KaggleのDigit Recognizerで画像認識を学びます。
Digit Recognizerは、手書き数字の画像を分類する、画像認識の入門コンペです。
私は最初の画像コンペにDigit Recognizerを選びました。
ノートブックの作成
Digit Recognizerのサイトにアクセスします。
CodeタブからNew Notebookボタンをクリックし、新しいノートブックを作成しました。
ライブラリの読み込み
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
データの読み込み
pandas.dataframeを用いて、学習データ、テストデータ、提出データをデータフレームとして代入します。
train = pd.read_csv("/kaggle/input/digit-recognizer/train.csv")
test = pd.read_csv("/kaggle/input/digit-recognizer/test.csv")
sample_submission = pd.read_csv("/kaggle/input/digit-recognizer/sample_submission.csv")
データの可視化
sns.countplot(x="label", data=train)
plt.show()
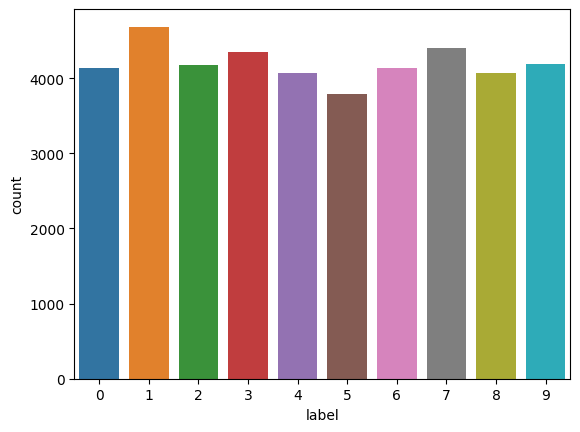
1が一番多く、5が一番少ないことがわかります。
また、どの数字も約4000ずつあることがわかります。
データ前処理
学習データとテストデータの抽出
X_train = train.drop('label', axis=1)
y_train = train['label']
X_test = test
データの形状の変更
X_train = X_train.values.reshape(-1, 28, 28, 1)
X_test = X_test.values.reshape(-1, 28, 28, 1)
データ型の変換
X_trainとX_testのデータ型をfloat32に変換します。
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
データの正規化
X_train = X_train / 255.0
X_test = X_test / 255.0
データの確認
plt.imshow(X_train[0][:, :, 0])
クラスラベルの変換
from keras.utils import to_categorical
y_train = to_categorical(y_train, num_classes=10)
学習データと検証データへの分割
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.1, random_state=0)
学習
CNN(畳み込みニューラルネットワーク)を用いて学習を行います。
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras.optimizers import Adam
datagen = ImageDataGenerator(rotation_range=10, zoom_range=0.1, width_shift_range=0.1, height_shift_range=0.1)
datagen.fit(X_train)
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=Adam(learning_rate=0.001), metrics=['accuracy'])
history = model.fit(datagen.flow(X_train, y_train, batch_size=128), epochs=30, validation_data=(X_val, y_val))
y_test = model.predict(X_test)
y_test = np.argmax(y_test, axis=1)
データの出力
提出データをsubmission.csvとして出力します。
sub = sample_submission
sub['Label'] = y_test
sub.to_csv("submission.csv", index=False)
Public Scoreは0.9906でした。
記事を書きながら、画像認識のコードの書き方を学ぶことができました。
Digit Recognizer以外のコンペにも挑戦したいです。
参考文献
https://atmarkit.itmedia.co.jp/ait/articles/2108/30/news033.html
https://tora3data.com/digit-recognizer-eda/
https://www.codexa.net/cnn-mnist-keras-beginner/