Hee-AI (へぇあい)
Hee-AIを作りました.

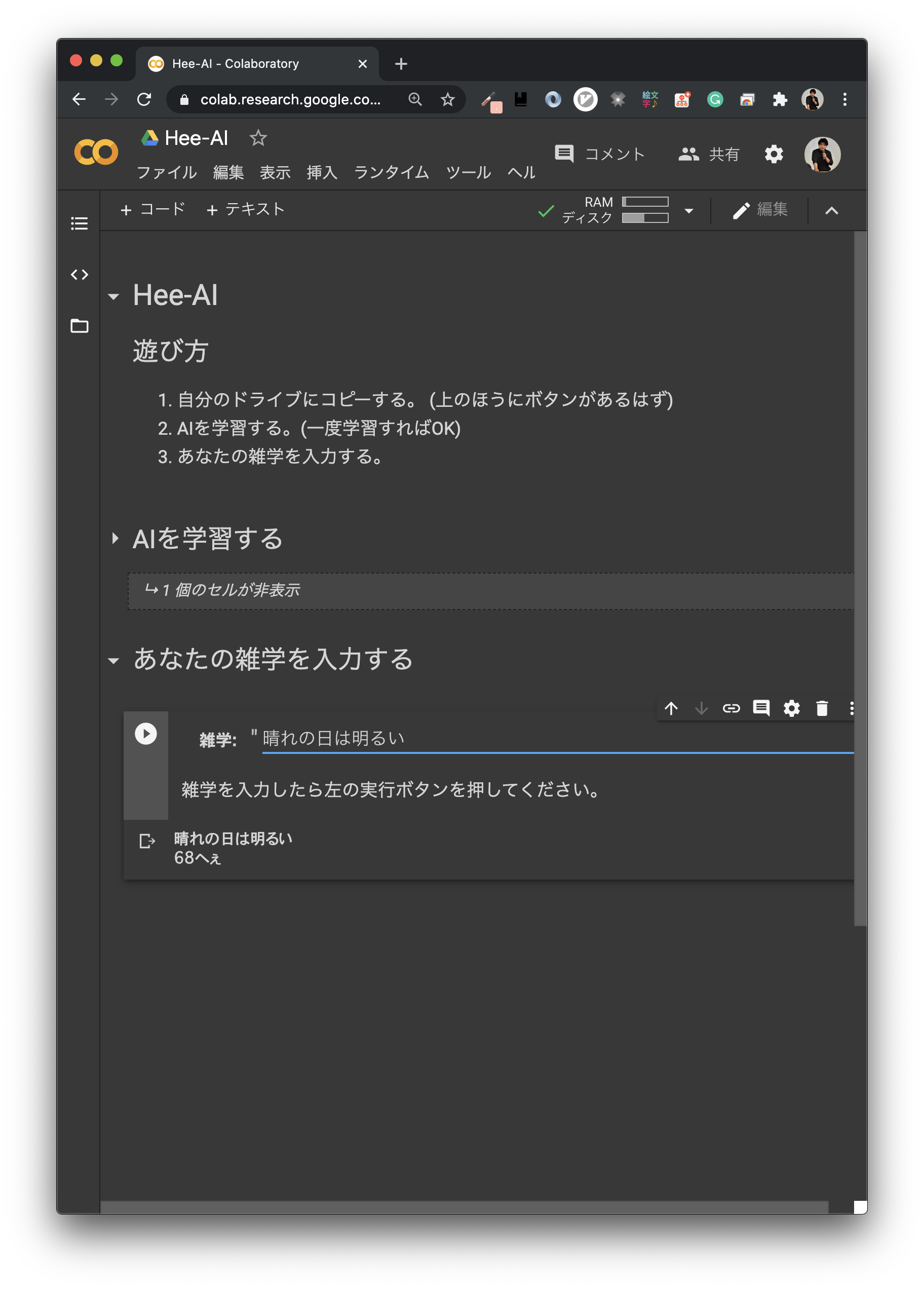
このGoogle Colabは編集できない状態で公開しています. 自分のドライブにコピーしてからぜひ遊んでみてください! (PC環境推奨)
ソースコードも公開しておりますので, 参考までにご覧ください.
