はじめに
この記事は NTTテクノクロス Advent Calendar 2020 の22日目の記事です。
NTT テクノクロスの渡邉です。
普段はAWSやコンテナ関連の業務に携わっております。
ときおり、社外向けブログ執筆や、ソフト道場のAWS分野(IaaS, PaaS)の講師なども務めております。
今回はAWS 利用で起こり得るアンチパターンについて考えていきたいと思います。
AWS × 無限ループ
タイトルを見て、インフラであるAWSが無限ループ? と疑問に思った読者向けに補足を。
AWS、というより主要メガクラウドにおいて、それぞれ下記のような特徴があります。
- マシンリソース調達がAPIコールで完結する。
- 利用リソース量(CPU,memory,disk,…)×利用時間に比例して課金が発生する。
逆に言えばこれらを組み合わせると、下記のような問題が発生します。
何らかの原因によりマシンリソース調達を大量、あるいは無制限に施行された結果、想定外の動作となる上に利用料金が青天井になってしまう
というわけで今回は、一生懸命なのに、どこか残念なアーキテクチャたちをお楽しみください。
ちなみに
今回の実例4つは、いずれもAWS CDKを中心に作成しました。
AWS CDK(以下、CDK)では、AWSのインフラ定義をTypescriptやPythonなどで記述できるフレームワークです。
JSON/YAML形式でなくプログラミング言語で書けるのも、まさに**Infrastructure as a Code(IaC)**と言ったところ。
CloudFormationだと1000行以上必要なリソース達も、抽象度の高い表現で100~200行程度で実装できてしまうのがたまらないですね。
本文が長くなってしまうのでコード類は隠していますが、興味のある方は「▶︎」をクリックでご覧ください。
※執筆の8割近く、CDK作成(特にCase4のCDK × EKS × AutoScaling)に熱くなってちょっと反省。
実行環境のセッティング
-
実行マシンはAWS Cloud9@東京リージョン+IAM Roleを利用しています。
- デフォルトのIAM権限(AWS Managed Temporary Credentials)だとsts周りの制約があります。EKSの利用などに手間取る為、
この辺を参考にIAM Roleを設定しています。(権限設定は割愛。)
- デフォルトのIAM権限(AWS Managed Temporary Credentials)だとsts周りの制約があります。EKSの利用などに手間取る為、
-
準備用の設定は下記のように。(クリックで表示)
環境設定
# Upgrade AWS CDK
npm -v
6.14.8
npm i -g aws-cdk@latest --force
cdk version
1.78.0 (build 2c74f4c)
# Initialize (By region)
cdk bootstrap
Case1. 止まらないStream編
DynamoDB Streams、便利ですよね。
DB書き込みをトリガーとするAWS Lambdaを用いることで、DB書き込みとデータ加工処理が簡単に連携できます。
有用な機能ですが、時として残念な使用例になってしまう場合もあります。
例えば、書き込まれたレコードをLambdaで取得し、同じカラムに追記 or 同じテーブル内にレコードの新規書き込みを行う場合には注意が必要です。
文字だけだと分かりづらいですね。
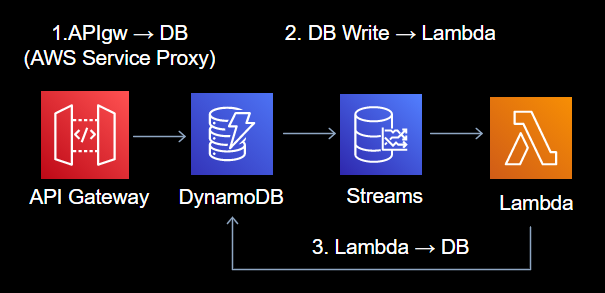
矢印を追うと分かるように、これは無限ループの可能性があるアーキテクチャです。
1.の書き込み情報を2.でLambdaに受け渡し、3.で処理した情報をDBに追記します。ここで1.と3.のDB書き込みをLambda側が見分ける方法がない場合、特定テーブルAへの追記をトリガーとし、特定テーブルAに追記をトリガーとし、……的に、2.~3.が無限ループする恐れがあります。
作り方
※本当に無限ループするので、動作を確認しだい早めに消しましょう。
サンプルコード
- CDK(TypeScript)
import * as cdk from "@aws-cdk/core";
import * as dynamodb from "@aws-cdk/aws-dynamodb";
import * as lambda from "@aws-cdk/aws-lambda";
import * as iam from "@aws-cdk/aws-iam";
import * as apigw from "@aws-cdk/aws-apigateway";
export class Case1Stack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const table = this.setupDdbTable();
this.setupDdbStreamFunction(table);
this.setupApiGateway(table);
}
private setupDdbTable(): dynamodb.Table {
return new dynamodb.Table(this, "Table", {
removalPolicy: cdk.RemovalPolicy.DESTROY,
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST,
partitionKey: {
name: "id",
type: dynamodb.AttributeType.STRING,
},
stream: dynamodb.StreamViewType.NEW_AND_OLD_IMAGES,
});
}
// DynamoのTodo TableストリームをフェッチするためLambdaの関数を定義する
private setupDdbStreamFunction(table: dynamodb.Table) {
const role = new iam.Role(this, "FetchDdbStreamRole", {
assumedBy: new iam.ServicePrincipal("lambda.amazonaws.com"),
managedPolicies: [
iam.ManagedPolicy.fromAwsManagedPolicyName(
"service-role/AWSLambdaBasicExecutionRole"
),
],
});
table.grantReadWriteData(role);
const handler = new lambda.Function(this, "FetchDdbStreamFunction", {
handler: "fetchStream.handler",
code: lambda.Code.fromAsset("lib/lambda"),
runtime: lambda.Runtime.NODEJS_12_X,
environment: {
TZ: "Asia/Tokyo",
TABLENAME: table.tableName,
},
role: role,
});
// To Fetch DynamoDB Stream
if (table.tableStreamArn) {
role.addToPolicy(
new iam.PolicyStatement({
actions: ["dynamodb:*"],
resources: [table.tableStreamArn],
})
);
handler.addEventSourceMapping("FetchDdbStreamSourceMapping", {
eventSourceArn: table.tableStreamArn,
batchSize: 10,
startingPosition: lambda.StartingPosition.LATEST,
});
}
}
// https://github.com/cdk-patterns/serverless/blob/master/the-dynamo-streamer/typescript/lib/the-dynamo-streamer-stack.ts
private setupApiGateway(table: dynamodb.Table) {
const gateway = new apigw.RestApi(this, "DynamoStreamerAPI", {
deployOptions: {
metricsEnabled: true,
loggingLevel: apigw.MethodLoggingLevel.INFO,
dataTraceEnabled: true,
stageName: "prod",
},
});
