Ragasとは
Ragasは、RAG(Retrieval Augmented Generation) Assessmentの略で、LLMによりRAGパイプラインの評価をフレームワークです。
Ragasの評価指標
Ragasで提供されているMetrics(評価指標)についてまとめます(2023/11/24時点)。
以下リンクを参考にします。
最初にまとめとなる表を示します。
表1 各指標の評価対象、目的、及び、評価に使用する情報
| 指標 | 評価対象 | 目的 | 評価に使用する情報 |
|---|---|---|---|
| Faithfulness(忠実度) | 生成モジュール | 生成された回答が与えられたコンテクストから導けるかを評価します。 | 回答、コンテクスト |
| Answer Relevancy(回答の関連性) | 生成モジュール | 生成された回答が元の質問にどれだけ関連しているかを評価します。 | 回答、元の質問 |
| Context Recall(コンテクストの再現性) | 検索モジュール | 取得されたコンテクストがGround Truthにどれだけ関連しているかを測定します。 | コンテクスト、Ground Truth |
| Context Precision(コンテクストの精度) | 検索モジュール | 複数個の検索結果(コンテクスト)の中で、質問に関連する要素がどれだけ高くランクされているかを評価します。 | コンテクスト、質問 |
| Context Relevancy(コンテクストの関連性)(廃止予定) | 検索モジュール | 以前はコンテクストが質問にどれだけ関連しているかを評価していましたが、廃止予定です。 | コンテクスト、質問 |
| Answer Semantic Similarity(回答の意味的類似性) | パイプライン全体 | 生成された回答とGround Truthとの間の意味的類似性を評価します。 | 回答、Ground Truth |
| Answer Correctness(回答の正確性) | パイプライン全体 | 生成された回答の正確性を、与えられたコンテクストに裏付られる事実性と、Ground Truthとの類似性に基づいて評価します。 | 回答、コンテクスト、Ground Truth |
| Aspect Critique(アスペクト批評) | パイプライン全体? | 回答について、無害性や正しさなど指定された側面を評価します。 | 回答、指定された基準 |
評価指標は、計7つ提供されています。
- Faithfulnesss
- Answer relevancy
- Context recall
- Context precision
- Context relevancy (廃止予定であり、代わりにCpntext Precisionを利用することが推奨。)
- Answer semantic similarity
- Answer correctness
- Aspect Critique
