記載内容は所属会社を代表したものではなく、私の個人的な意見ということをご了承ください。
はじめに
本件は自己学習のために使用しています。
過去問の外部公開に関しては留意点がございますのでご確認お願いします。
https://www.ipa.go.jp/shiken/faq.html#seido
本題
皆さん!普通の基本情報技術者試験の勉強には飽きたんじゃないでしょうか?
エンジニアの登竜門とも呼ばれてる基本情報技術者試験ですが私も入社4年目ですがまだ取れてません!笑
そろそろ後輩たちにも舐められ始めるので先輩の威厳のためにも取らないと、、、
そこで新しい勉強方法を考えてみたのでご紹介します!
なお、CBT形式になってからは過去問が公開されていないので、サンプル問題しかデータソースはありません😅
用語説明
まずは今回使用するAWSのサービスについて説明します。
・Amazon S3
✔ Amazon S3 は、業界最高水準のスケーラビリティ、データ可用性、セキュリティ、およびパフォーマンスを提供するオブジェクトストレージサービスです。
✔ データレイク、ウェブサイト、クラウドネイティブアプリケーション、バックアップ、アーカイブ、機械学習、分析など、さまざまなユースケースのあらゆる量のデータを保存および保護します。
✔ Amazon S3 は 99.999999999% (9 x 11) の耐久性を実現するように設計されており、世界中の何百万ものお客様のデータを保存しています。
・Lamda関数
AWS Lambda : サーバーを意識せずにコードを実行できる AWS のサーバーレスコンピューティングサービス
Lambda 関数 : AWS Lambda によって管理、実行されるアプリケーションのコードとその設定
・Amazon Bedrock
Amazon Bedrock は、AI21 Labs、Anthropic、Cohere、Meta、Stability AI、Amazon などの大手 AI 企業が提供する高性能な基盤モデル (FM) を単一の API で選択できるフルマネージド型サービスです。また、生成 AI アプリケーションの構築に必要な幅広い機能も備えているため、プライバシーとセキュリティを維持しながら開発を簡素化できます。
・Amazon Kendra
Amazon Kendra は、機械学習 (ML) を利用したインテリジェント検索サービスです。Amazon Kendra は、ウェブサイトやアプリケーションのエンタープライズ検索を再構築します。企業の従業員やお客様は、組織内のさまざまな場所やコンテンツリポジトリにコンテンツが散在している場合でも、目的のコンテンツを見つけることができます。
基本設計
Amazon Bedrock + Amazon Kendraを使用した以下のシンプルな構成で考えています。
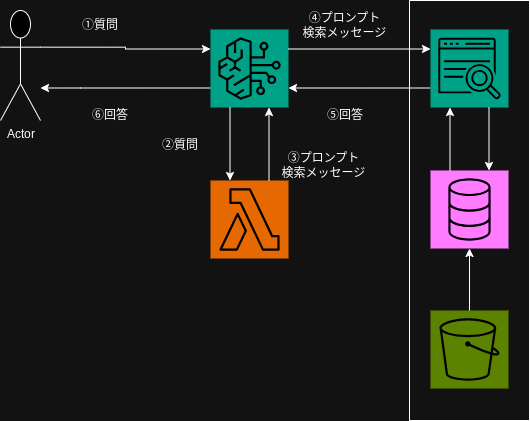
実現方法
①まずはデータ集めです。
IPAで公開されている基本情報技術者試験の過去問、シラバスをかき集めてS3バケットに保存します。
(データ集めしんどかった笑)
②続いてAmazon Kendraのインデックスを作成します。
※ここからKendraの従量制課金が始まります。稼働時間に対して料金がかかるので後の手順はちゃっちゃと進めましょう!(若しくは⑤で実装が終わって関数を実行するタイミングにデプロイしても良いでしょう)
「Create Index」からインデックスを作成します。
できました!
