この記事は、「C3 Advent Calendar 2023」18日目の記事です。
目次
- プロローグ
- はじめてのオブジェクト指向言語
- オブジェクト指向を触って、改めてc言語と向き合って
- エピローグ
1. プロローグ
どうも、わんたんです。
大学に編入してから、はや8ヶ月となりました。大学生活にも慣れてきて、あとは就職(卒業)まで余生を謳歌する終活人間になりつつあります。あと、最近忙しかったり、入学時より人間関係がディープになってきてるのもあって、今年度初めほどいろんな場所や人に顔を出せていない状態が続いてます。あの人元気かな...とDiscordを眺める日々...。
さて、そんなことはまた別の機会に話すとして、今回は技術的な話をひとつ...
2. はじめてのオブジェクト指向言語
立てばカラオケ、座ればゲーム。歩く姿はGeoGuessr。カラオケやゲームは芍薬や牡丹ほど美しい趣味ではありませんが、ギャンブルとかタバコとかよりはマシな気がします。ところで、芍薬や百合にはちょっと不吉な花言葉があります。美しいものの代名詞にネガティブな花言葉が付いてるのってエモいですよね…。
さて、そんな僕も大学生になり、世界には春が訪れました。大学に入学し、C3に入部して、これからプログラミングするぞぉ~~とウッキウキで構えていた矢先、そいつは現れました。そう、アイツです。オブジェクト指向言語です。
実のところ、僕は高専時代、ずっと手続き型のプログラミングをしてきました。C言語とか...。Rubyも触ってはいましたが、オブジェクト指向的記述からは逃げてきました。理屈だけ知ってた、的なやつです。
ええ、知ってます。知ってますとも。世界のスタンダードは今やオブシコ。C言語で開発してる変態なんてそうそういません。高専時代はそんな現実から目を背けてきたのに、C3はもうどこを見渡してもオブシコ一色でした。死角がありません。
だいぶ大仰な出だしでした。まぁ、別に僕もオブシコを知らないわけではありません。コンストラクタがどうのこうのとか、外部クラスからのアクセスがどうのこうのとか...。今回は、そんな自分が対面して、実際に記述して、いろいろ思ったことを紹介します。
interfaceとかいう「意外とやるやつ」
まずこれです。まずは継承について、例えば自動販売機をイメージしましょう。自動販売機くんはプロトタイプで、とりあえず以下の機能を持っています。
- 販売額の設定(セッタ)
- 販売額の閲覧(ゲッタ)
このとき、自動販売機を使用するユーザは下記の2名になります。
- 購入者
- 販売者
さて、この2人が自動販売機を触るとしましょう。購入者クラスが自動販売機クラスを操作するとき、販売額設定メソッドを購入者クラスから隠したいです(もしこのまま実装すると、購入者は販売額を勝手に設定できてしまいます)。
じゃあ、メソッドをprivateにして、同一クラス外からの参照を許さない形にしましょう。
// 自販機のクラス
class VendingMachine {
private int value;
VendingMachine() {
this.value = 160;
}
public int getValue() {
return this.value;
}
private int setValue(int value) {
this.value = value;
}
}
class Buyer {
VendingMachine vendingMachine = new VendingMachine();
VendingMachine.setValue(100); // 参照不可
}
class Seller {
VendingMachine vendingMachine = new VendingMachine();
VendingMachine.setValue(200); // 参照不可
}
あれれ、privateで定義したせいで、自販機クラスの外である購入者クラスはもちろん、販売者クラスからもアクセスできなくなってしまいました...。だからといって、publicにすると購入者クラスから参照できてしまいます...。どうすればよいのでしょうか。
こんなとき、役に立つのがinterface機能です。あらかじめ購入者が利用してよいメソッドをinterface上に定義しておき、それを実装する形でどうでしょう。
// 自販機のクラス(interfaceの実装)
class VendingMachine implements BuyerPermission {
private int value;
VendingMachine() {
this.value = 160;
}
public int getValue() {
return this.value;
}
public void setValue(int value) {
this.value = value;
}
}
// 購入者用interface
interface BuyerPermission {
public int getValue();
}
// メイン
class Buyer {
private int value = 100;
private BuyerPermission vendingMachine = new VendingMachine();
public void showValue() {
vendingMachine.setValue(value); // 参照できない
value = vendingMachine.getValue(); // 160が返ってくる
System.out.print(value);
}
}
class Seller {
private int value = 200;
private VendingMachine vendingMachine = new VendingMachine();
public void showValue() {
vendingMachine.setValue(value); // 参照可能
value = vendingMachine.getValue(); // 参照可能(200が返ってくる)
System.out.print(value);
}
}
// サンプルとしてのソースコードが複雑になることを防ぐため、自販機のインスタンスをそれぞれ作成しています(趣旨とは異なるので)。
上のコードでは、interfaceにsetValue()についての記述がされていないため、interfaceに依存している購入者クラスからsetValue()の存在を認識することができません。interfaceという名前通り、購入者が利用できるインタフェースのみ残してくれました。すごい!オブシコすごい!
