はじめに
2022-2023年は、GenerativeAIが目覚ましい進化を遂げています。その中でも、GPT-3と呼ばれるモデルは、非常に高い性能を発揮することで知られています。しかし、GPT-3は商用利用に制限がある点やOpenAIのChatGPTがコードをリリースしていない点を考えると、一般の開発者や研究者が利用することが難しい状況にあります。
そこで注目されているのが、ColossalAIという機械学習フレームワークです。ColossalAIは、ChatGPTのトレーニングプロセスをオープンソース版を提供しており、低コストでChatGPTと同等の実装プロセスを誰でも自由に利用することができます。本記事では、ColossalAIが開発したレプリカ版ChatGPTをGoogle Colabで動かしてみようと思います。
参考文献: https://www.hpc-ai.tech/blog/colossal-ai-chatgpt
リポジトリ: https://github.com/hpcaitech/ColossalAI/tree/main/applications/ChatGPT
ColossalAIのトレーニングプロセスの概要
- pytorchベースの完全なオープンソースで、ChatGPTと同等の実装プロセスを提供。
- デモトレーニングプロセスでは、1.62GBのGPUメモリしか必要としない軽量モデル
- 元のpytorchと比較して、単一マシンのトレーニングプロセスは7.73倍高速、1GPUでの推論が1.42倍高速になった、
- 単一GPUスケール、単一ノードでの複数 GPUスケール、オリジナルの1,750億パラメータスケールの複数のバージョンを提供。また、OPT、GPT-3、BLOOM、および Hugging Faceからトレーニングプロセスへの他の多くの事前学習済み大規模モデルのインポートもサポート。
GoogleColabの設定
-
ノートブックを新規作成
下記のURLをクリックしてGoogle Colabにアクセスします.
https://colab.research.google.com/?hl=ja
-
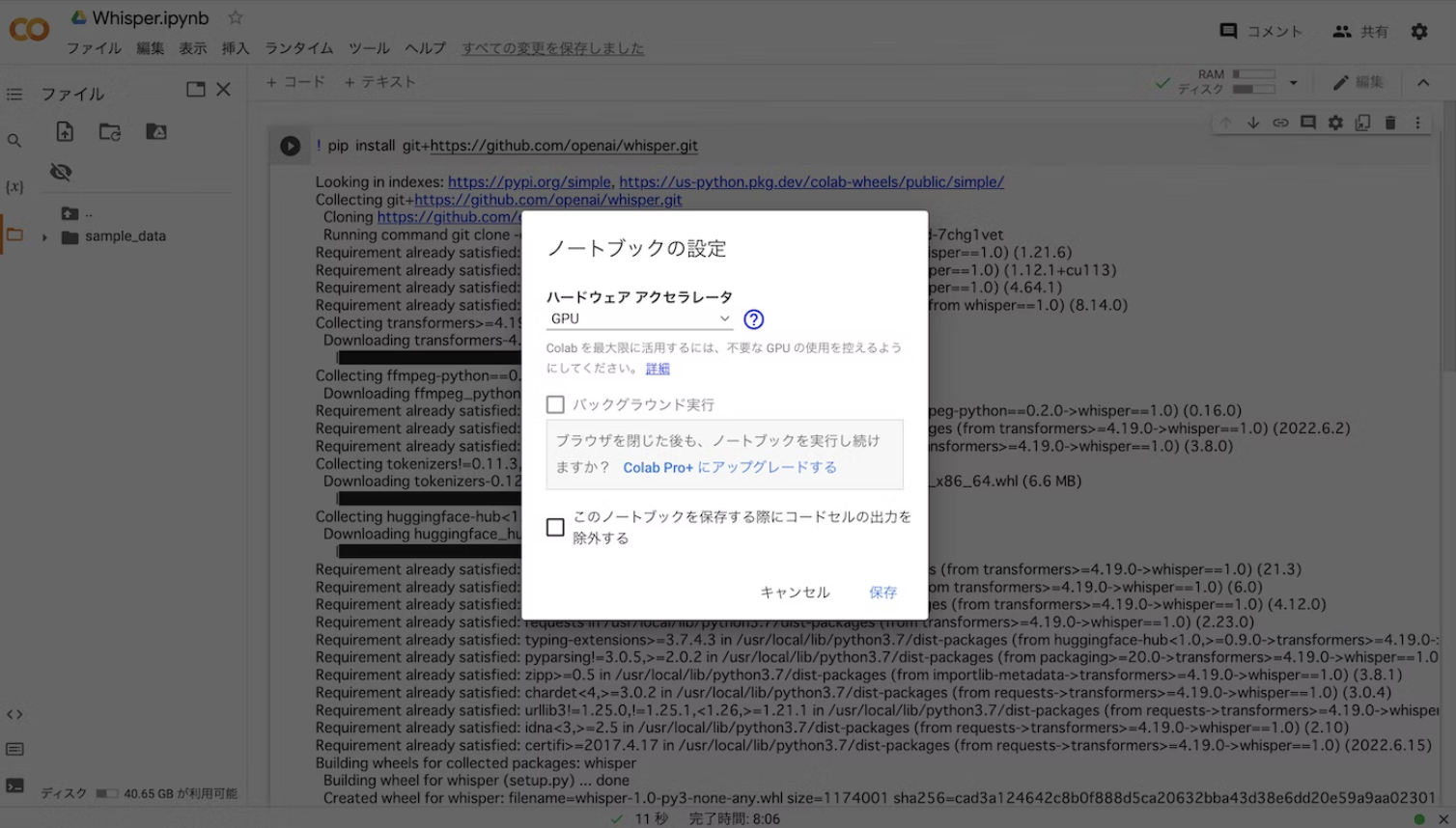
GPUの選択
タブから,ランタイム>ランタイムのタイプを変更>ハードウェアアクセラレータでGPUを選択します.無料版なので、デフォルトで保存しました。
-
作業フォルダの作成
自分のアカウントのGoogle Driveとマウントし、「マイドライブ」の中に「work」という作業フォルダを作成します。その後、以下のコードを実行します。
# Googleドライブのマウント
from google.colab import drive
drive.mount("/content/drive")
# 作業フォルダの作成と移動
import os
os.makedirs("/content/drive/My Drive/work", exist_ok=True)
%cd "/content/drive/My Drive/work"
