はじめに
Vitis™ Application Acceleration Development Flowに従ってCのコードを動かす記事です.
Xilinxの公式チュートリアル に全て詳しく書いてあります.
OpenCLやハードウェアについて勉強中なので色々教えてくれると嬉しいです.
今回実行するコード
昔書いたシンプルな行列積です
void mm(
const unsigned int a_rows ,
const unsigned int b_cols ,
const unsigned int mutual ,
const unsigned int *a ,
const unsigned int *b ,
unsigned int *c
)
{
for( int i = 0 ; i < a_rows ; i++ ) for( int j = 0 ; j < b_cols ; j++ ) c[ i * b_cols + j ] = 0;
for( int k = 0 ; k < mutual ; k++ )
for( int i = 0 ; i < a_rows ; i++ )
for( int j = 0 ; j < b_cols ; j++ )
c[ i * b_cols + j ] += a[ i * mutual + k ] * b[ k * b_cols + j ];
}
高速化
ALVEO等のデバイス上で実行するに辺り
- デバイス側で実行するカーネルを書く
- ホスト側で実行するコードを書く
- コンパイル・リンク
- 実行・プロファイリング
といった具合でコードを書きなおしていく必要があるらしい
カーネルコードを書く
入出力のプラグマの定義
CPU上で完結するコードと異なり,デバイス上で実行される関数(gemm)の入出力はプラグマで設定しポートを生成しなければなりません
このポート生成にあたり,ポインタとして渡されるものと値で渡されるものは異なってくるので注意です
ポインタ渡し
配列の値の取得のためにグローバルメモリにアクセスするポートをAXI Master interface(m_axi)として,
配列のベースアドレスをホストから受け取るポートをAXI4-Lite slave interface(s_axilite)として定義
今回のmmのaの場合次のようになります
# pragma HLS INTERFACE m_axi port=a offset=slave bundle=gmem
# pragma HLS INTERFACE s_axilite port=a bundle=control
offset=slaveはベースアドレスをs_axiliteから受け取るという意味で,bundleはそのポートのm_axiの指定を意味
値渡し
ポインタ渡しの際のs_axiliteの設定と作法は同じらしい
今回のmmのa_rowsの場合は次のようになります
# pragma HLS INTERFACE s_axilite port=a_rows bundle=control
return を忘れず
引数の他にreturnもpragma INTERFACEで設定してやる必要があります.
# pragma HLS INTERFACE s_axilite port=return bundle=control
これを忘れると後々ソフトウェアエミュレーションでは通るのに,ハードウェアエミュレーションではコンパイルできない......となります.
ERROR: [v++ 213-400] This design has interfaces which are not supported by Vitis. Check interface pragmas to ensure the design only uses one s_axilite interface including the 'return' port and one or more m_axi interfaces with offset=slave set to the s_axilite interface; there should not be any other port interface used.
extern "C"
仕上げ?に関数全体をextern "C"で囲ってあげます.
これがないとC++の命名規則でコンパイル/リンクされちゃうかららしいですが,Xilinx的にはCの命名規則が使いたいみたいですね(?)
extern "C"についてはnomunomu0504さんの記事 が分かりやすかったです.
カーネルコード完成
extern "C"{
void mm(
const unsigned int a_rows ,
const unsigned int b_cols ,
const unsigned int mutual ,
const unsigned int *a ,
const unsigned int *b ,
unsigned int *c
)
{
// ポインタ渡し引数のポート設定
# pragma HLS INTERFACE m_axi port=a offset=slave bundle=gmem
# pragma HLS INTERFACE m_axi port=b offset=slave bundle=gmem
# pragma HLS INTERFACE m_axi port=c offset=slave bundle=gmem
# pragma HLS INTERFACE s_axilite port=a bundle=control
# pragma HLS INTERFACE s_axilite port=b bundle=control
# pragma HLS INTERFACE s_axilite port=c bundle=control
// 値渡し引数のポート設定
# pragma HLS INTERFACE s_axilite port=a_rows bundle=control
# pragma HLS INTERFACE s_axilite port=b_cols bundle=control
# pragma HLS INTERFACE s_axilite port=mutual bundle=control
// 結果を格納する配列に0を代入
for( int i = 0 ; i < a_rows ; i++ ) for( int j = 0 ; j < b_cols ; j++ ) c[ i * b_cols + j ] = 0;
// 行列積
for( int k = 0 ; k < mutual ; k++ )
for( int i = 0 ; i < a_rows ; i++ )
// パイプライン処理
# pragma HLS pipeline II=1
for( int j = 0 ; j < b_cols ; j++ )
c[ i * b_cols + j ] += a[ i * mutual + k ] * b[ k * b_cols + j ];
}
}
デバイス内でメモリ確保して色々したくもありますが,とりあえずこれで
# pragma HLS PIPELINE
をおまけでつけてみました.
