導入
会社のQiita Organization を作成し、技術広報用のXアカウント を作ったので、OrganizationメンバーのQiita記事を紹介する仕組みを用意しようと思いつき、簡単に実装してみました。
背景
このプログラムの目的は、弊社メンバーのQiita記事をより多くの人々に届けるための自動化システムを構築することです。コストをできるだけ抑えたかったので、ChatGPT APIのトークン数を節約するために記事を英語に翻訳してから処理しています。
ちゃんと節約効果があるか、当時の記事一式を公式のカウンターで確認しました。
https://platform.openai.com/tokenizer
技術スタックとプログラム構成
- 言語とプラットフォーム: Python, Cloud Functions for Firebase
-
主要なモジュール:
-
main.py: プログラムのエントリーポイントとスケジュール設定 -
mainfunc.py: 各プログラムを呼び出し -
qiita.py: Qiita APIを使用して記事を取得 -
translate.py: Google Translate APIを利用して記事を英訳 -
chatgpt.py: ChatGPT APIを使用して記事の要約を生成 -
x_twitter.py: Twitter APIを利用して投稿処理
-
コード
コード一式はgithubに置いてあります。
https://github.com/yoshitakakurokawa/post_qiita_summary
サンプルコード
main.py
# Welcome to Cloud Functions for Firebase for Python!
# This script initializes Firebase and schedules a function to run every day.
from firebase_functions import scheduler_fn
import firebase_admin
import mainfunc
# Initialize Firebase
app = firebase_admin.initialize_app()
# 毎日朝九時に実行するよう指示
@scheduler_fn.on_schedule(schedule="every day 09:00", timezone="Asia/Tokyo")
def on_schedule(event: scheduler_fn.ScheduledEvent) -> None:
# Call the main function from the mainfunc module
mainfunc.main()
mainfunc.py
import os
from datetime import datetime
from dotenv import load_dotenv
import qiita
import translate
import chatgpt
import x_twitter
# '%j'は年中の日付を表す
DAY_OF_YEAR = '%j'
def main():
# .envファイルの内容を読み込見込む
load_dotenv()
org_name = os.environ["ORGANIZATION_NAME"] # 組織の名前
try:
articles = qiita.fetch_articles_from_organization(org_name)
num = int(datetime.now().strftime(DAY_OF_YEAR)) % len(articles)
if articles:
article = articles[num]
print(
f"ItemId: {article['id']}, Title: {article['title']}, URL: {article['url']}"
)
# articleの本文を取得
body = qiita.strip_html_tags(article["rendered_body"])
body = qiita.strip_blanklines(body)
# articleを英語に翻訳
translated_text = translate.translate_j2e(body)
print(translated_text)
# 要約を生成
summary = chatgpt.generate_summary(translated_text)
print(summary)
# ツイート
x_twitter.post(f"自動要約\n{article['url']}\n{summary}")
except Exception as e:
print(f"An error occurred: {e}")
if __name__ == "__main__":
main()
qiita.py
import requests
import json
import os
import re
from dotenv import load_dotenv
def fetch_articles_from_organization(org_name, per_page=10):
"""
組織名から記事を取得します。
Args:
org_name (str): 組織名。
per_page (int): 1ページあたりのアイテム数。
Returns:
list: 記事のリスト。
"""
url = "https://qiita.com/api/v2/items"
params = {
"page": 1, # ページ番号
"per_page": per_page, # 1ページあたりのアイテム数
"query": f"org:{org_name}", # 組織名で検索
}
headers = {"Authorization": "Bearer " + os.getenv("QIITA_ACCESS_TOKEN")}
response = requests.get(url, params=params, headers=headers)
if response.status_code == 200:
articles = json.loads(response.text)
return articles
else:
print("Failed to fetch articles" + response.text)
raise Exception(f"Failed to fetch articles. Status code: {response.status_code}, Response: {response.text}")
return None
def strip_html_tags(text):
"""
HTMLタグを取り除きます。
Args:
text (str): HTMLタグを取り除く文字列。
Returns:
str: HTMLタグを取り除いた文字列。
Examples:
>>> strip_html_tags("<h1>タイトル</h1>")
"タイトル"
"""
return re.sub(re.compile("<.*?>"), "", text)
def strip_blanklines(text):
"""
空行と行頭行末の空白を取り除きます。
Args:
text (str): 空行と行頭行末の空白を取り除く文字列。
Returns:
str: 空行と行頭行末の空白を取り除いた文字列。
Examples:
>>> strip_blanklines(" \n \n \n 本文 \n \n ")
"本文"
"""
return "\n".join(filter(None, map(lambda x: x.strip(), text.split("\n"))))
def generate_filename(title, max_length=255):
"""
タイトルからファイル名を生成します。特殊文字はハイフンに置き換えられ、最大長は255文字に制限されます。
Args:
title (str): ファイル名を生成するためのタイトル。
max_length (int, optional): ファイル名の最大長。デフォルトは255。
Returns:
str: 生成されたファイル名。
"""
filename = re.sub(r'[\\|/|:|?|.|"|<|>|\|]', '-', title)
return filename[:max_length]
if __name__ == "__main__":
# .envファイルの内容を読み込見込む
load_dotenv()
org_name = os.getenv("ORGANIZATION_NAME") # 組織の名前
if org_name is None:
raise Exception("Environment variable 'ORGANIZATION_NAME' is not set.")
