このシリーズを読むと何がわかる?
・Webページからデータを集めるためにはどうすればいいか
・scrapy shellによる対話的なスクレイピング
・scrapyによる基本的なクローラの作り方
・WebページにおけるHTMLの解析法
・javascriptに対処するスクレイピング法(scrapy + splash)
・scrapyとMongoDBの連結法
・あにこれさんにどんなデータがあるか
この記事では何がわかる?
・Webページからデータを集めるためにはどうすればいいか
・scrapy shellによる対話的なスクレイピング
・WebページにおけるHTMLの解析法
これは何をした記事?
実際のWebサイトに対してスクレイピングをした経験を記事にしました.あにこれさんをスクレイピングしました.使用したツールはscrapyです.
状況設定
あなたはアニメのレコメンドシステムを作りたいとします.しかし,適切なデータを用意するのは大変な作業です.幸いなことにあにこれというサイトにさまざまなアニメや,ユーザ,レイティングなどのデータがあることを知りました.これを利用したいのですが,手動でWebページを一つずつアクセスしながらメモを取る...というのは明らかに無理そうです.
このような問題を解決する技術としてスクレイパーが挙げられます.Pythonではscrapyというライブラリで用意にスクレイパーが作れるので,実際に作ってみます.
Scrapyのインストール
pip install scrapy
どのようなデータを取るか
まずはどのようなデータを取るか確認します.あにこれさんはさまざまなアニメに対し,ユーザによる評価データが存在します.このシリーズでは,これらを大きく四つのテーブルに分けて取得することにします.
①アニメ
たとえばこのページにおけるステータスタブとあらすじがこのテーブルに属します.
②タグ
このページにおけるタグ(アニメ成分)を取得します.タグ名とそのタグにいいねしている人数をセットとします.
③レビュー
このページにおける全レビューを取得します.レビューがされたの時間,レビューしたユーザ,評価点,本文などもセットで取得します.なお,このページはjavascriptで動的にHTMLが変化するため,それに対処する必要があります.このシリーズではsplashを使いました.
④ユーザ
ユーザに関するページはログインしてないと閲覧できません.ログインしていれば,このページを閲覧できます.このテーブルのデータとしてはユーザの基本的な情報や,アニメに対しての分類(観たい,今見てる,観終わった,途中で断念した)を取得します.
アニメテーブルの取得(Xpathの確認)
ページの確認
スクレイピングはHTMLのどこの情報を参照するかを指定する必要があるので,このページで取りたい情報がどこに書いてあるか確認します.たとえばアニメの総合点が取得したいとします.
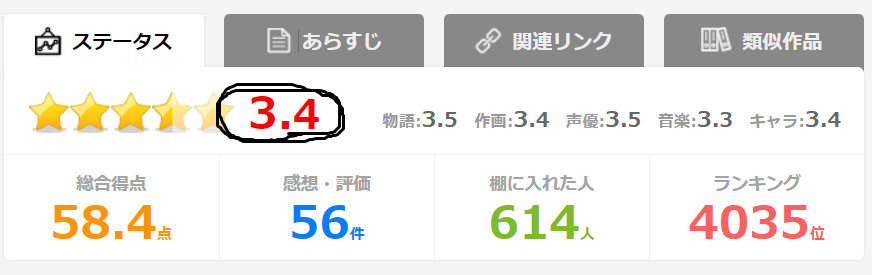
この部分のHTMLを確認するためにブラウザのディベロッパー機能を使います.ChromeならF12を押すと右側にいろいろ出てくるはずです.見たい所のHTMLを表示させるには,例えば,右クリックで出てくるメニューから.「検証」を選ぶと,対応するHTMLが協調されます.総合点の部分を右クリックして「検証」を選んでみてください.私の画面では次のようになりました.