const apigwDynamoRole = new iam.Role(this, "DefaultLambdaHanderRole", {
assumedBy: new iam.ServicePrincipal("apigateway.amazonaws.com"),
});
table.grantReadWriteData(apigwDynamoRole);
const responseModel = gateway.addModel("ResponseModel", {
contentType: "application/json",
modelName: "ResponseModel",
schema: {
schema: apigw.JsonSchemaVersion.DRAFT4,
title: "pollResponse",
type: apigw.JsonSchemaType.OBJECT,
properties: { message: { type: apigw.JsonSchemaType.STRING } },
},
});
// Create an endpoint '/InsertItem' which accepts a JSON payload on a POST verb
gateway.root.addResource("InsertItem").addMethod(
"POST",
new apigw.Integration({
type: apigw.IntegrationType.AWS, //native aws integration
integrationHttpMethod: "POST",
uri: "arn:aws:apigateway:ap-northeast-1:dynamodb:action/PutItem",
options: {
credentialsRole: apigwDynamoRole,
requestTemplates: {
"application/json": JSON.stringify({
TableName: table.tableName,
Item: { id: { S: "$input.path('$.id')" } },
}),
},
passthroughBehavior: apigw.PassthroughBehavior.NEVER,
integrationResponses: [
{
statusCode: "200",
responseTemplates: {
"application/json": JSON.stringify({
message: "item added to db",
}),
},
},
],
},
}),
{
methodResponses: [
{
statusCode: "200",
responseParameters: {
"method.response.header.Content-Type": true,
"method.response.header.Access-Control-Allow-Origin": true,
"method.response.header.Access-Control-Allow-Credentials": true,
},
responseModels: {
"application/json": responseModel,
},
},
],
}
);
}
}
- CDK(Node.js)
const AWS = require("aws-sdk");
const dynamoDB = new AWS.DynamoDB.DocumentClient();
const env = process.env;
// Write Only RandomString
exports.handler = (event, context, callback) => {
console.log(event);
const randomString = Math.random().toString(32).substring(2);
const params = {
TableName: env.TABLENAME,
Item: { id: randomString },
};
dynamoDB
.put(params)
.promise()
.then((data) => {
console.log("Put Success");
callback(null);
})
.catch((err) => {
console.log(err);
callback(err);
});
};
デプロイ方法
mkdir case1
cd case1
cdk init app -l typescript
mkdir lambda
npm i @aws-cdk/aws-dynamodb @aws-cdk/aws-lambda @aws-cdk/aws-iam @aws-cdk/aws-apigateway
# 上述のコードに更新
vi lib/case1-stack.ts
vi lib/lambda/fetchStream.js
npm run build
# 環境デプロイ用コマンド。停止はくれぐれも自己責任で。
cdk deploy
# ※確認後に削除するコマンド
cdk destroy
影響
-
APIに10件POSTした結果をLogs Insightで確認したところ、Lambdaの実行時間は30ms前後の様子でした。
- 以前の課金形態は100msで切り上げだったのですが、2020.12のUpdateで1ms単位に改定されました!※参考:New for AWS Lambda 1ms Billing Granularity Adds Cost Savings
-
最小のAWS Lambda(メモリ128MB)を実行したシナリオを考えると、約$0.0015になります。
- 参考:計算式
ⅰ.Lambdaの起動回数 :17回/分 ⅱ.実行時間 :30ms/回 ⅲ.1日を分換算 :24 × 60 = 1440分 ⅳ.ミリ秒単位の課金(メモリ128MB) :$0.0000002083 × 0.01 17 × 30 × 1440 × 0.0000002083 × 0.01 = $0.0015
例えばメモリ1GB(= 128 × 8)で動かす場合は、8倍した$0.012となります。
意外と安価に感じましたか?
ただ、ビッグデータやIoT系のサービスの場合、
- 数千~数万、時としてそれ以上のユーザ数で
- データ収集を毎時(×24)、毎分(×1440)、それ以上の頻度の周期で
処理するケースも考えると……かなりの金額に発展する場合も。くれぐれもご注意を。
ちなみに運用費以外では下記のような障害対応にも注意です。商用で発生すると、つらいやつ。
- 想定外のDB書き込み/追記が大量発生に伴う、DBの復旧作業
- DynamoDB負荷の過多による、正常データ書き込み失敗の解析
対処方法
-
DBに書かれた情報を処理すべきか?という観点で、Lambda側でチェックして、必要外のDB書き込みを防ぎましょう。
- DynamoDB Streamsの中から、登録元の情報を読み取るのはそのままでは難しいですね。この場合は、登録情報にステータスを表すカラムを追加してあげると良さそうです。
パターン カラム(e.g. writeStatus) Lambdaの動作パターン APIから登録 writeStatus=0(初期状態) 処理&DB書き込みの実行対象 後続のデータ加工 writeStatus≠0(加工中、済) 処理対象外として正常終了
Case2. S3のヤバい格納編
AWSのデータストアといえばS3ですよね。同リージョンに処理システムを構築すれば通信費は無料なので、安価かつ容量無制限のストレージとして使い倒せます。
この場合、S3の料金は保存費用とリクエスト数となり、その大半は前者となります。
後者はいったん置いておくとして、公式を参考に料金を確認してみましょう。
| S3 ストレージクラス | 保存費用(月) | 標準比 | 最低保存期間 |
|---|---|---|---|
| 標準 | $0.025/GB | 1.0 | - |
| Glacier | $0.005/GB | 0.2 | 90日 |
| Glacier Deep Archive | $0.002/GB | 0.08 | 180日 |
※今回は話をシンプルにするため、IA系は割愛します。
ファイルの特性に応じて適切なストレージクラスを選べば、標準比20%08%に保存コストを抑えられるのが魅力ですね。
なので、例えばこんなLambdaを検討することもあるでしょう。
- S3に格納された画像をダウンロードし、Lambdaで生成したサムネイルをS3へアップロード。
- 上記が成功したら、元ファイルのストレージクラスを標準からGlacierに移行。
これらの処理がサーバレスで自動化できたら嬉しいですよね。
