やりたいこと
・ファッションセンターしまむらの通販サイトに『安達としまむら』のアイテムが登場しているかを自動でチェックしたい
⇒背景として、「しまむらは不意打ち気味に熱いアイテムが登場する」という点や、「Octparse8」のようなスクレイピングツールを使っていたものの無償版ではアウトプット不可といった難点があったという経緯があります。
実装イメージ
・Seleniumを使ってブラウザ操作して目的の検索を実行する
・複数の検索ワードを事前に指定して、都度検索結果を取得する
・取得した結果をLINEに通知する
・該当がなければその旨を、該当があれば上限件数までアイテム情報を送信する
環境
** Windows10 64bit**
** Google Chrome 90.0.4430.93**
** Anaconda3**
仮想環境:python(3.7.3)
ライブラリ:pandas(1.1.2),ChromeDriver(90.0.4430.24)
事前準備
事前じゅびん。
Selenium WebDriverの導入
ブラウザ操作には各ブラウザに対応したWebDriverのダウンロードが必要です。
今回はこちらからChrome用のものを調達。
手順の詳細は割愛しますが、以下を参考までに。
⇒参考:たった3行のpythonで始めるSelenium入門
※実行環境のChromeと近似するバージョンのexeを使用しないとインスタンス生成時に下記のような例外となるので注意
SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 88
LINE Notifyのアクセストークン発行
LINEに通知を飛ばすためにこちらでアクセストークンを発行しました。
手順の詳細はやっぱり以下を参照で。
⇒参考:PythonでLINEにメッセージを送る
注意
・WEBスクレイピングは、WEBサイトの利用規定等で禁止されている場合があります。
今回利用したファッションセンターしまむらさんのサイトではそういった規定はありませんでしたが、やりようによっては負荷をかけることに変わりはないため、マナーの観点から今回書いたものは実装していません。
処理
1.ライブラリのインポート
# インポート
import requests
import pandas as pd
from selenium import webdriver
from urllib.parse import quote
from time import sleep
2.事前設定
chromedriver.exeの格納ディレクトリ、アクセス先のURL、LINE Notify APIのURL、同アクセストークン、結果通知用の画像なんかを格納しておきます。
# 初期設定
cd='D:\work\pyt\driver90.0.4430.24\chromedriver.exe' #WebDriverの格納先
b_url = 'https://www.shop-shimamura.com/disp/itemlist/?q=' #検索先のURL(パラメータを予め付加
r_list = [] #検索に該当するアイテム結果リスト
z_list = [] #該当がなかったキーワードの格納リスト
apiurl = 'https://notify-api.line.me/api/notify' #LINE Notify連携リクエスト先URL
access_token = 'xxxxxxxxxxx' #取得したLINE Notify連携用アクセストークンを設定
ngimage = 'D:\work\pyt\ngimage.jpg' #NG用送信画像
okimage = 'D:\work\pyt\okimage.jpg' #OK用送信画像
cnt = 0 #検索結果の該当件数
req_cnt = 0 #検索結果の送信件数
req_max = 10 #検索結果の送信件数上限
message = '' #送信本文
3.検索ワードの設定
検索したい単語をリストに入れておきます。
そんなに本格的なものにするつもりもなかったので、設定上限や論理演算子の考慮等はありません。
(URLエンコードで引き渡す値に気を遣えばすぐできそうではありますが)
あと。
残念ながら、誠に残念ながら、この記事作成時点で『安達としまむら』のアイテムはありません。
(故にこのAPを組んでいます)
とはいえ該当アイテムが存在する検索ワードを組み込まないと該当アイテムが存在した場合の検証ができないため、今回は『安達としまむら』関連以外のキーワードも組み込んでいます。
# 検索ワードのじゅびん
s_word=[]
s_word.append("安達としまむら")
s_word.append("安達桜")
s_word.append("島村抱月")
s_word.append("小泉のん") #テスト用ワード
s_word.append("前田佳織里") #テスト用ワード
4.検索
リストに入れた単語を一件ずつ検索にかけていきます。
# 検索文字列を1件ずつ検索
for keys in s_word:
#URL生成
k_word = quote(keys)
url = b_url + k_word
#WebDriver起動・検索結果ページアクセス
chrome = webdriver.Chrome(cd)
try:
chrome.get(url)
except HTTPError as e:
print(e)
else:
#検索結果判定
if len(chrome.find_elements_by_class_name("card__item")) == 0:
#該当がなければ次の検索文字列で検索
z_list.append("検索キー:" + keys + "⇒該当なし")
chrome.close()
sleep(5)
continue
#該当がある場合、アイテム結果リストへ登録
for element in chrome.find_elements_by_class_name("card__item"):
cnt += 1
item = element.text