制作物語
これは全て2020年6月26日に起こった出来事です.
動機
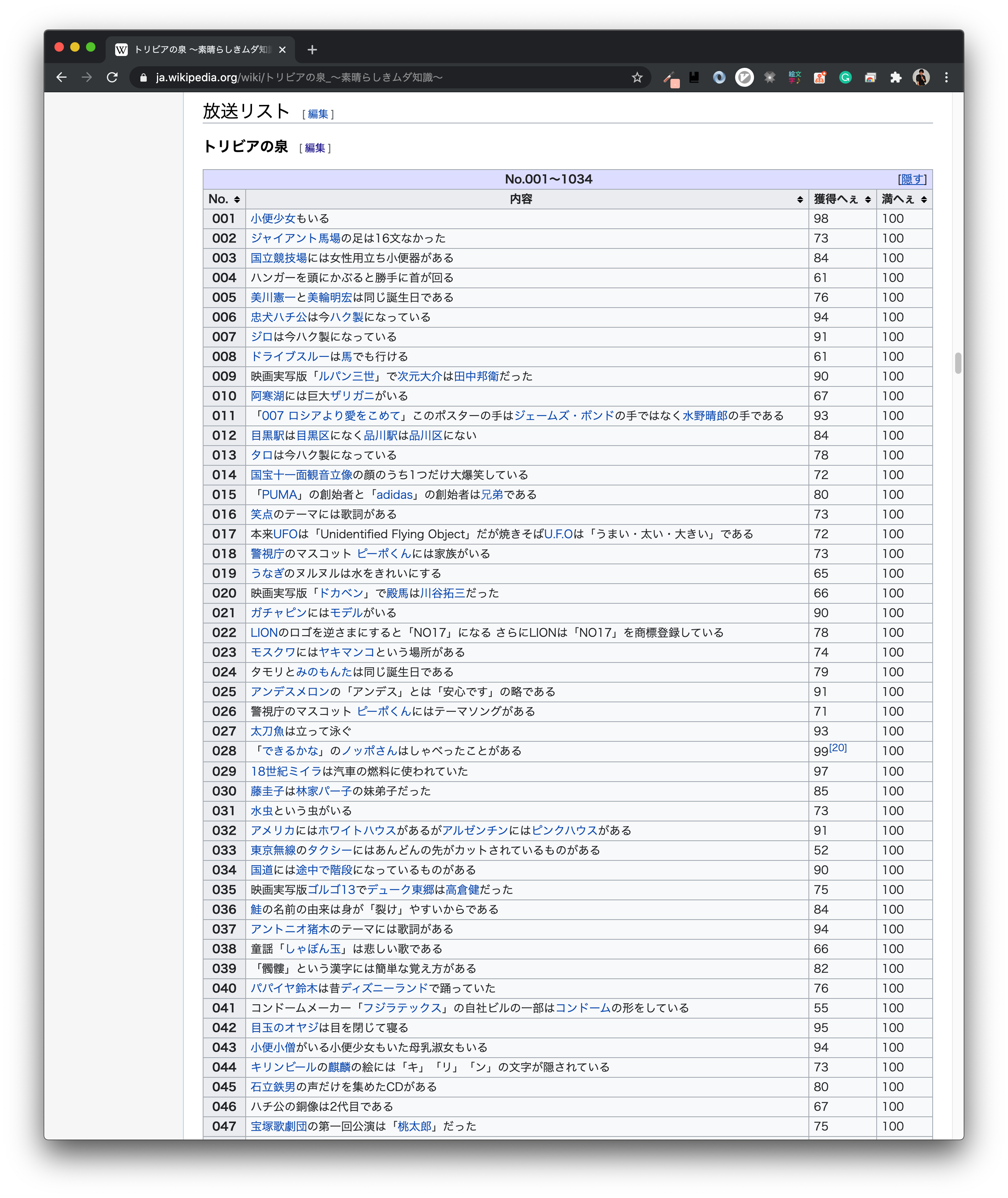
趣味がWikipedia探索の僕ですが, ある日のことトリビアの泉のページに番組で紹介された過去すべてのトリビアとそのいいねが記載されていることを知りました.
僕は迷いもなく「これは回帰問題になるじゃないか...!!!」と思いました.