……前回からの流れでお気づきとは思うのですが、何も考えずに実装すると無限ループします。
作成図はこちら。
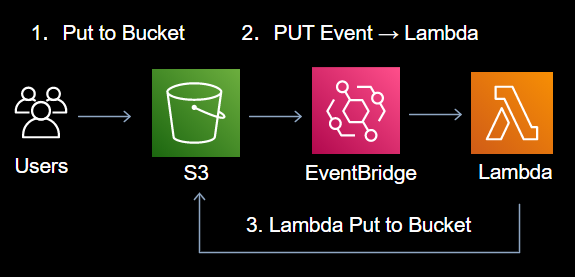
サムネイル格納、アーカイブ処理のいずれかがLambdaトリガーの条件(特定のS3バケットへのPUT)に合致するとロジックがループするのがわかると思います。
- S3からはLambdaが格納先が自分であることが、
- LambdaからはEventBridgeの発火条件が、
それぞれ、一見して判断できないのがポイントです。特にインフラとコードを別々にレビュするチームは注意が必要です。
作り方
※本当に無限ループするので、動作を確認しだい早めに消しましょう。
サンプルコード
- CDK(TypeScript)
import * as cdk from '@aws-cdk/core';
import * as s3 from "@aws-cdk/aws-s3";
import * as lambda from "@aws-cdk/aws-lambda";
import * as iam from "@aws-cdk/aws-iam";
import * as events from "@aws-cdk/aws-events";
import * as targets from '@aws-cdk/aws-events-targets';
export class Case2Stack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const bucket = this.setupBucket();
const handler = this.setupFunction(bucket);
this.setupEvent(bucket, handler);
}
private setupBucket() {
return new s3.Bucket(this, 'fileUploadBucket', {
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL,
removalPolicy: cdk.RemovalPolicy.DESTROY,
});
}
private setupFunction(bucket: s3.Bucket){
const role = new iam.Role(this, "PutBucketRole", {
assumedBy: new iam.ServicePrincipal("lambda.amazonaws.com"),
managedPolicies: [
iam.ManagedPolicy.fromAwsManagedPolicyName(
"service-role/AWSLambdaBasicExecutionRole"
),
],
});
bucket.grantPut(role);
const handler = new lambda.Function(this, "s3Writer", {
handler: "s3Writer.handler",
code: lambda.Code.fromAsset("lib/lambda"),
runtime: lambda.Runtime.NODEJS_12_X,
environment: {
TZ: "Asia/Tokyo",
BUCKETNAME: bucket.bucketName,
},
role: role,
});
return handler
}
private setupEvent(bucket: s3.Bucket, handler:lambda.Function) {
const rule = new events.Rule(this, 'put event rule', {
description:
's3 put event rule',
eventPattern: {
source: ['aws.s3'],
detailType: ['AWS API Call via CloudTrail'],
detail: {
eventSource: ['s3.amazonaws.com'],
eventName: [
'PutObject',
'CopyObject',
'CompleteMultipartUpload',
],
requestParameters: {
bucketName: [bucket.bucketName],
},
},
},
});
rule.addTarget(new targets.LambdaFunction(handler));
}
}
- Lambda(Node.js)
※ ランダムなファイルを「S3 標準クラス」でPUTするだけのLambdaです。
const aws = require('aws-sdk');
const s3 = new aws.S3();
const env = process.env;
exports.handler = async (event, context) => {
console.log ("start");
const key = Math.random().toString(32).substring(2);
const str_data = key + '\n' + key + '\n' + key + '\n';
const params = {
Bucket: env.BUCKETNAME,
Key: key,
Body: str_data,
};
try {
await s3.putObject (params).promise();
}
catch (error){
console.log (error);
}
console.log ("end");
};
デプロイ方法
mkdir case2
cd case2
cdk init app -l typescript
mkdir lambda
npm i @aws-cdk/aws-s3 @aws-cdk/aws-lambda @aws-cdk/aws-iam @aws-cdk/aws-events @aws-cdk/aws-events-targets
# 上述のコードに更新
vi lib/case2-stack.ts
vi lib/lambda/s3Writer.js
npm run build
# 環境デプロイ用コマンド。停止はくれぐれも自己責任で。
cdk deploy
# ※確認後に削除するコマンド
cdk destroy
影響
Lambdaの費用感についてはCase1で紹介済のため割愛します。
S3のストレージ費用は一体どの程度なのでしょうか。
(例)スマホで撮った写真がだいたい3MBとして、5秒毎のLambda実行に、設定1週間後に気付いて削除した場合。
Ⅰ.PUTした画像数 :100
Ⅱ.画像当たりのファイルサイズ :3MB (= 1 ÷ 1024 × 3)
Ⅲ.Lambda実行の合計数(5秒毎/Lambda) :86400 ÷ 5 × 7 = 120,960
として、かかる費用はどうなるでしょうか……!(一応リクエスト費用も)
| S3 ストレージクラス | 保存費用(月) | 最低保存期間 | 保存費用(週) | ※PUTリクエスト費用 |
|---|---|---|---|---|
| 標準 | $0.025/GB | - | $221.5 | $0.57 |
| Glacier | $0.005/GB | 90日 | $531.6 | $6.91 |
| Glacier Deep Archive | $0.002/GB | 180日 | $425.2 | $7.87 |
保存費用(週)を見ると……標準よりコスト抑えられてないやんけ!と叫びたい気持ちになりますが、これは仕様です。
Glacierの「よくある質問」を抜粋すると
Amazon S3 Glacier からデータを無料で削除できるのは、削除されるアーカイブが 3 か月以上保管されていた場合です。アップロードされてから 3 か月未満でアーカイブを削除する場合は、早期削除料金をいただきます。
(参考:Q: 3 か月経過前にデータを削除した場合は、どのように請求されるのですか?)
とあります。うーん、意識していないと怖いですね。
「最低保存期間」に満たない期間での削除時は、「最低保存期間」にて支払うはずだった残金が一括して請求されます。
もう少し噛み砕いて書くと、最低保存期間のあるストレージクラスについては誤ってアーカイブしたファイルをすぐさま削除する場合、最低保存期間分(3~6ヶ月分)の保存費用が当月の決済に確定する仕様なのです。
今回の削除タイミングはGlacierの特性と異なる利用方法なので、結果として標準クラスの1週間分とGlacierの請求額が逆転してしまいました。
※AWSアカウントの月額予算が動かせない場合、月当たりの支払いを分散する戦略として、あえて「最低保存期間」最終月まで削除しない判断もありかも!?
