概要
mecabの辞書を自動コストで作成します。
コストが何なのかはググってもらうことにして、ここでは作成方法しか書きません。
誰かコメントとかで補足してもらえることに期待!
追記
Google Codeのホスティングが終了したのか、下記方法ではダウンロードできなくなりました。
本家に記載しているGoogle Driveから落としてください。
MeCab: Yet Another Part-of-Speech and Morphological Analyzer
準備
mecab
そもそもmecabを入れないとダメなのでmecabを入れます。
といっても私の場合はmroongaを使ってあることをしているので、mroongaのmecabを利用します。
ということなので、mroongaのリポジトリを使ってください。
% sudo yum install -y http://packages.groonga.org/centos/groonga-release-1.1.0-1.noarch.rpm
% sudo yum makecache
% sudo yum install -y mecab mecab-ipadic mecab-devel
モデルファイル
辞書作成時にはある程度の語彙のコストを記録しているモデルファイルが必要です。
mecabの配布先でモデルファイルも配布しているので、それを利用します。
code.google.com
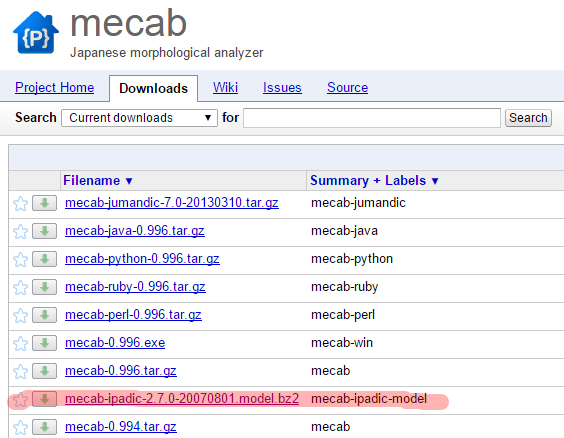
テストなので、このファイルを/tmpフォルダなどにダウンロードして解凍してください。
文字コードもutf-8にしたいので、そこら辺もいじります。
% cd /tmp
% wget https://mecab.googlecode.com/files/mecab-ipadic-2.7.0-20070801.model.bz2
% bzip2 -d mecab-ipadic-2.7.0-20070801.model.bz2
% vi ./mecab-ipadic-2.7.0-20070801.model #6行目を「charset: utf-8」に書き換えてください
% nkf -w --overwrite ./mecab-ipadic-2.7.0-20070801.model #文字コードをutf-8へ変換
辞書作成設定ファイル
辞書作成時にはコストや語彙をどのように解析するかを制御する設定ファイルがあるので、それを準備します。
これもmecab配布先にあるので落としてきます。
code.google.com
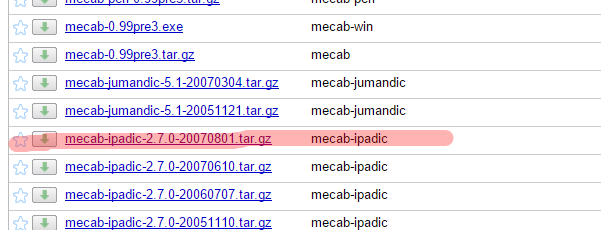
テストなので、これも/tmpなどに落としてください。
これも文字列がeuc-jpとかになっているのでutf-8に変換する処理が必要です。
% cd /tmp
% wget https://mecab.googlecode.com/files/mecab-ipadic-2.7.0-20070801.tar.gz
% tar zxfv ./mecab-ipadic-2.7.0-20070801.tar.gz
% cd ./mecab-ipadic-2.7.0-20070801
% nkf -w --overwrite ./*.def
% ./configure
% make
サンプル辞書データ
なんでもいいです。
私の場合はWikipediaの記事タイトルを辞書として登録したりしています。
その際、Wikipedia.csvとして次のような感じで用意しています。
この時、2~4列目にコストを記述しておくと記述されたコストを優先して辞書が作られるようです。
"ラジオマン",,,,名詞,一般,*,*,*,*,*,*,*,wikiepdia_title
"ラジオマンジャック",,,,名詞,一般,*,*,*,*,*,*,*,wikiepdia_title
"ラジオミセス",,,,名詞,一般,*,*,*,*,*,*,*,wikiepdia_title
辞書作成
ディレクトリ構造としては次のとおりです。
% cd /tmp
% tree -P *.def\|*.model
├── mecab-ipadic-2.7.0-20070801
│ ├── char.def
│ ├── feature.def
│ ├── left-id.def
│ ├── matrix.def
│ ├── pos-id.def
│ ├── rewrite.def
│ ├── right-id.def
│ └── unk.def
├── mecab-ipadic-2.7.0-20070801.model
└── Wikipedia.csv
このようなディレクトリ構造の場合、次のようなコマンドでコストが自動推定されて辞書が作成されます。
% pwd
/tmp
# コストの出力(辞書作成ではないです!)
% /usr/libexec/mecab/mecab-dict-index -m ./mecab-ipadic-2.7.0-20070801.model -d ./mecab-ipadic-2.7.0-20070801 -u ./Wikipedia.dic -f utf-8 -t utf-8 -a ./Wikipedia.csv
% cat ./Wikipedia.dic
・・・
ラジオマン,1285,1285,8922,名詞,一般,*,*,*,*,*,*,*,wikiepdia_title
ラジオマンジャック,1285,1285,8922,名詞,一般,*,*,*,*,*,*,*,wikiepdia_title
ラジオミセス,1285,1285,8922,名詞,一般,*,*,*,*,*,*,*,wikiepdia_title
・・・
# 辞書作成
% /usr/libexec/mecab/mecab-dict-index -m ./mecab-ipadic-2.7.0-20070801.model -d ./mecab-ipadic-2.7.0-20070801 -u ./Wikipedia.dic -f utf-8 -t utf-8 ./Wikipedia.csv
あとは/etc/mecabrcのuerdicとかでよしなにどうぞ。
defファイルをこんなふうにすればすごくいい感じになるよ!とか、そもそもコストとは・・・。といったアドバイスなどがありましたらコメントしてもらえれば勉強できるのでありがたいです。