原論文
- How Do Vision Transformers Work?
https://arxiv.org/abs/2202.06709
動画解説
- How do Vision Transformers work? – Paper explained | multi-head self-attention & convolutions
https://www.youtube.com/watch?v=dOwRXpSSc8E
関連研究
ResNetの解説
https://qiita.com/wakanomi/items/7bc4ebc2b3790fea90b9
ViTの解説
https://qiita.com/wakanomi/items/55bba80338615c7cce73
CNN+ViTモデルの傾向【サーベイ】
https://qiita.com/wakayama_90b/items/96bf5d32b09cb0041c39
結論
CNNベースであるResNetとViTの比較で,ResNetは高周波フィルタ,ViTは低周波フィルタの役割をする.また,ResNetのロスランドスケープは凸損失,ViTは非凸損失を示す.
概要
画像認識分野において2強であるCNNとViTは画像の特徴抽出方法が全く異なるため,当然に認識特性も異なる.そこで,CNNとViTでどのような認識特性の違いがあるかを特徴マップを解析して調査した結果,ViTは低周波フィルタの役割をすることが分かった.また,モデルの持つ重みを最適化するロスの値を3Dに可視化したロスランドスケープの違いについてはCNNが凸損失,ViTは非凸損失を示す.
認識特性の違い
畳み込みの認識でハイパスフィルタを通過したような出力,SAの認識でローパスフィルタを通過したような出力を示す.テクスチャ重視,形状重視の傾向は「Intriguing Properties of Vision Transformers」の論文に示されており,その結果と一致する.

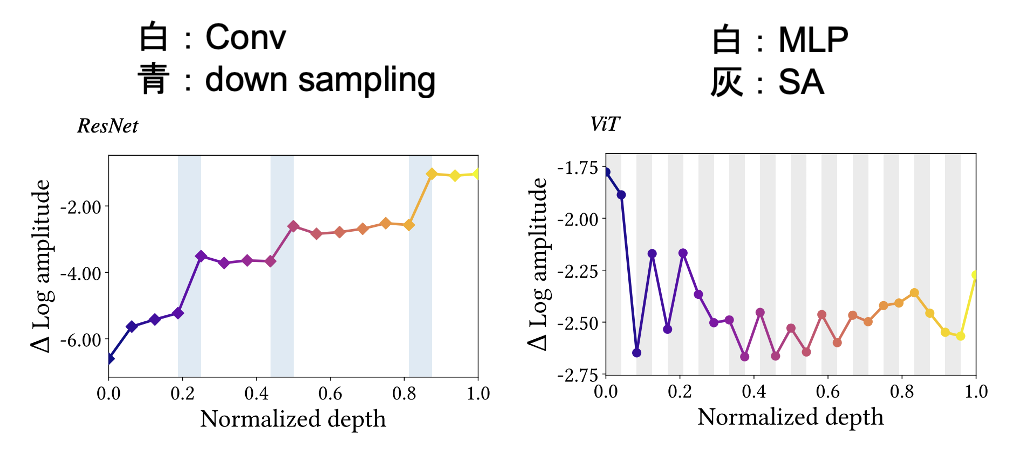
各層の特徴マップの特徴
各層の特徴マップをフーリエ解析した結果であり,縦軸に周波数成分(上が高周波,下が低周波)横軸に層の深さ(右に深い層)を示す.ResNetでは,白色のConv(畳み込み)の処理で高周波成分が増加する(高周波フィルタの役割).ResNetは全体的に,層が深くなるにつれて高周波成分を増加させる(低周波成分を増加させる機構がない).
ViTの中間層から後半層では,灰色のSA(self-attention)の処理で低周波成分を増加させる.白色のMLPは高周波成分を増加させる.
ここで,面白いのはViTの浅い層では, SAの処理で高周波成分を増加させている.これはViTの特性としてViTの浅い層は局所的な認識を行う畳み込み処理のような特徴抽出をする傾向から,この結果となる.
