はじめに
2022/09/22にOpenAIが音声認識モデルWhisperを発表しました.Whisperは人間レベルのロバスト性と音声認識の精度を持ったニューラルネットワークであり,オープンソース化されているので誰でも利用可能です!
[参考文献]
公式サイト:https://openai.com/blog/whisper
論文 :https://cdn.openai.com/papers/whisper.pdf
Github :https://github.com/openai/whisper
Whisperの概要
Whisperは68万時間分の大規模なデータセットで学習された自動音声認識モデルであり,アクセントやバックグラウンドノイズ,および専門用語に対する堅牢性が向上しています.アーキテクチャは,encoder/decoder Transformerとして実装されており,30秒ごとに分割された入力オーディオがLog-mel spectrogramに変換されてからエンコーダに渡されています.デコーダでは,対応するテキストを予測するように学習されており,言語識別,フレーズレベルのタイムスタンプ,多言語の音声文字起こし,英語への音声翻訳などのタスクが実行できるようになっています.
より詳細な内容については,公式サイトや論文を参照してみてください!画像によるアーキテクチャの説明や,k-popの音楽を使用したWhisperのデモンストレーションを見ることができます!(音楽を正確に聞き取って,英語に翻訳するのは本当にすごい...)
このような説明を見たら,実際に手を動かしたくなりますよね?一緒にGoogle ColabでWhisperを試してみましょう!
Google Colabの設定
-
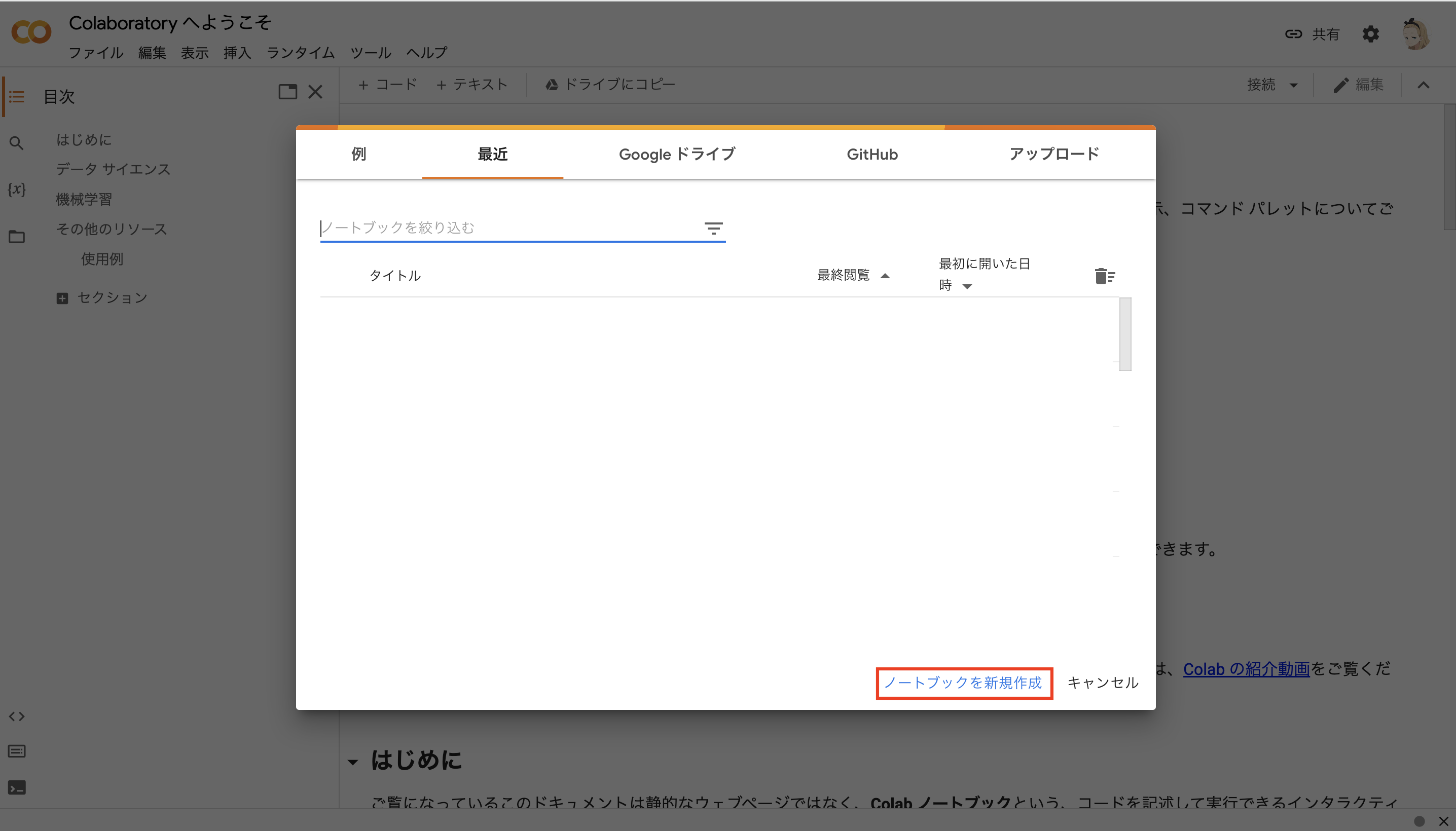