なお、途中でIAMロールの作成、選択を求められますが適切なものを選んでください。IAMに関しては別途セキュリティ編を用意してそこで解説予定です
③インデックスのデータソースとして①を選択します。
「Add data sources」を押下し、S3のデータをセットします。
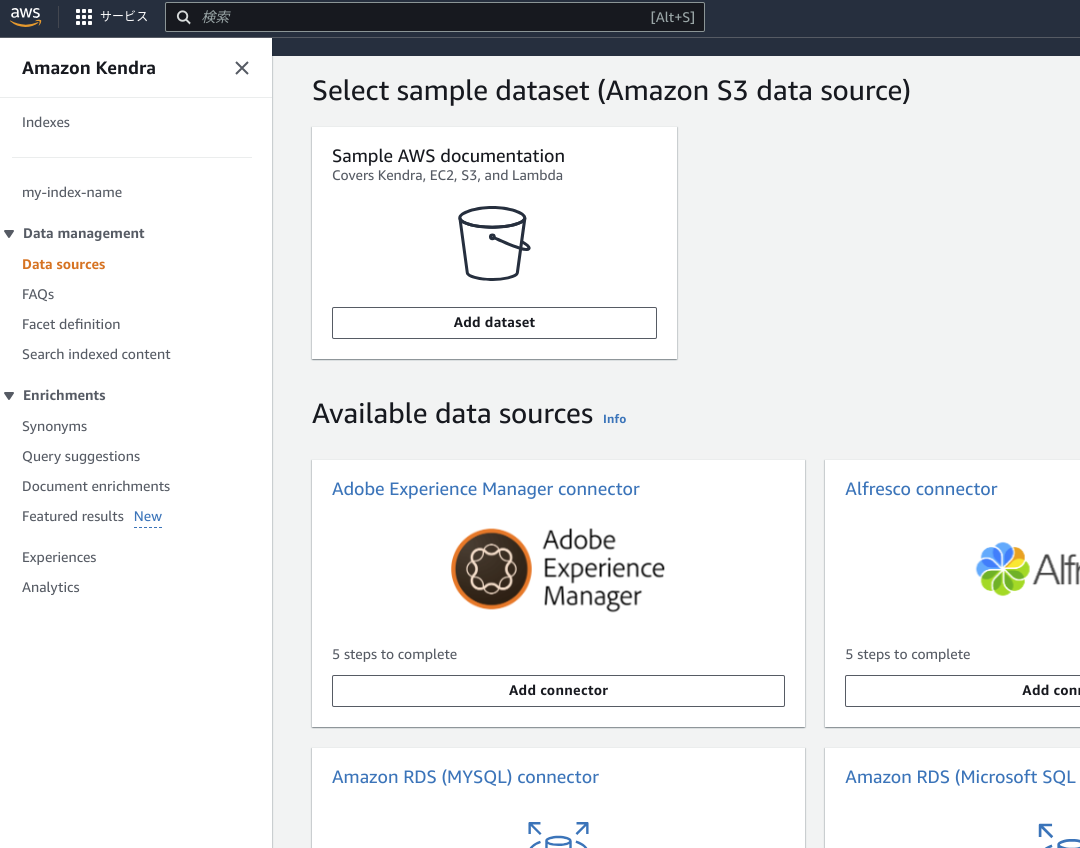
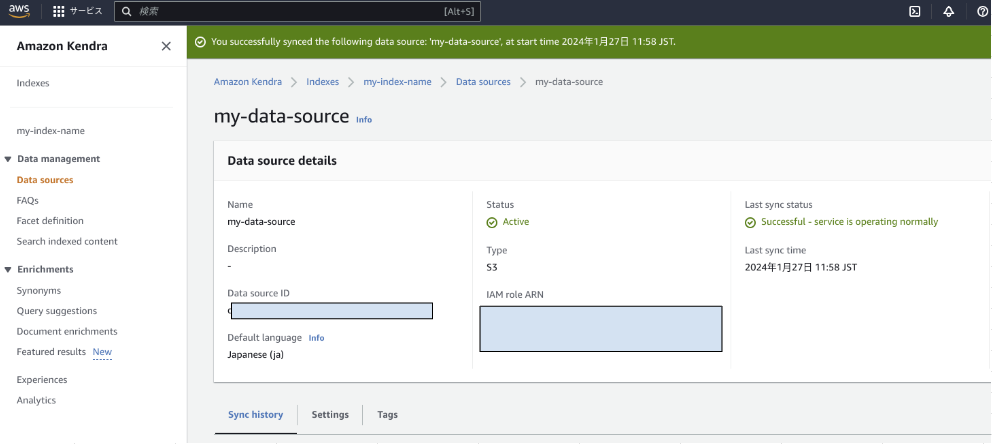
そして「Actions」から「Edit」を選択して、項目を進めて①でデータを集めたバケットを選択して更新します。
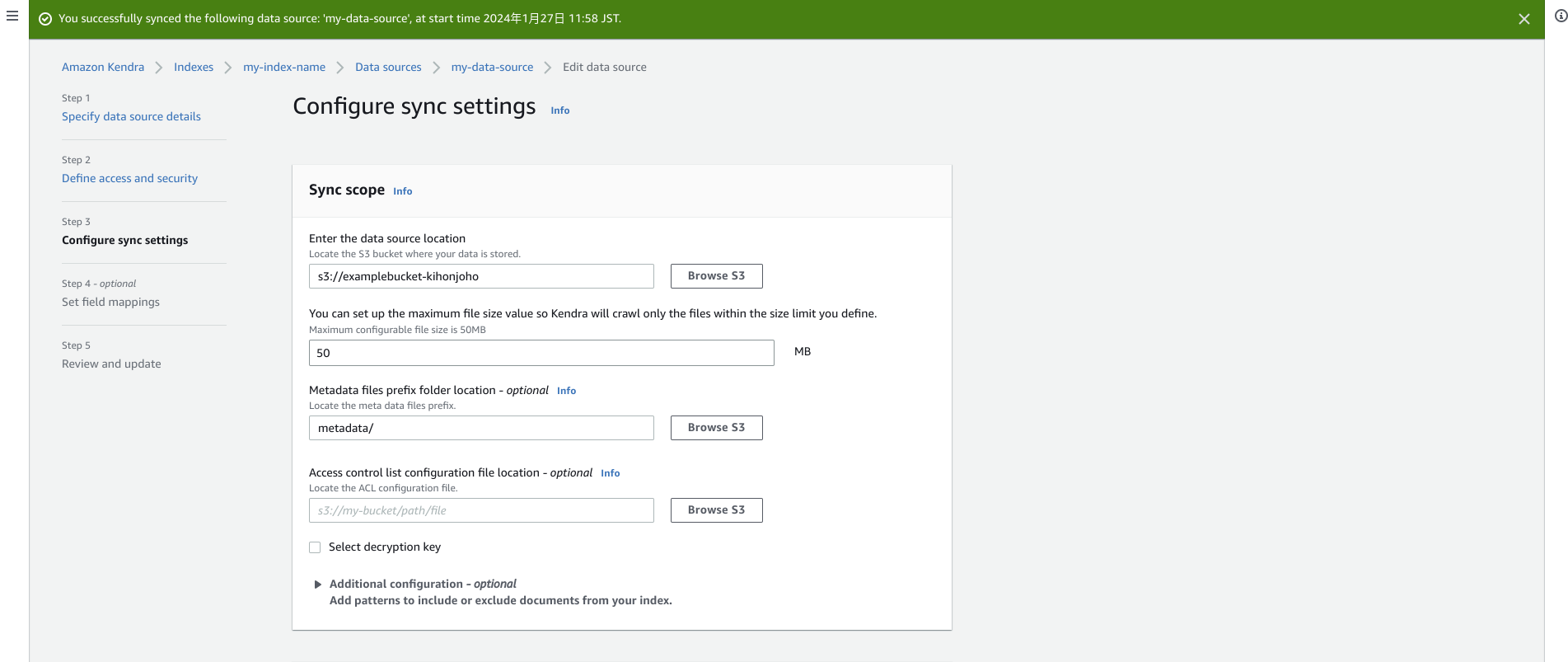
→この時点でテスト動作可能ですので動かしてみましょう。
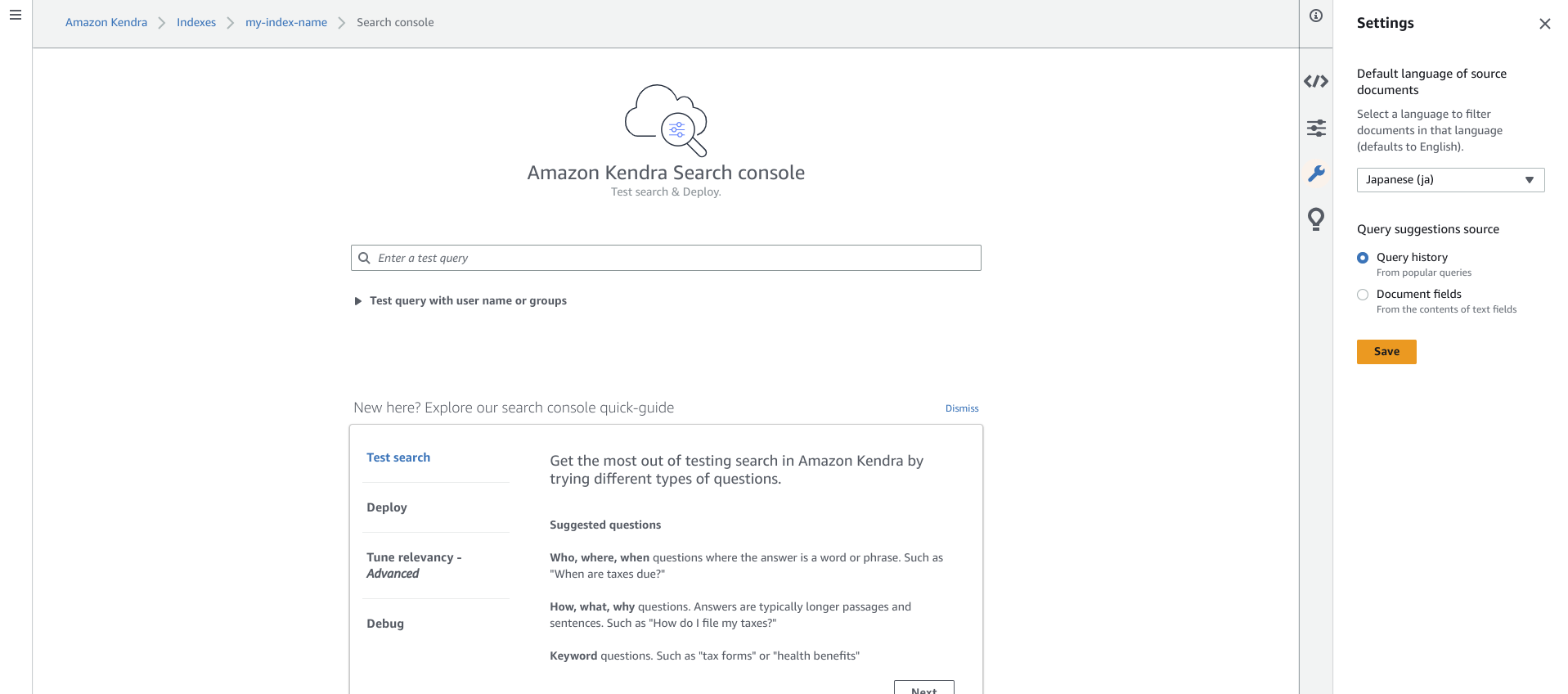
「Search indexed content」を選択して、テスト動作します。