# ColossalAIのリポジトリをworkディレクトリの中にクローン
!git clone https://github.com/hpcaitech/ColossalAI.git
# ColossalAIというディレクトリに移動し、インストール
%cd ColossalAI
!pip install .

Chatgpt/examplesでトレーニング
ColossalAIのgitリポジトリには、examplesというディレクトリが格納されており、実際にモデルのトレーニングやその結果を確認することができます。まずは用意されているrequirements.txtを使って、必要なライブラリをインストールしましょう。
%cd applications/ChatGPT/examples/
!pip install -r requirements.txt
1. ダミーデータを使ったモデルのトレーニング
ColossalAIの中には、3つのstrategiesがサポートされています。
・naive
・ddp
・colossalai
これらは、ランダムに生成されたprompt dataを使用し、naiveの場合は1GPU、ddpとcolossalaiの場合には、2GPUを使ってトレーニングを行います。GPU数が多いほど並列演算が速くなるため、トレーニングが早まると考えてください。それぞれを実行するコードは次の通りですので、好きなものを選んでください。
# run naive on 1 GPU
!python train_dummy.py --strategy naive
# run DDP on 2 GPUs
!torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy ddp
# run ColossalAI on 2 GPUs
!torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy colossalai
結果
今回はnaiveを使用し、1時間ほどで学習が終了しました。
[最終] 1.84it/s, actor_loss=0.374, critic_loss=0.0465

2. リアルデータを使ったモデルのトレーニング
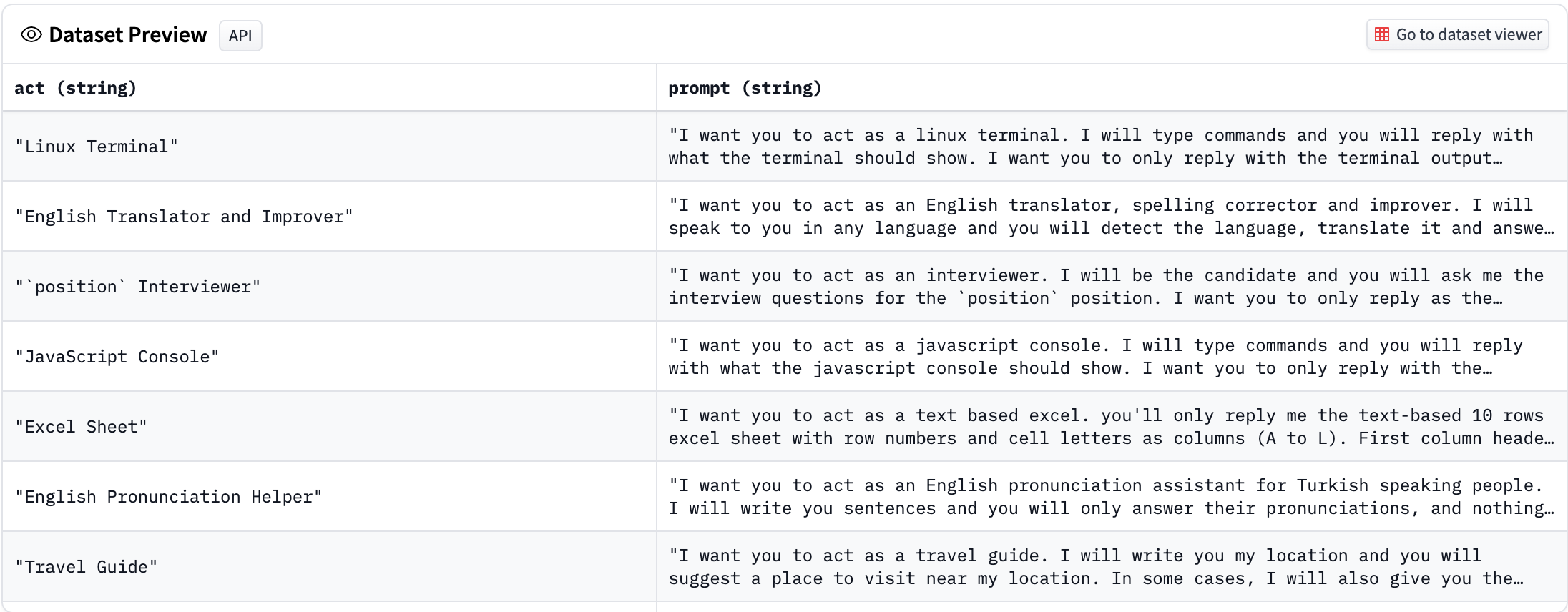
ColossalAIでは,トレーニングデータとしてHugging Faceのawesome-chatgpt-promptsを使用しているため、こちらのprompts.csvをworkフォルダにダウンロードします。テストで使用するのは、100promptsほどの小さいデータセットです。
%cd "/content/drive/My Drive/work"
!git clone https://github.com/f/awesome-chatgpt-prompts.git
%cp /content/drive/MyDrive/work/awesome-chatgpt-prompts/prompts.csv /content/drive/MyDrive/work/ColossalAI/applications/ChatGPT/examples
