はじめに
こんにちは、皆さん!@Raphael_de_murlです。今回はデータ分析の定番であるKaggleで提供されてるTitanicデータを利用してデータの前処理を行いたいと思います。
開発環境
OS: macOS Mojava 10.14.3
Memory: 16GB
開発ツール: Jupyter Notebook
データ前処理とは
簡単に定義すると以下のようです。
機械学習で行いたい作業に対してデータの読み込みやクリーニング、変形、整形といった作業のこと
なぜ前処理が重要なのか
機械学習のプロジェクトにおいて一番時間がかかる作業が前処理だと言われでます。作業全体を10にするとデータ前処理が8割以上になるほど重要な作業であります。そもそも何でこんなに時間がかかるのかをみると扱いたいデータがファイルやデータベースに保存されていても分析者が必要なデータの形式で保存されてない事があるためです。そのような場合に多くの分析者は、汎用的なプログラミング言語を用いて、データを別の形式に変換するためのアドホックな処理を行うという対応をとります。
欠損値の取り扱い
今回はこちらのTitanic: Machine Learning from Disasterサイトからデータを用意しました。では実際コートを見ながら説明して行きます。
import pandas as pd
from pandas import DataFrame
titanic_df = pd.read_csv('titanic.csv')
# 0~9行までのデータを表示
titanic_df.head(10)
これでtitanic.csvの生データを確認する事が出来ます。
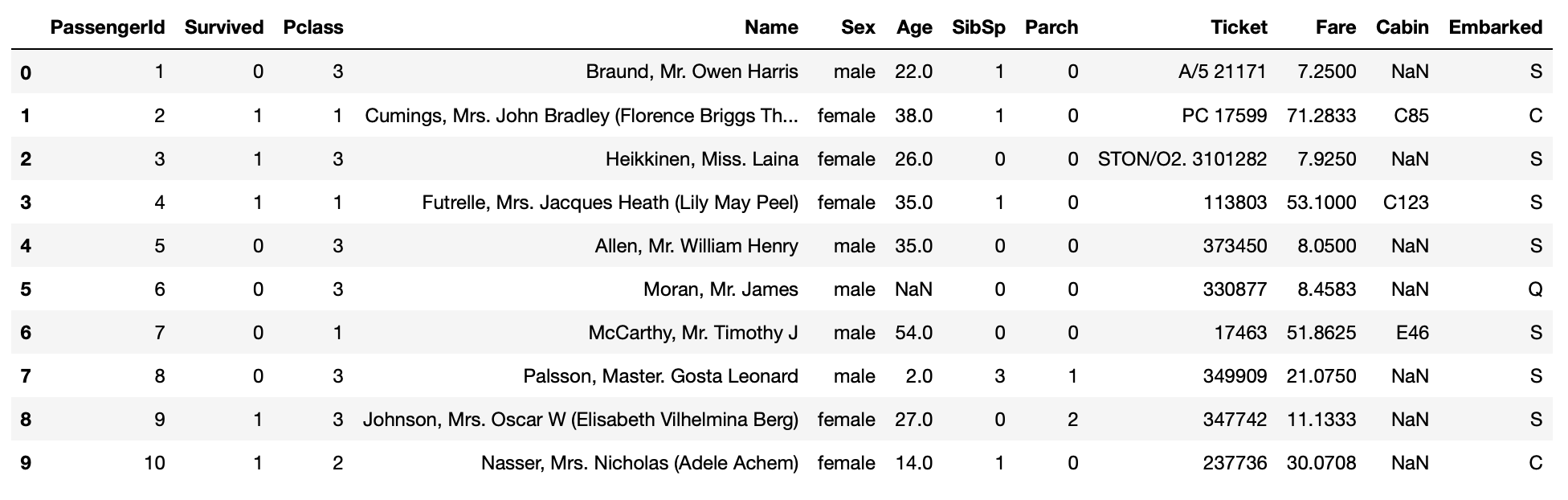
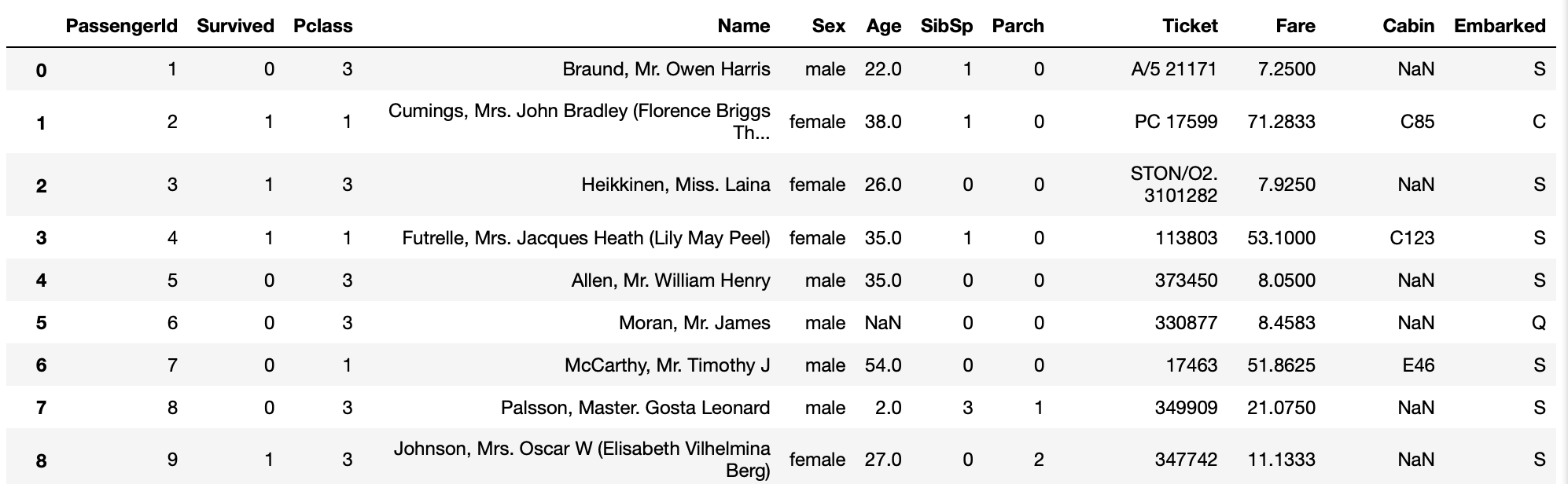
画像をよく見るとAge、Cabin列にNaNっていう文字がある事が分かります。Pandasのライブラリは、欠損値の表現として浮動小数値NaN(非数値、Not a Numberの意味)を使います。この値のことを、簡単に欠損値を見つけるための標識と読んでいます。ここで欠損値を列ごとに取りたいということであればPandasのisnull()メソッドを使うことで取ることが出来ます。
# 列ごとの欠損値をカウント
titanic_df.isnull().sum()
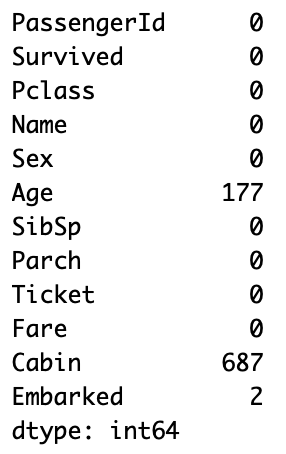
