分析に至った背景
以前から自然言語処理で何か面白いことをしたいと思ってはいたものの、手をつけないまま何か月も過ごしていました。しかし!!!今年のGWは奇跡の10連休です。思い切って何かに挑戦してみようと思い、自分の好きなアーティストであるaikoの歌詞を分析することにしました。
また、Qiita投稿などのアウトプットを怠っていることに最近危機感を覚えていたので、今回Qiitaに投稿してみます。
注意事項
- 筆者は機械学習や自然言語処理については初心者です。何かご意見・ご指摘ありましたらコメントをお願いします。
- 当記事では技術的に深い話はしていません。ご容赦ください。
この記事で言及すること
- MeCab・word2vecの使用例(ソースコード)
- 歌詞の分析結果
この記事で言及しないこと
- MeCab・word2vecの仕組み
- スクレイピングの手法や仕組みの詳細
著作物の収集と分析に関して
当記事で言及している歌詞データの収集および分析については著作権法47条の5に照らし合わせ、著作権法上問題ないものと判断します(同条2号の情報解析およびその結果の提供に該当と判断)。
問題定義
歌詞を分析するといってもどういう観点で分析すればいいのでしょうか。
いろいろと考えた結果、aikoの楽曲の歌詞に頻繁に出てくる**"あなた"や"あたし"という言葉の意味を明らかにするというアイデアが思いつきました。次いで、曲を書くアーティストたちも年齢によって恋愛や愛に対する思いが変化し、その変化が歌詞に現れるのではないか、という仮説**が思いつきました。
分析対象となるデータ量も少ないので毎年の変化を分析するのは現実的とは言えなさそうです。そこで今回は分析対象を以下の二つにしてみました。
①20代までのaikoの楽曲(104曲)
②30代以降のaikoの楽曲(94曲)
今回の分析では、"あなた"や"あたし"という分析対象の語句に対して類似度の高い語句を算出することで、分析対象となった語句自体の意味を考察していこうと思います。
分析の大きな流れとしては以下の3ステップとなります。
具体的な手段としては、1はWebスクレイピング、2はMeCab、そして3はword2vecを使用します。
- 歌詞データの収集
- 歌詞データの前処理
- 歌詞データの分析
Scrapyによる歌詞データのスクレイピング
分析の下準備として、歌詞検索サイトからaikoの楽曲200曲をスクレイピングしました。
スクレイピングの対象は、インディーズ時代の楽曲からアルバム『May Dream』に含まれる楽曲までです。年でいうと1996年から2016年までですね。(ちなみに発表年は1曲1曲ネットで調べて手入力しました。。。)
前述の通りスクレイピングについて詳しく言及しませんが簡単にまとめると、Scrapyを使用してHTML内の歌詞を保持しているタグを指定(XPath)し、1曲ごとにスクレイピングするように実装しました。
Scrapy含めスクレイピングの基礎知識・手法については以下の書籍が非常に参考になりました。おすすめです。
Pythonクローリング&スクレイピング -データ収集・解析のための実践開発ガイド-
MeCabによる形態素解析・分かち書き
word2vecで歌詞を分析するにあたり、インプットとなるデータ(歌詞)を「分かち書き」された状態にする必要があります。今回、その実現のためにオープンソースの形態素解析エンジンであるMeCabを使用しました。
http://taku910.github.io/mecab/
今回はMeCabで形態素解析を実行し、名詞・形容詞・副詞のみを抽出し、その語句をlistに格納してword2vecに渡しました。
寄り道 - 用語の確認
分かち書きとは
文を書く時、ある単位ごとに区切って、その間に空白を置くこと。また、その書き方。
コトバンク - 分かち書き
形態素解析とは
形態素解析とは、言語学においてある言葉が変化・活用しない部分を最小単位の「素」と捉え、その素ごとに言葉を分解してゆく手法のことである。
weblio辞書 - 形態素解析
形態素解析と分かち書きの具体例
実践ドメイン駆動設計。エリック・エヴァンスが確立した理論を実際の設計に応用する。
(略)
['エリック・エヴァンス', '名詞', '一般', '*', '*', '*', '*', '*']
['が', '助詞', '格助詞', '一般', '*', '*', '*', 'が', 'ガ', 'ガ']