articles = fetch_articles_from_organization(org_name)
if articles:
for article in articles:
print(
f"ItemId: {article['id']}, Title: {article['title']}, URL: {article['url']}"
)
body = strip_html_tags(article["rendered_body"])
body = strip_blanklines(body)
print(f"Body: {body}")
filename = generate_filename(article['title'])
with open(f"{filename}.txt", "w") as f:
f.write(body)
translate.py
import os
from dotenv import load_dotenv
from google.cloud import translate
# Google Translateで英語に翻訳
def translate_j2e(text):
"""
日本語を英語に翻訳します。
Args:
text (str): 翻訳する日本語の文章。
Returns:
str: 翻訳された英語の文章。
Examples:
>>> translate_j2e("こんにちは")
"Hello"
"""
client = translate.TranslationServiceClient()
location = "global"
project_id = os.getenv('GOOGLE_TRANSLATE_PROJECT_ID')
if project_id is None:
raise ValueError("環境変数 'GOOGLE_TRANSLATE_PROJECT_ID' が設定されていません。")
parent = f"projects/{project_id}/locations/{location}"
response = client.translate_text(
request={
"parent": parent,
"contents": [text],
"mime_type": "text/plain",
"source_language_code": "ja-JP",
"target_language_code": "en-US",
}
)
translated_text = "".join(translation.translated_text for translation in response.translations)
return translated_text
import sys
if __name__ == "__main__":
# .envファイルの内容を読み込見込む
load_dotenv()
if len(sys.argv) < 2:
print("Usage: python translate.py <filename>")
sys.exit(1)
# ファイルを読み込み、翻訳を行う
try:
with open(sys.argv[1]) as f:
article = f.read()
translated_text = translate_j2e(article)
print(translated_text)
except Exception as e:
print(f"エラーが発生しました: {e}")
x_twitter.py
import os
import tweepy
from dotenv import load_dotenv
# 環境変数の読み込み
load_dotenv()
def post(text):
"""
ツイートします。
Args:
text (str): ツイートする文章。
Returns:
None: None
"""
consumer_key = os.getenv("X_API_KEY")
consumer_secret = os.getenv("X_API_KEY_SECRET")
access_token_key = os.getenv("X_ACCESS_TOKEN")
access_token_secret = os.getenv("X_ACCESS_TOKEN_SECRET")
# 環境変数が設定されていない場合のエラーハンドリング
if not all([consumer_key, consumer_secret, access_token_key, access_token_secret]):
raise Exception("環境変数が設定されていません。")
# 認証
try:
client = tweepy.Client(
consumer_key=consumer_key,
consumer_secret=consumer_secret,
access_token=access_token_key,
access_token_secret=access_token_secret,
)
except Exception as e:
raise Exception("Twitter APIへの接続に失敗しました。") from e