item_trim = item.replace('\u3000','')
if 'NEW' not in item_trim and '在庫なし' not in item_trim:
item_conv1 = 'None\n' + item_trim
else:
item_conv1 = item_trim
atag = element.find_element_by_tag_name("a")
urltext = atag.get_attribute("href")
item_conv2 = urltext + '\n' + item_conv1
r_list.append(item_conv2.split())
chrome.close()
sleep(5)
# 該当全件をまとめてdataframeに格納
Resultd = pd.DataFrame(data=r_list, columns=['URL','tag','itemName','itemPrice','pre','web'])
Resultd.reindex(columns=['tag','itemName','itemPrice','pre','web','URL'])
この処理でChromeのウィンドウが起動して検索ワードの数だけ検索を繰り返します。
検索によって得られた商品リストは「Resultd」に格納し、後段のLINE通知にて使用します。


検索結果(Resultd)のDataFrameイメージ
| tag | itemName | itemPrice | pre | web | URL |
|---|---|---|---|---|---|
| NEW | レディースカーブパンツ(小泉のん) | 1,790円+税 | https://www.shop-shimamura.com/item/0152500006290/?cl=314 | ||
| NEW | レディースカーブパンツ(小泉のん) | 1,790円+税 | https://www.shop-shimamura.com/item/0152500006290/?cl=207 | ||
| NEW | レディースプリーツワイドパンツ(小泉のん) | 890円+税 | https://www.shop-shimamura.com/item/0152500006162/?cl=203 | ||
| NEW | レディースカーブパンツ(小泉のん) | 1,790円+税 | https://www.shop-shimamura.com/item/0152500006133/?cl=314 | ||
| ・・・ | (中略) | ||||
| レディースプルオーバー(小泉のん) | 990円+税 | https://www.shop-shimamura.com/item/0152100011833/?cl=104 | |||
| NEW | メンズ半袖Tシャツ(前田佳織里) | 890円+税 | 予約 | WEB限定 | https://www.shop-shimamura.com/item/0123200006320/?cl=213 |
| 在庫なし | メンズ半袖Tシャツ(前田佳織里) | 890円+税 | 予約 | WEB限定 | https://www.shop-shimamura.com/item/0123200006319/?cl=211 |
| 在庫なし | メンズTパーカ(前田佳織里) | 1,290円+税 | 予約 | WEB限定 | https://www.shop-shimamura.com/item/0123200006318/?cl=213 |
| 在庫なし | メンズTパーカ(前田佳織里) | 1,290円+税 | 予約 | WEB限定 | https://www.shop-shimamura.com/item/0123200006317/?cl=211 |
【Tips】検索手順について
今回、検索の仕方としてはちょっと本来とは異なるやり方をしました。
通常であれば以下のようなプロセスで検索を実行する想定です。
#1:WebDriver(=Chromeの画面)起動
chrome = webdriver.Chrome(cd)
#2:検索画面へ遷移
chrome.get("https://www.shop-shimamura.com/disp/itemlist/")
#3:検索ワード入力フィールド取得
search_box = chrome.find_element_by_name("q")
#4:検索ワードを入力
search_box.send_keys("安達としまむら")
#5:エンターキープッシュ送信(検索ボタンはないためエンターキー押下で検索実行
search_box.send_keys(Keys.ENTER)
ところがこれを実行すると5時点でWebページがエラー(Access Denied)となります。
(原因は特定できませんでした。どなたかわかるようでしたら教えてください……)
このため、今回はアクセスするURLに予めリクエストパラメータとして検索文字列を組み込んでいます。
k_word = quote(keys) #検索文字列をURLエンコード
url = b_url + k_word #リクエストパラメータを付与したURLとエンコード済み検索文字列を結合
chrome = webdriver.Chrome(cd) #WebDriver起動
chrome.get(url) #検索結果ページにアクセス
【Tips】要素の取得
今回、商品情報の取得元要素としてdivブロック[class="card__item"]より取得します。
しまむらオンラインストアの場合、だいたいこのへんに商品の基本情報は格納されています。
必要な情報を最低限の単位で個別にClass指定して取得したほうが良さそうですが横着しました。
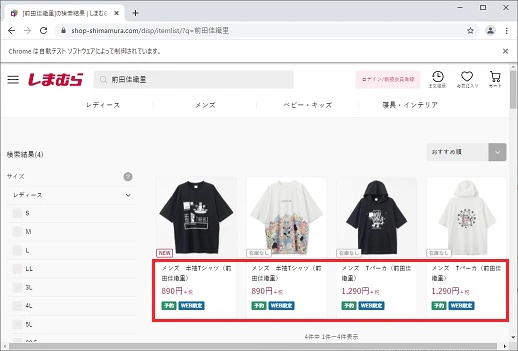
上の検索結果ページの赤枠部分が取得したい情報にあたりますが、これがだいたいブロック[class="card__item"]に収まってます。