↓promptsの例
こちらも、3種類のstrategiesから選択することができます。
# run naive on 1 GPU
!python train_prompts.py prompts.csv --strategy naive
# run DDP on 2 GPUs
!torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy ddp
# run ColossalAI on 2 GPUs
!torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy colossalai
結果
今回はnaiveを使用し、10分ほどで学習が終了しました。
[最終] 1.83it/s, actor_loss=-.102, critic_loss=0.00737

3.報酬モデルをトレーニング
公式によると、以下のモデルがサポートされています。
GPT
- GPT2-S (s)
- GPT2-M (m)
- GPT2-L (l)
- GPT2-XL (xl)
- GPT2-4B (4b)
- GPT2-6B (6b)
- GPT2-8B (8b)
- GPT2-10B (10b)
- GPT2-12B (12b)
- GPT2-15B (15b)
- GPT2-18B (18b)
- GPT2-20B (20b)
- GPT2-24B (24b)
- GPT2-28B (28b)
- GPT2-32B (32b)
- GPT2-36B (36b)
- GPT2-40B (40b)
- GPT3 (175b)
BLOOM
- BLOOM-560m
- BLOOM-1b1
- BLOOM-3b
- BLOOM-7b
- BLOOM-175b
OPT
- OPT-125M
- OPT-350M
- OPT-1.3B
- OPT-2.7B
- OPT-6.7B
- OPT-13B
- OPT-30B
今回は、bloom-560mを使っていきましょう!
!python train_reward_model.py --pretrain bigscience/bloom-560m
結果
OutOfMemoryErrorになってしまいました😭もう少し調べる必要ありますね
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 64.00 MiB (GPU 0; 14.75 GiB total capacity; 13.62 GiB already allocated; 2.81 MiB free; 13.74 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
まとめ
本記事では、ColossalAIのChatGPTをGoogle Colabで動かしてみた結果を紹介しました。オープンソースでChatGPTが動かせるようになるのは夢が広がりますね。今後、さらなるLLMの登場や、より高度な自然言語処理が可能になることを期待してます!
おすすめの記事