と、このように、カプセル化を貫くオブシコでは、とにかく参照していい場所、してはいけない場所などが明確に示されるようになっています。僕自身、オブシコのアクセサは基本的にprivate/publicなどで指定されるものだと考えていたので、こういった方法もあることに驚きました。
当然のようで当然じゃない「多態性」
多態性、つまりポリモフィズムについても、例えば以下のように、オブジェクト指向では複数の同一名メソッドを宣言できます(引数が違う必要があります)。
class Addition {
public int add(int a, int b) {
return a + b;
}
public double add(double a, double b) {
return a + b;
}
}
こういったものは、ポリモフィズムを実現する方法の1つとして「オーバーロード」と呼ばれています。
引数が違う、また戻り値が違うような複数の同一名メソッドを作成できるのは、C言語ヘビーユーザからするとマジで神です。C言語なら、メソッド名を一意にする必要があるので。。一応、引数から実行関数を指定したり処理を分岐させたりする方法はあるにはあるんですが、いかんせんオープン・クローズドではないので、やっぱり簡単に処理分岐を追加できるのはいいですね。
C++とかJSだと、メソッドの引数についてはまた別の書き方ができて楽なんですけどね...。これをポリモフィズムと置くかはおいといて...。
void cry(const char* animal, const char* sound = "Hogehoge") {
cout << animal << " crying " << sound;
}
int main(void) {
cry("A dog", "bowwow");// どちらでも動く
cry("A human"); // どちらでも動く
}
引数が1つや2つ違うときに、このC++のデフォルト引数機能(勝手にそう呼んでる)はすごく重宝します。引数が異なるメソッドを何個も書く必要がないので...。
例として、C++のDxLibでは、字体のハンドラーを作成する関数を以下のように定義しています(DxLib質問ページより引用)。
int CreateFontToHandle(
const TCHAR *FontName,
int Size,
int Thick,
int FontType = -1 ,
int CharSet = -1 ,
int EdgeSize = -1 ,
int Italic = FALSE ,
int Handle = -1
) ;
上記の関数では、イタリックやエッジサイズ(縁の太さ)などを設定する引数が、わざわざ関数を呼ぶ際に指定しなくとも勝手に初期化されます。javaのように引数の数で関数を分けても良いですが、冗長なコードがかなり発生してしまいますね。
このように、オブジェクト指向的プログラミングでは、複数人体制でシステムを開発する際に有用となる機能が多数存在しています。事実、C言語では、例えばコードの一部を外部委託をする際など、利用されてはいけないような関数は物理的に見えないようにする必要があります(それはオブシコでも結局同じかもしれませんが。C言語では変数や関数のアクセサを言語的に実装することが難しいため、それらは外部の取り決めや約束事、あるいはディレクトリ構造によって指定される必要があります)。逆に言えば、とあるまとまり(オブジェクト指向であればクラスなど)と別のリソースとの参照や依存関係について、オブジェクト指向であれば、ある程度はソースコードで明示することができます。
3. オブジェクト指向を触って、改めてc言語と向き合って
前提として、GoやRustといった「オブジェクト指向言語っぽい」言語もまとめて大きくオブジェクト指向言語としてくくらせていただきます。
Cとオブジェクト指向、どっちがいい?