<!-- 商品リスト START -->
<div class="card -col4">
<div class="card__item">
<!-- ~中略~ -->
<p class="itemName">メンズ 半袖Tシャツ(前田佳織里)</p>
<p class="itemPrice">890円<span>+税</span></p>
<p class="itemTag">
<span class="tag -pre">予約</span>
<span class="tag -web">WEB限定</span>
<!-- ~中略~ -->
</div>
<div class="card__item">
<!-- ~中略~ -->
<p class="itemName">メンズ Tパーカ(前田佳織里)</p>
<p class="itemPrice">1,290円<span>+税</span></p>
<p class="itemTag">
<span class="tag -pre">予約</span>
<span class="tag -web">WEB限定</span>
<!-- ~中略~ -->
</div>
この情報を参照して、lenを用いて該当アイテムが存在するかを判定したり、存在する場合は画面上に表示されているアイテムの件数分だけページ内に[class="card__item"]が複数存在するので、繰り返し参照してページ内の全アイテムの情報を取得したりします。
#検索結果の件数判定
if len(chrome.find_elements_by_class_name("card__item")) == 0:
#該当がなければ次の検索文字列で検索
#~中略~#
#該当がある場合、アイテム結果リストへ登録
for element in chrome.find_elements_by_class_name("card__item"):
item = element.text #"card__item"内のテキストを取得
【Tips】要素の取得2(リンク先URL)
該当する商品情報をLINEに通知するなら同時に商品ページにも飛べるようURLも取得しておきたいのですが、
for element in chrome.find_elements_by_class_name("card__item"):
item = element.text
の部分の処理で掴めるのはおそらくValue値(画面上から見える値)だけなので、これだけだとURLは取得できませんでした。
<!-- 商品リスト START -->
<div class="card -col4">
<div class="card__item">
<a href="/item/0123200006320/?cl=213" class="card__link">
<!-- ~中略~ -->
<p class="itemName">メンズ 半袖Tシャツ(前田佳織里)</p>
<p class="itemPrice">890円<span>+税</span></p>
<!-- ~中略~ -->
</a>
</div>
このため、「element」として取得した要素[div class="card__item"]の配下部品からさらに「a」タグを参照し、URLをテキストとして取得します。
atag = element.find_element_by_tag_name("a")
urltext = atag.get_attribute("href")
【Tips】要素の取得3(特定表示部品)
この項は蛇足なので読み飛ばしていただいて問題ないです。
アイテムによっては商品画像左下に「NEW」「在庫なし」といったラベルが付くものと付かないものがあります。

こういったものは、ソース上でもその表記のための要素(span class="tag -sold")があったりなかったりします。
対象アイテム以外は要素自体が作られない、というものであるようです。
<div class="card__item">
<figure class="card__thumb">
<span class="tag -sold">在庫なし</span>
</figure>
<div class="card__detail">
<p class="itemName">レディース 袖ポケットぬいぐるみTシャツ(小泉のん)</p>
<p class="itemPrice">990円<span>+税</span></p>
</p>
</div>
</div>
<div class="card__item">
<figure class="card__thumb">
</figure>
<div class="card__detail">
<p class="itemName">レディース パンツ(小泉のん)</p>
<p class="itemPrice">1,790円<span>+税</span></p>
</p>
</div>
</div>
「element」として取得した要素[div class="card__item"]から抽出したテキストには、こういったラベルがあればテキストに含まれ、なければテキストにも含まれないので、(加えて、element.textで取得するとこのラベルは先頭に並ぶ文字列であるため)有無判断が必要になりました。
個別にclass指定してテキスト取得していれば問題ないので、やはり横着はよくない、ということが早くも証明されました。
if 'NEW' not in item_trim and '在庫なし' not in item_trim:
item_conv1 = 'None\n' + item_trim
else:
item_conv1 = item_trim
5.結果をLINEへ通知
# 結果をLINEへ送信
headers = {'Authorization': 'Bearer ' + access_token}
if cnt == 0:
#該当がなかった場合、無念のメッセージと画像をLINEへ通知
message = 'なんだばしゃあああああ!!'