pragma HLSにはこのような高速化マクロが色々あるので,試したいですね
[https://www.xilinx.com/html_docs/xilinx2019_2/vitis_doc/Chunk538726301.html#okr1504034364623]
ホストコードを書く
ホスト側の処理は
- Platform 取得
- Context 作成
- CommandQueue 作成
- バイナリをロード
- Program 作成
- Kernel 作成
- デバイス上のメモリ(Buffer)確保
- 変数 に Buffer の値を代入
- Kernel を投げる
- 結果をデバイスからホストに転送
- デバイスメモリ開放
という流れで進んでいきます
今回はXilinxのサンプルプログラム
を改変して利用します.
/**********
Copyright (c) 2018, Xilinx, Inc.
All rights reserved.
Redistribution and use in source and binary forms, with or without modification,
are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice,
this list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its contributors
may be used to endorse or promote products derived from this software
without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED.
IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,
INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE,
EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
**********/
# include "host.hpp"
int main(int argc, char** argv)
{
if (argc != 2) {
std::cout << "Usage: " << argv[0] << " <XCLBIN File>" << std::endl;
return EXIT_FAILURE;
}
std::string binaryFile = argv[1];
cl_int err;
unsigned fileBufSize;
unsigned int a_rows = 128;
unsigned int b_cols = 128;
unsigned int mutual = 128;
size_t a_size = sizeof(unsigned int) * a_rows * mutual;
size_t b_size = sizeof(unsigned int) * mutual * b_cols;
size_t c_size = sizeof(unsigned int) * a_rows * b_cols;
// メモリ確保
std::vector<int,aligned_allocator<int>> a( a_rows * mutual );
std::vector<int,aligned_allocator<int>> b( mutual * b_cols );
std::vector<int,aligned_allocator<int>> sw_c( a_rows * b_cols );
std::vector<int,aligned_allocator<int>> hw_c( a_rows * b_cols );
// テストデータ入力
for( int i = 0 ; i < a_rows ; i++ )
for( int j = 0 ; j < mutual ; j++ )
a[i * mutual + j ] = i * mutual + j;
for( int i = 0 ; i < mutual ; i++ )
for( int j = 0 ; j < b_cols ; j++ )
b[i * b_cols + j ] = i * b_cols + j;
for( int i = 0 ; i < a_rows ; i++ ) for( int j = 0 ; j < b_cols ; j++ ) sw_c[ i * b_cols + j ] = 0;
for( int k = 0 ; k < mutual ; k++ )
for( int i = 0 ; i < a_rows ; i++ )
for( int j = 0 ; j < b_cols ; j++ )
sw_c[ i * b_cols + j ] += a[ i * mutual + k ] * b[ k * b_cols + j ];
// OPENCL HOST CODE AREA START
// ------------------------------------------------------------------------------------
// 1 : 全ての Platform を取得し、Xilinxのものを持ってくる
// ------------------------------------------------------------------------------------
std::vector<cl::Device> devices = get_devices("Xilinx");
devices.resize(1);
cl::Device device = devices[0];
// ------------------------------------------------------------------------------------
// 2 : Context 作成
// ランタイムでオブジェクトを管理してくれるやつ
// ------------------------------------------------------------------------------------
OCL_CHECK(err, cl::Context context(device, NULL, NULL, NULL, &err));
// ------------------------------------------------------------------------------------
// 3 : CommandQueue 作成
// コマンドのQueue
// ------------------------------------------------------------------------------------
OCL_CHECK(err, cl::CommandQueue q(context, device, CL_QUEUE_PROFILING_ENABLE, &err));
// ------------------------------------------------------------------
// 4 : Binaryのロード
// ここではargv[1]で受け取ったカーネル関数のバイナリファイルをロードしてる
// ------------------------------------------------------------------
char* fileBuf = read_binary_file(binaryFile, fileBufSize);
cl::Program::Binaries bins{{fileBuf, fileBufSize}};
// -------------------------------------------------------------
// 5 : Context, Device, Binary を用いて Program を作成
// ここでFPGAにバイナリを送信してるらしい
// -------------------------------------------------------------
OCL_CHECK(err, cl::Program program(context, devices, bins, NULL, &err));
// -------------------------------------------------------------
// 6 : Kernel の作成
// ホストコードが実際にハードウェアを動かすためのハンドル
// -------------------------------------------------------------
OCL_CHECK(err, cl::Kernel krnl_mm(program,"mm", &err));
// ================================================================
// 7 : デバイスメモリ確保
// ================================================================
// o) 結果格納用のメモリを確保
// o) グローバルメモリにバッファを確保
// ================================================================
// .......................................................