※言語を日本語に設定してください。
プロンプトも作ってない状態でしたので、検索結果に出典が明記されなかったのでこのタイミングでの検索結果の公表は控えさせていただきます。
個人で楽しんでみてください。
※最悪この状態だけでも、検索の仕方を工夫すれば自己学習には使えますが、皆様に公開出来るよう最後まで作っていきたいと思います。
④デプロイして使えるようにします。
「Create experience」を押下し、デプロイします。(個人情報の入力が発生するので手順は割愛)
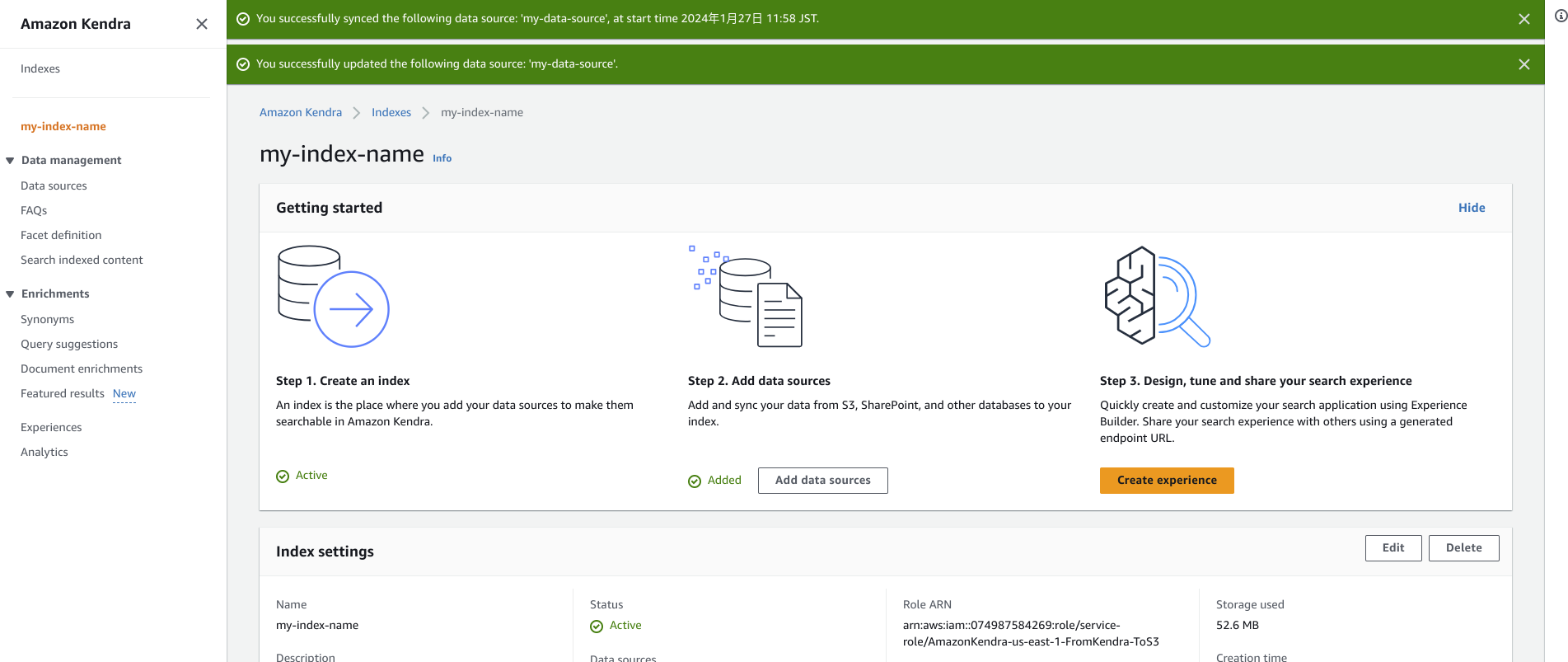
↑ここまででもどうにか学習に使えるレベルにはなります。
イメージ的には基本情報技術者試験に特化した、検索サイトみたいな感じになります。
(現時点で、IPAの規約通り出典元を正しく表示することが上手くいってないので公開は控えさせていただきます。)
↓ここからはオプションです。
RAG形式で使えるようにするため、下記の手順を行います。
⑤Lamda関数を使用してプロンプトと検索クエリを実装して作成します。
import boto3
def lambda_handler(event, context):
# Kendraクライアントを作成
kendra = boto3.client('kendra')
# ユーザーの質問を取得
user_query = event["queryStringParameters"]["query"]
# Kendraに質問を送信して回答を取得
kendra_response = kendra.query(
IndexId='YOUR_KENDRA_INDEX_ID',
QueryText=user_query
)
# Kendraからの回答を解析してRAG形式のフィードバックを生成
feedback = generate_rag_feedback(kendra_response)
# レスポンスを作成
response = {
"statusCode": 200,
"body": feedback
}
return response
def generate_rag_feedback(kendra_response):
# Kendraからの回答を解析して、RAG形式のフィードバックを生成するロジックを実装
# ここでは過去問の回答と比較し、適切なフィードバックを生成する例を示します
# この部分は具体的なロジックに応じてカスタマイズしてください
# 仮のロジック例: 回答が完全に正しい場合は"Green"、一部正しい場合は"Amber"、間違っている場合は"Red"を返す
if kendra_response["Answer"] == "正解":
return "Green - この問題は完全に正解です!"