ちなみにGlacier系を早く削除する場合、標準クラスと比べてどの程度支払わなくてはならないのでしょう。
標準より安いレートの筈だけど数か月分……?と混乱するので、標準クラス/月と比較してみました。
| S3 ストレージクラス | 保存費用(月) | 標準比 | 1Week後に削除時の標準比 | 1Day後に削除時の標準比 |
|---|---|---|---|---|
| 標準 | $0.025/GB | 1.0 | 0.25(1.0×0.25ヶ月) | 0.034(1.0×0.03ヶ月) |
| Glacier | $0.005/GB | 0.2 | 0.6(0.2×3ヶ月) | 0.6(0.2×3ヶ月) |
| Glacier Deep Archive | $0.002/GB | 0.08 | 0.48(0.08×6ヶ月) | 0.48(0.08×6ヶ月) |
格納から一か月以内にGlacier系からファイルを削除する場合は、標準クラス1か月分の、だいたい5~6割の請求が発生すると覚えると分かり易そうです。
特に機械学習等で、大容量の画像を利用するユースケースでGlacierへの誤格納を無限ループさせてしまうと、なかなか悲惨な請求額になってしまいそうですね。
対処方法
S3に格納する役割毎にPrefixを切って、特定PrefixのみでLambdaが発火させましょう。
-
今回の例では、実装を下記のようにPrefixを考慮した実装に改修します。
- S3(bucket/org/)に格納された画像をダウンロードし、Lambdaで生成したサムネイルをS3(bucket/tmb/)へアップロード。
- 上記が成功したら、元ファイルのストレージクラスを標準からGlacier(bucket/archive/)に移行。
-
そして、EventBridgeを「key = prefix:org/」と制限することで、PUTを区別でき誤動作を起こさない作りに出来ますね。
"requestParameters": {
"bucketName": "samplebucket",
}
"requestParameters": {
"bucketName": "samplebucket",
"key": [
{ "prefix": "org/" }
]
}
- EventBridgeの発火条件は**「必ず」チームに共有し、設計書などにも反映させましょう。**
- ルールを知らない人が「おっ使ってなさそうだな、このファイルは新しくorg/newimage/に置くことにしよう!」とサブディレクトリを利用し始めると、意図しないタイミングでLambdaが起動されます。
Case3. ひとりぼっちなIaC編
ここまでの「作り方」で挙げたように、インフラの構成をコード化して管理するInfrastructure as Code(IaC)を活用している方も多いと思います。AWSでのIaC事情としては現状、本記事で例としたAWS CDKや、AWS CloudFormation, Terraformなどを活用するのが一般的かな、という認識です。
勉強会などの発表スライドを読むと、チーム一丸での採用例が当たり前に感じますね。半面、もう少し調査すると上述のツールを扱える人が特定メンバーに偏った状況、いわゆる「職人化」したチームもあるようです。
みなさんのチームは前者と後者、どちらでしょうか。後者のざんねんな例がどうなるか、試しに想像してみましょう。
なるべく実際の開発ライクな例を。
-
アプリケーションの仕様
- 日に一度、コンテナ上の処理を定期バッチとして起動する。
- 利用サービスは下記のAWSマネージドサービスを用いる。
- 日時トリガー(Cron):Amazon EventBridge
- ワークフロー制御:AWS Step Functions
- コンテナによるタスク実行:AWS Fargate (With Amazon Elastic Container Service(ECS))
- タスクの成功/失敗/リトライの制御はStep Functionsで実施する。
- 図はこちら。(Fargateに関するVPC周りは省略)
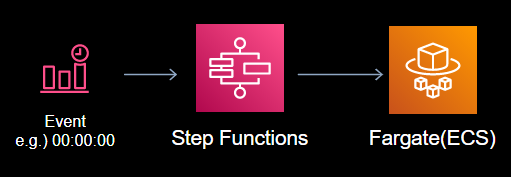
- 図はこちら。(Fargateに関するVPC周りは省略)
-
レビュ例(Step Functions)
CDKで環境テンプレートを書き上げた担当が、開発メンバにレビュを依頼しました。
もし、あなたへレビュ依頼が届いたら?という仮定でCDKの抜粋をご覧ください。
※TypeScriptの文法はあまり関係ありません。
const chain = sfn.Chain.start(runTask).next(
new sfn.Choice(this, "What is result?")
.when(sfn.Condition.isBoolean("$.iterator"), fin)
.when(sfn.Condition.isNotBoolean("$.iterator"), failed.next(runTask))
.otherwise(retry)
);
どこにバグがあるか分かりましたか?
念の為ヒントを。StateMachineのフローは下図です。永久機関が完成しちゃってます。
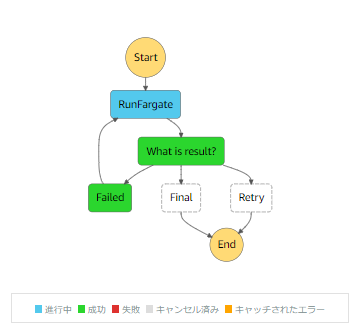
間違いには気づきましたでしょうか?
それでは正解の発表です。
const chain = sfn.Chain.start(runTask).next(
new sfn.Choice(this, "What is result?")
.when(sfn.Condition.isBoolean("$.iterator"), fin)
// NG Pattern
// .when(sfn.Condition.isNotBoolean("$.iterator"), failed.next(runTask))
// .otherwise(retry)
// OK Pattern
.when(sfn.Condition.isNotBoolean("$.iterator"), failed)
.otherwise(retry.next(runTask))
);
本来は「リトライ(retry)」フローでrunTaskに戻る(.next)べきですが、「失敗(failed)」フローで戻っている為、失敗時にループが発生してしまう恐れがある、という例でした。
※正解のStateMachineのフロー。
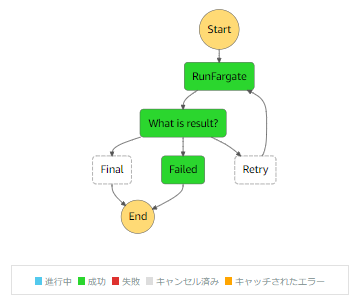
ちなみに「ざんねんな状態」の場合、 チームレビューがどうなるかというと。
- Step Functions全然わからんけど、読んでて違和感ないのでヨシ!
- 形式チェックはしてくれるパターン。
- CDKもTypeScriptもよく分からんけど、IDEでエラー出てないからヨシ!
- LintクロスチェックでOKパターン。
- うーん、○○がAWS担当だから多分大丈夫でヨシ!
- もう丸投げ。
結果としてレビュ工程はパススルーと同義となり、本例のようなケアレスミスに気付けないことも。
利用技術についてはレクチャーする、観点をチームでしっかり共有するなど、レビュ工程を形骸化させない仕組みを検討しましょう。
作り方
※本当に無限ループするので、動作を確認しだい早めに消しましょう。
サンプルコード
- CDK(TypeScript)
import * as cdk from "@aws-cdk/core";
import * as logs from "@aws-cdk/aws-logs";
import * as ec2 from "@aws-cdk/aws-ec2";
import * as ecs from "@aws-cdk/aws-ecs";
import * as sfn from "@aws-cdk/aws-stepfunctions";
import * as tasks from "@aws-cdk/aws-stepfunctions-tasks";
import * as events from "@aws-cdk/aws-events";
import * as targets from "@aws-cdk/aws-events-targets";
import * as ecsAsset from "@aws-cdk/aws-ecr-assets";
export class Case3Stack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const runTaskFargate = this.setupTaskFargate();
const stateMachine = this.setupStateMachine(runTaskFargate);
this.setupCron(stateMachine);
}
private setupTaskFargate(): tasks.EcsRunTask {
const vpc = new ec2.Vpc(this, "VPC", {});
const cluster = new ecs.Cluster(this, "FargateCluster", { vpc });
const taskDefinition = new ecs.FargateTaskDefinition(this, "TaskDef", {
memoryLimitMiB: 512,
cpu: 256,
});
// for many pull image
const repo = new ecsAsset.DockerImageAsset(this, "testRepo", {
repositoryName: "sampleapps",
directory: "lib/image",
});
const containerDefinition = taskDefinition.addContainer("TheContainer", {
image: ecs.ContainerImage.fromEcrRepository(
repo.repository,
repo.sourceHash
),
memoryLimitMiB: 256,
entryPoint: ["sleep", "10"],
});
return new tasks.EcsRunTask(this, "RunFargate", {
integrationPattern: sfn.IntegrationPattern.RUN_JOB,
cluster,
taskDefinition,
containerOverrides: [
{
containerDefinition,
},
],
subnets: { subnetType: ec2.SubnetType.PRIVATE },
resultPath: "$.iterator",
launchTarget: new tasks.EcsFargateLaunchTarget(),
});
}
private setupStateMachine(runTask: tasks.EcsRunTask): sfn.StateMachine {
const fin = new sfn.Pass(this, "Final", {
result: sfn.Result.fromObject({ success: true }),
resultPath: "$.result",
});
const failed = new sfn.Pass(this, "Failed");
const retry = new sfn.Pass(this, "Retry");
const chain = sfn.Chain.start(runTask).next(
new sfn.Choice(this, "What is result?")
