この記事はNTTテクノクロスアドベントカレンダー2023、シリーズ 2 の2日目の記事です。
NTTテクノクロスの渡邉です。
2023年は念願の「2023 Japan AWS Top Engineers (Services)」に選出されて嬉しかったです。
今回はAWSのスコープではあまり取り上げられない、CDN Edgeのお話を書きます。
CDN Edge Computingとそのトレンド
CDN(Content Delivery Network)におけるエッジコンピューティングは、データ処理をユーザーに近いエッジロケーションで行うことで、レイテンシーを大幅に削減し、パフォーマンスを向上させる技術です。近年、このCDN Edgeでのコンピューティングが注目されています。
具体的にいうと、以下のような製品があげられます。
元の利用目的としては、CDNからOriginへの通信に対して、認証やHeader操作などの付帯処理などがありました。ですが昨今、少なくとも私が観測しているCloudflare Workersの文脈では、HonoなどのWebフレームワークを活用して、以下のような扱い方の事例も見受けられます。
- リバースプロキシ:Redirect, Origin振り分け、動的キャッシュ管理、etc......
- Webサーバ: エッジロケーションで直接RESTやGraphQLを処理する。
- Webサイトホスティング: ストレージから取得した静的コンテンツやエッジロケーションで動的にページをレンダリングし(SSR)、ユーザーに提供する。
面白いことに、これらの処理を実施するのにCDNのOriginは必要ありません。すなわちCDN Edgeながら、Originが不要、つまりOriginless(いま作った言葉)な構成として完結しうるのです。
AWS におけるCDN Edge Computing
概要
AWSが提供するCDN Edge Computingを説明する前に、以下の図を見てみましょう。
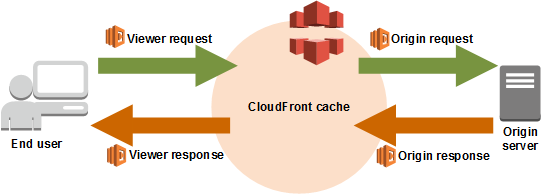
出典:https://docs.aws.amazon.com/lambda/latest/dg/lambda-edge.html
AWSのCDNサービスであるAmazon CloudFrontで作成されたDistribution(CDNリソース)のCacheを中心と見たときに、以下の4種類の CloudFront Eventがあります。
- Cacheへの/Cacheからの 通信:Viewer request/Viewer response
- Originへの/Originからの 通信:Origin request/Origin response
このうち、前者のViewer系のEventにのみ、CloudFront Functionsを紐づけられます。Lambda@Edgeは4種類いずれにも紐づけられます。
CloudFront Functionsの制約
CloudFront Functionsは安価でスケーラビリティも高いですが、制約がかなり大きく、特に以下の制約が厳しいものです。
- JavaScript (ECMAScript 5.1 準拠)
- 実行時間は最大1秒(通信待ち含む)
- バンドルサイズが最大10 KB
そのため、従来の目的である軽微なワンアクションに留めるのが現実的です。
Lambda@Edgeの使い分け
新しいCDN Edge Computingの使い方を、改めて掲載します。
- リバースプロキシ
- Webサーバ
- Webサイトホスティング
Lambda@Edgeをどこのイベントでフックさせるかについては、「CDNキャッシュが必要か?」という観点で考えるとわかりやすいです。
この辺りはまだノウハウが少ないので一概に言えませんが、例えばこのような分け方ができそうです。
- Viewer系EventによるLambda@Edge
- 1, 2
- Origin系EventによるLambda@Edge
- 2, 3
ここまでで文章ばかりになってしまいました。折角ですので、何か実例を踏まえて説明しましょう。
作成するサービス
今回は、AWS What’s Newの英語版RSSをレンダリングするサービスを作ります。
背景として、日本国内からこのWebサイトへアクセスすると、デフォルト設定だと日本語翻訳ではあるが数日遅れのアップデートしか読めない仕様となっております。最新情報を確認するには、サイト内で言語をEnglishへ変更する必要があり煩雑です。
そこで今回は、英語版のアップデート情報のリンク集を表示するだけのサイトを作ります。(RSS Readerを導入しろという話ですが……)
アーキテクチャ
この図のような構成を作ります。
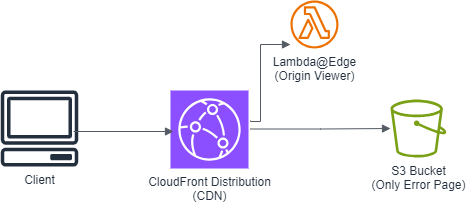
まず、キャッシュがない状態ではCloudFrontのOrigin Viewerで起動したLambda@Edgeが数秒処理を行い、RSS FeedをParseした結果を返却します。以降のアクセスでは、ユーザはCDNキャッシュへアクセスします。