['確立', '名詞', 'サ変接続', '*', '*', '*', '*', '確立', 'カクリツ', 'カクリツ']
['し', '動詞', '自立', '*', '*', 'サ変・スル', '連用形', 'する', 'シ', 'シ']
['た', '助動詞', '*', '*', '*', '特殊・タ', '基本形', 'た', 'タ', 'タ']
['理論', '名詞', '一般', '*', '*', '*', '*', '理論', 'リロン', 'リロン']
['を', '助詞', '格助詞', '一般', '*', '*', '*', 'を', 'ヲ', 'ヲ']
['実際', '副詞', '助詞類接続', '*', '*', '*', '*', '実際', 'ジッサイ', 'ジッサイ']
['の', '助詞', '連体化', '*', '*', '*', '*', 'の', 'ノ', 'ノ']
(略)
実践 ドメイン 駆動 設計 。 エリック・エヴァンス が 確立 し た 理論 を 実際 の 設計 に 応用する 。
word2vecによる単語のベクトル化
word2vecとは、テキストデータを学習して単語の意味をベクトルとして表現するライブラリのことです。ある単語に類似した単語を算出したり、単語同士の加算・減算が可能です。
自分の言葉で説明しようとすると10時間くらいかかりそうなので以下のサイトを見て理解してみてください。
絵で理解するWord2vecの仕組み
実際にやってみた
実際に動作させたソースコードを以下に示します(import~word2vecのモデル生成)。記録を残しつつ対話的に実行したかったこともあり、実際はJupyter Notebookで動かしました。
# 必要なライブラリのインポート
import sys
import re
import MeCab
import psycopg2
import pandas as pd
import matplotlib.pyplot as plt
from gensim.models import word2vec
# 楽曲テーブルへの接続
POSTGRESQL_URL = 'postgresql://postgres:(パスワード)localhost:5432/(スキーマ)'
conn = psycopg2.connect(POSTGRESQL_URL)
# 歌詞データの取得
COL_TITLE = 0
COL_LYRICS = 1
COL_YEAR = 2
song_list = []
sql_str = "SELECT title, lyrics, made_in FROM songs WHERE words_by IN ('aiko', 'AIKO')"
curs = conn.cursor()
curs.execute(sql_str, )
song_list = curs.fetchall()
IDX_WORD = 0
IDX_POS = 1
TARGET_YEAR = 2005
TARGET_POS_LIST = ['名詞', '形容詞', '副詞']
EXCEPTIONAL_SONG_LIST = ['相合傘(汗かきMix)'] # 重複削除のため
EXCEPTIONAL_LIST = ['・', 'さ', 'ん', 'の', 'ら', 'よ', '°', 'そう', 'よう', 'ない', 'それ', 'あれ', 'これ'
, 'ここ', 'そこ', 'はず', '人', '何', '事', '様', '話', '日', '目', '度', '時', '今']
analyzed_young_list = []
analyzed_old_list = []
analyzed_list = []
# 形態素解析用のインスタンス生成
tagger = MeCab.Tagger()
tagger.parse('')
for song in song_list:
# 重複する曲は除外
if song[COL_TITLE] in EXCEPTIONAL_SONG_LIST:
continue
# 形態素解析の実行
parsed_item = tagger.parse(song[COL_LYRICS])
# 1曲ごとにデータ整形
lines = parsed_item.split('\n')