図1を見るに、指標1. Faithfulnesss,2. Answer relevancyは、文章生成(generation)のモジュールの評価に、指標3. Context recall,4. Context precisionは文章検索(retrieval)のモジュールの評価に利用されています。
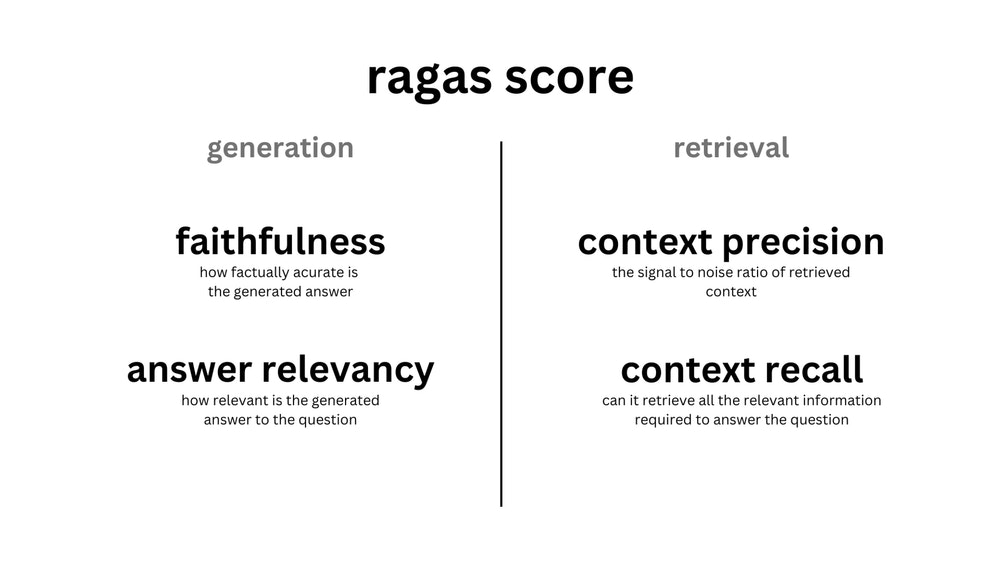
図1 評価指標の利用方法。
また、指標5. Context relevancyは、文章検索モジュールの評価に利用されていましたが、近い将来廃止されるようです。
そして、指標6. Answer semantic similarity,7. Answer correctness、8. Aspect Critiqueは、パイプラインの出力の評価に利用されています。
指標の中でも、1. Faithfulnesss、2. Answer relevancy、4. Context precision(Context relevancyの代わり)は、Ground Truth(正しい答え)がなくとも測定可能指標であることを、このライブラリを作成している方々の論文(RAGAS: Automated Evaluation of Retrieval Augmented Generation)でプッシュしていました。
各指標の詳細は、これから説明しますが、RAGのQA利用が前提の評価プロンプトを指標の計算に利用している場合が多いです。Retrievalでキーワードをqueryとして利用したり、取得したコンテクストから要約を生成する場合など、QAでないシステムの場合には、プロンプトを工夫する必要があると感じています。
各指標について、以下で説明していきます。
Faithfulness
用途:
生成された回答が、与えられたコンテクストから導けるか、定量的に評価することを目的としています。スコアは0から1の範囲で評価され、高いスコアはより一貫性のある回答を意味します。
スコアの計算方法:
①大規模言語モデル(LLM)により、生成された回答から一連の主張を特定します。
②LLMにより、それぞれの主張が与えられたコンテクストから推論できるかどうかを確認します。
③コンテクストから推論できる主張の数を、生成された回答に含まれる総主張数で割ります。この比率がFaithfulnessスコアとなります。
①生成された回答から一連の主張を特定するためのプロンプト
質問とその回答を受け取り、与えられた回答の各文から一つ以上の声明を作成してください。
質問: アルバート・アインシュタインは誰で、何で最もよく知られていますか?
回答: 彼はドイツ生まれの理論物理学者で、史上最も偉大で影響力のある物理学者の一人と広く認められています。彼は相対性理論の開発で最もよく知られており、量子力学の理論の発展にも重要な貢献をしました。
主張:\nアルバート・アインシュタインはドイツで生まれました。\nアルバート・アインシュタインは相対性理論で最もよく知られています。
質問: カドミウム塩化物はこの化学物質にわずかに溶けますが、それは何とも呼ばれていますか?
回答: アルコール
主張:\nカドミウム塩化物はアルコールにわずかに溶けます。
質問: シャフルとジティンは同じ国籍ですか?