ノートブックを新規作成
下記のURLをクリックしてGoogle Colabにアクセスします.
https://colab.research.google.com/?hl=ja
-
上部のタブから,ランタイム>ランタイムのタイプを変更>ハードウェアアクセラレータでGPUを選択
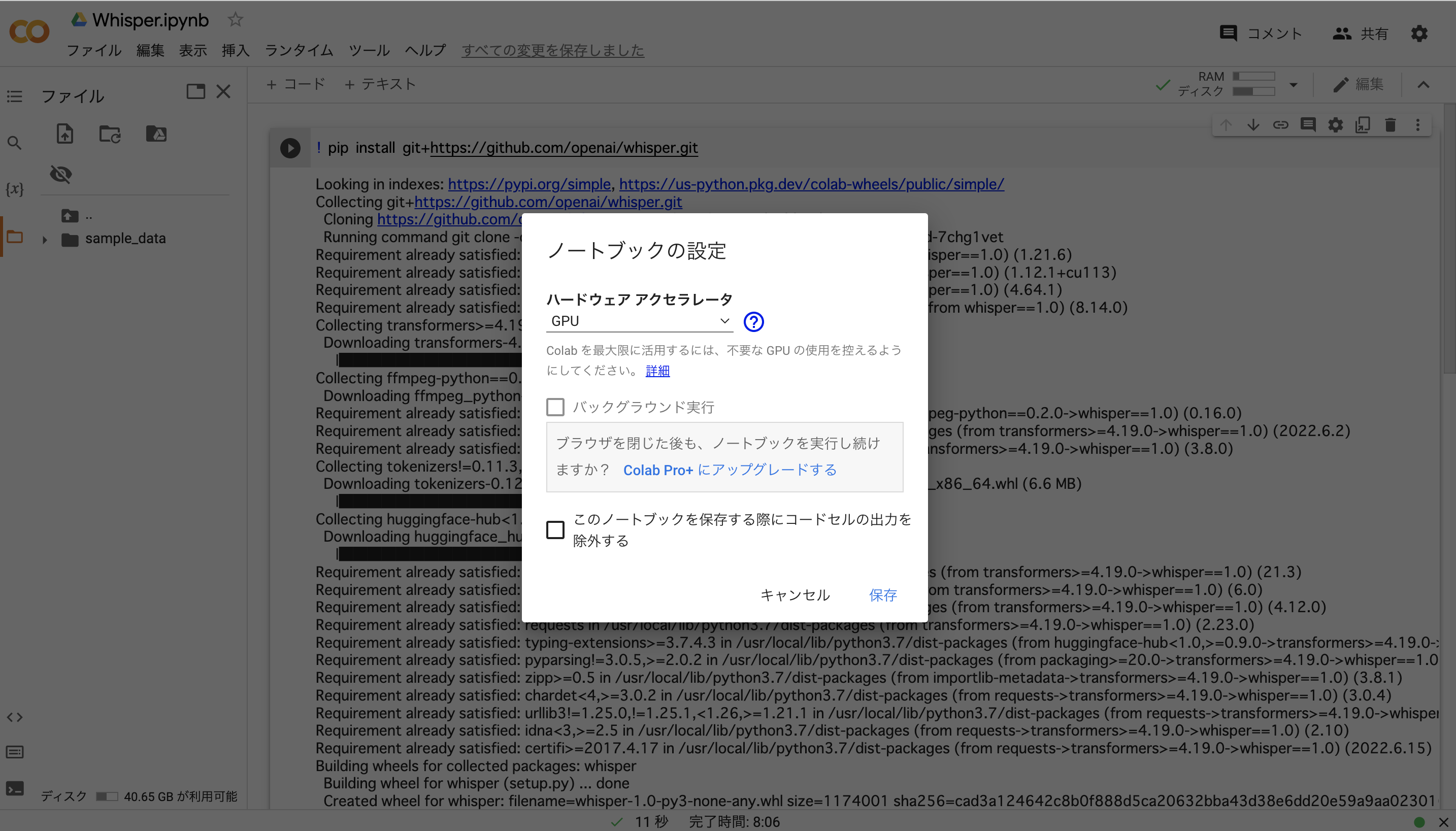
3. コードを実行して,whisperをインストール
! pip install git+https://github.com/openai/whisper.git
4.モデルの設定
こちらに,利用可能なモデルでを示します.
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39M | tine.en | tiny | ~1GB | ~32x |
| base | 74M | base.en | base | ~1GB | ~16x |
| small | 244M | small.em | small | ~2GB | ~6x |
| medium | 769M | medium.en | medium | ~5GB | ~2x |
| large | 1550M | N/A | large | ~10GB | ~1x |
今回は,baseモデルを試してみます.
import whisper
model = whisper.load_model("base")
whisperをimportして,ベースモデルをロードします.以下のようなプログレスバーが完了したら次に進みます.