さて、ここまでずっとオブジェクト指向の話をしてきました。そろそろC言語の話もしましょうか。
C言語とオブジェクト指向言語でシステム開発をするとき、やはり書きやすいのはオブジェクト指向言語でしょう。それもそのはず、そもそもオブジェクト指向は、現代に存在するたくさんのシステムの根本的な設計理論に寄り添っています。ハードウェアあるいはソフトウェアの進化に応じて巨大化するシステムに対して、C言語での設計では工数的にも限界が来る、というのは当然の話です。
しかし、オブジェクト指向がC言語などの非オブジェクト指向言語に対する上位互換であるかと言われれば、答えはNOです。その理由として広く一般的に挙げられるのはやはり「実行速度」や「実行環境の非依存」など処理系に基づく視点からであることが多いですが、これらは学生(が開発するレベルのシステム)にとってそこまで重要な視点ではありません。
学生にとって、C言語を記述する、あるいは理解する一番大きなメリットは「体感的にハードウェア動作の理解ができる点」だと思います。
C言語とハードウェア
よく言われることがあります。「C言語を勉強すれば、他の言語が身に付きやすい」。これは、全部が全部真実ってわけでもありません。
まずもって、普通に考えて、今普及しているプログラミング言語はほとんどオブジェクト指向言語です。対してC言語はそのうちの数少ない例外です。C言語を学んだとて、その知識が直接オブジェクト指向言語の理解につながるかと言われれば、そんなことはないと思います。むしろ、これまでC言語しか書いたことない人と、この前までjava書いてた人がいたとき、同時に別のオブジェクト指向言語を学び始めたとしたら、理解が早いのは後者だと思います。
じゃあ、C言語は学ぶ価値がない言語なのかと言われれば、そうではないです。C言語を一言で表すと、「ハードウェアに寄り添う言語」です。
C言語でコードを書くとき、その不自由さに驚くと思います。代入演算子を用いた、文字列の直接的な再代入ができないこと(ここでいう「文字列」とは、char型の配列を指します)。constで宣言した変数を配列宣言時の要素数として指定できないこと。何故か標準入力関数にscanfとscanf_sがあり、少し文法が異なること。などなど、挙げていくとキリがありません。しかし、これらの裏には全て「ハードウェアシステムの都合」という理由が詰まっているのです。
配列とポインタは一緒じゃないし、C言語の配列は「配列」じゃない
例えば、代入演算子を用いた文字列への再代入ができないこと。これは、C言語における配列の仕組みそのものが原因です。具体的には、変数名がその中身でなく、メモリ上の座標しか示さないからです(いわゆる「ポインタ」)。C言語では、配列は宣言時に必要分だけメモリを確保するだけなので、どのくらいメモリを確保したかという情報が変数に紐づけて記録されることはありません。例えば、以下のコードです。
int main(void) {
char str[6] = "aiueo";
// char str2[6] = str; // 実行不可
char* str_p = str; // ポインタに配列を代入
printf("%s %zu\n", str, sizeof(str));
printf("%s %zu\n", str_p, sizeof(str_p));
}
aiueo 6
aiueo 8
ソースコード2行目で文字列"aiueo"が登場し(文字列リテラルといいます)、配列strに代入されました。このとき、実行用に確保されたメモリのうち「静的領域」と呼ばれる場所にまず文字列リテラルが格納され、「スタック」領域にその値がコピーされます。変数strはこの「スタック」に存在する文字列の先頭アドレスが格納されている、という感じです。
ちなみに、先ほどC言語の配列はどのくらいメモリを確保したかという情報が変数に紐づいて記録されることはない、と言いました。「じゃあsizeof演算子はなんなんだ!サイズ分かるじゃねぇか!」と言われる方もおられるかもしれませんが、実はsizeof演算子はコンパイル時に引数を基に判断して整数定数に変換されているので、その行を実行するたびに演算が行われるわけではありません(じゃあなんで演算子って名前なんだよ)。 C90までの仕様です。厳密には、(C99以降は)引数に可変長配列を指定した場合のみプログラム実行時に値が決定します。ちなみに、strはスタックにコピーされた文字列長の6が返されますが、str_pはポインタなので8が返されます。sizeofの話だけで割と1記事書けるくらい直感と異なる動作があるので詳しくは割愛しますが、文字列長を取得したいのであればstrlen()が無難でしょう。