回答: 彼らは異なる国の出身です。
主張:\nシャフルとジティンは異なる国の出身です。
質問:{question}
回答:{answer}
主張:\n
②それぞれの主張が与えられた文脈から推論できるか判断するためのプロンプト
プロンプト:自然言語推論
与えられた文脈と以下の声明を考慮し、それらが文脈に存在する情報によってサポートされているかどうかを判断してください。結論(はい/いいえ)に至る前に、各声明について簡単な説明を提供してください。指定された形式で最終的な結論を各声明ごとに提供してください。指定された形式から逸脱しないでください。
コンテクスト:
ジョンはXYZ大学の学生です。彼はコンピューターサイエンスの学位を取得しています。彼はこの学期、データ構造、アルゴリズム、データベース管理を含むいくつかのコースに登録しています。ジョンは勤勉な学生で、勉強や課題の完了にかなりの時間を費やしています。彼はしばしば図書館で遅くまでプロジェクトの作業をします。
主張:
1.ジョンは生物学を専攻している。
2.ジョンは人工知能のコースを受講している。
3.ジョンは献身的な学生である。
4.ジョンはアルバイトをしている。
5.ジョンはコンピュータープログラミングに興味がある。
回答:
1.ジョンは生物学を専攻している。
説明:ジョンの専攻は明示的にコンピューターサイエンスとして述べられています。彼が生物学を専攻しているという情報はありません。結論:いいえ。
2.ジョンは人工知能のコースを受講している。
説明:文脈はジョンが現在登録しているコースを言及しており、人工知能については言及されていません。したがって、ジョンがAIのコースを受講しているとは推測できません。結論:いいえ。
3.ジョンは献身的な学生である。
説明:プロンプトは、彼が勉強と課題の完了にかなりの時間を費やしていると述べています。さらに、彼はしばしば図書館で遅くまでプロジェクトの作業をするとも述べられており、これは献身的であることを示唆しています。結論:はい。
4.ジョンはアルバイトをしている。
説明:文脈ではジョンがアルバイトをしているという情報は提供されていません。したがって、ジョンがアルバイトをしているとは推測できません。結論:いいえ。
5.ジョンはコンピュータープログラミングに興味がある。
説明:文脈はジョンがコンピューターサイエンスの学位を取得していると述べており、これはコンピュータープログラミングへの興味を示唆しています。結論:はい。
最終的な結論(順番に):いいえ。いいえ。はい。いいえ。はい。
コンテクスト:{context}
主張:{statements}
回答:
Answer Relevancy
用途:
生成された回答が元の質問にどれだけ関連しているかを評価します。スコアは0から1の範囲で、高いスコアは回答の関連性が高いことを示します。このメトリクスでは、事実性は考慮されず、不完全な回答や冗長な情報を含む回答にはペナルティが課されます。
スコアの計算方法:
①LLMにより、生成された回答から質問を何パターンか復元します。
②これら復元した質問と元の質問との間で、コサイン類似度を測定し、復元した質問の全パターンについて平均値をとります。コサイン類似度は、回答が元の質問にどれだけ適切に対応しているかを示す指標です。生成された回答が初期の質問に正確に対応していれば、LLMは回答から元の質問と一致する質問を生成することができるはずです。
①生成された回答から質問を復元するためのプロンプト
与えられた回答に対して質問を生成してください。
回答:
PSLV-C56ミッションは、2023年7月30日日曜日の06:30 IST / 01:00 UTCに打ち上げられる予定です。これは、インドのアーンドラ・プラデーシュ州、スリハリコタのサティシュ・ダワン宇宙センターから打ち上げられます。
質問:PSLV-C56ミッションの予定されている打ち上げ日時と打ち上げ場所は何ですか?
回答:{回答}
質問:
Context Precision (執筆中)
用途:
複数個の検索結果(コンテクスト)の中で、質問に関連する要素がどれだけ高いランクにあるかを評価するメトリックです。スコアは0から1の範囲で、高いスコアは、関連する要素が上位にランクされていることを示します。
スコアの計算方法:(調査中)
①Precision@kを計算します。TP(true positives@k)を、TPとFP(false positives@k)の合計で割ります。ここで、kはcontexts内のチャンクの総数を指します。
②Context Precision@kを計算します。トップK結果内の関連する項目の総数で、precision@kの合計を割ります。
プロンプト
与えられたコンテクストにある情報が、設問に答える上で役に立つかどうかを確認する。
質問:
緑茶にはどのような健康効果がありますか。
コンテクスト:
この記事では、中国における茶栽培の豊かな歴史を探り、そのルーツを古代王朝までさかのぼります。さまざまな地域がどのように独自の茶の品種と抽出技術を発展させてきたかを論じている。また、中国社会におけるお茶の文化的意義や、お茶がどのようにもてなしやリラクゼーションの象徴となったかについても掘り下げている。
検証結果:
{"reason": "中国におけるお茶の歴史と文化的意義については有益であるが、緑茶の健康効果についての具体的な情報はない。したがって、健康効果に関する質問に答えるには役に立ちません。", "verdict": "No"}}
質問:
植物の光合成はどのように行われますか?
