原論文
-
The origins and prevalence of texture bias in convolutional neural networks
https://arxiv.org/abs/1911.09071 -
Are convolutional neural networks or transformers more like human vision?
https://arxiv.org/abs/2105.07197 -
Intriguing Properties of Vision Transformers
https://arxiv.org/abs/2105.10497 -
IMAGENET-TRAINED CNNS ARE BIASED TOWARDS TEXTURE; INCREASING SHAPE BIAS IMPROVES ACCURACY AND ROBUSTNESS
https://arxiv.org/pdf/1811.12231.pdf -
Deep convolutional networks do not classify based on global object shape
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6306249/
日本語解説
-
CNNは本当にテクスチャ好きなのか?
https://ai-scholar.tech/articles/image-recognition/texture -
CNNやTransformerは人間の視覚と比べてどうなのか?
https://ai-scholar.tech/articles/transformer/human_vision -
Vision transformersの魅力的な特性とは?
https://ai-scholar.tech/articles/transformer/intriguing-properties-ViT -
論文紹介: ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness
https://qiita.com/f0o0o/items/eb1e86d11318aeb54109
関連研究
CNNとViTのノイズへの頑健性の違い
https://qiita.com/wakayama_90b/items/a9b931c8cfff990c542a
CNN+ViTモデルの傾向【サーベイ】
https://qiita.com/wakayama_90b/items/96bf5d32b09cb0041c39
結論
右の画像を見て,人間は猫,ViTは猫,CNNは象と答える.
形状重視だからって性能が向上するわけではない.

認識対象を形状で捉えるか?テクスチャで捉えるか?
評価方法
画像認識モデルが画像のテクスチャの情報を捉えているのか,形状の情報を捉えているのかをSIN Datasetを用いて評価する.SIN Datasetとは,上図のように,猫の画像をGenerative Adversarial Network (GAN) を用
いて象のテクスチャに変換したように,シルエットとテクスチャを別にした画像のデータセットである.例えば,モデルが猫と認識した場合は,認識対象の形状を重視する.象と認識した場合は,認識対象のテクスチャを重視する.
ViTとCNNの認識特性の違い
【Are convolutional neural networks or transformers more like human vision?】
下図のプロットは左にあれば形状重視,左にあればテクスチャ重視である.各色の縦線は平均値を示す.
オレンジや黄色のViTモデルは,CNNベースのモデルと比較して形状重視である.また,赤色で示す人間の認識は極端に形状重視である.(人間はシルエットクイズが得意であることがわかる.逆に,テクスチャ情報のみの超ドアップ画像はよく分からない.)人間の認識に近いモデルはViTである.

モデル構造から導く
CNNはモデル構造上,カーネルの範囲で特徴抽出をするため,局所的な認識をする.反対にViTは画像全体を並列に特徴抽出するため,受容野が画像全体で大局的な認識をする.
下図の場合,画像の局所的な認識をすると左:N,右:Eと認識し,画像全体で見ると,左:J,右:Kと認識する.
局所的な認識をするモデルはテクスチャを重視し,大局的な認識をするモデルは形状を重視する.
モデルの構造から,テクスチャか形状の認識かのバイアスが決まる.

Datasetから導く
画像認識モデルに入力される学習用画像に,様々な変換(データ拡張)をかけて学習する.画像に色の歪み,ノイズ,ブラーなどのデータ拡張は,テクスチャバイアスを大幅に減少させ,ランダムな切り出しなどのデータ拡張は,テクスチャバイアスを増加させる.ノイズなどは画像のテクスチャ情報を邪魔するするように働く,これにより,ノイズを含んだ画像を学習するモデルはテクスチャバイアスを低下させる.また,画像を切り出すことは大局的な認識を邪魔するように働く,このモデルは大局的な認識ができずに,形状バイアスを低下させる.
SIN Datasetで学習
【Intriguing Properties of Vision Transformers】
データセットによりモデルの認識特性が変化することが分かっている.1番上の右,猫と象の画像で正解ラベルを猫として学習させる.つまり,テクスチャ情報を使用しないで学習する.下図から,SIN Datasetで学習したオレンジと赤は,極端に形状重視の傾向がある.これは,ほぼ人間の認識特性と類似する.

