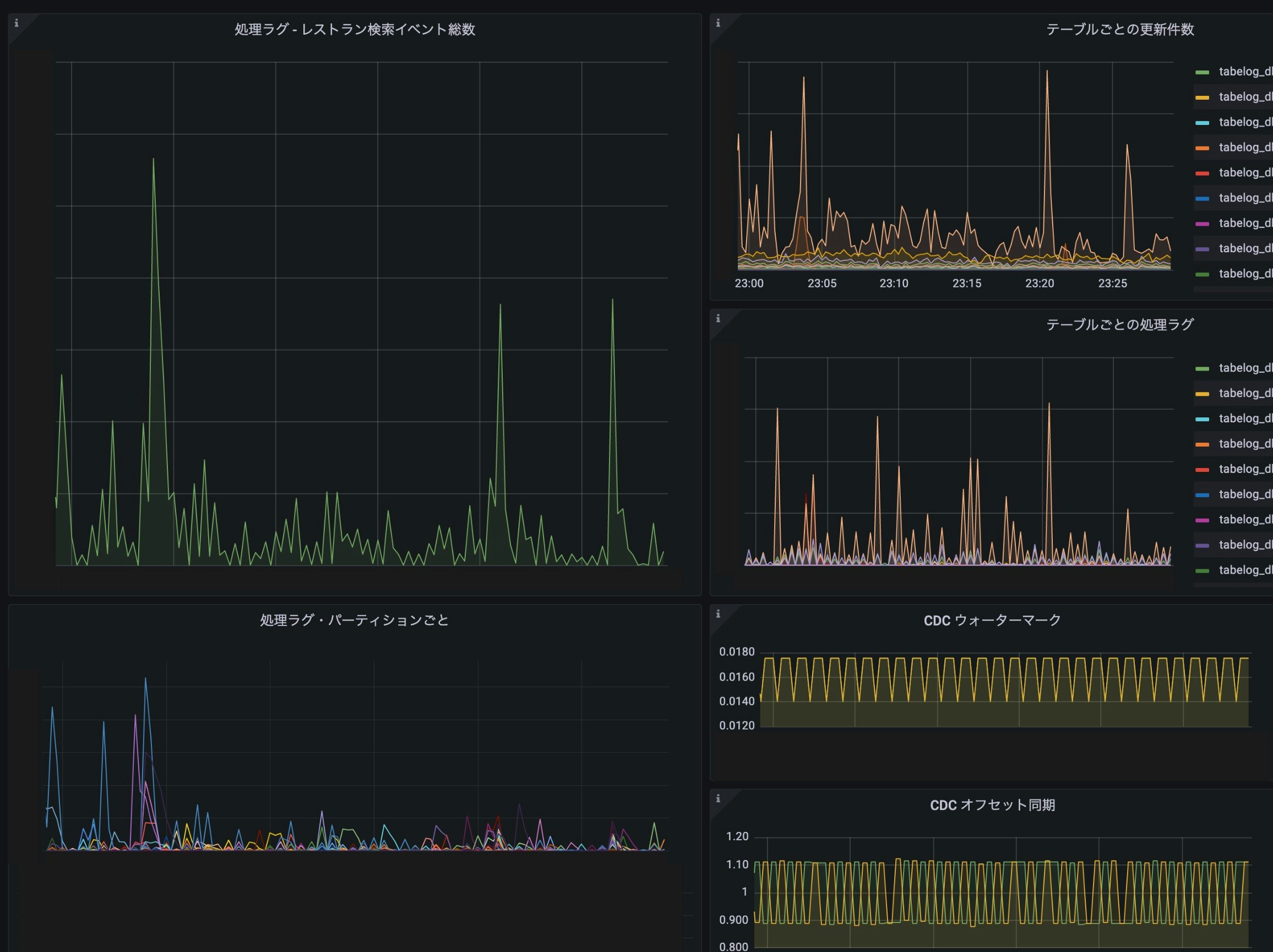
基本メトリクス監視の他に Kafka Monitor でセマンティック監視、Burrow で Consumer のラグ監視をしています。各種メトリクスは Prometheus と Grafana で可視化して、ラグが急激にスパイクしたり、長時間にわたってしきい値を越えたときには AlertManager から OpsGenie に発報しています。
キャプチャー件数、Consumer ラグのダッシュボードも用意しました。業務データを大量更新するメンテナンスの際、更新ペース調節の参考に利用されています。
まとめ
- レストラン検索インデックス同期処理全体を cron バッチから Kafka Consumer によるイベント駆動に切り替えることで業務データ更新から検索インデックスデータに反映するタイムラグを数秒程度に短縮できました
- Change Data Capture により業務データの更新検出を低負荷・低レイテンシに改善できました
- 検索インデックスデータの更新が競合しないように高度に並列化することでスループットを大きく向上できました
さいごに
この記事では省略した苦労話もあったのですが、今回は各技術が概ねしっくりはまって目標を大きく上回る改善ができました。しかし食べログのシステムにはまだ多くの課題があり、マイクロサービス化チームでは共に改善を進めてゆく仲間を募集中です。
本記事で伝えきれたかどうかわかりませんが、マイクロサービス化チームは戦略立案、導入技術の選定といったシステム改善の初期フェーズから意思決定に参加できる、大きな裁量とやりがいのあるポジションです。「ユーザーと飲食店をつなぐ」という食べログのコンセプトに共感された方はぜひご応募お願いします。
まずはカジュアル面談で情報交換をしてみたいという方も大歓迎です。その場合はご応募いただくときに、フリーテキスト記入欄に「カジュアル面談希望」とご記載ください。
明日は @skido の「食べログFEチームに新卒エンジニアが飛び込んでみた学び」です。お楽しみに!
-
We Need a New Weapon ! 映画 パシフィック・リム のクライマックスにおける台詞にしてサントラ25曲目のタイトルです ↩
-
レストラン名の表記ゆれを検索できるようにする変換や、口コミ、写真、メニューなどのテキスト集約が特に重たい処理です。一般的に人気のレストランほど口コミが多く検索インデックス更新に時間がかかり、しかも更新頻度が高いという傾向があります。これが後述する目標と達成値の差につながります ↩
-
技術部では目標達成ツールとして OKR を採用しており、クォーターごとに各チームでこのようなストレッチ目標を設定し部内で公開しています ↩
-
JSON 以外のフォーマットも選択できます。Avro を採用しているシステムが多いと思われますが、Avro のメリットを享受するには Schema Registry の安定運用が不可欠なので、最初から導入するのは障壁が高いと考え、今回は採用を見送りました ↩
-
他のバッチ処理も稼働しているのでこのスペックが無駄ということはありませんが、活用し切れてないことは確かでした ↩
-
言い換えるとパーティション数が並列度の上限になり、並列度が不足した場合はトピック内のパーティション分割数を増やす必要があります ↩
-
何故予想の倍以上のパフォーマンスが出たかというと各要素に想定以上の改善効果があった訳ではなく、リソース計算の根拠にした実績値が全店舗の平均ではなかったからでしょう。前述のように更新時間が長くかかる人気のレストランほど頻繁に更新されるので、実績値には偏りがあったのだと推測されます ↩
-
順序の整合性も重要なシステムでは Change Data Capture で Kafka に投入した時点からキーをシャッフルしない設計が必要になります ↩