elif kendra_response["Answer"] == "一部正解":
return "Amber - この問題は一部正解です。もう少し勉強をしましょう。"
else:
return "Red - この問題は間違っています。再度確認してみてください。"
⑥Amazon Bedrock側の準備
Amazon bedrockを使うためにはまずは申請が必要です。
申請方法については下記を参照しました。選択したAIモデルは「Claude」です。
Amazon BedrockでClaude 2のAPIを使う方法!使い方から実践まで
⑦Amazon Bedrock + Lamda + Amazon Kendraを結合する
下記の「RAGの動作確認」の章以降が参考になります。
Bedrock、Lambda、Kendra、S3を使用したRAGをSAMで実装してみた
※今回は個人で勉強をする目的で、システム自体を外部に公開するつもりはないため、セキュリティ面で甘い箇所があります。
また、そのまま放置しておくと従量課金制で課金される箇所がいくつかあるので、ご利用が終わればすぐに削除することをおすすめします。
検証結果
問題の出典元を上手く出すために、プロンプトを調整していたところ先に試験日が来てしまいました😅
よってそのままキャプチャを載せるとIPAの規約に引っ掛かるのでイラスト風に紹介します!
【実際に出来ること】

【したかったこと】

ちなみにChatGPTではこんな感じです。

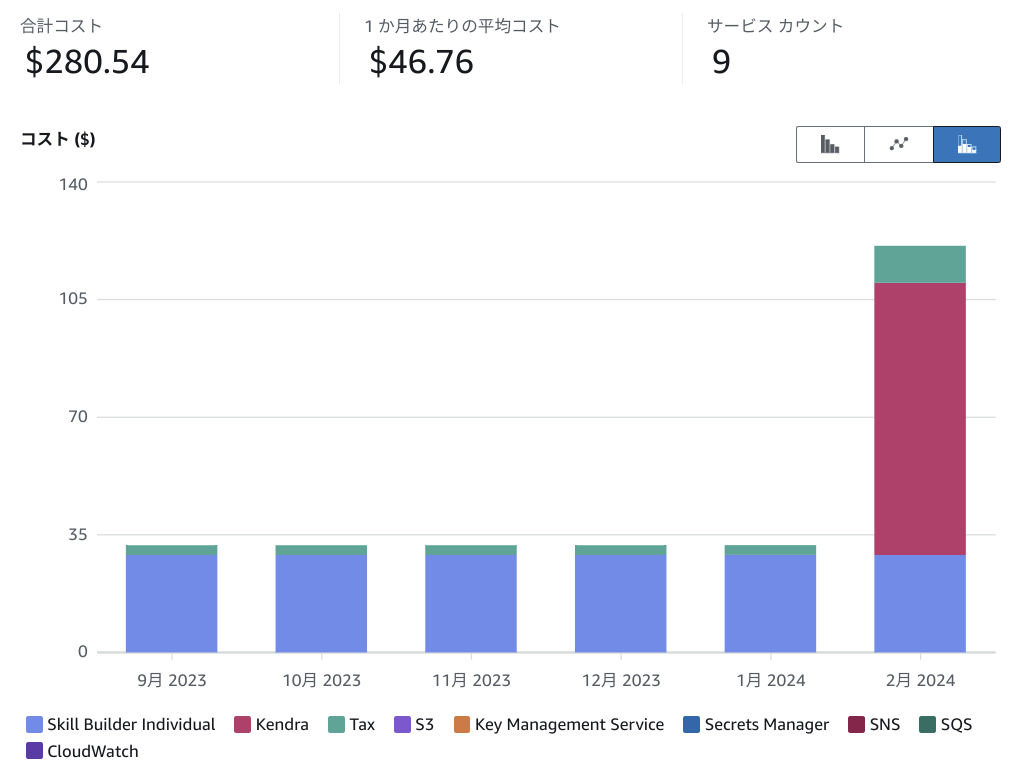
総費用
なお、勉強は後回しにしようという精神では、請求額が大変なことになります。(丸1ヶ月放置していました。)
くれぐれも、システム構築後はさっさと勉強を終わらせるようにしましょう。(BedrockとLamdaは次の月の請求になりますがほとんどかかってません。)
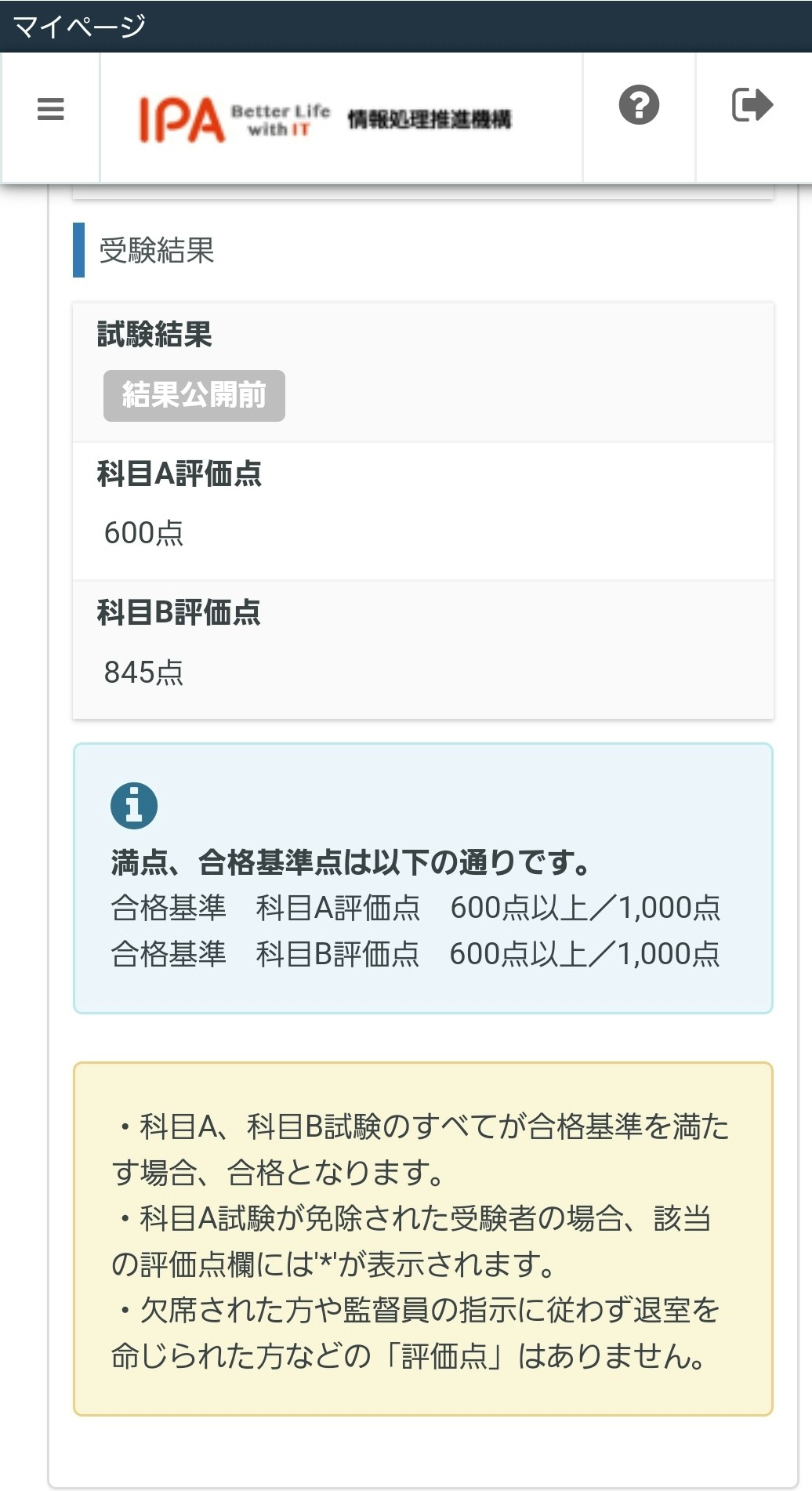
試験結果
どうにか無事に、、、笑
感覚的にはシステムを作ってる最中に覚えた知識だけで事足りたような感じです。
次回予告
応用情報技術者試験でこそ、完璧に皆さんに公開できるレベルのプロンプトを作って試験に臨みたいと思います!
(データソースを変えるだけで出来るように準備します。)
では!また10月に!