また,形状重視なモデルは認識対象の形状をうまく捉えており,認識対象を捉えることができる.これは,セグメンテーションタスクにおいて有効である.

CNN分析
【Deep convolutional networks do not classify based on global object shape】
CNNはテクスチャを重視する認識をするため,下図のようなシルエット,アウトライン,ガラス細工,テクスチャ情報変更した画像の認識が困難であることが分かっている.

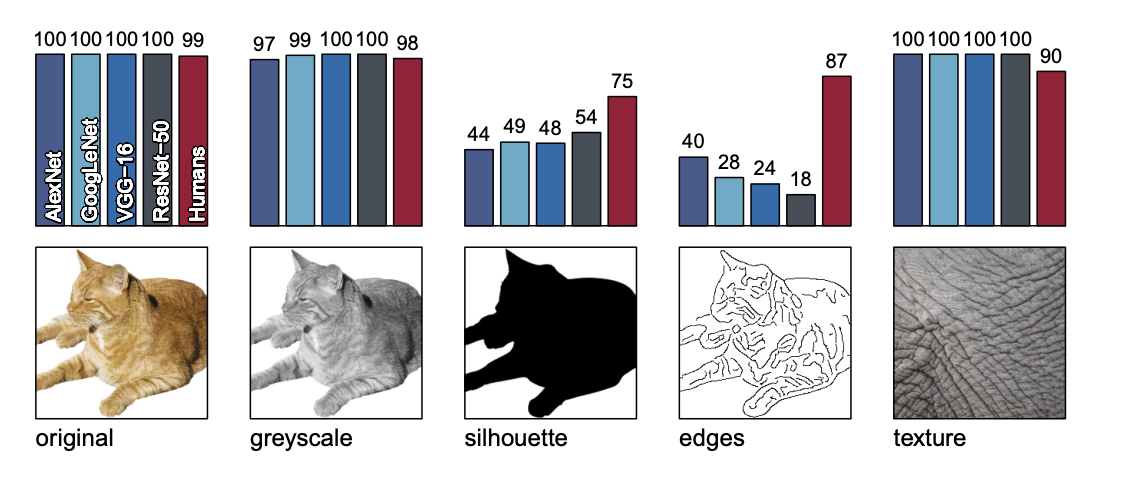
【IMAGENET-TRAINED CNNS ARE BIASED TOWARDS TEXTURE; INCREASING SHAPE BIAS IMPROVES ACCURACY AND ROBUSTNESS】
また,各モデルが全て正解した画像を用いて4つのCNNモデル+人で分析する.オリジナル画像,グレースケール,テクスチャの画像は人と同程度の精度だが,シルエットとエッジ画像は精度低下する.
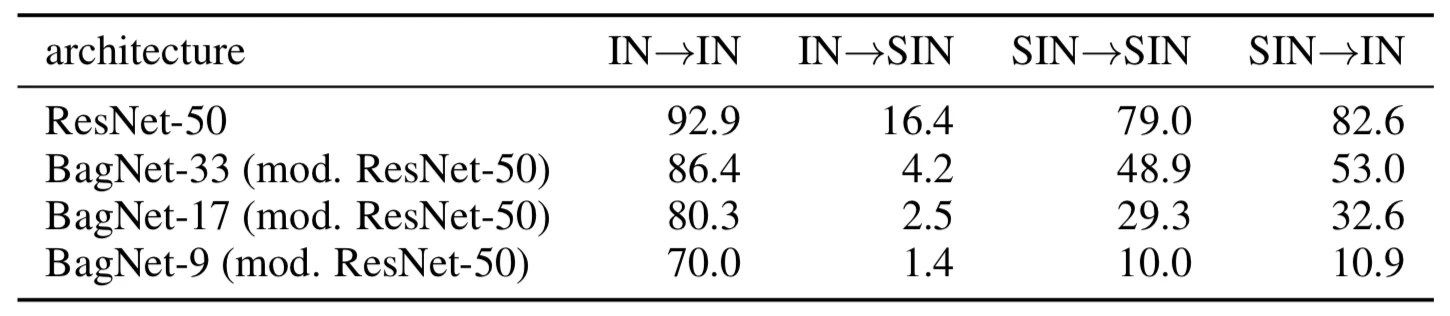
局所的な受容野とSIN Dataset評価
1番上の画像の正解ラベルを猫として学習,評価する.つまり,テクスチャ情報を使用せずに学習する.
最上段のResNet50は,IN(ImageNet),で学習してSINで評価する場合に精度が大きく低下する.また,SINで学習してINで評価しても精度は大きく低下しない.このことから,形状を捉えるような学習をするとImageNetに通用するモデルが完成する.
また,下段にいくと受容野の制限されたCNNモデルを示す.BagNet-33は受容野が($33 \times 33$)である.下段にいくにつれて,SINを使用した評価の精度が 順に低下する.このことから,SINは局所的な認識だけでは精度が低下し,大局的な認識が重要であることが分かる.
また,SINで学習したモデルは形状重視を強める.
下図で赤:人,黄色:SIN-ResNet,灰:ResNet.