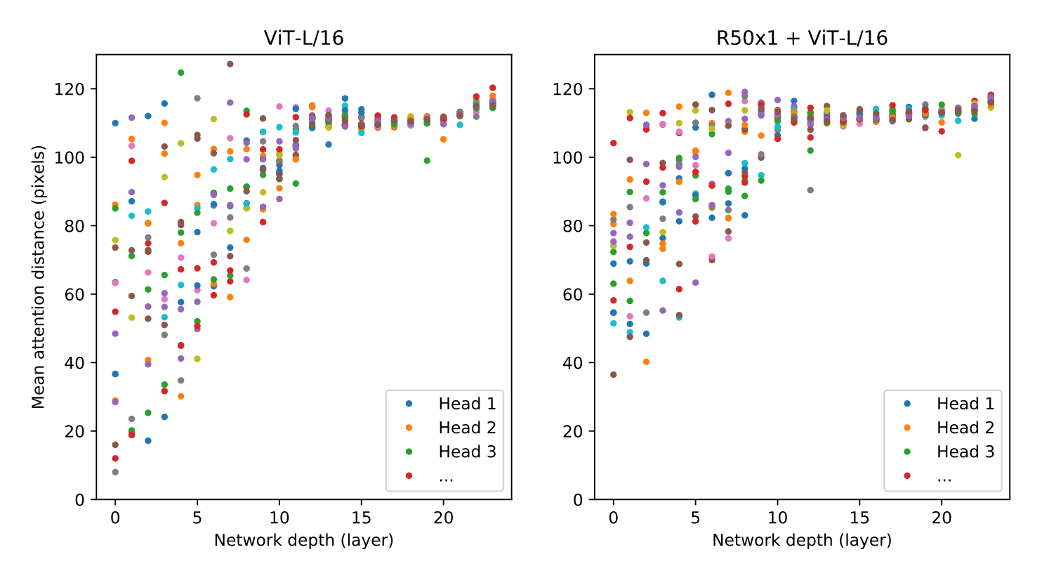
hybrid ViTの傾向
ViTの原論文にパッチ特徴量をResNet50のステージ3までの処理を使用して出力するhybrid ViTがあり,通常のViTとhybrid ViTの層ごとの受容野(SAの類似度計算でattentionの重みを強く示した距離の平均)を示す.本来,広い受容野を得意とするViTであるが,通常のViTでは浅い層で狭い受容野(局所的な認識)を好む傾向にあり,CNNのような認識を行うことになる.hybrid ViTでは,パッチ特徴量出力の段階で局所的な認識をある程度完了しているため,SAの処理では浅い層から大局的な認識を行う.
ViTの特性として,浅い層ではCNNのような認識,深い層ではSAの力を発揮する.
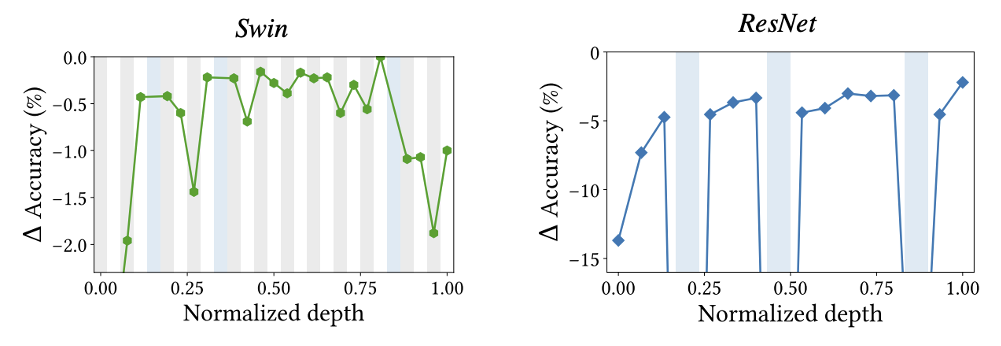
モデルで重要な認識はどこで?
学習済みモデルの一部を取り出した精度を示す.ResNetはボトルネック機構の($3\times 3$)畳み込み,SwinはSAとMLP.横軸に取り出した機構の深さを示す.ResNetでは浅い層のConvを削除すると精度が大きく低下する.
Swinでは最終ステージのSAを処理を削除すると著しく精度が低下する.
CNN(畳み込み)は浅い層の認識が重要,Swinを含むViT(SA)は深い層の認識が重要であり,ステージ内でも前半に畳み込みが重要で,後半にSAが重要である.
スクリーンショット 2023-05-29 11.50.45
ノイズの頑健性の違い
画像に低周波から高周波のノイズを付与してその頑健性の調査で,低周波ノイズには高周波な認識を行うResNetが強く,高周波ノイズには低周波な認識を行うViTが強い.