.when(sfn.Condition.isBoolean("$.iterator"), fin)
// OK Pattern
// .when(sfn.Condition.isNotBoolean("$.iterator"), failed)
// .otherwise(retry.next(runTask))
// NG Pattern
.when(sfn.Condition.isNotBoolean("$.iterator"), failed.next(runTask))
.otherwise(retry)
);
return new sfn.StateMachine(this, "StateMachine", {
definition: chain,
logs: {
destination: new logs.LogGroup(this, 'MyLogGroup'),
level: sfn.LogLevel.ALL,
}
});
}
private setupCron(stateMachine: sfn.StateMachine) {
const rule = new events.Rule(this, "Rule", {
schedule: events.Schedule.expression("cron(0/5 * * * ? *)"),
});
rule.addTarget(new targets.SfnStateMachine(stateMachine));
}
}
デプロイ方法
mkdir case3
cd case3
cdk init app -l typescript
mkdir image
npm i @aws-cdk/aws-ec2 @aws-cdk/aws-ecs @aws-cdk/aws-stepfunctions @aws-cdk/aws-stepfunctions-tasks @aws-cdk/aws-events @aws-cdk/aws-events-targets
# 上述のコードに更新
vi lib/case3-stack.ts
echo -n 'FROM alpine:latest' > lib/image/Dockerfile
npm run build
# 環境デプロイ用コマンド。停止はくれぐれも自己責任で。
cdk deploy
# ※確認後に削除するコマンド
cdk destroy
影響
今回はStep Functions + Fargateの料金を考えてみましょう。
-
Fargate
-
駆動時間
- 日毎に1バッチずつ増加すると、1台 × 30day + 1台×29day … + 1台×1day分のマシンが動き続けることになります。
- 台数毎の稼働時間がバラバラなので、台数ベースでは無く、バッチ実行の合計時間に置き換えましょう。
- 結果、1ヵ月放置すると435日分、時間にして10440時間が1台実行された場合と同等になりそうです。
-
計算式はこちら。
0.5n(n-1) = 0.5 × 30 × (30 - 1) = 435 (day) 435 × 24 = 10440 (hour)
-
-
料金
- Fargateを動かした料金は「合計 vCPU 料金」 + 「合計メモリ料金」で求められます。
- 1vCPU&メモリ2GBの条件で10440時間動かす場合、請求は約 $643.32となりました。
・ 合計 vCPU 料金 = タスク数 × vCPU 数 × CPU 時間あたりの料金 × 1 日あたりの CPU 使用時間 1 × 1.0 × (0.05056) × 10440 = $527.85 ・ 合計メモリ料金 = タスク数 × メモリ (GB) × 1 GB あたりの料金 × 1 日あたりのメモリ使用時間 1 × 2.0 × (0.00553) × 10440 = $115.4664
-
-
Step Functions
-
遷移回数・料金
-
Step Functionsの利用料金はワークフローの遷移数に比例します。参考:AWS Step Functions の料金
-
サンプルのStateMachine(3つの状態遷移)の1周にかかる時間がほぼ1分なので、遷移数を計算すると約1,879,200となります。
0.5n(n-1) = 0.5 × 30 × (30 - 1) = 435 (day) 435 × 24 × 60 = 626,400 (loop) 626400 × 3 = 1,879,200 (遷移数) -
という訳で遷移数を料金レートと掛け合わせてみた結果、請求は約 $46.98となりました。
1,879,200 × 0.000025 = $46.98 -
-
したがって、このシナリオでは $643.32 + $46.98 = $690.30ほどの費用が請求されそうですね。
日が嵩むごとに加速度的に費用が加算されるシナリオなので、「あれ?ちょっと多いかな、まあ一時的なものか。」と流してしまうと大事故になる可能性を秘めているのが怖いですね……!
対処方法
- レビュの件は突き詰めるとチームビルディング論になり、話題が発散するので置いといて……
- Step Functionsは必ずロギングし、定期的に確認しましょう。
- ロギング設定は初期設定だとOFFになっています!
- 今回のようなStatemachineでは、「リトライし続ける」ことを考慮した上で対策しましょう。
- リトライ回数をカウントし、異常時に処理終了するフローを追加する。
- リトライ毎にリトライ間隔を空け、空回りする回数を減らす。(Exponential Backoff)
無限ループではないですが……
Case4はスケールアウト条件が制御不能、のシナリオをお送りします。少々毛色の異なる点、あらかじめご了承ください。
Case4. 知らなかったよK8sのAutoScaling編
クラウドはAPI経由でリソースを簡単に、かつ柔軟に調達できて素晴らしいですよね!
それを生かしたAutoScalingの概念もすっかり定着しました。
「Auto」ということは……もうお分かりですね?
特に動的スケールイン/アウトにおいて、以前はこんなつらい無限ループのシナリオがありました。
- インスタンスがスケールアウトし、n台分×1時間の料金が発生!
- スケールアウトしたインスタンスが何らかの理由で起動に失敗、スケールイン(1.の元々の台数へ)
- 再度スケールアウトを試みる、を繰り返すことで大量のEC2使用料金が発生
現在のEC2は最小60秒の秒単位課金が一般的ですし、時代はVMからコンテナの時代へ。
と言いつつEC2 AutoScalingの事故は過去の話です、とは言い切れない状況。Fargateに対応したとはいえ、EKSのノードは未だにEC2が多いですしね。
ワークロードにも寄りますが、一般的にAWS費用においてEC2はかなりの割合を占めるものです。無駄遣いはしたくないですよね?