The cache for model files in Transformers v4.22.0 has been updated. Migrating your old cache. This is a one-time only operation. You can interrupt this and resume the migration later on by calling `transformers.utils.move_cache()`.
Moving 0 files to the new cache system
0/0 [00:00<?, ?it/s]
100%|███████████████████████████████████████| 139M/139M [00:03<00:00, 46.9MiB/s]
次に,モデルが使用しているデバイスを確認するため,以下のコードを実行します.
model.device
すると,下のようにgoogle colab上でcudaを利用していることが確認できます
device(type='cuda', index=0)
音声認識を行う音声データ
今回利用する音声データはこちらです.
スリーエーネットワーク 日常会話で親しくなれる! 日本語会話 中上級音声
https://www.3anet.co.jp/np/resrcs/333020
こちらから,音声データをダウンロードしてください.
終わりましたら,google colabのcontentフォルダにカーソルを当て,右に出てくる:(3つの点マーク)をクリックし,音声データのアップロードを行いましょう.今回は001.mp3というデータをcontentフォルダにアップロードしました.
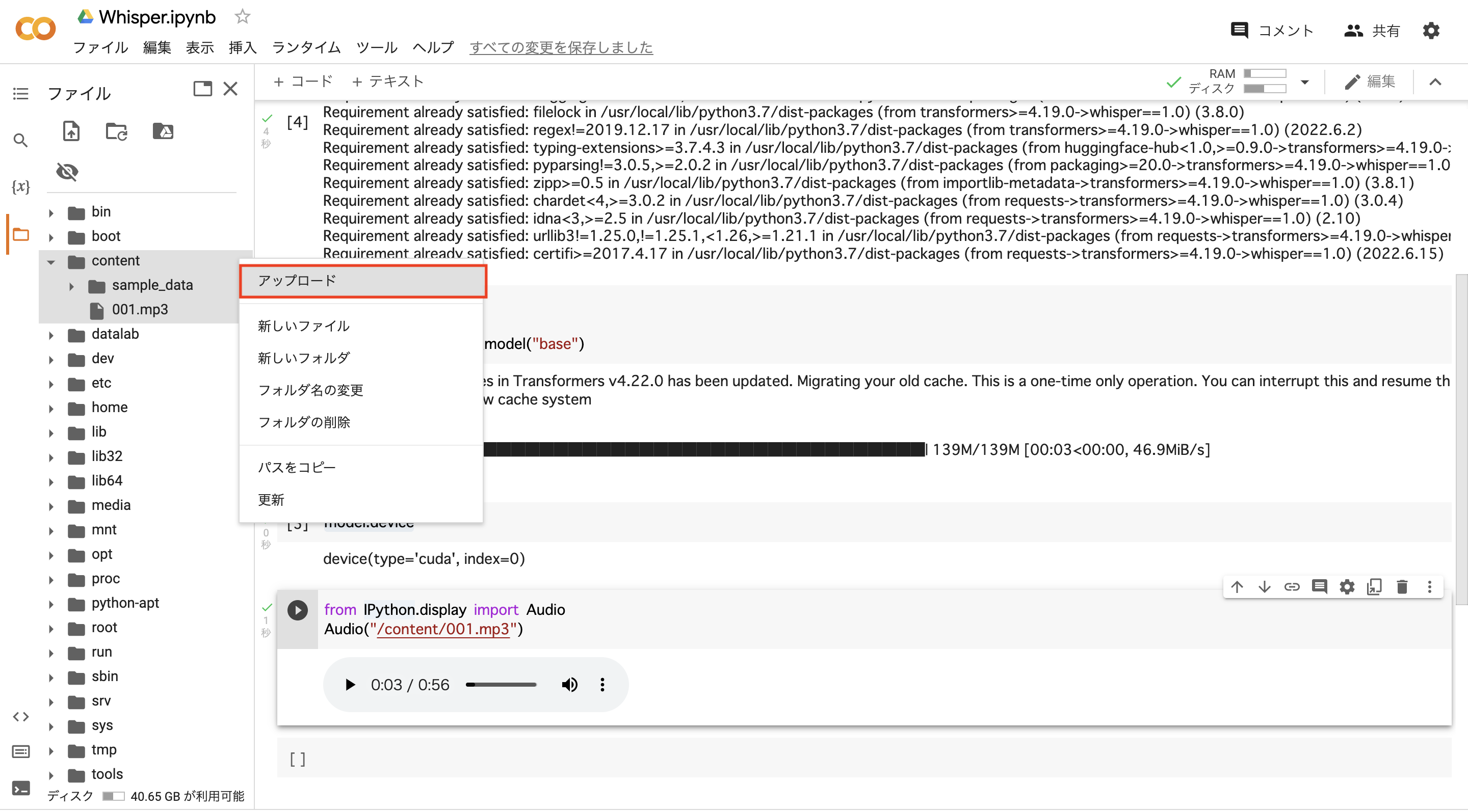
続いて,以下のコードを実行します.
from IPython.display import Audio
Audio("/content/001.mp3")