constで宣言した変数が配列宣言時の要素数として使用できないのも、コンパイル段階でその値が確定しないからです。Cにおける配列とは、「メモリ空間上の連続したデータの羅列」に過ぎません。事実、それ以上でも以下でもないのです。だから、配列で定義外の要素数を参照してもそれ専用のエラーを返したりしてくれないし、データを挿入して要素数を増やそうなんてこともできたりしないし、配列のある要素を指すポインタに+1(あるいは+n)すると結果的に次の要素が得られたりするわけです。他言語の便利で快適な配列に比べれば、C言語の配列なんて「それっぽい何か」にしか見えませんね(C言語の配列が原初に近いことに変わりはないですが。技術的イノベーションにより、世間一般のスタンダードが変わってしまった結果、概念としてのそれすらシフトしてしまうことはよくあります。Array型がもはや配列ではなくリストそのものを指している言語は少なからずありますからね(Rubyなど。Rubyに至ってはもはや双方向リストどころかトポロジーに近い構造をしていますが))。
直感性を犠牲に実行速度を手に入れたマクロ
defineなどで定義されるマクロはコンパイル前にソースコードが置換されるので(プリプロセッサ)、配列の要素数として問題なく使用することができます。つまり、マクロ関数は一般的な関数と異なり、関数を呼び出してその戻り値を受け取る形ではないため、記述する際には注意が必要です(直感的に僕らが想像する関数と違くて違和感ありますよね)。よって、以下のようなマクロ関数を定義する際は予期しない挙動を発生させる可能性があります。
#define TWICE(x) x+x // 任意の数xを2倍するマクロ(のつもり)
int main(void) {
printf("%d", 2 * TWICE(3));
}
上のコードでは、「3を2倍したものに2をかける」ことをしようとしています。つまり、理想の出力値は12です。しかし、いざ実行してみるとこうなります。
9
これは、コンパイル時に以下のようにコードが置換されるからです。
#define TWICE(x) x+x // 任意の数xを2倍するマクロ(のつもり)
int main(void) {
printf("%d", 2 * 3+3);
}
演算子には優先順位があるため、2*3が先に計算され、結果的に9が出力されてしまうわけです。これを防ぐために、以下のように演算の優先順位をきちんと示してやる必要があります。
#define TWICE(x) ((x)+(x)) // 任意の数xを2倍するマクロ
int main(void) {
printf("%d", 2 * TWICE(3));
}
ちなみに、マクロも相当奥が深いです。もちろん割愛します。
これまで挙げてきた「予想しない不具合とその解決策」の例は、全てCのコンパイラに起因するものです。C言語は元々「メモリサイズが小さくても利用できる」言語であるため、その点ではユーザからハードウェア的動作をできるだけ隠さない方が都合がよく、言わばこれらは「極めて単純で機械的な動作」であり、腑に落ちやすいと言えます。
C言語を記述するうえで「なんでこんな記法なんだろう」「なんでこういう挙動なんだろう」ということがあれば、ネットで調べたり、実際にコードを書いて動作を確かめたりしてみてください。そのほとんどは、ハードウェア的原因に起因しているはずです。
オブジェクト指向はどうなのか
では、対してオブジェクト指向言語はどうなのでしょうか。これまで散々C言語について話してきましたが、オブジェクト指向言語の記法とハードウェアはどう関係しているのでしょうか。
例として、javaを挙げることにしましょう。javaはC言語ライクな言語であり、記法が似ています。よって、javaの記法をC言語的に解釈するのは、あまり難しい話ではありません。
例えば、javaにはLinkedListと呼ばれるクラスが存在します。以下に記述例を示します。
class A {
List<String> list = new LinkedList<String>(Arrays.asList("Apple", "Grape", "Orange"));
void func() {
System.out.println("==== 1回目の出力 ====");
for (String fruit : list) {
System.out.println(fruit);
}
// リストに要素を追加する
list.add("Kiwi"); // 末尾にキウイを追加
list.add(1, "Pineapple"); // インデックス1の位置にパイナップルを挿入
System.out.println("==== 2回目の出力 ====");
for (String fruit : list) {
System.out.println(fruit);
}
}
}
実際にfuncメソッドを実行すると、以下のようになります。
==== 1回目の出力 ====
Apple
Grape
Orange
==== 2回目の出力 ====
Apple
Pineapple
Grape
Orange
Kiwi
これは、内部的には双方向リストによって実現されています。つまり、単純に要素を追加しているように見えても、実際には以下のような処理をしています。
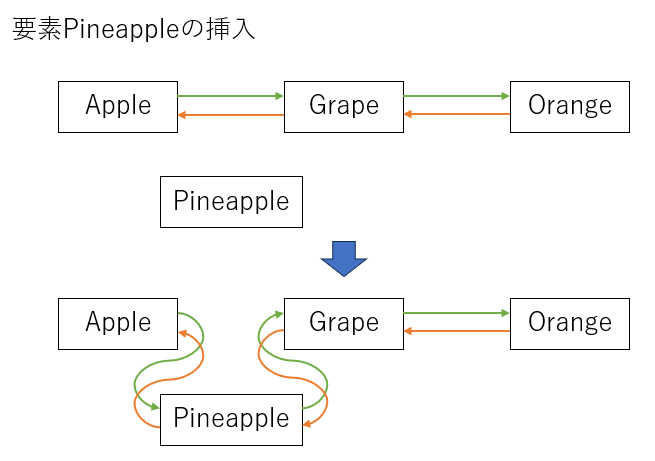