items = (re.split('[\t,]', line) for line in lines)
for item in items:
# 不要データは除外
if len(item) <= IDX_POS:
continue
# 対象品詞以外は除外
if not item[IDX_POS] in TARGET_POS_LIST:
continue
# 半角記号の除去
if re.match(r"[a-zA-z!-/:-@[-`{-~]", item[IDX_WORD]):
continue
# 不要語句の除去(記号など)
if item[IDX_WORD] in EXCEPTIONAL_LIST:
continue
# 数値の除去
if item[IDX_WORD].isnumeric():
continue
if song[COL_YEAR] <= TARGET_YEAR:
analyzed_young_list.append(item[IDX_WORD])
else:
analyzed_old_list.append(item[IDX_WORD])
analyzed_list.append(item[IDX_WORD])
# word2vecのモデルを定義 ~20代の歌詞
model_young = word2vec.Word2Vec([analyzed_young_list], size=500, min_count=2, window=7, iter=1000, seed=2019)
# word2vecのモデルを定義 30代~の歌詞
model_old = word2vec.Word2Vec([analyzed_old_list], size=500, min_count=2, window=7, iter=1000, seed=2019)
# word2vecのモデルを定義 all
model = word2vec.Word2Vec([analyzed_list], size=500, min_count=2, window=7, iter=1000, seed=2019)
# 定数定義
PDCOL_WORD = '語句'
PDCOL_SIMILARITY = '類似度'
HEADER_YOUNG = "[~20代]"
HEADER_OLD = "[30代~]"
# 以降で分析実行
分析結果
さて... 分析結果を発表していきたいと思います。
ちなみに、分析結果と言っているのは分析対象の語句(ダブルクォーテーションで括っています)に類似した語句を類似度が高い順に示した表のことですので、その認識で確認してみてください。
20代以前と30代以降の比較結果
aikoにとっての"あなた"
分析処理
KEYWORD = 'あなた'
result_young = model_young.wv.most_similar(positive=KEYWORD, topn=10)
df_young = pd.DataFrame(result_young, columns=[HEADER_YOUNG + PDCOL_WORD, PDCOL_SIMILARITY])
df_young.index = df_young.index + 1
result_old = model_old.wv.most_similar(positive=KEYWORD, topn=10)
df_old = pd.DataFrame(result_old, columns=[HEADER_OLD + PDCOL_WORD, PDCOL_SIMILARITY])
df_old.index = df_old.index + 1
display(pd.concat([df_young, df_old], axis=1))
分析結果
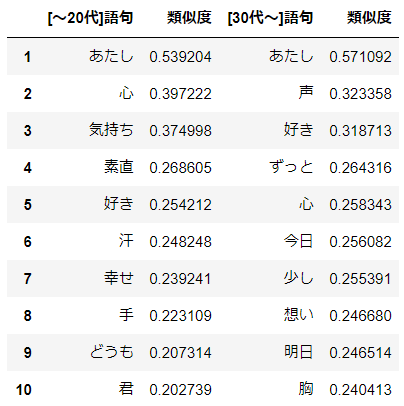
おお!どうやら**aikoにとって"あなた"とは"あたし"**のことみたいです。20代以前と30代以降とで一貫していますね。
20代以前では"心"や"気持ち"など内面を示す言葉が上位に登場している一方で、30代以降では2位に"声"がありますね。自らの心中ではなく実在する"あなた"の"声"を想って歌詞を書いたということでしょうか。
aikoにとっての"あたし"
分析処理
KEYWORD = 'あたし'
result_young = model_young.wv.most_similar(positive=KEYWORD, topn=10)
