原論文
- ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases
https://arxiv.org/abs/2103.10697
関連研究
Vison Transformerの解説
https://qiita.com/wakanomi/items/55bba80338615c7cce73
CNN+ViTモデルの傾向【サーベイ】
https://qiita.com/wakayama_90b/items/96bf5d32b09cb0041c39
結論
ViTに近傍バイアスを追加することによって,浅い層で局所的な認識を行う傾向を補助するViT
概要
近年,画像認識分野において,CNNと次に発表されたViTのモデルが覇権を握っており,それぞれ異なるモデル構造をしているため,その認識特徴を異なる.ViTの特徴として,画像全ての情報を並列に処理(self-attention)を行うため,「近い画素は関係が深い」といった機能的バイアスがCNNモデルと比較して小さく,それを補うために,学習には多くの学習データ(3億枚のデータセット(JFT-300M))と計算時間をかけて性能を向上させる必要がある.画像分類タスクのImageNet-1kの場合にViTはCNNより精度が低下する.反対に,3億枚のデータセット(JFT-300M)ではViTの精度が良い.小さいデータセットでは機能的バイアス(近い画素は関係が深い)を強め,大きいデータセットでは機能的バイアスを弱める指標を学習によって調整する.また,ViTの特性として,浅い層では局所的な認識,深い層では大局的な認識を好む傾向にあり,その特性を補助する.これによって,DeiTを上回る精度を達成した.
モデル構造
ConViTはCaiTのように途中からクラストークンを追加する構造である.クラストークンを追加した後は通常のSAの処理を行う.スラストークン追加前は通常10層のGPSAを行う.そこにSAの2層の12層で構成される.
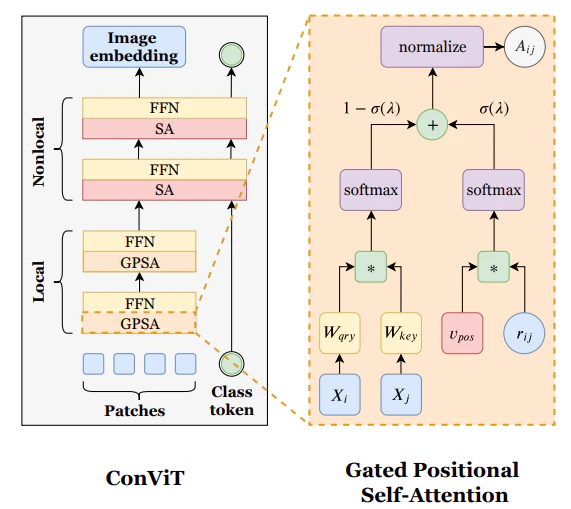
GPSA
GPSA(Gated Positional self-attention)とはself-attention(SA)に近傍バイアスを加えた構造をしめす.通常のSAの式を以下に示す.
A = \mathrm{Softmax}(\frac{QK^T}{\sqrt{d}})\\
SA = A \cdot V
-
GPSAの式を以下に示す.
-
上図右のオレンジの範囲(Gated Positional self-attention)内で,左のクエリとキーの内積計算と,右の$\mathrm{Softmax}(v_{pos}^{hT}r)$計算に分かれている.左は通常($/\sqrt{d}$が無いだけ)のSAで,右は近傍の注目する認識を行なっている.
-
それぞれの処理に$1 - \sigma (\lambda_h)$,$\sigma (\lambda_h)$がかけられる($\sigma$はシグモイド関数(0~1)).
- これは,2つの処理の採用割合を示す
- ($\sigma (\lambda_h)=0.9$)の場合,
- 左ルート(SA)は($1-\sigma (\lambda_h)=0.1$)の値の積をとるため認識結果を重視されない.
- 右ルート(近傍バイアス)は0.9の値の積で重視する
- この割合は,学習可能な$\lambda_h$によって調整される.
A = (1- \sigma (\lambda_h)) \mathrm{Softmax}(QK^T) + \sigma (\lambda_h) \mathrm{Softmax}(v_{pos}^{hT}r)\\
GPSA = \mathrm{Norm} [A] \cdot V
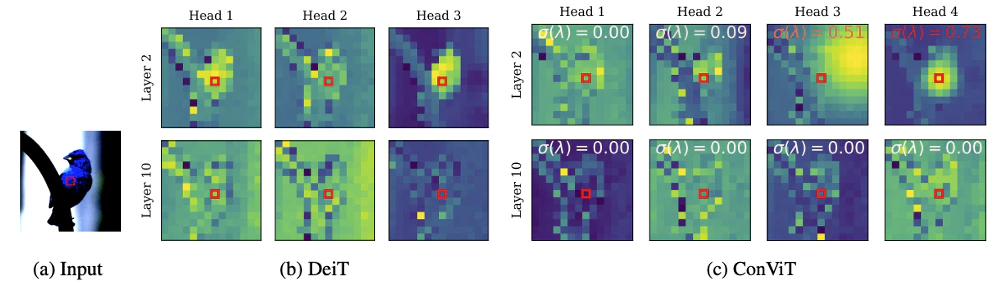
近傍バイアスの可視化
目的通りにいけば,浅い層では$\sigma (\lambda_h)$の値が大きく(近傍バイアスの情報多め),深い層では$\sigma (\lambda_h)$の値が小さく(SAの情報多め)になる.