コンテナ時代のAutoScalingはどう留意すればいいのか、Kubernetesの機能を使って確認してみましょう。
補足(HPA & CA)
AWS記事なので、一応Kubernetes知らない読者への補足を。
-
Kubernetes
- 言わずと知れたコンテナオーケストレータの代表格
- ピンとこない方は「複数台のマシンでコンテナ(プロセス)を、クラウドのVMのように柔軟に管理するOSS」と読んで頂ければ、とりあえずOKです。
- Kubernetesの(水平)スケーリング
- クラウドベンダに寄らない方法として、独自のAutoScalingの機構が存在しています。
-
Horizontal Pod Autoscaler(HPA)
- Kubernetes管理のメトリクス(CPU負荷など)に応じて、コンテナのスケールイン/アウトを制御する。
-
Cluster Autoscaler(CA)
- Kubernetesのワーカーノード(マシン)のスケールイン/アウトを制御する。
- AWSの場合、EC2 Auto Scalingに希望するキャパシティを直接伝える。
- スケーリングポリシーに寄らないのがポイント。
-
Horizontal Pod Autoscaler(HPA)
- つまりHPA+CAによって、コンテナの負荷をトリガーとして間接的にEC2のAutoScalingを発火可能となる。
- e.g. HPAがCPU使用率の高騰を検知し、コンテナを増やす。しかしワーカーノードのリソース不足で増やしたコンテナが起動できないため、CAでノード(EC2)を増やす。
- クラウドベンダに寄らない方法として、独自のAutoScalingの機構が存在しています。
- ちなみにHPA、CAの仕組みをAWSへマッピングした構成図がこちら。(作画の限界を感じる)
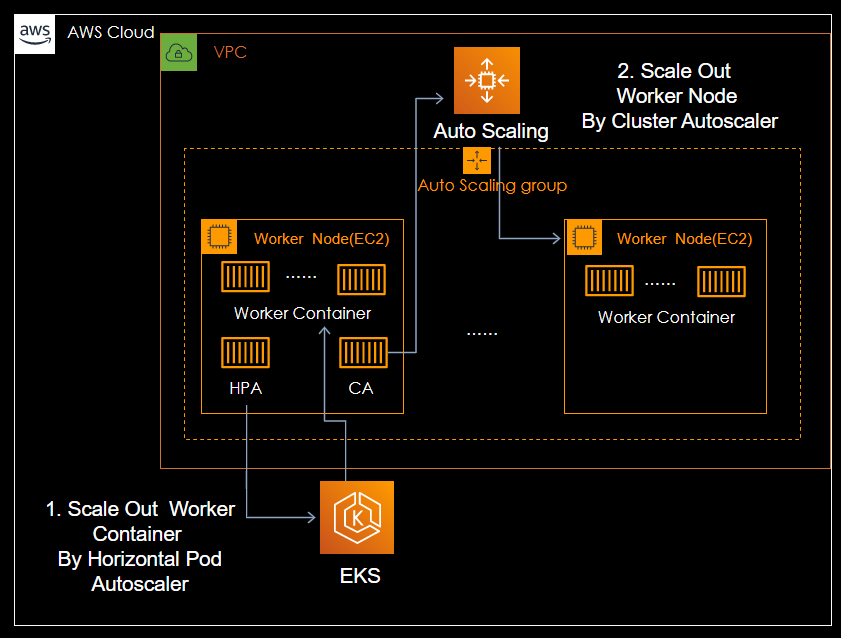
作り方
※本当に無限ループするので、動作を確認しだい早めに消しましょう。
サンプルコード
- CDK(TypeScript)
FROM alpine:latest
- 作成メモ
- eks.clusterのdefaultでManegedWorkerNodeを作成するとRoleなど設定し辛いので、addNodegroupCapacityで明示的に作成。
- リクエスト数が多い(100pull/6hour)とdockerhubがエラーを返すので、ECRを構築
- clusterEndpointはpublic and Privateでないと、PrivateSubnetのNodeの認識に失敗する?(未検証)
- Cluster AutoScalerの設定は公式を参照。
import * as cdk from "@aws-cdk/core";
import * as eks from "@aws-cdk/aws-eks";
import * as ec2 from "@aws-cdk/aws-ec2";
import * as iam from "@aws-cdk/aws-iam";
import * as ecsAssets from "@aws-cdk/aws-ecr-assets";
import { safeLoadAll } from "js-yaml";
export class Case4Stack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// IamRole name in (List)
const myEksAdmins: string[] = ["xxxxxxxx"];
const maxInstance: number = 5;
const [cluster, role] = this.createEKSCluster();
this.settingWorkerNode(cluster, maxInstance);
this.loadScalingManifest(cluster);
this.settingAwsAuth(cluster, role, myEksAdmins);
this.settingSampleApp(cluster);
}
private createEKSCluster(): [eks.FargateCluster, iam.Role] {
const eksRole = new iam.Role(this, "eksRole", {
assumedBy: new iam.CompositePrincipal(
new iam.ServicePrincipal("eks.amazonaws.com"),
new iam.AccountPrincipal(this.account)
),
managedPolicies: [
iam.ManagedPolicy.fromAwsManagedPolicyName("AmazonEKSClusterPolicy"),
iam.ManagedPolicy.fromAwsManagedPolicyName("AmazonEKSServicePolicy"),
],
});
const clusterAdmin = new iam.Role(this, "clusterAdmin", {
assumedBy: new iam.AccountRootPrincipal(),
});
const cluster = new eks.Cluster(this, "hello-eks", {
clusterName: "case4-cluster",
version: eks.KubernetesVersion.V1_18,
role: eksRole,
mastersRole: clusterAdmin,
defaultCapacity: 0,
endpointAccess: eks.EndpointAccess.PUBLIC_AND_PRIVATE,
outputClusterName: true,
});
return [cluster, clusterAdmin];
}
private settingAwsAuth(
cluster: eks.FargateCluster,
clusterAdmin: iam.Role,
myEksAdmins: string[]
) {
const awsAuth = new eks.AwsAuth(this, "AwsAuth", {
cluster: cluster,
});
awsAuth.addRoleMapping(cluster.role, {
groups: ["system:bootstrappers", "system:nodes"],
username: "system:node:{{EC2PrivateDNSName}}",
});
awsAuth.addMastersRole(
iam.Role.fromRoleArn(this, "clusterAdminAtAwsAuth", clusterAdmin.roleArn),
clusterAdmin.roleName
);
myEksAdmins.forEach((roleName) => {
awsAuth.addMastersRole(
iam.Role.fromRoleArn(
this,
`${roleName}`,
`arn:aws:iam::${this.account}:role/${roleName}`
),
`${roleName}`
);
});
}
private settingWorkerNode(cluster: eks.FargateCluster, maxInstance: number) {
const eksWorkerRole = new iam.Role(this, "eksWorkerRole", {
assumedBy: new iam.ServicePrincipal("ec2.amazonaws.com"),
managedPolicies: [
iam.ManagedPolicy.fromAwsManagedPolicyName("AmazonEKSWorkerNodePolicy"),
iam.ManagedPolicy.fromAwsManagedPolicyName(
"AmazonEC2ContainerRegistryReadOnly"
),
iam.ManagedPolicy.fromAwsManagedPolicyName("AmazonEKS_CNI_Policy"),
],
});
const autoscalerPolicy = new iam.Policy(this, "cluster-autoscaler-policy", {
statements: [
new iam.PolicyStatement({
actions: [
"autoscaling:DescribeAutoScalingGroups",
"autoscaling:DescribeAutoScalingInstances",
"autoscaling:DescribeLaunchConfigurations",
"autoscaling:DescribeTags",
"autoscaling:SetDesiredCapacity",
"autoscaling:TerminateInstanceInAutoScalingGroup",
"ec2:DescribeLaunchTemplateVersions",
],
resources: ["*"],
}),
],
});
eksWorkerRole.attachInlinePolicy(autoscalerPolicy);