isnull()メソッドを使うことで一目で欠損値の把握ができることが分かります。
欠損値を削除する
欠損値を削除する方法はいくつかあります。Pandas.isnull()と真偽値の配列を用いて手動で削除するという方法も常に選択の1つではありますが、Pandas.dropna()を使う方法が便利です。このdropna()を使うことで欠損値を含んでいる全ての行を削除することが出来ます。
titanic_df.dropna()
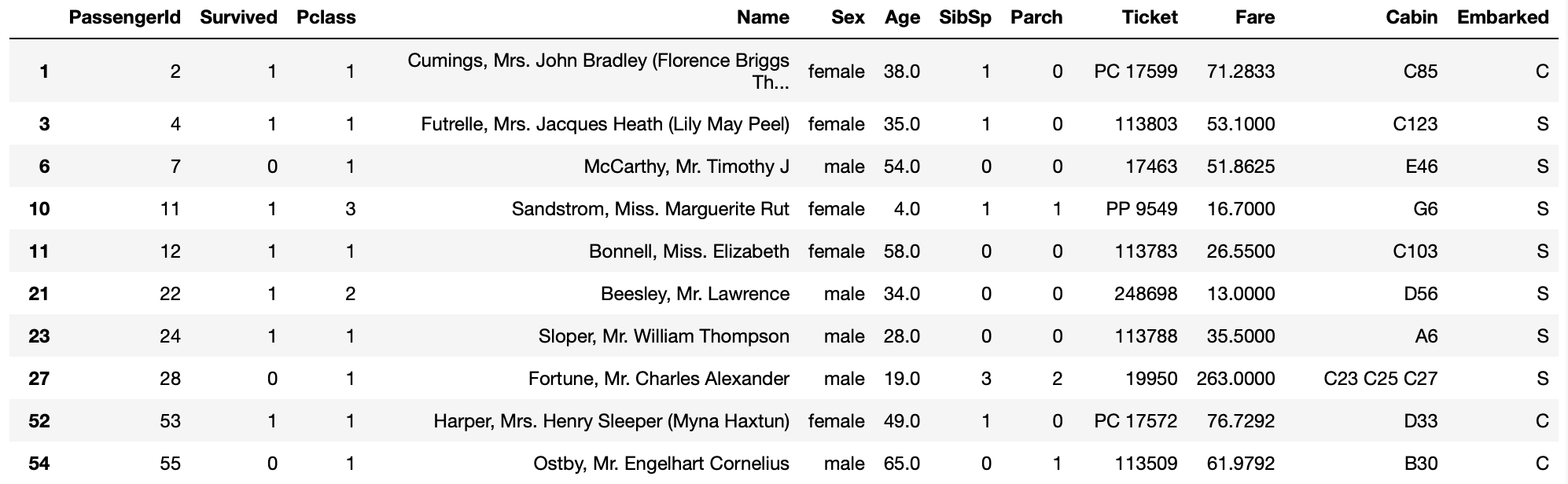
# 全てのデータがNaNである行のみを削除
titanic_df.dropna(how='all')
# 欠測値を含む列を削除
titanic_df.dropna(axis=1)
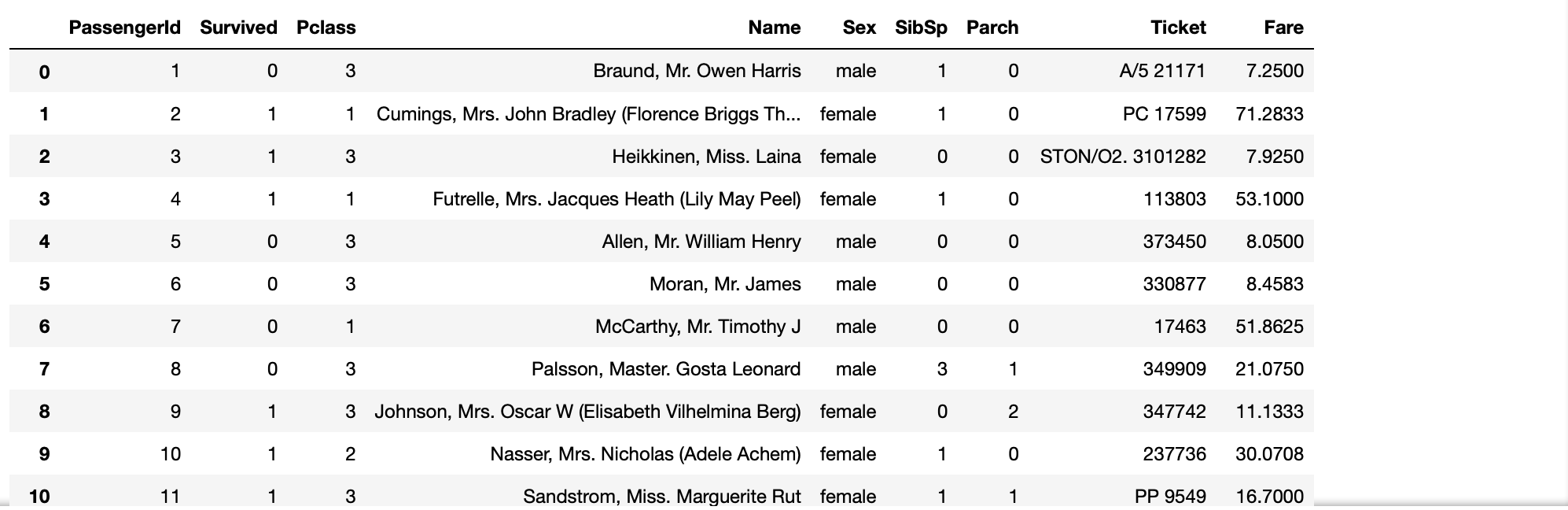
# 全ての列がNaNの行のみの列を削除
titanicdf.dropna(axis=1, how='all')
欠損値を穴埋めする
Pandas.dropna()で欠損値を簡単に削除することができますが、削除しすぎると後のデータ分析で役に立つ有効なデータも削除される場合もありますので、欠損値という【穴】を何らかの方法で埋めたい場合もあります。その役目を果たしてくれるのがfillnaメソッドです。簡単に言うと欠損値をある値で置き換えるということです。