コンテクスト:
植物の光合成は、複数のステップを含む複雑なプロセスである。この論文では、葉緑体内のクロロフィルがどのように太陽光を吸収し、二酸化炭素と水をグルコースと酸素に変換する化学反応を促進するかについて詳しく説明する。明反応と暗反応の役割と、これらの過程でATPとNADPHがどのように生成されるかを説明する。
検証結果:
{{"reason": "This context is extremely relevant and useful for answering the question. 光合成のメカニズムを直接取り上げ、重要な構成要素とプロセスを説明しています。", "verdict": "Yes"}}
質問:{question}
コンテクスト:{context}
検証結果:
Context Recall
用途:
取得されたコンテクストがGround Truthにどの程度関連しているかを測定する指標です。スコアは0から1の範囲で、高い値はより良いパフォーマンスを示しています。
スコアの計算方法:
Ground TruthからContext Recallを推定するために、以下のプロセスを踏みます。
①Ground Truthの各文を分析し、それが取得されたコンテクストに帰属できるかどうかをLLMで判断します。
②Ground Truthの全文の数に対する、取得された文脈に帰属する文の数の比でスコアを計算します。理想的なシナリオでは、Ground Truthの全文が取得されたコンテクストに帰属するべきです。
①Ground Truthの各文を分析し、それが取得された文脈に帰属できるかどうかを判断するためのプロンプト
注:以下のプロンプトにおいて、回答はGround Truthを指しています。
与えられた文脈と回答に基づき、回答内の各文を分析し、その文が与えられた文脈に帰属するかどうかを分類してください。理由を含めたjsonで出力してください。
質問:アルバート・アインシュタインについて何が言えますか?
コンテクスト:アルバート・アインシュタイン(1879年3月14日 - 1955年4月18日)は、ドイツ生まれの理論物理学者で、史上最も偉大で影響力のある科学者の一人と広く認識されています。相対性理論を発展させたことで最もよく知られており、量子力学への重要な貢献も行い、20世紀初頭の科学的理解の革命的変革における中心人物でした。彼の質量とエネルギーの等価性の公式E=mc2は、相対性理論から生じ、"世界で最も有名な方程式"と呼ばれています。彼は1921年に物理学のノーベル賞を"理論物理学への貢献、特に光電効果の法則の発見"で受賞しました。量子理論の発展における重要なステップです。彼の仕事は科学哲学への影響でも知られています。1999年にイギリスの雑誌「Physics World」によって行われた130人の主要な物理学者による調査では、アインシュタインは史上最も偉大な物理学者にランクされました。彼の知的業績と独創性はアインシュタインを天才の代名詞にしました。
回答:アルバート・アインシュタインは1879年3月14日に生まれ、ドイツ生まれの理論物理学者で、史上最も偉大で影響力のある科学者の一人と広く認識されています。彼は1921年に物理学のノーベル賞を受賞しました。1905年に4つの論文を発表しました。1895年にスイスに移住しました。
分類:
[
{{ "statement_1": "Albert Einstein(アルベルト・アインシュタイン)は、1879年3月14日生まれのドイツ出身の理論物理学者、
"reason": "アインシュタインの生年月日は文脈の中で明確に言及されている"、
"Attributed": "はい"
}},
{{
"statement_2": "彼は1921年にノーベル物理学賞を受賞した、
"reason": "指定された文脈に正確な文が存在する"、
"Attributed": "はい"
}},
{{
"statement_3": "彼は1905年に4つの論文を発表した"、
"reason": "指定された文脈では、彼が書いた論文についての言及はない。"
"Attributed": "いいえ"
}},
{{
"statement_4": "アインシュタインは1895年にスイスに移住した"、
"reason": "与えられた文脈では、これを裏付ける証拠はない"、
"Attributed": "いいえ"
}}
]
質問:2020年ICCワールドカップを制したのは?
コンテクスト:2022年ICC男子T20ワールドカップを制したのは?