image = ngimage
payload = {'message': message}
files = {'imageFile': open(image, 'rb')}
#結果送信
r = requests.post(apiurl, headers=headers, params=payload, files=files,)
else:
#該当があった場合、喚起のメッセージと画像をLINEへ通知
message = 'しまむらのアイテム……見てみたい……'
image = okimage
payload = {'message': message}
files = {'imageFile': open(image, 'rb')}
#結果送信
r = requests.post(apiurl, headers=headers, params=payload, files=files,)
#さらに商品リストを1件ずつ読み込みLINEへ通知(事前設定した上限件数まで
for rec_tag,rec_iName,rec_iPrice,rec_pre,rec_web,rec_URL in zip(Resultd['tag'],Resultd['itemName'],Resultd['itemPrice'],Resultd['pre'],Resultd['web'],Resultd['URL']):
#メッセージ作成
message = ""
if rec_tag != None:
message= message + '\n' + rec_tag #タグ(NEW/在庫なし)
message= message + '\n' + rec_iName #商品情報
message= message + '\n' + rec_iPrice #価格
if rec_pre != None:
message= message + '\n' + rec_pre #予約対象
if rec_web != None:
message= message + '\n' + rec_web #WEB限定
message= message + '\n' + rec_URL
payload = {'message': message}
#商品情報送信
r = requests.post(apiurl, headers=headers, params=payload, )
req_cnt += 1
#送信済み件数の判断
if req_cnt == req_max:
#上限件数まで達したら送信終了
break
■実行結果:「検索による該当アイテムあり」の場合
検索による該当アイテムが存在する(下記の検索ワードで検索した)場合は……
# 検索ワードのじゅびん
s_word=[]
s_word.append("安達としまむら")
s_word.append("安達桜")
s_word.append("島村抱月")
s_word.append("小泉のん") #テスト用ワード
s_word.append("前田佳織里") #テスト用ワード


こういった形で上限件数(10件)分、アイテム情報が通知されました。
また、通知メッセージ内のURLから各アイテムページへ飛ぶこともできるので、だいたいよさそうです。
■実行結果:「検索による該当アイテムなし」の場合
検索による該当アイテムが存在しない(下記の検索ワードで検索した)場合は……
# 検索ワードのじゅびん
s_word=[]
s_word.append("安達としまむら")
s_word.append("安達桜")
s_word.append("島村抱月")
# s_word.append("小泉のん") #テスト用ワード
# s_word.append("前田佳織里") #テスト用ワード

NGであったことを現す安達の悲しそうな顔と感情由来の新言語が飛んできました。
こちらも(心が痛む点以外は)問題なさそうです。
実装
コード全体です。
エラー考慮なんかが徹底できてはいませんが、ひとまず最低限の要件は満たしそうです。
# インポート
import requests
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from urllib.parse import quote
from time import sleep
import schedule
# スクレイピング
def shima_scp_job():
#初期設定
cd="D:\work\pyt\driver90.0.4430.24\chromedriver.exe"
b_url = "https://www.shop-shimamura.com/disp/itemlist/?q="
r_list = []
z_list = []
apiurl = "https://notify-api.line.me/api/notify"
access_token = 'xxxxxxxxxxx' #アクセストークンを入力
ngimage = 'D:\work\pyt\ngimage.jpg' # png or jpg を指定
okimage = 'D:\work\pyt\okimage.jpg' # png or jpg を指定
cnt = 0 #検索結果の該当件数
req_cnt = 0 #検索結果の送信件数
req_max = 10 #検索結果の送信件数上限
message = "" #送信本文
#検索ワードのじゅびん
s_word=[]
s_word.append("安達としまむら")
# s_word.append("小泉のん")
# s_word.append("前田佳織里")
s_word.append("安達桜")
s_word.append("島村抱月")
