Rubyを触っていく中で、「Rubyはどんな過程を経てコードが理解されて処理されるんだろう」と思って書籍を読んでそのアウトプットをしていこうとおもいます。
処理の流れ
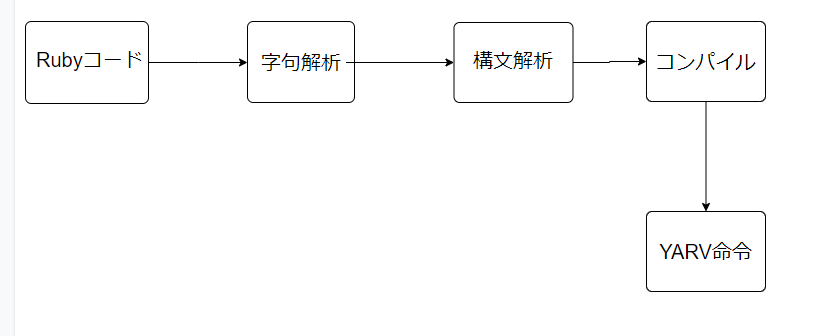
全体的な処理の流れはこのような感じです。まずは全体の流れを抑えることが大事になりそうです。
この記事では、字句解析と構文解析までを書こうとおもいます。
字句解析
以下のコードをsimple.rbファイルに記述し、実行してみます。
10.times do |n|
p n
end
# =>0
1
2
3
4
5
6
7
8
9
まず、この文字列に遭遇すると、Rubyは字句解析を行います。
字句解析とは、自然言語の文やプログラミング言語のソースコードなどの文字列を解析して、後半の狭義の構文解析で最小単位(終端記号)となっている「トークン」(字句)の並びを得る手続きである。
wikipediaより
つまり、字句解析しているコードにどんな文字列があって、どんな数字があるのかをという情報を得ることを字句解析というんです。
最初のこの文字列
10.times do |n|
最初に1から見ていき、次に0を見つけます。その次に「.」が出てきます。このピリオド文字は、小数点のピリオドか字句の区切りの2つの可能性があります。
字句(じく)とは、プログラミング言語などにおいてソースコードに出現する文字列の中で意味を持つ最小単位で、トークンとも言う。
ピリオド文字の次にtが出てくるので、ピリオド文字は小数点のピリオドではなく、字句の区切りの役割を持つピリオドであることが分かります。
つまり10は整数のトークンをもつtINTEGERを持つということになります。
つぎにtimesは文字列であるため、tINDENTIFERとなります。このように続けていくと以下の画像のようになります。

トークンの一覧はこちらのソースコードを参照してみてください
構文解析
字句解析がされた後に、構文解析が行われます。
構文解析とはRubyが分かるように、トークン列をグループ化する作業のことです。
Rubyはパーサジェネレータを使ってコードを理解しています。RubyはBisonというパーサジェネレータを使っています。
文法規則が記されているparse.yファイルをもとにパーサコード(parse.cファイル)が作成されます。
実際に、文法規則を見ていきましょう
program: top_compstmt
top_compstmt: top_stmts opt_terms
opt_terms: ... | top_stmt | ...
top_stmt: stmt | ...
stmt: ... | expr
expr: ... | arg
arg: ... | primary
primary: ... | method_call brace_block | ...
最後に出てくるprimaryの子規則にあるのが、method_callとbrace_blockです。
method_callをまずは見ていきましょう。
ちなみにソースコードはこちらを見てみてください。
#=> rubyコード
10.times
#=> 文法規則
method_call: ... | primary_value call_op operation2 opt_paren_args |
method_call
primary_value
まず、primary_valueから見ていきましょう
primary_value : primary
primary : literal #=>他にもあります。Stringなど
literal : numeric
つまり、今回でいえば、primary_valueには数値が入ります。つまり、10が入ります。
call_op
つぎにcall_opです。
call_op : '.'
#=> 他にもあります
つまりcall_opはドットが入ります。
operation2
つぎにoperation2を見ていきます。
operation2 : tIDENTIFIER
つまり、operations2には識別子が入ります。
opt_paren_args
opt_paren_args : none
今回でいえばnoneになります。他にもありますけどね。
brace_block
先ほどのセクションでは10.timesまで見てきましたが、ブロックを見ていきますので識別子が変わります。
それがbrace_blockです。それを見ていきます
ソースコードはこちらになります
brace_block :k_do do_body k_end #=> 他にもあります
k_do
k_do : keyword_do
do_body
do_body :opt_block_param bodystmt
k_end
k_end : keyword_end
上記のセクションのように探していくと答えが見つかります。このセクションでは省略させていただきます。答えだけ書くと
・keyword_doは予約語であるdoに一致する
・opt_block_paramはブロック引数である|n|に一致する
・bodystmtはputs nに一致する
・keyword_endは予約語であるendに一致する
AST(抽象構文木)
Rubyにはコードを変換したトークン列を表示し、コードをどう解析するかを表すRipperライブラリがあります。それをつかって他のコードも見てみましょう。
require 'ripper'
require 'pp'
code = <<STR
1 + 2 * 3
STR
puts code
pp Ripper.sexp(code)
これを実行すると、
[:program,
[[:binary,
[:@int, "1", [1, 0]],
:+,
[:binary, [:@int, "2", [1, 4]], :*, [:@int, "3", [1, 8]]]]]]
これだけだと、分からないと思うので図示してみます。

これを見ると、出力結果の文字列たちの意味も分かってくると思います。
このアルゴリズムは、最初でみた以下のコード
10.times do |n|
p n
end
これでも同じように作れます。
なぜいきなり、ASTの話をしたかというと、字句解析がなされたあとに構文解析が行われます。
その構文解析がASTというデータ構造へと変換されるからなんです。
結論
RubyプログラムをRubyがどう理解するのかというと、
- 字句解析が行われ、トークン列へと変換される
- 変換されたトークン列は構文解析され、ASTというデータ構造へと変換される
次の章では、ASTに変換されたコードが、どのようにコンパイルされるかを見ていきます
【参考文献】