すると,下の画像のように音声データを再生することができます.

音声データがgoogle colab上で使用できることを確認したら,実際に音声認識をしていきます!
whisperを用いた音声認識
先程の001.mp3データに対して,以下のコードを実行します.
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("/content/001.mp3")
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)
すると,15秒ほどで文字起こしが完了しました.結果を下に示します.whisperでは,最大30秒のクリップに対して音声認識を行うので,001.mp3の56秒のデータのうち,30秒まで読み込まれています.
Detected language: ja
こんにちは。シェアハウスコルサってここですか?もしかして、4人目の10人の人?はい、吉田ゆりです。よろしくお願いします。思ったよりいいところですね、ここ。そうでしょう。僕、ちょうです。やっときた。ゆり、今何時だと思ってる?ごめんごめん、スティーブ。ついにどねしちゃって。
実際の本文も並べて確認します.
こんにちは。シェアハウスコルサってここですか?
もしかして、4人目の「住人」の人?
はい、吉田ゆりです。よろしくお願いします。思ったよりいいところですね、ここ。
そうでしょう。僕、ちょうです。
やっときた。ゆり、今何時だと思ってる?
ごめんごめん、スティーブ。つい「二度寝」しちゃって。
精度がすごいですね.ほぼ完璧に音声認識できています.また,自動で日本語と言語識別できてますね.
今回はここまでにしたいと思います!この記事を見た方,ぜひ自分の手で実践してみてください!
次回の記事
他の記事