2022年10月16日から11月13日までオーストラリアで開催された2022年ICC男子T20ワールドカップは、第8回大会である。当初は2020年に予定されていたが、COVID-19の流行により延期された。イングランドが決勝でパキスタンを5ウィケット差で破り、2度目のICC男子T20ワールドカップ優勝を果たした。
回答:イングランド
分類:
[
{{
"statement_1": "イングランドは2022年ICC男子T20ワールドカップで優勝した"、
"reason": "文脈から、イングランドがパキスタンを破ってワールドカップを制したことは明らかである。"
"Attributed": "はい"
}}
]
質問:{question}
コンテクスト:{context}
回答:{answer}
分類:
Context Relevancy (廃止予定の指標)
注:この指標はもうすぐ廃止されるようです。代わりに、Context Precisionの使用が推奨されています。
The 'context_relevancy' metric is going to be deprecated soon! Please use the 'context_precision' metric instead. It is a drop-in replacement just a simple search and replace should work.
用途:
取得されたコンテクストのうち、質問の回答に必要なコンテクストがどの程度含まれているか評価する指標です。スコアは0から1の範囲で、高い値はより良い関連性を示します。
スコアの計算方法:
①取得されたコンテクストの中で、与えられた質問に回答するために必要な文の数をLLMで特定します。
②これらの関連する文の数を、取得された文脈内の総文数で割ります。
①取得されたコンテクストの中で、与えられた質問に回答するために必要な文の数を特定するためのプロンプト
提供された文脈から、次の質問に答えるために絶対に必要な関連文を抽出してください。関連する文が見つからない場合、または与えられた文脈から質問に答えることができないと考えられる場合は、「情報不足」というフレーズを返します。 候補文を抽出している間、与えられた文脈から文を変更することは許されません。
質問:{question}
コンテクスト:{context}
候補文:
Answer Semantic Similarity
用途:
生成された回答とGround Truthとの間の意味的類似性を評価することを目的としています。値は 0 から 1 の範囲にあり、スコアが高いほど、生成された回答とGround Truthとの間の整合性が高いことを意味します。
スコアの計算方法:
生成された回答とGround Truthからそれぞれの埋め込み表現を作成して内積を計算するか、もしくは、生成された回答とGround TruthをまとめてCross Encoderに投入しスコアを計算します。
Answer Correctness
用途:
生成された回答との正確性を評価する指標です。与えられたコンテクスト(事実)に基づいた回答であること、およびGround Truthと似ている回答であることを、高く評価します。値は 0 から 1 の範囲にあり、スコアが高いほど、生成された回答が正確であることを意味します。
スコアの計算方法:
Answer Semantic SimilarityとFaithfulnessの平均を取ります。
Aspect Critique
用途:
回答について、無害性や正しさといった一面を評価するための指標です。どういった一面を評価するか、ユーザが指定することもできます。スコアは0か1のどちらかで、1が高評価です。
スコアの計算方法:
①回答について、コンテキストを与えたうえで、基準(有害性、悪意、一貫性、正しさ、簡潔さ)を指定して、LLMで評価します。
②strictnessというパラメータで、評価の回数を指定でき、指定した回数文の評価(処理①)で多数決を取ります。
③答えが「はい」の場合、スコアを1、「いいえ」の場合、スコアを0とします。もし、答えが「はい」または「いいえ」でない場合、スコアを強制的に0にします。
①回答を批評するためのプロンプト
コンテキストと回答が与えられる。与えられた基準を用いて回答を評価しなさい。
ステップバイステップで根拠を示しながら考え、最後にYesかNoの評決を出すことで結論を導き出しなさい。
コンテキスト:ロスアラモス研究所の所長は誰ですか?
回答:アインシュタインはロスアラモス研究所の所長だった。
基準:アウトプットは完璧な文法で書かれているか
私の考えはこうだ:アウトプットが完璧な文法で書かれているかどうかが評価の基準である。この場合、アウトプットは文法的に正しい。よって、答えはYes。
コンテキスト:{input}
回答:{answer}
基準:{criteria}
私の考えはこうだ: