はじめに
【初投稿】
Qiitaにある記事をタグを指定して取得したいなということでPythonで実装してみました。
そもそも取り組んだ理由として、Livedoorニュースコーパスを使って記事のカテゴリを機械学習で分類していて、同じようなことをQiitaの記事でもできたらいいねというアドバイスをいただいたからです。。。
多少コードの書き方に分かりづらい点があるかもしれませんが、その時はコメントなどで教えてもらえればと思います。
Qiita API について
Qiitaが提供している様々なデータの取得・記事の投稿などができるWeb-APIです。
https://qiita.com/api/v2/docs
記事の取得には上限があり、1度にpageの上限は100、per_page(pageごとに何個記事を取得するか)の上限は100なので、最大10000記事取得できるってわけです。
ただし、ユーザ認証が必要なので、気をつけましょう。
認証している状態ではユーザごとに1時間に1000回まで、認証していない状態ではIPアドレスごとに1時間に60回までリクエストを受け付けます。(Qiita API公式より)
今回は、1ページごとに1記事を合計900記事取得したいので、page=100, per_page=1 x 9回行います。
Qiita APIのアクセストークン取得方法
まずは、ユーザ認証に必要なアクセストークンを取得します。
・「設定」より「アプリケーション」を選択
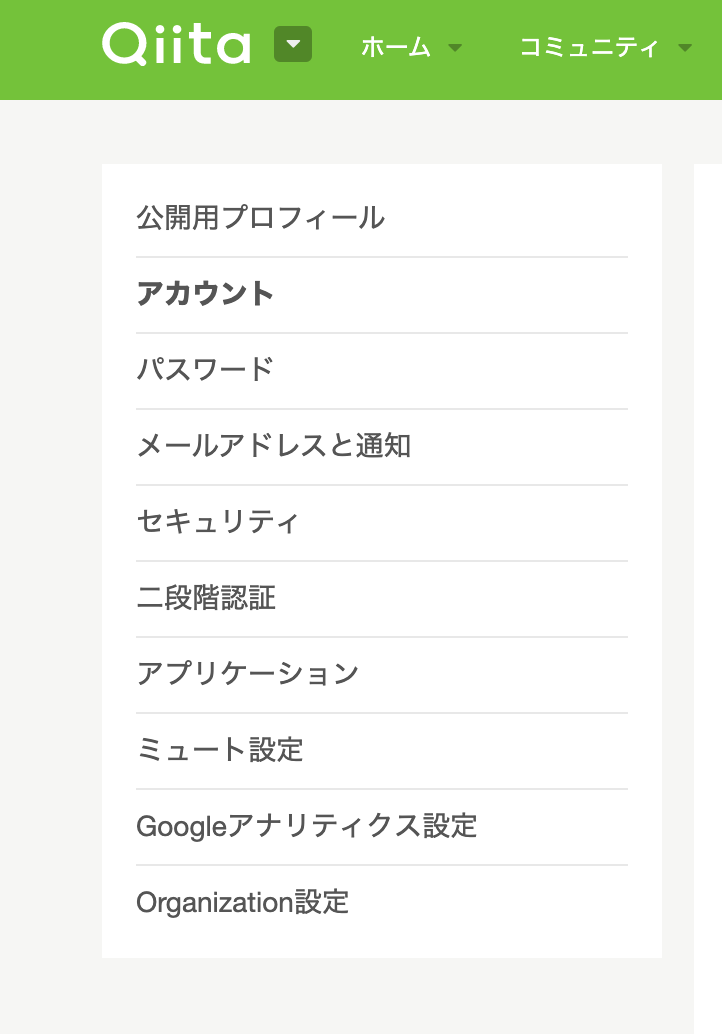
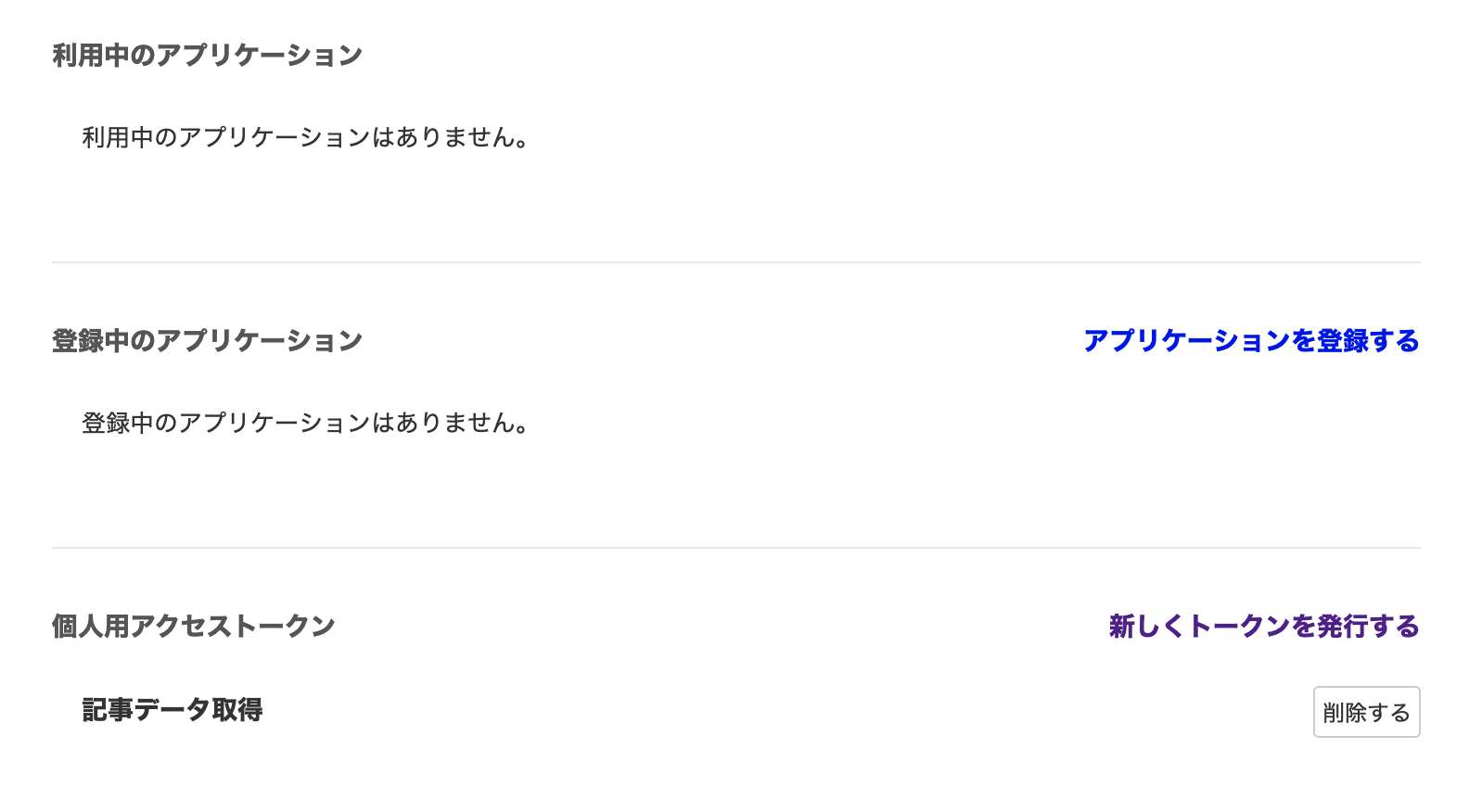
・「個人用アクセストークン」→「新しくトークンを発行する」
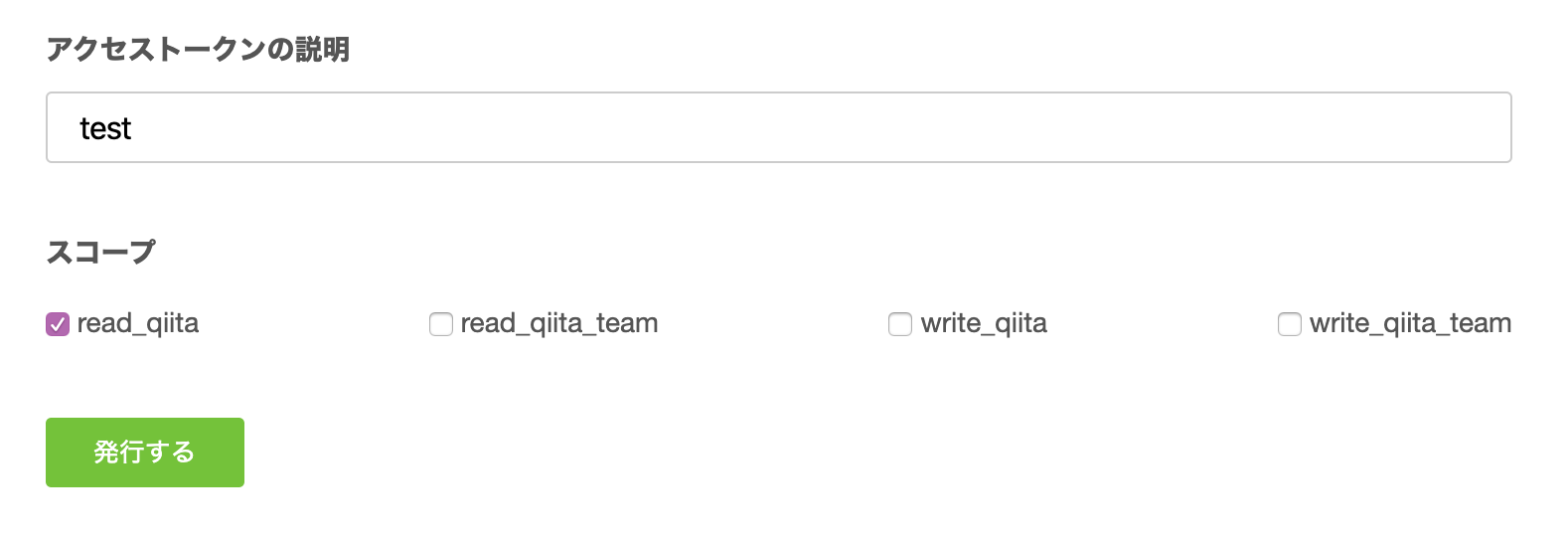
・今回は、read_qiitaのみチェックマークを入れて「発行する」
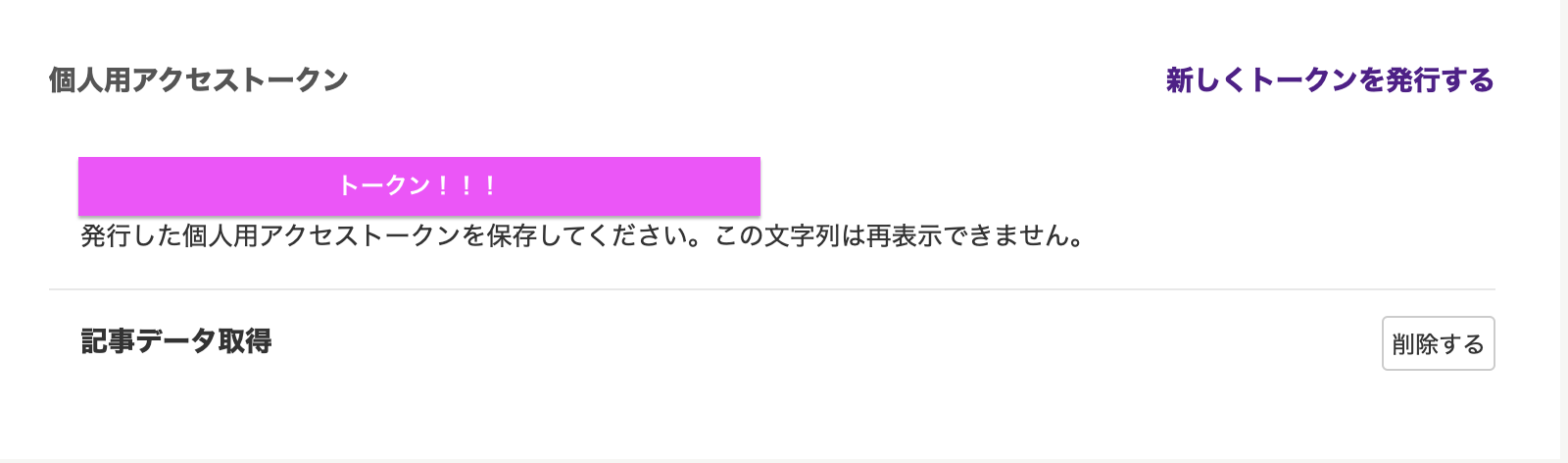
・ トークンが発行されるのでコピー
Qiita APIのユーザ認証を行うコードの例
# ユーザ認証に必要なヘッダー
h = {'Authorization': 'Bearer 【取得したアクセストークン】'}
connect = http.client.HTTPSConnection("qiita.com")
url = "/api/v2/items?"