早速デスクトップを立ち上げました.
計画
最終的に多くの人に遊んでもらいたいので, 最初はWebサービスにしようかと考えましたが, 1日以上研究をストップすることはしたくなかったので, それは諦めました. Google Colab上で実行可能にすることで, 個々のドライブ上にコピーしてもらえば簡単に遊べるので, その路線で計画を練って行きました.
Google Colab
Google Colab (Google Colaboratory)はGoogleが提供するサービスで, Google Drive上のJupyter NotebookをGoogleさんのマシンで実行できる代物です. GPUも使えます. ローカルで計算する必要がないためとても重宝できるものなのですが, なにせJupyter Notebookですので, 僕のように階層構造が大好きな人間にはあまり向きません.
しかし今回はそんなこと言ってられません. しかも, できれば一つのセルを実行するだけで全てが完結するようにし, できるだけユーザーの負担を減らすべきです. しかし, 学習プロセスと推論プロセスを同じセルにしてしまうと, 推論する度に学習が回ってしまいますので, そこだけは分ける必要があります. なので, 完成形としては以下のような2つのセルのみで構成されたGoogle Colabを計画しました.
- 学習のセル
- 推論のセル
そして, 省ける処理はできるだけ省いた状態で公開したいと考えました. そこで, Google Golab上ではディレクトリ構造を持つGithubリポジトリをcloneしてきたりせず, install系以外は完結したものにしようと決めました. 従って, Wikipediaのデータなどもpythonの辞書型で先に保持しておいたり, 一つのpythonファイルにするためにstickytapeというpythonパッケージを用いたり, 様々な工夫を凝らしました.
Qiita夏祭り2020
ということで, Colab上のpythonのみでAIアプリを作るという強い制約プレイになりましたので, 現在開催中のQiita夏祭り2020に応募することにもしました.
こちらの企画では, 以下の3つのお題に沿った記事を募集しています.
- 〇〇(言語)のみを使って、今△△(アプリ)を作るとしたら
- システム開発における過去の失敗と乗り越えた方法について共有しよう!
- 【機械学習】"やってはいけない” アンチパターンを共有しよう!
自分は1.かなぁと思って書き始めたのですが, やっているうちに3.の機械学習アンチパターンにも触れられそうかと考えたので, そちらにも話題を乗せていこうかと思います.
話がそれました.
制作物語に戻りましょう.
スクレイピング
ますはスクレイピングです. 最初はHTMLをコピペしてきてvimのマクロで自動整形とかできないかなと15分ほど格闘したのですが, いくつか異常値があり, それに対応するためにはプログラミングの方がいいかと諦めました.
実際に書いたスクレイピングのコードはこんな感じです.
import urllib
from bs4 import BeautifulSoup
URL = "https://ja.wikipedia.org/wiki/%E3%83%88%E3%83%AA%E3%83%93%E3%82%A2%E3%81%AE%E6%B3%89_%E3%80%9C%E7%B4%A0%E6%99%B4%E3%82%89%E3%81%97%E3%81%8D%E3%83%A0%E3%83%80%E7%9F%A5%E8%AD%98%E3%80%9C"
def get_text(tag):
text = tag.text
text = text.replace('\n', '')
text = text.replace('[18]', '')
text = text.replace('[19]', '')
text = text.replace('[20]', '')
text = text.replace('[21]', '')
text = text.replace('[22]', '')
return text
if __name__ == "__main__":
html = urllib.request.urlopen(URL)
soup = BeautifulSoup(html, 'html.parser')
trivia_table = soup.find('table', attrs={'class': 'sortable'})
trivias_list = []
for i, line in enumerate(trivia_table.tbody):
if i < 3:
continue
if line == '\n':
continue
id = line.find('th')
content, hee, man_hee = line.find_all('td')
id, content, hee, man_hee = map(get_text, [id, content, hee, man_hee])
if hee == '?':
continue
trivias_list.append({'id': id, 'content': content, 'hee': int(hee), 'man_hee': int(man_hee)})
print(trivias_list)
ざっくり説明しますと,
- BeautifulSoupの
soup.find()を用いてwikipediaのトリビアのページから全てのトリビアが乗っているtableを見つけてくる. -
continueのところらへんで関係のない行を飛ばす例外処理を行いながら一行一行読み込んでいく. - 所望の行を手に入れても注釈など意味のない文字列があるので
get_text関数で整形. -
trivial_listにidや文章やへぇの数などを格納していく.