titanic_df.fillna(0)
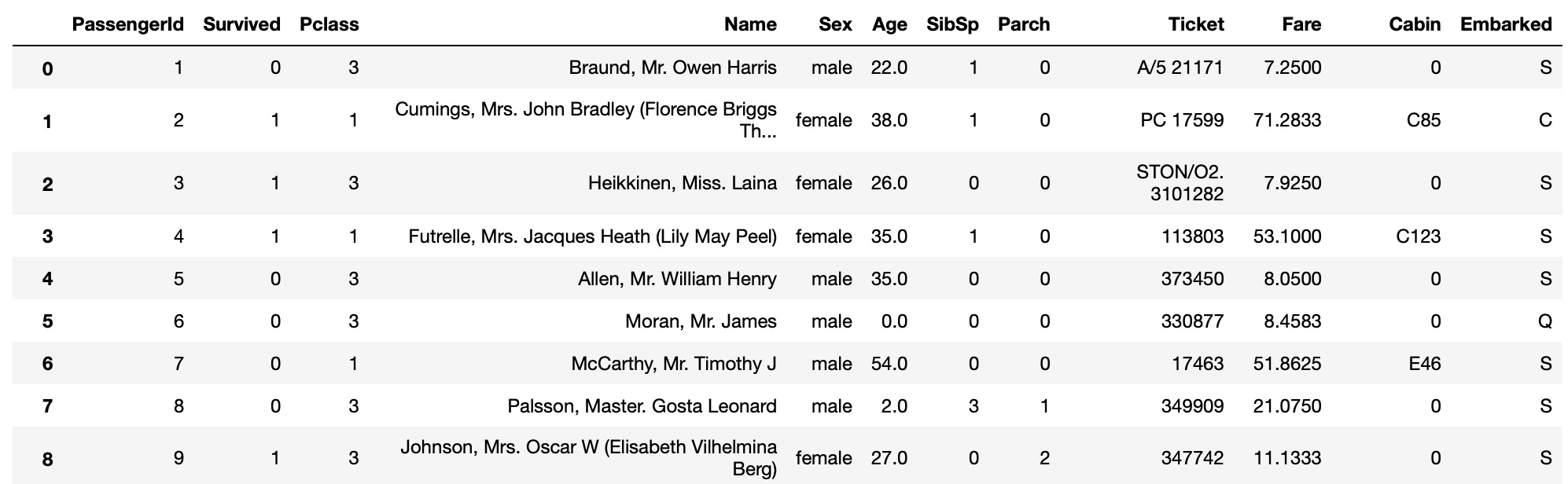
# 列ごとに異なる値を埋める
titanic_df.fillna({'Age':0, 'Cabin':'C01'})
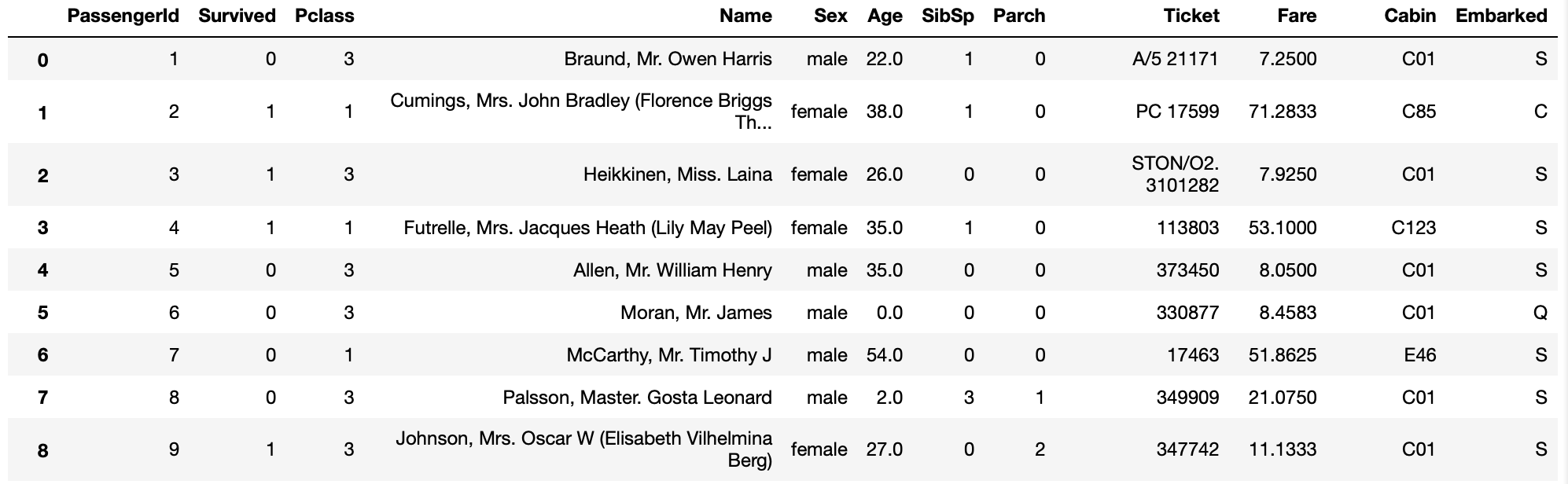
Pandas.fillna()を使うことで指定した値で埋めることができることが分かります。
# fillnaメソッドはデフォルトでは新しいオブジェクトを戻しますが、既存のオブジェクトを直接変更することも可能
titanic_df.fillna(0, inplace=True)
データ分析を行う
上でデータ前処理を行うことで欠損値を削除又は値を置き換えました。実際簡単な分析をやってみましょう。Pandas.dropna()を使って欠損値を扱います。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from pandas import DataFrame