下図に注目場所を可視化しており,右上の浅い層のConvは$\sigma (\lambda_h)$の値が高く,近傍バイアスが強い傾向になり,深い層では,$\sigma (\lambda_h)=0$で近傍バイアスを使わない傾向が分かった.
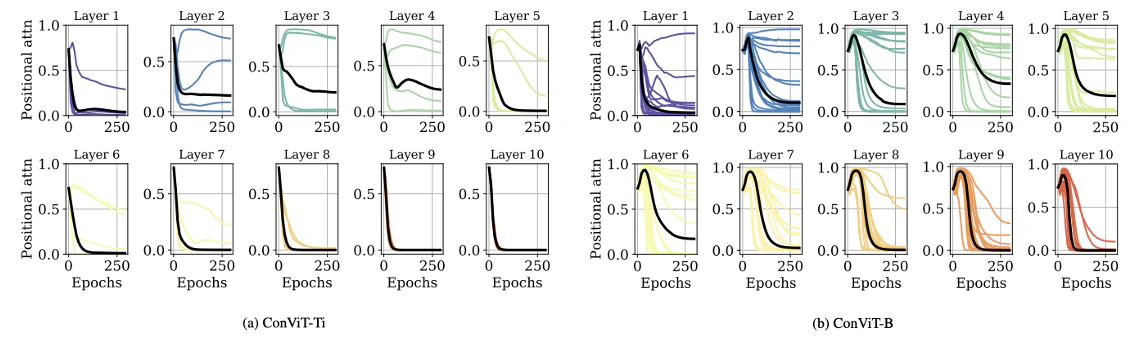
各層の近傍バイアス
各層の近傍バイアスで,縦軸の値が高いほど近傍バイアスが強い.(a)では5層まで近傍バイアスを必要としており,より大きいモデル(b)は7層まで必要としている.
実験
画像分類
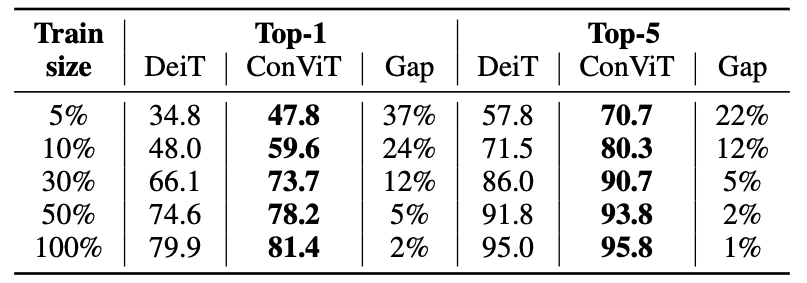
ImageNet-1kでConViTはViT,DeiTを上回る精度を達成した.
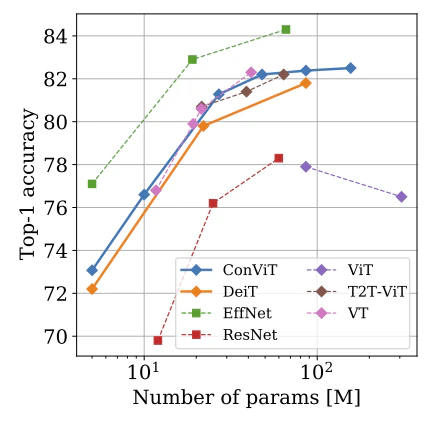
また,ImageNet-1kの画像使用枚数をどの割合で制限したとしてもDeiTの精度を超える(小さいデータセットでも有効).
考察
ViTの特性の浅い層で局所的を行う傾向に補助することで性能が向上する傾向があってSwinもその傾向と一致しているのかなと思いました.
まとめ
今回はConViT: Improving Vision Transformers with Soft Convolutional Inductive Biasesの論文について解説した.ViTに近傍バイアスを追加することによって,浅い層で局所的な認識を行う傾向を補助し,DeiTを上回る精度を達成した.