という流れです.
特徴量エンジニアリング
さて, データが揃いましたので機械学習屋さんの見せ所, 特徴量エンジニアリングです. 正直やる前からわかっていたのですが, どうせいい精度は出ません. 高々20文字程度の一文が1000ちょっとあるくらいでは絶対に無理があります. しかし, やるからには最低減やるべきことはやろうと以下のように特徴量を抽出しました.
- 文章の長さ
- 単語の数
- 平仮名の数
- カタカナの数
- 漢字の数
- 英語の数
- tfidf
- へぇの数/満へぇ
です.
最後のへぇの数/満へぇに関してはこれを目的変数としています. へぇの数をそのまま使用してしまうと, トリビアの泉のスペシャル会では200へぇが満へぇの時もありましたので, スケールが異なってしまいます. 従って, へぇの数/満へぇという0-1に正規化された値を目的変数としました.
コードはこんな感じです.
import re
import MeCab
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
# Mecab
tagger = MeCab.Tagger('-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
tagger.parse('')
# lambda
re_hira = re.compile(r'^[あ-ん]+$')
re_kata = re.compile(r'[\u30A1-\u30F4]+')
re_kanj = re.compile(r'^[\u4E00-\u9FD0]+$')
re_eigo = re.compile(r'^[a-zA-Z]+$')
is_hira = lambda word: not re_hira.fullmatch(word) is None
is_kata = lambda word: not re_kata.fullmatch(word) is None
is_eigo = lambda word: not re_eigo.fullmatch(word) is None
is_kanj = lambda word: not re_kanj.fullmatch(word) is None
# tl: trivias_list
def normalize_hee(tl):
for i in range(len(tl)):
tl[i]['norm_hee'] = tl[i]['hee'] / tl[i]['man_hee']
return tl
def wakati(text):
node = tagger.parseToNode(text)
l = []
while node:
if node.feature.split(',')[6] != '*':
l.append(node.feature.split(',')[6])
else:
l.append(node.surface)
node = node.next
return ' '.join(l)
def preprocess(tl):
tl = normalize_hee(tl)
for i in tqdm(range(len(tl))):
tl[i]['wakati_content'] = wakati(tl[i]['content'])
return tl
def count_len(sentence):
return len(sentence)
def count_word(sentence):
return len(sentence.split(' '))
def count_kata(sentence):
cnt = 0; total=0
for word in sentence.split(' '):
if word == '': continue
total += 1
if is_kata(word): cnt += 1
return cnt/total
def count_hira(sentence):
cnt = 0; total=0
for word in sentence.split(' '):
if word == '': continue
total += 1
if is_hira(word): cnt += 1
return cnt/total
def count_eigo(sentence):
cnt = 0; total=0
for word in sentence.split(' '):
if word == '': continue
total += 1
if is_eigo(word): cnt += 1
return cnt/total
def count_kanj(sentence):
cnt = 0; total=0
for word in sentence.split(' '):
if word == '': continue
total += 1
if is_kanj(word): cnt += 1
return cnt/total
def get_features(trivias_list, content=None, mode='learn'):
trivias_list = preprocess(trivias_list)
trivias_df = pd.DataFrame(trivias_list)
wakati_contents_list = trivias_df['wakati_content'].values.tolist()
word_vectorizer = TfidfVectorizer(max_features=5)
word_vectorizer.fit(wakati_contents_list)
if mode == 'inference':
content = [{'content': content, 'wakati_content': wakati(content)}]
content_df = pd.DataFrame(content)
wakati_content_list = content_df['wakati_content'].values.tolist()
tfidf = word_vectorizer.transform(wakati_content_list)
content_df = pd.concat([
content_df,
pd.DataFrame(tfidf.toarray())
], axis=1)
num_len_df = content_df['wakati_content'].map(count_len)
num_word_df = content_df['wakati_content'].map(count_word)
num_hira_df = content_df['wakati_content'].map(count_hira)
num_kata_df = content_df['wakati_content'].map(count_kata)
num_eigo_df = content_df['wakati_content'].map(count_eigo)
num_kanj_df = content_df['wakati_content'].map(count_kanj)
content_df['num_len'] = num_len_df.values.tolist()
content_df['num_word'] = num_word_df.values.tolist()
content_df['num_hira'] = num_hira_df.values.tolist()
content_df['num_kata'] = num_kata_df.values.tolist()
content_df['num_eigo'] = num_eigo_df.values.tolist()
content_df['num_kanj'] = num_kanj_df.values.tolist()
content_df = content_df.drop('content', axis=1)