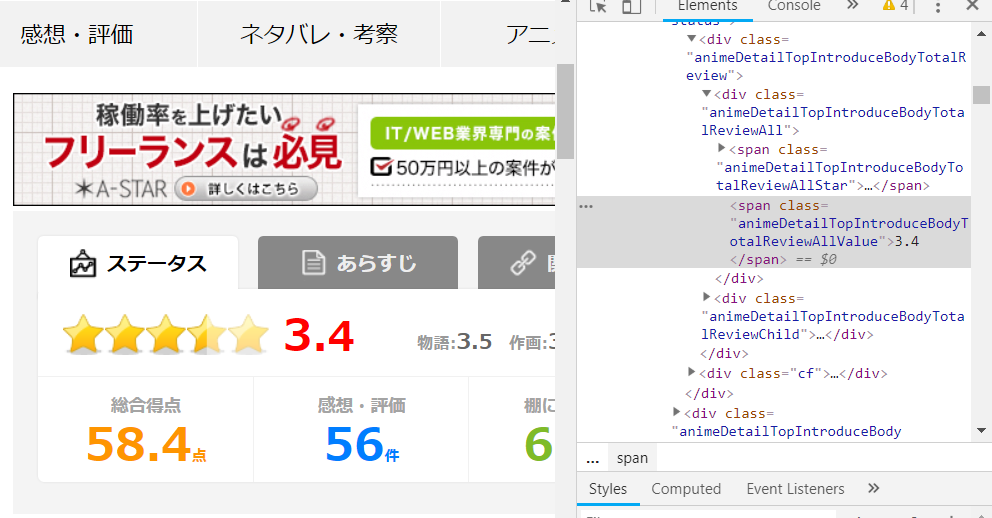
3.4というアニメの総合点がHTMLに確認できます.よって,ここの部分を抜き出すようなプログラムを作ればよさそうです.
対話的にスクレイピング
次は上記のページにアクセスし,総合点の部分を抜き出す方法について解説します.scrapy shellは対話的にスクレイピングすることができます.次のコマンドで起動します.
scrapy shell
fetch(URL)でURLのページのHTMLを得ることができます.結果は自動的にresponseという変数に保存されます.responseの詳細については公式ドキュメントで確認してみてください。
fetch('https://www.anikore.jp/anime/11553/')
response.url
>>>https://www.anikore.jp/anime/11553/
Xpath
HTMLで抜き出したい部分を指定する文法として、Xpathというものがあります。Xpathの記法に関しては@rllllhoさんのこの記事がわかりやすいです。
便利な方法として、Chromeの検証機能から指定した部分のXpathを抜き出すことができます。
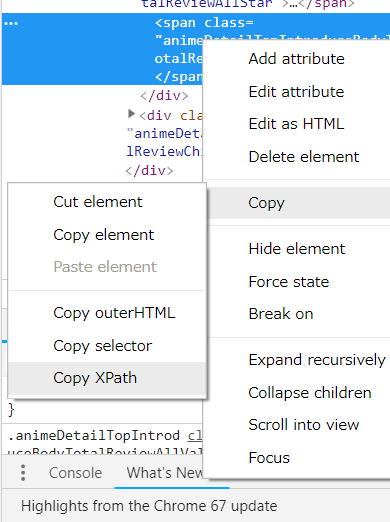
response.xpath([抜き出したいXpath])でresponseから抜きたい部分を抜き出せます。
node = response.xpath(response.xpath('//*[@id="main"]/div[2]/div[2]/div[1]/div[1]/span[2]')
node
>>>[<Selector xpath='//*[@id="main"]/div[2]/div[2]/div[1]/div[1]/span[2]' data='<span class="animeDetailTopIntroduceBody'>]
responseから.xpathで抜き出すと,SelectorListが返ってきます。SelectorList.extract()でHTMLを表示できます。
node.extract()
>>>['<span class="animeDetailTopIntroduceBodyTotalReviewAllValue">3.4</span>']
HTMLのテキスト部分(<>に囲まれてない部分)を抜き出すには、Xpathの末尾にtext()を追加しましょう。
text = response.xpath('//*[@id="main"]/div[2]/div[2]/div[1]/div[1]/span[2]/text()')
text.extract()
>>>['3.4']
やったぜ!
今回のまとめ
できたこと
Webページからほしい情報をscrapyによって抜き出すことに成功しました!
次回やること
今回は対話的に抜き出したので手間はメモとペンを使うより増えてしまいました。しかし、抜き出し方のルールを確定されることができたので、あとは複数のページに対して実行させるだけです。これはクローラと呼ばれている技術です。(scrapyではspiderと呼ばれています。)次回ではspiderを書いていきたいと思います。