df_young = pd.DataFrame(result_young, columns=[HEADER_YOUNG + PDCOL_WORD, PDCOL_SIMILARITY])
df_young.index = df_young.index + 1
result_old = model_old.wv.most_similar(positive=KEYWORD, topn=10)
df_old = pd.DataFrame(result_old, columns=[HEADER_OLD + PDCOL_WORD, PDCOL_SIMILARITY])
df_old.index = df_old.index + 1
display(pd.concat([df_young, df_old], axis=1))
分析結果
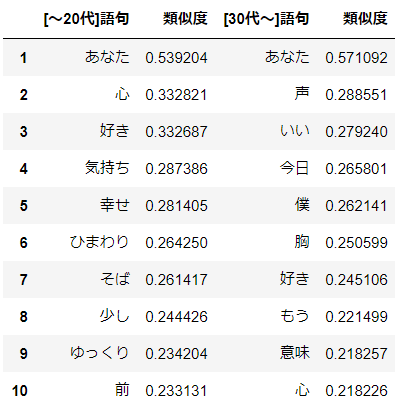
"あなた"≒"あたし"なので"あたし"≒"あなた"も成り立ちます。
20代以前では"好き"や"幸せ"などの直接的な表現が上位に多くありますが、30代以降ではあまり見られません。年齢を重ねるごとにそのような直接的な表現を避けるようになったということでしょうか。
aikoにとっての"好き"
分析処理
KEYWORD = '好き'
result_young = model_young.wv.most_similar(positive=KEYWORD, topn=10)
df_young = pd.DataFrame(result_young, columns=[HEADER_YOUNG + PDCOL_WORD, PDCOL_SIMILARITY])
df_young.index = df_young.index + 1
result_old = model_old.wv.most_similar(positive=KEYWORD, topn=10)
df_old = pd.DataFrame(result_old, columns=[HEADER_OLD + PDCOL_WORD, PDCOL_SIMILARITY])
df_old.index = df_old.index + 1
display(pd.concat([df_young, df_old], axis=1))
分析結果
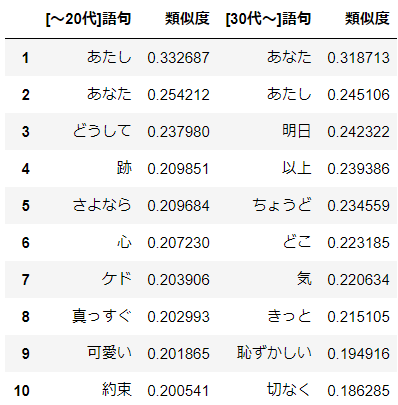
おお!これは面白い結果になりました。"あなた"と"あたし"の順位が逆転しています。
ただこれはどう捉えればよいのでしょう。。。
これまでの分析結果を踏まえると、"あたし"の心中で留まっていた"好き"という思いが、30代以降では"あなた"を意識して表現されているということでしょうかね。
"あなた" + "あたし" = ???
分析処理
# "あなた" + "あたし" = ???
KEYWORD_1 = 'あなた'
KEYWORD_2 = 'あたし'
result_young = model_young.wv.most_similar(positive=[KEYWORD_1,KEYWORD_2], topn=10)
df_young = pd.DataFrame(result_young, columns=[HEADER_YOUNG + PDCOL_WORD, PDCOL_SIMILARITY])
df_young.index = df_young.index + 1
result_old = model_old.wv.most_similar(positive=[KEYWORD_1,KEYWORD_2], topn=10)
df_old = pd.DataFrame(result_old, columns=[HEADER_OLD + PDCOL_WORD, PDCOL_SIMILARITY])
df_old.index = df_old.index + 1
display(pd.concat([df_young, df_old], axis=1))
分析結果
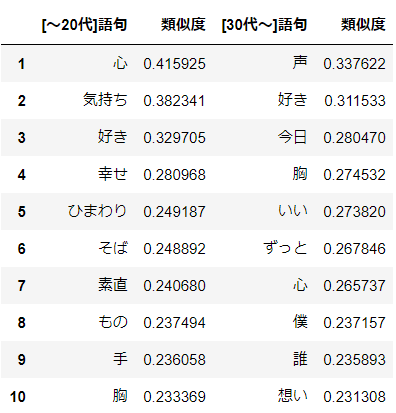
"あなた" + "あたし" = "心" だったのが
"あなた" + "あたし" = "声" に変わりました。
どういうことでしょうか。。。
"あたし" - "あなた" = ???