content_df = content_df.drop('wakati_content', axis=1)
return content_df
tfidf = word_vectorizer.transform(wakati_contents_list)
all_df = pd.concat([
trivias_df,
pd.DataFrame(tfidf.toarray())
], axis=1)
num_len_df = all_df['wakati_content'].map(count_len)
num_word_df = all_df['wakati_content'].map(count_word)
num_hira_df = all_df['wakati_content'].map(count_hira)
num_kata_df = all_df['wakati_content'].map(count_kata)
num_eigo_df = all_df['wakati_content'].map(count_eigo)
num_kanj_df = all_df['wakati_content'].map(count_kanj)
all_df['num_len'] = num_len_df.values.tolist()
all_df['num_word'] = num_word_df.values.tolist()
all_df['num_hira'] = num_hira_df.values.tolist()
all_df['num_kata'] = num_kata_df.values.tolist()
all_df['num_eigo'] = num_eigo_df.values.tolist()
all_df['num_kanj'] = num_kanj_df.values.tolist()
if mode == 'learn':
all_df = all_df.drop('id', axis=1)
all_df = all_df.drop('hee', axis=1)
all_df = all_df.drop('man_hee', axis=1)
all_df = all_df.drop('content', axis=1)
all_df = all_df.drop('wakati_content', axis=1)
return all_df
モデリング
モデルはlightgbmを選択しました. 理由はめんどくさかったからです.
他のモデルなら何が使えるやろ, nn使うなら正規化しないといけないし...んー、勾配ブースティング!
という思考回路です. 笑
しかし, やるからには最低限のことはしました.
- 評価指標はMSE
- KFoldで5セットのテストデータに対してMSEを計算
- 5セットのMSEの平均値を目的値として, optunaでハイパーパラメータ探索
- max_depth: 1-20
- learning_rate: 0.001-0.1
- num_leaves: 2-70
最終的なbest MSEは0.014程度でした.
つまり, 一つのトリビアに対する誤差の2乗が0.014くらいということですので, ルートを取ると0.118程度, 正規化していましたので100かけると, 11.8.
従って, 大体11.8へぇくらいの誤差となりました. (へぇ...)
コードはこんな感じです.
import os
import optuna
import numpy as np
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import KFold
from data.loader import load_data
from data.feature import get_features
from data.trivias_list import trivias_list
def objective(trial):
max_depth = trial.suggest_int('max_depth', 1, 20)
learning_rate = trial.suggest_uniform('learning_rate', 0.001, 0.1)
params = {
'metric': 'l2',
'num_leaves': trial.suggest_int("num_leaves", 2, 70),
'max_depth': max_depth,
'learning_rate': learning_rate,
'objective': 'regression',
'verbose': 0
}
mse_list = []
kfold = KFold(n_splits=5, shuffle=True, random_state=1)
for train_idx, valid_idx in kfold.split(X, y):
X_train = X.iloc[train_idx]
y_train = y.iloc[train_idx]
X_valid = X.iloc[valid_idx]
y_valid = y.iloc[valid_idx]
lgb_train = lgb.Dataset(X_train, y_train)
lgb_valid = lgb.Dataset(X_valid, y_valid)
model = lgb.train(params,
lgb_train,
valid_sets=lgb_valid,
verbose_eval=10,
early_stopping_rounds=30)
# f-measure
pred_y_valid = model.predict(X_valid, num_iteration=model.best_iteration)
true_y_valid = np.array(y_valid.data.tolist())
mse = np.sum((pred_y_valid - true_y_valid)**2) / len(true_y_valid)
mse_list.append(mse)
return np.mean(mse_list)
def build_model():
study = optuna.create_study()
study.optimize(objective, n_trials=500)
valid_split = 0.2
num_train = int((1-valid_split)*len(X))
X_train = X[:num_train]
y_train = y[:num_train]
X_valid = X[num_train:]
y_valid = y[num_train:]
lgb_train = lgb.Dataset(X_train, y_train)
lgb_valid = lgb.Dataset(X_valid, y_valid)
lgb_data = lgb.Dataset(X, y)
params = study.best_params
params['metric'] = 'l2'
model = lgb.train(params,
lgb_data,
valid_sets=lgb_valid,
verbose_eval=10,
early_stopping_rounds=30)
return model
X, y = load_data(trivias_list)
if __name__ == "__main__":
model = build_model()
content = 'ミツバチが一生かけて集める蜂蜜はティースプーン1杯程度。'
content_df = get_features(trivias_list, content=content, mode='inference')
output = model.predict(content_df)
hee = int(output*100)
print(f"{content}")
print(f"{hee}へぇ")
アンチパターン
機械学習モデル作成に当たって, 失敗したアンチパターンを記載します. 少しでも皆さん, そして未来の自分の役に立てればと思います.