// a用のバッファ,buf_a 確保
// .......................................................
OCL_CHECK(err, cl::Buffer buf_a (context,CL_MEM_USE_HOST_PTR | CL_MEM_READ_ONLY,
a_size , a.data(), &err));
// .......................................................
// b用のバッファ,buf_b 確保
// .......................................................
OCL_CHECK(err, cl::Buffer buf_b (context,CL_MEM_USE_HOST_PTR | CL_MEM_READ_ONLY,
b_size , b.data(), &err));
// .......................................................
// 結果,つまりc用 のバッファ buf_c 確保
// .......................................................
OCL_CHECK(err, cl::Buffer buf_c(context,CL_MEM_USE_HOST_PTR | CL_MEM_WRITE_ONLY,
c_size , hw_c.data(), &err));
// ============================================================================
// 引数を渡します!
// void mm(
// const unsigned int a_rows ,
// const unsigned int b_cols ,
// const unsigned int mutual ,
// const unsigned int *a ,
// const unsigned int *b ,
// unsigned int *c
// )
//
// 第n引数という情報が必要なので,
// a_rows : 0
// b_cols : 1
// mutual : 2
// *a : 3
// *b : 4
// *c : 5
//
// 値渡しのものには値を,ポインタ渡しのものにはバッファを与える
// ============================================================================
OCL_CHECK(err, err = krnl_mm.setArg(0, a_rows));
OCL_CHECK(err, err = krnl_mm.setArg(1, b_cols));
OCL_CHECK(err, err = krnl_mm.setArg(2, mutual));
OCL_CHECK(err, err = krnl_mm.setArg(3, buf_a ));
OCL_CHECK(err, err = krnl_mm.setArg(4, buf_b ));
OCL_CHECK(err, err = krnl_mm.setArg(5, buf_c ));
// ------------------------------------------------------
// 8 : ホストからデバイスのグローバルメモリに転送
// ------------------------------------------------------
OCL_CHECK(err, err = q.enqueueMigrateMemObjects({ buf_a , buf_b },0/* 0 means from host*/));
// ----------------------------------------
// 9 : Kernel 実行
// ----------------------------------------
OCL_CHECK(err, err = q.enqueueTask(krnl_mm));
// --------------------------------------------------
// 10 : 結果を取得
// --------------------------------------------------
OCL_CHECK(err, err = q.enqueueMigrateMemObjects({buf_c},CL_MIGRATE_MEM_OBJECT_HOST));
q.finish();
// OPENCL HOST CODE AREA END
// Compare the results of the Device to the simulation
bool match = true;
for (int i = 0 ; i < a_rows * b_cols ; i++){
if (sw_c[i] != hw_c[i]){
std::cout << "Error: Result mismatch" << std::endl;
std::cout << "i = " << i << " CPU result = " << sw_c[i]
<< " Device result = " << hw_c[i] << std::endl;
match = false;
break;
}
}
// ============================================================================
// 11 : メモリ解放
// ============================================================================
delete[] fileBuf;
std::cout << "TEST " << (match ? "PASSED" : "FAILED") << std::endl;
return (match ? EXIT_SUCCESS : EXIT_FAILURE);
}
コンパイル/リンク
Xilinxの公式チュートリアル に沿ってしました.
ただし,設定ファイルをsourceし忘れていると一生できないので注意です.
また,
- ソフトウェアエミュレーション
- ハードウェアエミュレーション
- ハードウェア実行
が存在し,それぞれでカーネルコードをコンパイルしてあげる必要があります.