const worker = cluster.addNodegroupCapacity("custom-node-group", {
nodeRole: eksWorkerRole,
desiredSize: 1,
minSize: 1,
maxSize: maxInstance,
instanceType: ec2.InstanceType.of(
ec2.InstanceClass.T3,
ec2.InstanceSize.MEDIUM
),
subnets: { subnetType: ec2.SubnetType.PRIVATE },
});
// to delay resolution to deployment-time
const clusterName = new cdk.CfnJson(this, "clusterName", {
value: cluster.clusterName,
});
cdk.Tags.of(worker).add(
`k8s.io/cluster-autoscaler/${clusterName}`,
"owned",
{ applyToLaunchedInstances: true }
);
cdk.Tags.of(worker).add("k8s.io/cluster-autoscaler/enabled", "true", {
applyToLaunchedInstances: true,
});
}
private loadScalingManifest(cluster: eks.Cluster) {
const manifestHpaUrl =
"https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.3.6/components.yaml";
const manifestCaUrl =
"https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml";
const fetch = require("node-fetch");
async function load(url: string, name: string) {
try {
const res = await fetch(url);
const body = await res.text();
const manifest = safeLoadAll(
body.replace("<YOUR CLUSTER NAME>", cluster.clusterName)
);
cluster.addManifest(`manifest-${name}`, ...manifest);
} catch (err) {
console.error(err);
}
}
load(manifestHpaUrl, "hpa");
load(manifestCaUrl, "ca");
}
private settingSampleApp(cluster: eks.FargateCluster) {
// for many pull image
const repo = new ecsAssets.DockerImageAsset(this, "testRepo", {
repositoryName: "sampleapps",
directory: "lib/image",
});
const appLabel = { app: "sampleapp" };
const spec = { cpu: "100m", memory: "16Mi" };
const minPods = 1;
const deployname = "case4"
const deployment = {
apiVersion: "apps/v1",
kind: "Deployment",
metadata: { name: deployname, labels: appLabel },
spec: {
replicas: minPods,
selector: { matchLabels: appLabel },
template: {
metadata: { labels: appLabel },
spec: {
containers: [
{
name: "sample",
image: repo.imageUri,
command: ["dd", "if=/dev/zero", "of=/dev/null"],
resources: { limits: spec, requests: spec },
},
],
},
},
},
};
cluster.addManifest("sample-deployment", deployment);
const hpa = {
apiVersion: "autoscaling/v2beta1",
kind: "HorizontalPodAutoscaler",
metadata: { name: "case4-hpa" },
spec: {
scaleTargetRef: {
apiVersion: "apps/v1",
kind: "Deployment",
name: deployname,
},
minReplicas: minPods,
maxReplicas: 100,
metrics: [
{
type: "Resource",
resource: {
name: "cpu",
targetAverageUtilization: 80,
},
},
],
},
};
cluster.addManifest("sample-hpa", hpa);
}
}
デプロイ方法
mkdir case4
cd case4
cdk init app -l typescript
mkdir image
npm i @aws-cdk/core @aws-cdk/aws-ec2 @aws-cdk/aws-eks @aws-cdk/aws-iam @aws-cdk/aws-ecr-assets @types/js-yaml node-fetch
# 上述のコードに更新
vi lib/case4-stack.ts
echo -n 'FROM alpine:latest' > lib/image/Dockerfile
npm run build
# 環境デプロイ用コマンド。停止はくれぐれも自己責任で。
cdk deploy
# CDKが成功した時に出力される「update-kubeconfig」を実行し、kubectlコマンドを利用可能に。
aws eks update-kubeconfig --name case4-cluster --region ap-northeast-1 --role-arn arn:aws:iam::xxxxxxxxxxxx:role/Case4Stack-clusterAdminXXXXXXXX-XXXXXXXXXXXXX
Added new context arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/case4-cluster to /home/ec2-user/.kube/config
# case4, cluster-autoscalerが下例と同様なことを確認。
kubectl get deploy -A
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
default case4 1/1 1 1 48m
kube-system cluster-autoscaler 1/1 1 1 48m
kube-system coredns 2/2 2 2 57m
kube-system metrics-server 1/1 1 1 48m
# ※確認後に削除するコマンド
cdk destroy
影響
簡単に言うと、Kubernetesが追加インスタンスをリクエストし続けてしまい、EC2数が常時AutoScalingの最大数まで達してしまう危険性があります。
よくあるEC2 AutoScalingのスケールアウト誤りと異なる点として、AWSリソースだけを監視しても状況に気付けない場合があります。
HPAのスケール条件を、例えばコンテナのCPU使用率としていれば、EC2のCPU使用率から間接的に把握できます。しかしコンテナの秒当たりキュー数やコネクション数などをトリガーにした場合はどうでしょう?
CloudWatchの監視観点に入っていなかったり、Kubernetesの監視ダッシュボードと連携させてない場合は検知が遅れたり、最悪検知が漏れてしまうこともあります。
「そもそもEC2って、OSSからの操作でそんな簡単に増えちゃうの?」という方のために、KubernetesのAutoScalingを実演してみましょう。
※下例は検証を簡単にするため、PodのCPU使用率をトリガーとしています。
# init
#################################################
# 一旦pod数を0にして, node数1になるようにリセット。
kubectl scale --replicas 0 deploy/case4
deployment.apps/case4 scaled
# EC2(WorkerNode)の数が1台であることを確認
kubectl get node
NAME STATUS ROLES AGE VERSION
ip-10-0-244-126.ap-northeast-1.compute.internal Ready <none> 77m v1.18.9-eks-d1db3c