# ツイート
try:
client.create_tweet(text=text)
except Exception as e:
raise Exception("ツイートの作成に失敗しました。") from e
if __name__ == "__main__":
posttext = "API test post 3"
try:
post(posttext)
print(posttext)
except Exception as e:
print(e)
APIの概要
Qiita API
Qiita APIは、Qiita上の記事やユーザー情報にアクセスするためのインターフェイスです。このAPIを使用して、特定のタグやキーワードを持つ記事を取得します。
今回は GET /api/v2/items に queryパラメータを付けて指定Organizationの記事一覧を取得しています。
参考:https://qiita.com/api/v2/docs#get-apiv2items
記事の取得だけであれば登録なしでも使えますが、今回認証した上でAPI利用するようにしています。
無料です。
Google Translate API
Google Translate APIは、テキストを多様な言語に翻訳するためのサービスです。英語に翻訳することで、ChatGPT APIのトークン使用量を節約するという目的のために使用しています。
参考:https://cloud.google.com/translate/docs/advanced/translating-text-v3?hl=ja
有料のAPIですが、一定文字数までは無料なので、今の使い方であれば無料枠に収まっています。
料金についてはこちらを参照ください。
https://cloud.google.com/translate/pricing?hl=ja
ChatGPT API
ChatGPT APIは、自然言語処理とテキスト生成のための強力なツールです。このAPIを使用して、Qiitaの記事を効率的に要約し、Twitterでの共有に適した形式に変換します。
参考:https://platform.openai.com/docs/quickstart?context=python
最初はgpt-3.5-turboモデルを使用していましたが、11/12からgpt-4-1106-previewを使用しています。
料金や目新しさに応じて、今後も適宜使用も出るは切り替えていく予定です。
これは完全従量制なので費用がかかります。
https://openai.com/pricing#language-models
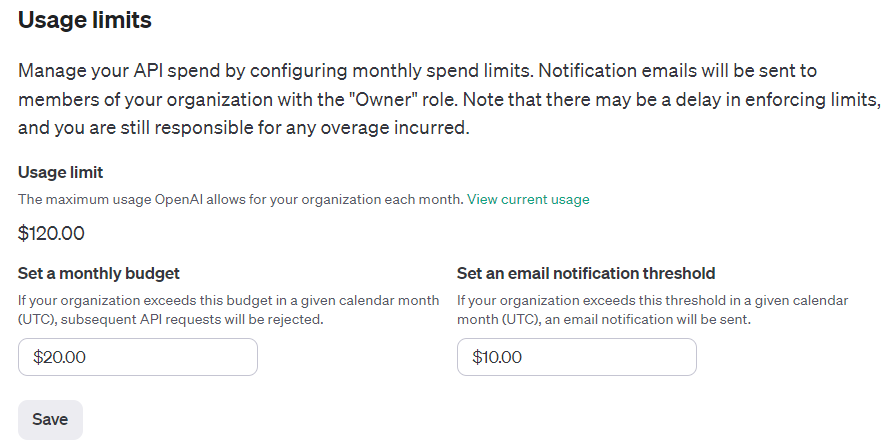
上記の通りgpt-4-1106-previewの使用で、1記事あたり平均$0.02(=$0.6/月)くらいかかっています。
課金上限の設定があるので、API使ってみたいけど費用が心配という方は設定をおすすめします。
Twitter API
Twitter APIを利用して、生成された要約を自動的にX(Twitter)に投稿します。
と言いつつ、直接APIを呼び出さずtweepyを使用しています。
Twitter API v2のOAuth 1.0aで認証し、create_tweetでポストしてます。
いろいろと変更が激しいので、いつどうなるかわかりませんが現状では無料プラン(日本語ドキュメントではEssensial)で登録しています。
https://developer.twitter.com/ja/docs/twitter-api
Cloud Functions for Firebase と スケジュール設定
APIというわけではないですが、定時実行のためこれらの仕組みを利用しました。
https://firebase.google.com/docs/functions?hl=ja
https://firebase.google.com/docs/functions/schedule-functions?hl=ja&gen=2nd
スケジュール設定時、タイムゾーンの設定をしないとUTCになることに注意
00:00 ⇒ 日本時間 午前9時に実行されます。
処理フローとシーケンス図
main.pyは省略
処理フロー
-
mainfunc.pyがqiita.pyを呼び出してQiitaの記事を取得 -
translate.pyで英語に翻訳 -
chatgpt.pyで要約を生成 -
x_twitter.pyでTwitterに投稿
シーケンス図
まとめ
この仕組みで一日一回つぶやいていますので、興味のある方は各投稿本文と生成された紹介文を見比べてみてください。
https://twitter.com/wakuto_kurokawa
この仕組みで2023/10/19に初投稿後、すぐに記事にする予定がなかなか着手できなかったのですが
せっかくのイベントに参加しない手はないなということで、Qiita Advent Calendar のタイミングで投稿することにしました。
おまけ
株式会社ワクトでは、エンジニア積極採用中です!!!
SES、請負、受託、Saleforce やりたい方はご興味を持っていただけたら幸いです。