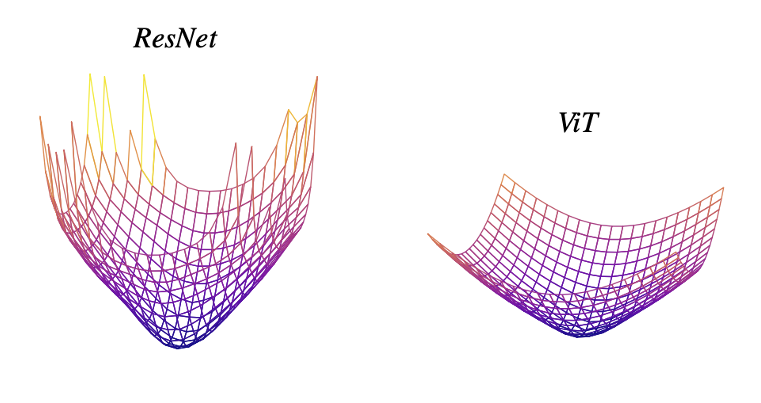
Loss landscape visualizations
学習によってロスが最も小さくなるような重みパラメータを探索する.(局所的最小値に坂を使ってボールが転がり落ちるような表現)
ロス関数を3Dに可視化したもので,ResNetは凸損失,ViTは非凸損失である.非凸損失はデータの頑健性が高いメリットがあり,ボールを落とす速度のように損失を小さくするためのスピードが遅く,大規模な学習と平滑化手法で問題を解決する.
Loss landscape visualizationsはViTのような非凸損失になることを目指しているが,ViTには負のへシアン固有値がある問題点がある.
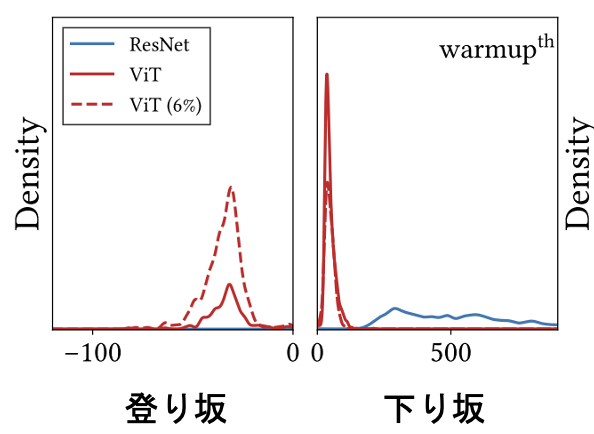
へシアン固有値
へシアン固有値とは,ロスの登り坂と下り坂の方向数と強さを示す.縦軸に個数,横軸に右が強い下坂,左に強い登り坂を示す.ViTはResNetより緩やかな下り坂なため,正のへシアン固有値の値が小さい.これは良い傾向である.ViTの問題は負のへシアン固有値があることであり,下り坂は緩やかであるが,実際は所々に登り坂があり,表面が凸凹している状態である.この凸凹は重みの最適化に有効だとは言えない.反対に,CNNは正のへシアン固有値は高いが,負のへシアン固有値がほとんどない.
理想系として,ViTのような小さい正の固有値とCNNのような負の固有値がほとんどないモデルである.
ViTで理想のへシアン固有値にする工夫
ViTの構造から,クラストークンをGAPに変更,ヘッドあたりの埋め込み次元の変更,ヘッド数の変更,パッチサイズの変更を行ったが,多少の変化はあったものの,根本的な解決には至らなかった.

畳み込みとSAを組み合わせモデルの構造
ResNetの階層型モデル構造にSAを追加するモデル構造にする.SAを導入する.分析の結果からCNN(畳み込み)は浅い層の認識が重要,Swinを含むViT(SA)は深い層の認識が重要であり,ステージ内でも前半に畳み込みが重要で,後半にSAが重要であることが分かったので,後半3つのステージにSA,最後のステージはSAを2つをConvと入れ替える.これによって,CIFAR-100の精度がViT,ResNetと比較して向上した結果になった.

考察
CNNとViTにはそれぞれ異なる認識特性を持つ.今回,説明した違い以外にも受容野やデータセットの影響などにも違いがあり,それらの得意不得意を補完するようにCNNとViTの組み合わせるのは,良い方向性かも.
まとめ
今回は,「how do vision transformers work?」の論文について解説した.CNNベースであるResNetとViTの比較で,ResNetは高周波フィルタ,ViTは低周波フィルタの役割をする.また,ResNetのロスランドスケープは凸損失,ViTは非凸損失を示す.