当然キャッシュ切れ時の待ち時間が気になりますが、CloudFrontでも2023年5月からはstale-while-revalidate stale-if-errorを使えるようになったので、キャッシュ切れの際にも古いキャッシュにアクセスさせられることを許容できれば、待ち時間はある程度緩和されます。
つまりCloudFrontとLambda@EdgeのみのOriginlessな構成で、このサービスは完結させられます。
Appendix. 空のOrigin
Originを使わないとはいえ、何かしら用意しないとCloudFront distributionは構築できないため、費用が掛からずアクセスを制御しやすいS3バケットをOriginとして置いています。
今回はDefaultのBlock Public Access設定のまま何も設定しませんが、もう少し真面目に運用する場合にはエラー画面くらいは置くべきでしょう。たとえばLambda@Edge失敗時の502、503など。それでも正規のOriginサーバを配置するより、運用負荷は格段に少なくなります。
構築
ベースの手順はこちらを参考にしています。
Lambda@Edge
Lambda@Edgeへ設定するコードはこちらです。
import { Hono } from "hono";
import { etag } from "hono/etag";
import { logger } from "hono/logger";
import { secureHeaders } from "hono/secure-headers";
import { handle } from "hono/lambda-edge";
import { parseFeed } from "htmlparser2";
import { FC } from "hono/jsx";
const app = new Hono();
app.use("*", logger(), secureHeaders());
app.use("/feed", etag());
interface Item {
title: string;
description: string;
datetime: string;
href: string;
}
const FeedItem: FC<{ item: Item }> = ({ item }) => (
<li>
<a href={item.href}>{item.title}</a>
</li>
);
const FeedPage: FC<{ items: Item[], fetchTime: string }> = ({ items, fetchTime }) => (
<html>
<head>
<title>AWS What’s New Feed</title>
</head>
<body>
<h1>AWS What’s New Feed</h1>
<h2>Fetched at {fetchTime}</h2>
<ul>
{items.map((item) => (
<FeedItem key={item.href} item={item} />
))}
</ul>
</body>
</html>
);
app.get("/feed", async (c) => {
const feedUrl = "https://aws.amazon.com/about-aws/whats-new/recent/feed/";
const response = await fetch(feedUrl, {
headers: {
"If-None-Match": c.req.headers.get("If-None-Match"),
},
});
if (!response.ok) {
return new Response(JSON.stringify([]));
}
const htmlString = await response.text();
const feed = parseFeed(htmlString);
if (!feed) {
return new Response(JSON.stringify([]));
}
const items: Item[] = feed.items.map((data: any) => ({
title: data.title,
description: data.description,
datetime: data.isoDate,
href: data.link,
}));
const fetchTime = new Date().toLocaleString();
c.header("Cache-Control", "max-age=3600, stale-while-revalidate=2678400, stale-if-error=2678400");
return c.html(<FeedPage items={items} fetchTime={fetchTime} />);
});
export const handler = handle(app);
実装のポイント
- 今回はエッジ向けの軽量フレームワークであるHonoを利用しています。Lambda@Edge用のAdaptorは私がContributeしました!