記事を取得するコードの例
# 取得したいタグを指定
query = "&query=tag%3A" + tag_name
# 検索で指定した期間内に作成された記事数を取得
connect.request("GET", url + query, headers=h)
# 要求に対する応答
res = connect.getresponse()
# 応答の読み出し
res.read()
# サーバーからの応答
print(res.status, res.reason)
total_count = int(res.headers['Total-Count'])
print("total_count: " + str(total_count))
# データを取得してtxtファイルに100個記事を書き出す
for pg in range(100):
pg += 1
page = "page=" + str(pg) + "&per_page=1"
connect.request("GET", url + page + query, headers=h)
res = connect.getresponse()
data = res.read().decode("utf-8")
# jsonファイルのデータをpandas.DataFrame形式で格納
df = pd.read_json(data)
# txtファイルの指定
filename = "./qiita/" + tag_name + "/page/" + str(pg) + ".txt"
# Qiitaの記事からタイトルと本文を取得
df.to_csv(filename, columns=[
'title',
'body',
], header=False, index=False)
print(str(pg) + "/" + str(100) + " 完了")
上記コードの解説
ユーザ認証
ユーザ認証では、ヘッダーに
h = {'Authorization': 'Bearer 【取得したアクセストークン】'}
のように認証のためのトークンを指定してあげる必要があります。
jsonファイルの取得
Qiita APIは、投稿されたデータがjsonファイルになっています。
https://qiita.com/api/v2/docs#%E6%8A%95%E7%A8%BF
取得する際は、pandasライブラリのread_json関数を使ってpandasのDataFrame形式に変換しています。
指定したタグの記事を900個取得するコード
こちらが、コード全体になります。
# ライブラリのインポート
import http.client
import pandas as pd
import time
# 取得したいページ数
TOTAL_PAGE = 900
TIME = int(TOTAL_PAGE / 100)
PER_PAGE = 1
# ユーザ認証
h = {'Authorization': 'Bearer 【取得したアクセストークン】'}
connect = http.client.HTTPSConnection("qiita.com")
url = "/api/v2/items?"
# 指定するタグ
tag_name = "Java"
# カウント変数
num = 0
pg = 0
count = 0
# tag別に記事をPAGEだけ繰り返し取得
query = "&query=tag%3A" + tag_name
# 検索で指定した期間内に作成された記事数を取得
connect.request("GET", url + query, headers=h)
# 要求に対する応答
res = connect.getresponse()
# 応答の読み出し
res.read()
# サーバーからの応答
print(res.status, res.reason)
print("指定しているタグ: " + tag_name)
total_count = int(res.headers['Total-Count'])
print("total_count: " + str(total_count))
# データを取得してtxtファイルに900個記事を書き出す
for count in range(TIME):
count += 1
for pg in range(100):
pg += 1
page = "page=" + str(pg) + "&per_page=" + str(PER_PAGE)
connect.request("GET", url + page + query, headers=h)
res = connect.getresponse()
data = res.read().decode("utf-8")
df = pd.read_json(data)
filename = "./qiita/" + tag_name + "/page" + str(count) + "-" + str(pg) + ".txt"
df.to_csv(filename, columns=[
'title',
'body',
], header=False, index=False)
print(str(count) + ":" + str(pg) + "/" + str(100) + " 完了")
結果
分かりづらいですが、900記事取得できました。

まとめ
今回は、記事のタイトルと本文を指定して取得しましたが、ほかにも「いいね数」「更新日時」なども取得できますので、ほかの項目が欲しい方はQiita API公式を参考にしてやってみてください!
参考資料
・Qiita API 公式
https://qiita.com/api/v2/docs
・Qiitaの記事情報をAPIで取得しCSVに書き出す
https://qiita.com/arai-qiita/items/94902fc0e686e59cb8c5