%matplotlib inline
# cabin列の欠損値がある行を削除
drop_titanic_df = titanic_df['Cabin'].drop()
levels = []
for level in drop_titanic_df:
levels.append(level[0])
cabin_df = DataFrame(levels)
cabin_df.columns = ['Cabin']
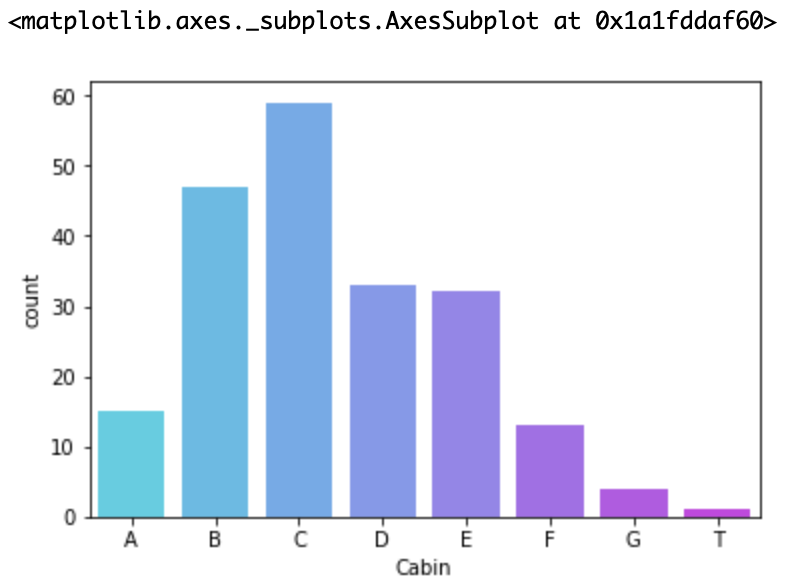
ここまでは欠損値を除いたCabin列をdrop_titanic_df変数に入れて新しいオブジェクトに生成しました。これを用いてカウントをしてみます。
sns.countplot('Cabin', data=cabin_df, palette='cool',order=sorted(set(levels)))
まとめに
サンプルとしてカウントしかやってないんですけれどもデータ前処理は生データによって前処理の手法が違うのでどの手法を選ぶべきなのかから始まるんだと思います。皆さんも手軽にやりながら勉強ができればと思います。この記事が少しでも気に入ったらいいねとフォロワー宜しくお願い致します。