失敗① スケーリング
目的変数のスケーリングとして, へぇ数/満へぇとしました. 運よくすぐに気をつけられたのですが, 最初はへぇ数を目的変数にする気満々でした. そのままコーディングを続けていれば, 精度が出ないまま「まぁこんなもんか...」と諦めていたことでしょう.
失敗② word_vectorizerのfit忘れ
すみません. めっちゃくちゃ細かい話になります...
しかし, わたくしこの失敗2回目なので書かせてください...
文章からtfidfを埋め込む際に, 以下の3ステップを踏む必要があります.
# インスタンスの生成
word_vectorizer = TfidfVectorizer(max_features=max_features)
# 分かち書きされた文章リストを入力し, fitさせる.
word_vectorizer.fit(wakati_contents_list)
# 所望の分かち書きされた文章リストを埋め込む.
tfidf = word_vectorizer.transform(wakati_contents_list)
tfidfは全ての文章の中から当該文章に存在する単語がどれほど珍しいかを考慮しなければならないので, 一度全ての文章をベクトライザーインスタンスに渡す必要があります. つまり, 「この文章埋め込んどいて」と一文だけを渡してもダメです.
しかし僕はいつもtfidfが決定論的な処理であることからfitさせないといけないというイメージに直結せず, 適当にtransformで埋め込もうとしてしまいます...
皆さんもお気をつけて.
失敗③ 使わない特徴量の削除
これは基本的すぎるので書くか迷ったのですが, 1分ほど詰まってしまったのは事実ですので書きます.
はいこちら。
all_df = all_df.drop('id', axis=1)
all_df = all_df.drop('hee', axis=1)
all_df = all_df.drop('man_hee', axis=1)
all_df = all_df.drop('content', axis=1)
all_df = all_df.drop('wakati_content', axis=1)
id, content(元の文字列)などなど, lightgbmに入力しない情報はpandasデータフレームからちゃんと削除しようねという話です.
これ意外とやりがちかと思います.
特徴量生成していく過程で, 以下のように, pandasのデータフレームにホイホイと追加していくので, いらないのが残っていることを忘れてしまいがちです. (多分pandas初心者だからですね.ディープラーニングやりすぎました.)
all_df['num_eigo'] = num_eigo_df.values.tolist()
公開
さて, 前述の通り, 完成物はGoogle Colabで公開しました.
stickytapeで単一のコードにビルドし, Google Colab上でもわかりやすいUIで遊べるように工夫を凝らしました. stickytapeについては昨日自分が書いた記事がありますので, よければご覧ください.
複数pythonファイルを一つのpythonファイルにする@wataoka
実験!
さて, せっかく作ってみたんですから自分でも遊んでみましょう. 学習させた後に, 自分の持っている雑学をHee-AIに入力し推論させます.