上図における、AppleやGrapeなどのことを「ノード」といいます。双方向リストでは、自分の前後に存在するノードの場所をお互いに保持しており、この情報を繋ぎ変えることで、配列では難しい「要素の挿入」を可能にしています。配列では宣言時にコンスタントにメモリを確保してしまうため要素の追加が難しいのですが、リストでは必要なメモリを都度確保してその座標を保存するため、こういった特殊な挙動が可能になります。
一見簡単そうに見えますが、この繋ぎ変え作業をC++で実装すると以下のようになります(C言語はオブジェクト指向ではないので、javaのlistのようなものを作成するためにオブジェクト指向の力を借りる必要がありました。邪道かもしれませんが許してください)。
#include<iostream>
using namespace std;
class Node {
public:
string name;
Node* prev = NULL;
Node* next = NULL;
};
class LinkedList {
private:
Node* head;
Node* tail;
Node* recorded_node;
int index;
void delete_list(Node* node) {
delete node->next;
if (node->prev == NULL) {
return;
}
node = node->prev;
this->delete_list(node);
}
public:
LinkedList() { // コンストラクタ(まずここが実行)
this->head = new Node();
this->tail = new Node();
this->recorded_node = NULL;
this->head->next = tail;
this->tail->prev = head;
this->index = 0;
}
~LinkedList() { // デストラクタ(クラスを消すときに実行)
Node* delete_node = tail->prev->prev;
this->delete_list(delete_node);
}
Node* get(const int dest_index, Node* node = NULL) { // 本当に便利なデフォルト引数くん
if (node == NULL) {
if (recorded_node == NULL) {
node = this->head->next;
this->index = 0;
}
else {
node = recorded_node;
}
}
if (dest_index == this->index || node == NULL) { // 目的のnodeであれば終了
return node;
}
if ((dest_index < this->index && node->prev == NULL) ||
(dest_index > this->index && node->next == NULL)) { // 範囲外の参照でNULLを返す
return NULL;
}
if (dest_index < this->index) {
index--;
node = this->get(dest_index, node->prev);
}
else if (dest_index > this->index) {
index++;
node = this->get(dest_index, node->next);
}
return node;
}
void add(const string add_data) { // 末尾にデータを追加
Node* add_node = new Node();
add_node->name = add_data;
tail->prev->next = add_node;
add_node->prev = tail->prev;
add_node->next = tail;
tail->prev = add_node;
}
void insert(const int dest_index, const string insert_data) { // 指定位置にデータを挿入
Node* insert_node = new Node();
Node* dest_node = new Node();
insert_node->name = insert_data;
dest_node = this->get(dest_index);
// リンクの付け替え
if (dest_index != 0) {
insert_node->prev = dest_node->prev;
dest_node->prev->next = insert_node;
}
dest_node->prev = insert_node;
insert_node->next = dest_node;
}
void show(Node* node = NULL) {
if (node == NULL) {
node = head->next;
}
