原論文
PVT v2: Improved Baselines with Pyramid Vision Transformer
https://arxiv.org/abs/2106.13797
関連研究
Vison Transformerの解説
https://qiita.com/wakanomi/items/55bba80338615c7cce73
CNN+ViTモデルの傾向【サーベイ】
https://qiita.com/wakayama_90b/items/96bf5d32b09cb0041c39
PVTの解説(PVTv2の元となったモデル)
https://qiita.com/wakayama_90b/items/77c4c6857210b73e24b8
結論
PVTから以下を改善した.
- 位置埋め込みを削除
- パッチ埋め込みに畳み込みを採用(局所的な認識を補助と特徴量のダウンサンプリング)
- キーとバリューのダウンサンプリングに平均プーリングを採用
- FFNにDWConvの追加(位置情報の保存と性能向上)
概要
ViTの問題に,計算量が膨大であるという問題点がある.この問題をPVT含め,PVTはキーとバリューをダウンサンプリングすることでこの問題を解決する.また,ViTは画像を小領域のパッチに分割し,パッチ間の類似度計算をする認識を行うため,パッチ内の特徴を抽出できず,画像の細かい認識が苦手である問題点もある.これをViTの構造に細かい認識が得意な畳み込み層を組み込むことにより,ViTの認識を補助する.
ViTにはパッチの情報を並列に処理するため,パッチの位置を保存するために,位置埋め込みを行う.しかし,位置埋め込みによる性能低下する可能性がある.PVTv2は,FNNに畳み込み層を追加することにより,位置情報を保存の役割をすることにより,位置埋め込みを削除する.
モデル構造
PVTv2のモデル構造はPVTを元としたステージ4の階層型モデルが採用されている.以下に変更点を示す.
- 位置埋め込みを削除
- パッチ埋め込みに畳み込みを採用(局所的な認識を補助と特徴量のダウンサンプリング)
- キーとバリューのダウンサンプリングに平均プーリングを採用
- FFNにDWConvの追加(位置情報の保存と性能向上)
(注)以下のモデル構造はPVTv1
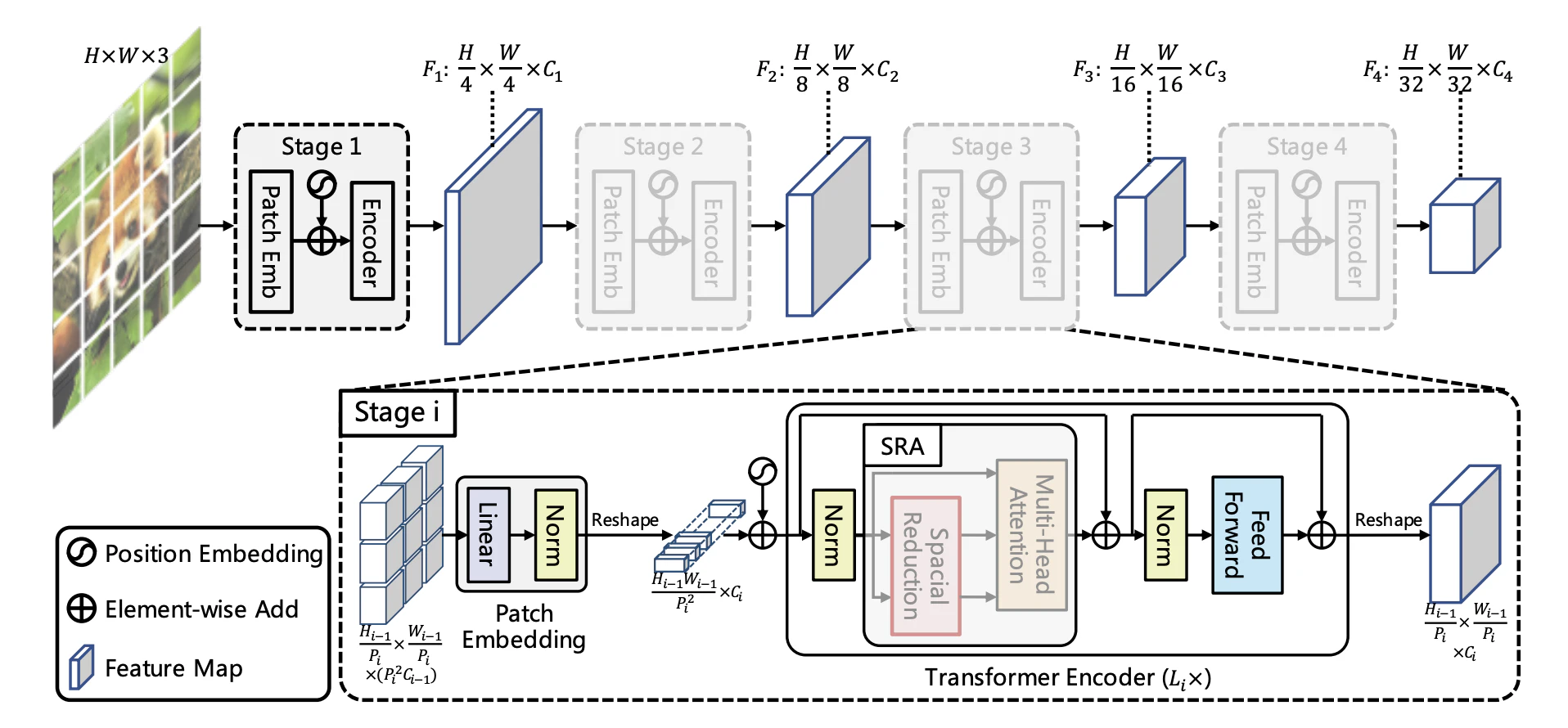
パッチ埋め込みとFNNの改良

パッチ埋め込み(a)
畳み込み処理でカーネルのサイズを大きくする.また,0パディング(特徴量の外周に0の値を付与する).特徴を抽出をオーバーラップさせる.オーバーラップとは,重複するようにカーネル(フィルタ)を通す.
図(a)の上段のPVTv1は特徴抽出で赤い範囲をずらした時に他と被らないようにする.下段のPVTv2は赤い範囲を被るように移動させる.
FFN(b)
カーネル3,パディング1のDWConvを追加する.PVTv2は位置埋め込みを行なっていない.これを,FFNに追加したDWConvを用いて位置情報の保存の役割をする.
実験結果
画像分類,物体検出,セグメンテーションで良い精度.
まとめ
今回は,ViTのキーとバリューを小さくするPVTの進化【PVTv2】について解説した.
PVTを改善して良くなった.