分析処理
# "あたし" - "あなた" = ???
KEYWORD_1 = 'あたし'
KEYWORD_2 = 'あなた'
result_young = model_young.wv.most_similar(positive=[KEYWORD_1], negative=[KEYWORD_2], topn=10)
df_young = pd.DataFrame(result_young, columns=[HEADER_YOUNG + PDCOL_WORD, PDCOL_SIMILARITY])
df_young.index = df_young.index + 1
result_old = model_old.wv.most_similar(positive=[KEYWORD_1], negative=[KEYWORD_2], topn=10)
df_old = pd.DataFrame(result_old, columns=[HEADER_OLD + PDCOL_WORD, PDCOL_SIMILARITY])
df_old.index = df_old.index + 1
display(pd.concat([df_young, df_old], axis=1))
分析結果
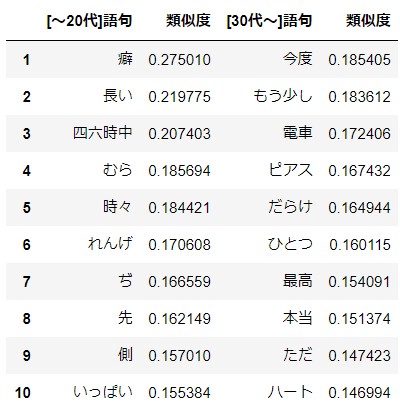
類似度も低く謎な感じになってきました。"あなた" + "癖" = "あたし"というのはわかるようなわからないような。。
おまけ
あまり類似度が高くなかったのでおまけ扱いとしますが、結構おもしろい結果になってます。
aikoにとっての"夏"(20年分)
分析結果
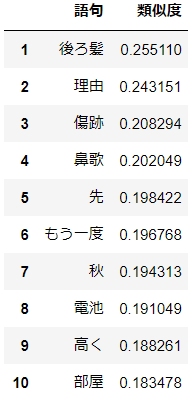
"後ろ髪"が1位(笑)。名残惜しいということでしょうか。
aikoにとっての"冬"(20年分)
分析結果
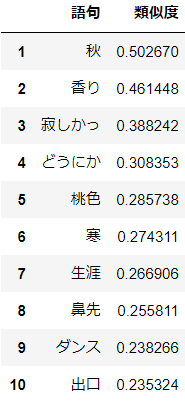
aikoにとって"冬"は"秋"らしいです。おそらく季節を表す言葉が続けざま(秋→冬)に出たために類似度が高くなったのでしょう。
"寂しかっ(た)"や"寒"が出てくるのはイメージとあっていますね。
aikoにとっての"恋"
分析結果
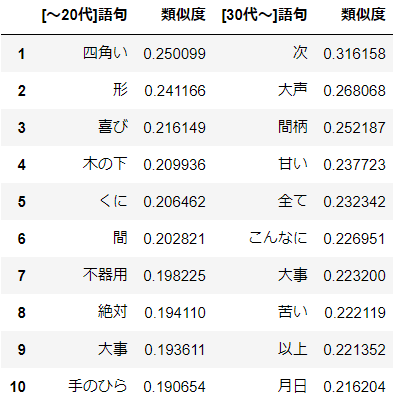
次って(笑)
aikoにとっての"愛"
分析結果
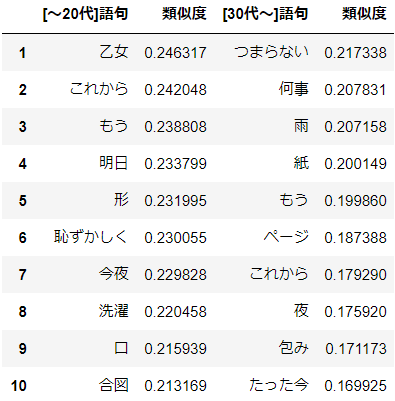
30代のaiko(笑)つまらない割には愛を歌っている気がします。
20代以前の方は"これから"や"明日"など未来を感じる言葉があってよいですね。
最後に
先人の苦労によってこんなにも簡単に分析できてしまいました。感謝感謝。
とりあえず、疲れたけど楽しかったです(小学生)。
参考資料
分析全般
・B'zの歌詞をPythonと機械学習で分析してみた 〜Word 2 Vec編〜
word2vecについて
・絵で理解するWord2vecの仕組み
・models.word2vec – Word2vec embeddings
著作権法について
・著作権法
・平成30年改正著作権法がビジネスに与える「衝撃」