if (node->next == NULL) { // tailノードであれば終了
return;
}
cout << node->name << "\n";
show(node->next);
}
};
int main(void) {
LinkedList list;
list.add("Apple");
list.add("Grape");
list.add("Orange");
list.show();
cout << "\n";
list.insert(1, "Pineapple");
list.show();
return 0;
}
Apple
Grape
Orange
Apple
Pineapple
Grape
Orange
このようになります(このクラスでは、前回参照したノードの位置をインデックスで保存しています。これは、双方向リストの利点を活用し、演算回数をなるべく削減するためです(保存しているノードが1つなので、実際どこまで早くなっているかは疑問ですが)。if文がある分1回あたりの実行速度は落ちますが、メモリにも参照の局所性とかあるので、ノード数が増えれば増えるだけ相対的な実行回数は少なくなるんじゃないかなと勝手に思っております)。
なお、上記のコードはC++で記述されているので、少し簡単になっています。リストをC言語で表現する場合は、ざっくりと以下のような記述をする必要があります(以下は、単方向リストで利用される関数の例の一部です)。
// リスト用構造体
typedef struct Fruit_t {
char name[10];
struct Fruit_t* next = NULL;
}list_t;
// 任意の地点にあるデータを返す関数
// headから目的のデータまでの距離を変数distanceで示し、距離0を目的データとして返す
list_t* getNodeWithIndex(int distance, const list_t* start_node) {
list_t* node = start_node;
// 目的のnodeに着いたら終了
if (distance == 0) {
return node;
}
node = getNodeWithIndex(--distance, node->next);
return node;
}
// ノードを作成する関数
list_t* createNode() {
list_t* new_node;
new_node = (list_t*)malloc(sizeof(list_t));
return new_node;
}
ざっくりと挙動が分かればいいので、例外処理などはしていません。
ポインタが多用されているのが分かると思います。C言語の構造体は基本的に参照渡しをすべきという話はそもそもありますが、卵が先か鵜が先か、線形リストを作成する際はポインタを利用するのが楽なのです(それとこれとは話が違う気がするね)。
このコードを見ると、線形リストがハードウェア的に果たしてどう動いているのかを知ることができます。逆に言えば、このコードは(丸暗記していない限りは)線形リストがハードウェア的にどういった挙動をしているのか理解していないと記述することができません。JavaやC++のコードと比較してもらうとわかる通り、こういった言語ではハードウェア的な処理はなるべく隠されるような記述ルールが用意されています。つまり、私たちがJavaを使用する際も、実はそう感じていないだけで、ポインタを多用しているのです。
せっかくなので例を挙げておきましょう。以下は、Javaの参照型である「String型」の例です。
class Test {
public static void main(String[] args) {
String str1 = "あああ";
String str2 = "あああ";
String str3 = "ああ";
str3 += "あ";
System.out.println("str1:" + str1);
System.out.println("str2:" + str2);
System.out.println("str3:" + str3);
System.out.println("str1 == str2は" + (str1==str2?"真":"偽") + "だよ!");
System.out.println("str1 == str3は" + (str1==str3?"真":"偽") + "だよ!");
System.out.println("st1.equals(str3)は" + (str1.equals(str3)?"真":"偽") + "だよ!");
str3 = str1;
str3 = "いいい";
System.out.println("str3:" + str3);
System.out.println("str1 == str3は" + (str1==str3?"真":"偽") + "だよ!");
}
}
str1:あああ
str2:あああ
str3:あああ
str1 == str2は真だよ!