#検索文字列を1件ずつ検索
for keys in s_word:
#URL生成
url = ''
k_word = quote(keys)
url = b_url + k_word
#WebDriver起動・検索結果ページアクセス
chrome = webdriver.Chrome(cd)
try:
chrome.get(url)
except HTTPError as e:
print(e)
else:
#検索結果判定
if len(chrome.find_elements_by_class_name("card__item")) == 0:
#該当がなければ次の検索文字列で検索
z_list.append("検索キー:" + keys + "⇒該当なし")
chrome.close()
sleep(5)
continue
#該当がある場合、アイテム結果リストへ登録
for element in chrome.find_elements_by_class_name("card__item"):
cnt += 1
item = element.text
item_trim = item.replace('\u3000','')
if 'NEW' not in item_trim and '在庫なし' not in item_trim:
item_conv1 = 'None\n' + item_trim
else:
item_conv1 = item_trim
atag = element.find_element_by_tag_name("a")
urltext = atag.get_attribute("href")
item_conv2 = urltext + '\n' + item_conv1
r_list.append(item_conv2.split())
chrome.close()
sleep(5)
#該当全件をまとめてdataframeに格納
Resultd = pd.DataFrame(data=r_list, columns=['URL','tag','itemName','itemPrice','pre','web'])
Resultd.reindex(columns=['tag','itemName','itemPrice','pre','web','URL'])
#結果をLINEへ送信
headers = {'Authorization': 'Bearer ' + access_token}
if cnt == 0:
#該当がなかった場合、無念のメッセージと画像を通知
message = 'なんだばしゃあああああ!!'
image = ngimage
payload = {'message': message}
files = {'imageFile': open(image, 'rb')}
#結果送信
r = requests.post(apiurl, headers=headers, params=payload, files=files,)
else:
#該当があった場合、喚起のメッセージと画像を通知
message = 'しまむらのアイテム……見てみたい……'
image = okimage
payload = {'message': message}
files = {'imageFile': open(image, 'rb')}
#結果送信
r = requests.post(apiurl, headers=headers, params=payload, files=files,)
#商品リストを上限件数分まで通知
for rec_tag,rec_iName,rec_iPrice,rec_pre,rec_web,rec_URL in zip(Resultd['tag'],Resultd['itemName'],Resultd['itemPrice'],Resultd['pre'],Resultd['web'],Resultd['URL']):
#通知する商品情報メッセージを作成
message = ""
if rec_tag != None:
message= message + '\n' + rec_tag #タグ(NEW/在庫なし)
message= message + '\n' + rec_iName #商品情報
message= message + '\n' + rec_iPrice #価格
if rec_pre != None:
message= message + '\n' + rec_pre #予約対象
if rec_web != None:
message= message + '\n' + rec_web #WEB限定
message= message + '\n' + rec_URL
payload = {'message': message}
#商品情報送信
r = requests.post(apiurl, headers=headers, params=payload, )
req_cnt += 1
#送信済み件数の判断
if req_cnt == req_max:
#上限件数まで達したら送信終了
break
# 毎日10時にjobを実行
schedule.every().day.at("10:00").do(shima_scp_job)
while True:
schedule.run_pending()
time.sleep(1)
まとめ
・スクレイピングをやってみましたが、要件が簡単なものだったのでさほど難しいことはありませんでしたが、複雑なことをやろうとするとサイト毎の特徴に対応する必要がありそうな印象でした。
・LINE通知はお手軽便利で、スクレイピングに限らず自動化のお供になりそうです。
・『安達としまむら』おすすめです。