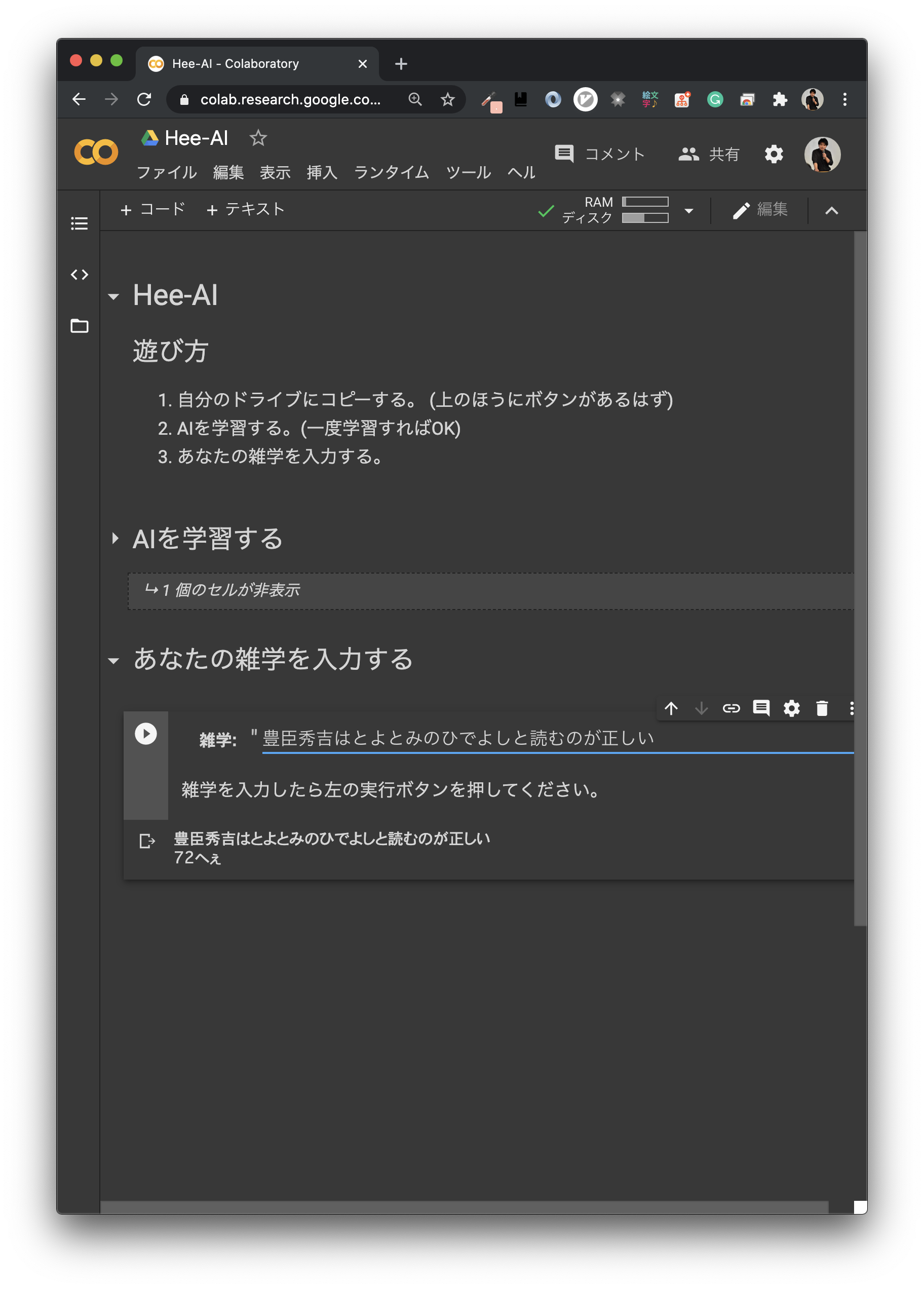
- 「豊臣秀吉はとよとみのひでよしと読むのが正しい」 72へぇ
手厳しい...