HonoはJSXが使えるので、RSS Parserの結果を組み立ててHTMLとして返しています。
- CloudFrontを前提としたキャッシュ戦略として、以下の2つを採用しています。結果的に効果は出ているが雰囲気で設定しているので自信はない。
- EtagとIf-None-Match を併用して、キャッシュされたコンテンツが最新であるかをクライアントが確認。Etag値を比較して、リソース変更がなければ304 Not Modifiedを返し、コンテンツの再ダウンロードを防ぐ。
-
stale-while-revalidate,stale-if-errorヘッダーを使い、キャッシュコンテンツの期限切れや取得失敗時に古いキャッシュを一時的に返し、クライアントを待たせない。
CDK
インフラをCDKで作ります。こちらも手順はHonoのGetting Startedを参考にします。
import { Construct } from 'constructs';
import * as cdk from 'aws-cdk-lib';
import * as cloudfront from 'aws-cdk-lib/aws-cloudfront';
import * as origins from 'aws-cdk-lib/aws-cloudfront-origins';
import * as lambda from 'aws-cdk-lib/aws-lambda';
import { NodejsFunction } from 'aws-cdk-lib/aws-lambda-nodejs';
import * as s3 from 'aws-cdk-lib/aws-s3';
export class RssEdgeStack extends cdk.Stack {
public readonly edgeFn: lambda.Function;
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const edgeFn = new NodejsFunction(this, 'edgeViewer', {
entry: 'lambda/index_edge.tsx',
handler: 'handler',
runtime: lambda.Runtime.NODEJS_20_X,
timeout: cdk.Duration.seconds(10),
memorySize: 128
});
// Upload any html
const originBucket = new s3.Bucket(this, 'originBucket');
new cloudfront.Distribution(this, 'Cdn', {
defaultBehavior: {
origin: new origins.S3Origin(originBucket),
edgeLambdas: [
{
functionVersion: edgeFn.currentVersion,
eventType: cloudfront.LambdaEdgeEventType.ORIGIN_REQUEST,
},
],
},
});
}
}
動作確認
このように取得した情報をCloudFrontとLambda@Edgeだけをつかって、What’s Newの情報をブラウザで簡単に読むことが出来ました。
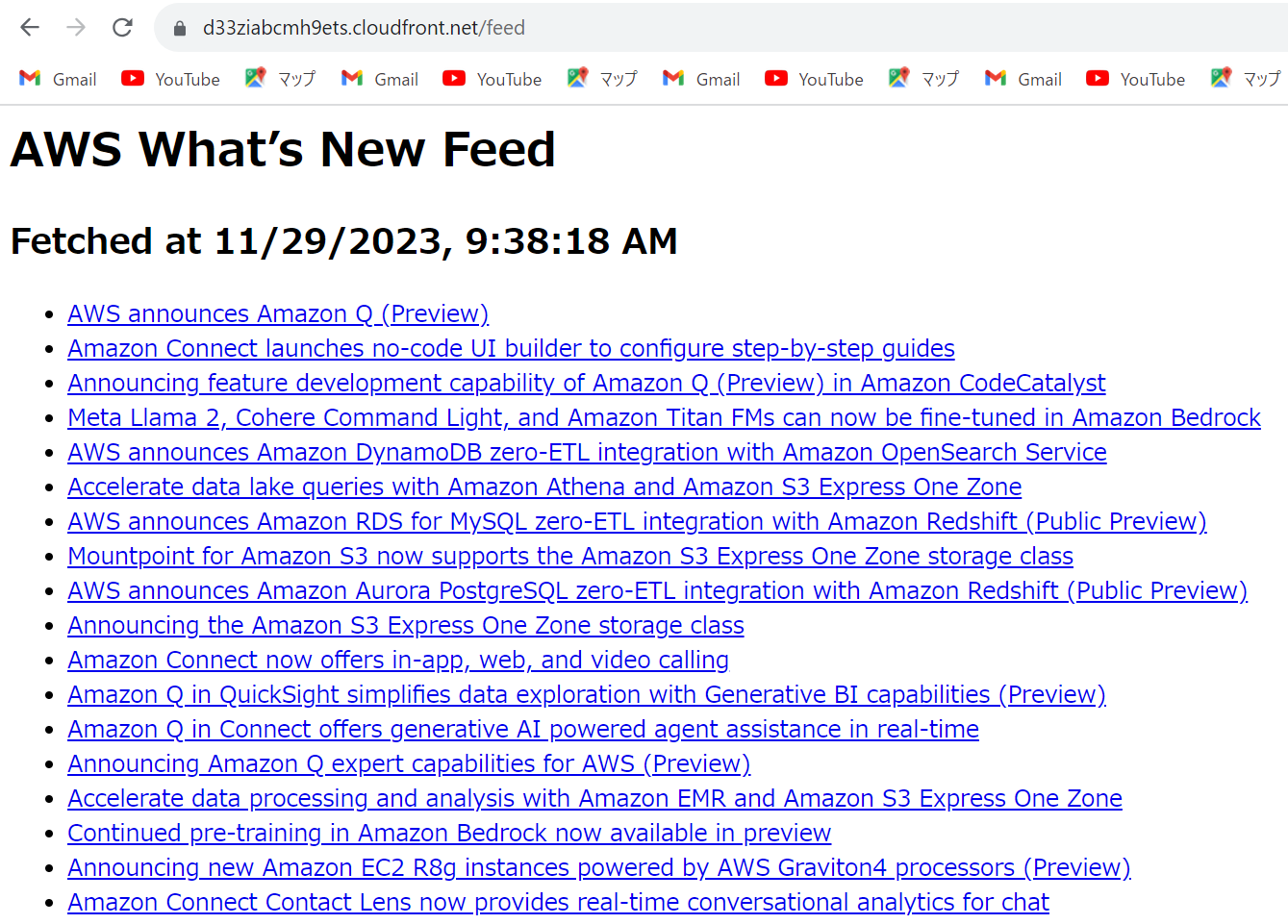
キャッシュが切れても何度かアクセスすると最新の情報がキャッシュに乗るので、即時性の高くないコンテンツ運用ならこれで十分そうです。
AWSでの”Originless”に関する所感
今回のLambda@Edgeでなく、OriginにLambda Functions URLsやAPI Gatewayを置いたとしても、もちろん同様のサービスは実現できます。
-
Pros
- よりユーザに近いロケーションで動作するため、高速に処理を実現できる。
- CDNに近いリージョンのLambdaが割り当てられるため、マルチリージョン構成をシンプルに実現できる。
- 実行されるリージョンが確約されない点は注意。
- Originが実質無いので、CDNを使わない経路へのアクセスに関して、検討箇所を減らすことができる。
- Originを個別にWAFで守る必要がない。
-
Cons
- Lambda@EdgeはLambdaより制約が強く、実行時間やマシンリソース、環境変数などに制約がある。
- Lambda@Edgeの単価はLambdaの3倍ほど。
- Cacheを使うOrigin系のEventでは問題になりにくいが、Viewer系ではコール数を意識する。
と、一長一短はあります。汎用的なアーキテクチャではないですが、検討候補の一つとして手札として持っておくのは便利だと思います。
というわけで、AWSにおけるCDN Edge Computingについて、現状の整理とサンプルを公開してみました。事例の少ない分野なので、試してくれる方はよろしくお願いします。
明日は @sa-da 氏がAppsyncの記事を担当するそうです。こちらもお楽しみに!