設定ファイルのsource
$ source /Xilinx_wo_install_shitato-ko/Vitis/2019.2/settings64.sh
$ source /Xilinx_wo_install_shitato-ko/xrt/setup.sh
ホストコードのコンパイル
$ g++ -I$XILINX_XRT/include/ -I$XILINX_VIVADO/include/ -Wall -O0 -g -std=c++11 ./src/host.cpp -o 'host' -L$XILINX_XRT/lib/ -lOpenCL -lpthread -lrt -lstdc++
ソフトウェアエミュレーション
サンプルのカーネルコードのコンパイルではdesign.cfgから設定を読んでおり,チュートリアルではPlatformがxilinx_u200_xdma_201830_2ですが,
実行環境はPlatformがxilinx_u280_xdma_201920_1なので,その辺りを変更しています.(--config design.cfg を消してコマンドラインで渡してやることもできるとは思います).
$ v++ -t sw_emu --config design.cfg -c -k mm -I'../src' -o'mm.xilinx_u280_xdma_201920_1.xo' './src/mm.cpp' # コンパイル
$ v++ -t sw_emu --config design.cfg -l -o'mm.xilinx_u280_xdma_201920_1.xclbin' mm.xilinx_u280_xdma_201920_1.xo # リンク
$ emconfigutil --platform xilinx_u280_xdma_201920_1
$ export XCL_EMULATION_MODE=sw_emu
$ ./host mm.xilinx_u280_xdma_201920_1.xclbin #実行
実行結果は
Found Platform
Platform Name: Xilinx
INFO: Reading mm.xilinx_u280_xdma_201920_1.xclbin
Loading: 'mm.xilinx_u280_xdma_201920_1.xclbin'
TEST PASSED
ちなみにコンパイル/リンク時間は51秒でした,ちょっと長い.
ハードウェアエミュレーション
ソフトウェアエミュレーションのカーネルのコンパイルのsw_emuをhw_emuに変えるだけでハードウェアエミュレーションになります.
$ v++ -t hw_emu --config design.cfg -c -k mm -I'../src' -o'mm.xilinx_u280_xdma_201920_1.xo' './src/mm.cpp' # コンパイル
$ v++ -t hw_emu --config design.cfg -l -o'mm.xilinx_u280_xdma_201920_1.xclbin' mm.xilinx_u280_xdma_201920_1.xo # リンク
$ emconfigutil --platform xilinx_u280_xdma_201920_1
$ export XCL_EMULATION_MODE=hw_emu
$ ./host mm.xilinx_u280_xdma_201920_1.xclbin
コンパイル/リンク時間は16分ほどでした.
行列サイズを1024×1024で行ったところ,終わる気配が感じられなかったので128×128で実行しなおしたのですが......
Found Platform
Platform Name: Xilinx
INFO: Reading mm.xilinx_u280_xdma_201920_1.xclbin
Loading: 'mm.xilinx_u280_xdma_201920_1.xclbin'
INFO: [HW-EM 01] Hardware emulation runs simulation underneath. Using a large data set will result in long simulation times. It is
recommended that a small dataset is used for faster execution. The flow uses approximate models for DDR memory and interconnect a
INFO::[ Vitis-EM 22 ] [Time elapsed: 4 minute(s) 48 seconds, Emulation time: 0.54278 ms]
Data transfer between kernel(s) and global memory(s)
mm_1:m_axi_gmem-HBM[0] RD = 54.758 KB WR = 82.250 KB
INFO::[ Vitis-EM 22 ] [Time elapsed: 9 minute(s) 48 seconds, Emulation time: 1.10157 ms]
Data transfer between kernel(s) and global memory(s)
mm_1:m_axi_gmem-HBM[0] RD = 122.484 KB WR = 104.824 KB
INFO::[ Vitis-EM 22 ] [Time elapsed: 14 minute(s) 49 seconds, Emulation time: 1.67072 ms]
Data transfer between kernel(s) and global memory(s)
mm_1:m_axi_gmem-HBM[0] RD = 191.469 KB WR = 127.820 KB
INFO::[ Vitis-EM 22 ] [Time elapsed: 19 minute(s) 49 seconds, Emulation time: 2.24573 ms]
Data transfer between kernel(s) and global memory(s)
mm_1:m_axi_gmem-HBM[0] RD = 261.164 KB WR = 151.051 KB
INFO::[ Vitis-EM 22 ] [Time elapsed: 24 minute(s) 49 seconds, Emulation time: 2.82035 ms]