# start
#################################################
# cdk deploy直後の状態に戻す。(pod=1)
kubectl scale --replicas 1 deploy/case4
deployment.apps/case4 scaled
# コンテナの数(deployment管理のpod数)を確認
kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
case4 1/1 1 1 95m
# 少し待つ(10分強?)
# この間にコンテナ内でCPU負荷がかかり、発火条件を超えると(今回はCPU使用率>80%)HPAでPodがスケール
kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
case4 26/33 33 26 108m
# CAにより、EC2(Node)も3台に増えている。
kubectl get node
NAME STATUS ROLES AGE VERSION
ip-10-0-185-186.ap-northeast-1.compute.internal Ready <none> 4m14s v1.18.9-eks-d1db3c
ip-10-0-225-195.ap-northeast-1.compute.internal NotReady <none> 10s v1.18.9-eks-d1db3c
ip-10-0-244-126.ap-northeast-1.compute.internal Ready <none> 111m v1.18.9-eks-d1db3c
# その後6分ほどでコンテナ数が50を超え、EC2(WorkerNode)がスケールアウト(3台→5台)したことを確認
kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
case4 56/64 64 56 114m
# CA設定での最大数(5台)になりました。
kubectl get node
NAME STATUS ROLES AGE VERSION
ip-10-0-130-133.ap-northeast-1.compute.internal Ready <none> 3m5s v1.18.9-eks-d1db3c
ip-10-0-185-186.ap-northeast-1.compute.internal Ready <none> 10m v1.18.9-eks-d1db3c
ip-10-0-225-195.ap-northeast-1.compute.internal Ready <none> 6m28s v1.18.9-eks-d1db3c
ip-10-0-244-126.ap-northeast-1.compute.internal Ready <none> 117m v1.18.9-eks-d1db3c
ip-10-0-247-0.ap-northeast-1.compute.internal Ready <none> 21s v1.18.9-eks-d1db3c
Kubernetesの機能を用いて、間接的にEC2のAutoScalingを再現出来ました。
元々アクセスパターンに波のあるシステムであれば、EC2使用量が上限に張り付けば、直ぐ気付けるかもしれません。しかし、高負荷が断続的に長期間、発生し得るシステムでは「最近は負荷が大きいな~。ユーザ数増えたからかな? 予算を申請してEC2 AutoScalingの上限を上げるか。」と安易に判断し、結果として不必要に支払額を増やしてしまう可能性も。
対処方法
-
極々当たり前の話なのですが、リソースの増え方を監視しましょう。
- 注意としては、インフラ部隊の中でも「AWS」と「それ以外(今回はKubernetes)」とで担当が分かれていると、今回のように領域を横断するケースでの観点が漏れる恐れがあります……。
-
AWSリソース外も、同列に監視できるスキームを整備しましょう。
-
Container Insights + CloudWatch
で、AWS監視のスキームに寄せるのは王道。 - AWSアーキテクチャの依存度を減らしたいからKubernetes使っとるんじゃ!な方はGrafana(+ Prometheus)で、CloudWatchの内容も併せてウォッチする体制もありです。
- とは言え、監視基盤を管理するのは大変なので、マネージドOSSに頼るのも?(2020.12.17時点でプレビューですが)
-
Container Insights + CloudWatch
「ざんねん」にしない3つのTips
極端な話、「スケールイン/アウト、非同期的なアーキテクチャを禁ずる!」とすれば大半の無限ループは防げます。ただ、それではクラウドを有効活動出来ず、コスト効率の悪い利用方法になってしまうことも。クラウドネイティブな利用法とうまく付き合う方法は無いのでしょうか?
比較的導入しやすいTipsを3つ紹介します。
1. 毎日のリソース利用量(≒料金)をウォッチしよう。
クラウドは利用時間に比例して課金が発生しますが、裏を返せば「請求の上昇率をウォッチすれば、想定外の利用状況を検出できる」とも言えます。とにかく計測しましょう。
ちなみに経験談として「担当が毎日がAWS コンソールを見に行く」という運用だと続きません(笑)
チームが利用中のチャネルにEmail、チャット(Slack or Amazon Chime)があるならば、まずはAWSコンソールからAWS Budgets→コスト予算と進んで、
- 間隔:日別
- 予算額:$0.01
で設定するのが、手軽かつ効果的です。
異常な支出を機械学習で検知してくれるAWS Cost Anomaly Detectionも早くGAになって欲しいですね!
2. 「クラウドネイティブ」なレビュをしよう。
今回は様々な例を挙げてきましたが、**アーキテクチャレベルでの無限ループ対策が出来ているか?**という観点があれば防げたものもあります。
有識者レビュを十分に受けられれば一番ですが、要員のスケジュール上、難しい場合もありますよね。「書くのも見るのも、自分一人しか居ないんだよ!」って時も稀にある……
私の場合、大抵下記を言い聞かせてセルフレビューしています。
- 注意すべきはスケール条件と非同期実行
- テストコードは👍でも、マネージドによる準正常、異常ルート考慮できてますか?
- 課金パターンを把握して、危険なシナリオは想定できるか?
3. リリース確認は「動き過ぎていないか」まで確認しよう。
特に商用環境のデータ量で、事故を起こすと例に挙げた費用感の数十倍~数百倍に達してしまうことも!?
リリース後、数時間後にCloudWatchのダッシュボードを覗いてみましょう。
エラーのアラートも出ていないし、動いているから良いか! が必ずしも正で無いのは今回の記事でもお分かりいただけたと思います。
少なくとも、CloudWatch Metrics&Logsは必見ですよ!(オライリーの入門・監視でも「SaaSに頼ろう」と書いていましたね。)
おわりに
なかなかのボリュームになってしまいましたが、AWSのアンチパターン集はいかがでしたでしょうか。
本編ではさらっと流しましたが、AWS CDK、かなり最高です! CloudFormation運用な方は移行しやすいと思うので是非試してください!
明日は、@yamkazuによるリモートアジャイルに関する記事です。引き続き、NTTテクノクロス Advent Calendar 2020をお楽しみください。もうすぐメリークリスマス!🎄
Appendix
CDK VS CloudFormation (Line数)
CDKでの記述量とYAMLに変換した場合の行数を比較してみましょう。(cdk synthコマンド)
| Case | Line(CDK) | Line(CloudFormation) |
|---|---|---|
| Case 1 | 140 | 388 |
| Case 2 | 72 | 216 |
| Case 3 | 86 | 615 |
| Case 4 | 215 | 1142 |
減った行数分の生産性が線形に比例して向上する訳ではないですが、リソース間の関係が理解しやすくなり、管理も容易になるのはうれしいですよね。
学習関連
-
AWS Cloud Design Pattern(CDP)
- そもそもAWSの正しいアーキテクチャとは?の大定番。
- 少々古い情報もあるので、後述するCDK Pattarnsの併用が無難。
-
AWS CDK Patterns
- CDKの代表的な作成パターン、およびコードサンプル集。
- アーキテクチャ例としてもいい感じ。
-
実践 AWS CDK
- CDK&TypeScriptの日本語情報はまだ少ない。
- 有料だがこの本を読んだ上で入門するのが、結果として効率的かと。(先に読んでおけば…)
-
AWS Solutions Constructs
- CDKの高レベル拡張ライブラリ。先に読んでおけば……シリーズ第二弾。
- 例えばCase1のAPI Gateway to DynamoDBなど、Well-Architectedパターンをより簡潔に表現可能です。