str1 == str3は偽だよ!
st1.equals(str3)は真だよ!
str3:いいい
str1 == str3は偽だよ!
str1とstr3が持つ文字列の見た目は結果的に同じですが、参照先の文字列リテラルが異なるため==演算子は真を返しません。str1とstr2であれば、指し示す文字列リテラルが同一であるので、==演算子は真を返します。だからといってポインタ型ではなく、str3にstr1を代入した後(同じ文字列リテラルを指し示すようにする)、str3に異なる文字列リテラルを代入するとstr3の参照先が自動的に切り替わり、str1とstr3の指す文字列リテラルは異なるものとなります(つまり、C言語における参照渡しのように、変数の中身そのものが書き換えられる処理ではなく、新たにヒープ(コンスタントプール)に文字列リテラルが追加された後、そこを参照するように変数が変更されます。実際には、ここで対象の文字列リテラルが既に存在するかチェックするフェーズがあります)。本来=演算子は「代入」を指し示す演算子なのですが、やっていることは(ハードウェア的には)単純な代入とは少し違っていて気持ち悪いですよね。
この機能は、ガベージコレクションと呼ばれ、メモリリークを回避するための重要な考え方の一つに基づくものです。この機能がないC言語では、メモリリークに気を付けなければなりません。
まとめ:C言語を理解しよう
だいぶ話が脱線しましたね。ここまで読んでくださっている方(いるかな)、ありがとうございます。さて、結論から言うと、C言語をしっかり理解しましょう。たしかにC言語を理解していなくてもコードは記述できますが、見える世界が違います。断然楽しいです。僕も単方向リストのアルゴリズムを作りながら、「各ノードで目的地までの距離を-1して同じ関数を実行するなんて、tracerouteみたいでおもしろいなぁ」なんて考えてました(なんの話だよ)。まぁtracerouteは似てるだけで全然違いますけどね。僕が大好きなネットワークの話が始まるとここじゃ書ききれないのでそろそろやめます。
C言語を理解して、アルゴリズムをハードウェア的に理解できるようになりましょう!そしてハードウェア的に説明すれば、きっとみんなから「キモッ」って思ってもらえます。エンジニアにとってキモいは誉め言葉です。みんなでキモキモエンジニアを目指しましょう!
4. エピローグ
もうちょっといろいろ書こうかなって思ってたんですけど(最近の趣味の話とか、C3入部して思ったこととか)、思いのほか分量がすんごいことになってしまっているので、この辺で切り上げます。とりあえず最後に言うとすれば、NETFLIXで独占配信されてる『今際の国のアリス』の実写化、めちゃんこ面白かったです。いわゆるデスゲーム系作品とは一線を画す内容でした。まじでこれ観るためだけにネトフリ契約するのもいいんじゃないかなって思うくらいには面白かったのでぜひみてね!