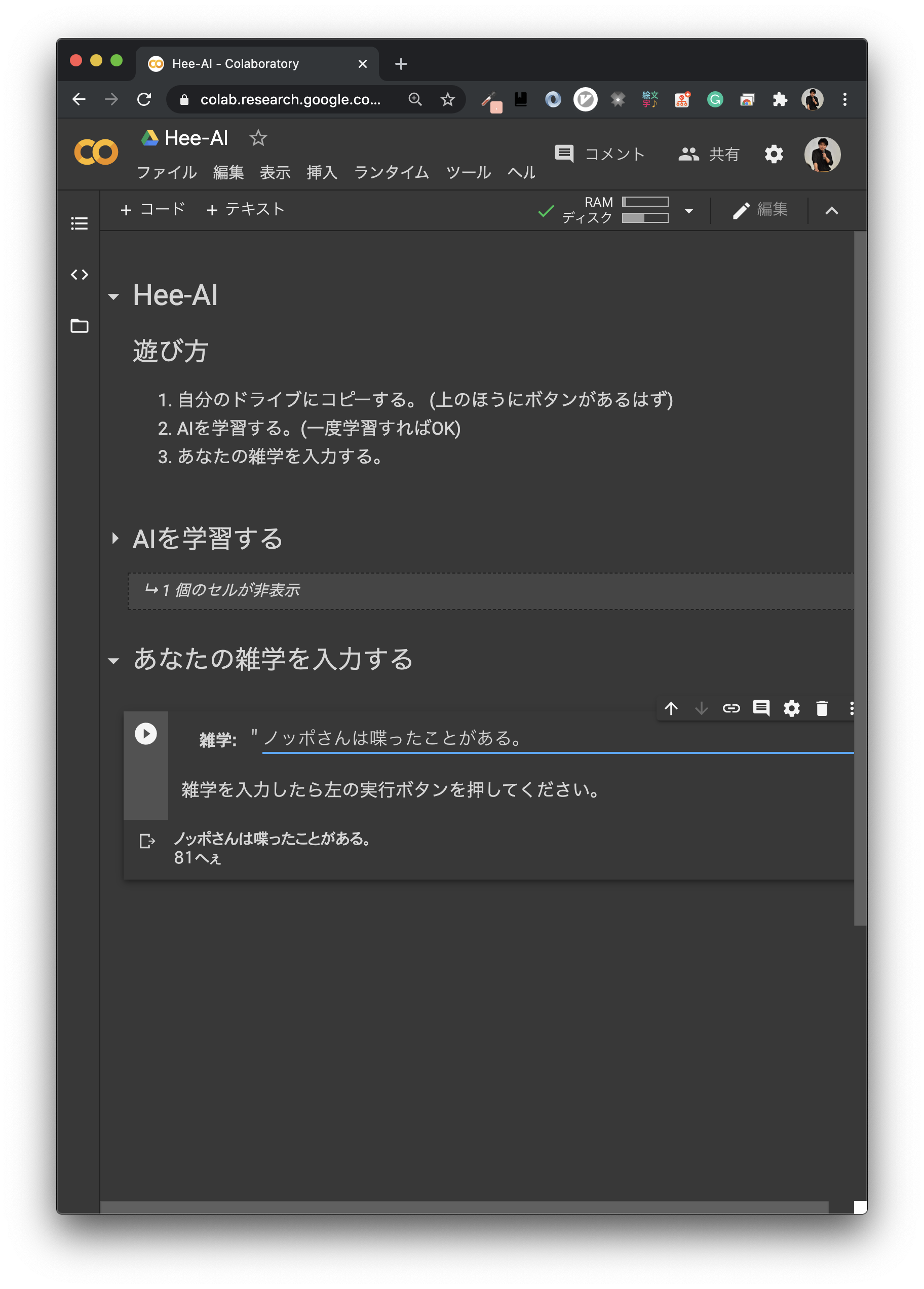
- 「ノッポさんは喋ったことがある。」 81へぇ
本家では99へぇで歴代トップなのになぁ...
- 「晴れの日は明るい」 68へぇ
当たり前な言うとちょっとは低くしてくれてるのかな?
感想
全体としては手厳しい評価ですね. 90へぇに一度も到達しませんでした. 5人中5人がタモリさんなのでしょうか.
どなたか90へぇに到達したら教えてください.
自己紹介
冒頭に書くと邪魔になるので最後にひっそりと自己紹介させてください。

| 名前 | 綿岡晃輝 |
|---|---|
| 学校 | 神戸大学大学院 |
| 学部の研究 | 機械学習, 音声処理 |
| 大学院の研究 | 機械学習, 公平性, 生成モデル, etc |
| @Wataoka_Koki |
Twitterフォローしてね!