データセットの変更と変化
【The Origins and Prevalence of Texture Bias in Convolutional Neural Networks】
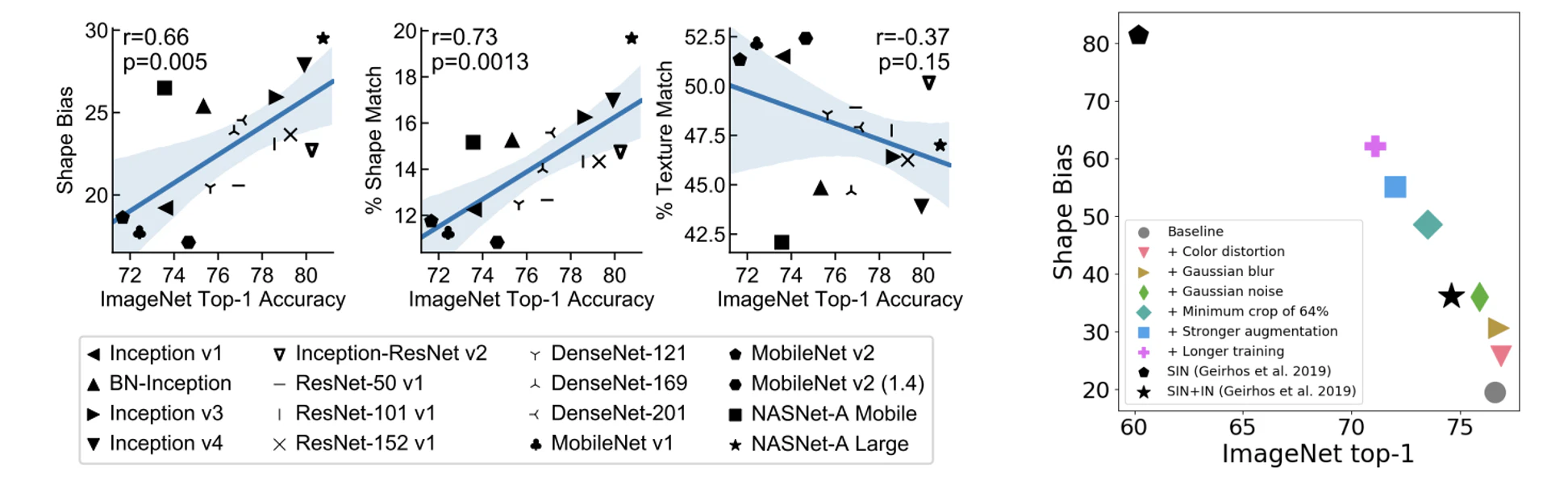
CNNの分析の結果,データ拡張方法を変更した場合に認識特性が変化した.色の歪みやノイズなどは形状バイアスを増加,ランダムクロップはテクスチャバイアスを増加させることが分かった.
下図の左から,ImageNetで優れた精度を発揮するモデルは形状バイアスが強い相関がみられた.しかし,右の図でデータ拡張と形状バイアスの関係を示し,形状バイアスが小さい方が精度向上している.2つの結果は対象的な結果を示し,一概にも形状重視しているモデルが有効だとは限らないことが分かる.
まとめ
今回は,CNNとViTの認識特性の違いをテクスチャ重視か形状重視かの面から解説した.「形状重視だからいい」とかではないらしい.認識特性を理解することが大切である.データセットによって最適なモデルを選択できるようになったらいいなと思う.