Data transfer between kernel(s) and global memory(s)
mm_1:m_axi_gmem-HBM[0] RD = 330.809 KB WR = 174.266 KB
INFO::[ Vitis-EM 22 ] [Time elapsed: 29 minute(s) 49 seconds, Emulation time: 3.38731 ms]
Data transfer between kernel(s) and global memory(s)
mm_1:m_axi_gmem-HBM[0] RD = 399.527 KB WR = 197.172 KB
### 中略 ###
INFO::[ Vitis-EM 22 ] [Time elapsed: 1766 minute(s) 11 seconds, Emulation time: 199.509 ms]
Data transfer between kernel(s) and global memory(s)
mm_1:m_axi_gmem-HBM[0] RD = 24170.293 KB WR = 8120.762 KB
INFO::[ Vitis-EM 22 ] [Time elapsed: 1771 minute(s) 12 seconds, Emulation time: 200.052 ms]
Data transfer between kernel(s) and global memory(s)
mm_1:m_axi_gmem-HBM[0] RD = 24236.129 KB WR = 8142.707 KB
INFO::[ Vitis-EM 22 ] [Time elapsed: 1776 minute(s) 12 seconds, Emulation time: 200.569 ms]
Data transfer between kernel(s) and global memory(s)
mm_1:m_axi_gmem-HBM[0] RD = 24298.805 KB WR = 8163.598 KB
INFO::[ Vitis-EM 22 ] [Time elapsed: 1781 minute(s) 12 seconds, Emulation time: 201.073 ms]
Data transfer between kernel(s) and global memory(s)
mm_1:m_axi_gmem-HBM[0] RD = 24359.832 KB WR = 8183.941 KB
INFO::[ Vitis-EM 22 ] [Time elapsed: 1786 minute(s) 12 seconds, Emulation time: 201.606 ms]
Data transfer between kernel(s) and global memory(s)
mm_1:m_axi_gmem-HBM[0] RD = 24424.512 KB WR = 8205.500 KB
INFO::[ Vitis-EM 22 ] [Time elapsed: 1791 minute(s) 13 seconds, Emulation time: 202.127 ms]
Data transfer between kernel(s) and global memory(s)
mm_1:m_axi_gmem-HBM[0] RD = 24487.613 KB WR = 8226.535 KB
INFO::[ Vitis-EM 22 ] [Time elapsed: 1796 minute(s) 13 seconds, Emulation time: 202.652 ms]
Data transfer between kernel(s) and global memory(s)
mm_1:m_axi_gmem-HBM[0] RD = 24551.293 KB WR = 8247.762 KB
TEST PASSED
INFO::[ Vitis-EM 22 ] [Time elapsed: 1798 minute(s) 12 seconds, Emulation time: 202.859 ms]
Data transfer between kernel(s) and global memory(s)
mm_1:m_axi_gmem-HBM[0] RD = 24576.000 KB WR = 8256.000 KB
と,1798分もかかっていました (エッ)
$O(N^3)$でデータが約10倍なのを考えると......
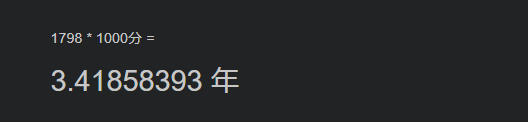
......
ハードウェア実行
最後の実機で動かしてやりましょう.sw_emuだったりhw_emuだったところをhwにして,unset XCL_EMULATION_MODEです
$ v++ -t hw --config design.cfg -c -k mm -I'../src' -o'mm.xilinx_u280_xdma_201920_1.xo' './src/mm.cpp' # コンパイル
$ v++ -t hw --config design.cfg -l -o'mm.xilinx_u280_xdma_201920_1.xclbin' mm.xilinx_u280_xdma_201920_1.xo # リンク
$ emconfigutil --platform xilinx_u280_xdma_201920_1
$ unset XCL_EMULATION_MODE
$ ./host mm.xilinx_u280_xdma_201920_1.xclbin #実行
コンパイル/リンク時間は2時間ほどでした.
おまけでchronoを用いて時間を測り,1024×1024同士の行列積を求めてみました.
CPU : 11789.000000 ms
Found Platform
Platform Name: Xilinx
INFO: Reading mm.xilinx_u280_xdma_201920_1.xclbin
Loading: 'mm.xilinx_u280_xdma_201920_1.xclbin'
ALVEO: 399177.000000 ms
TEST PASSED
えっ
おわり
ALVEOを使って行列積を計算してみました.
結果的にCPUより遅いという悲しい結果でしたが,ローカルメモリの確保や違いpragmaを試したり色々やることはありそうです(そもそもSDAccelに行列積のライブラリがあった気がする).
今後高速化等を詰めてまた何か書きたいです.