原論文
Vision Transformer with Deformable Attention
https://arxiv.org/abs/2201.00520
日本語解説
Swin Transformerを超える最先端画像認識モデルDeformable Attention Transformerを詳細解説!
https://deepsquare.jp/2022/01/deformable-vision-transformer/
【論文メモ】Deformable Attention Transformer
https://yuiga.dev/blog/posts/deformable_attention_transformer/
関連研究
Vison Transformerの解説
https://qiita.com/wakanomi/items/55bba80338615c7cce73
CNN+ViTモデルの傾向【サーベイ】
https://qiita.com/wakayama_90b/items/96bf5d32b09cb0041c39
Swin Transformerの解説
https://qiita.com/wakanomi/items/8fcedaaae7c8f4d94abd
結論
Swin Transformerでは受容野が正方形状になっていたが,正方形は決して最適ではない.その受容野の正方形を学習によって変形し,より関係のある範囲を受容野として学習する.
概要
近年,Attention機構を利用したVison Transformer発表され,画像認識分野の代表的なモデルとなった.しかし,ViTのデメリットとして,画像全ての関係性を求めるため,計算コストが膨大であり,近い画素は関係が深いというような帰納的バイアスがなく,大量のデータで学習することでしかCNNを超える精度を達成できない問題点がある.さらに,関係のない場所の情報が特徴抽出に影響してしまう可能性もある.
そこで,self-attrntionの範囲を制限するSwin Transformerが発表された.Swinは画像全体をSelf-Attentionの計算を行うのではなく,画像を小領域に分割し,小領域内でSelf-Attentionを行う.
SwinはViTと比較して,ImageNet-1kにおいて精度向上したが,小領域内での関係性しか取得出来ずに大局的な関係性の情報が失われる可能性がある.
Swinのように人の手で決めたself-attentionの受容野では,重要な情報を取りこぼしてしまうかもしれない.
その問題を解決するために,Deformable Attention Transformer(DAT)が提案された.self-attentionの範囲を制限する際に,より関係がある領域を選択できるようなDeformable self-attention(変形可能なセルフアテンション)を利用するように改良したモデルである.つまり,self-attentionの範囲をより柔軟にコントロールできるモデルである.
これにより,Swinを上回る精度を叩き出し,クラス分類,物体検出,セグメンテーションタスクにおいてSOTAを達成した.
DATとその周辺
(a)ViT(Vison Transformer)は画像全体を受容野として,self-attentionを行うことで大局的な特徴を捉える.
(b)Swin Transformerは受容野を制限し,self-attentionの処理を行う.
(c)DCN(Deformable Convolution Networks)はCNNベースであり,変形可能な受容野を行うモデルである.
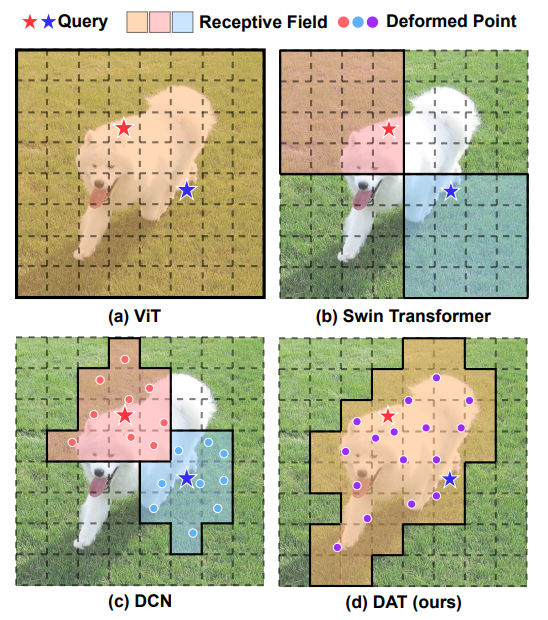
モデル構造
全体的なモデル構造としてResNetのような4ステージの階層型を採用している.ステージが進むにつれて,特徴マップの空間サイズが半分になり,チャンネル数が倍になる.このステージ間のダウンサンプリングは畳み込み層を使用する.(k=カーネルサイズ,s=ストライド).
最初に処理を行う4x4の畳み込みは画像サイズを1/4にダウンサンプリングして計算量を削減する.
ステージ1,2ではlocal AttentionとShift-Window Attentionを採用する.これらはSwin Transformerで使用されている受容野を制限したself-attentionの認識方法である.
ステージ3,4ではlocal AttentionとDeformable Attentionを採用する.ローカルな認識とグローバルな認識を交互に行い精度向上に貢献する.
後半の処理のみにDeformable Attentionを採用する理由として,ViTモデルの特徴として認識初期にはローカルな認識を好む傾向にあることと計算量を削減するために後半のみにDeformable Attentionを採用する.

Deformable attention module
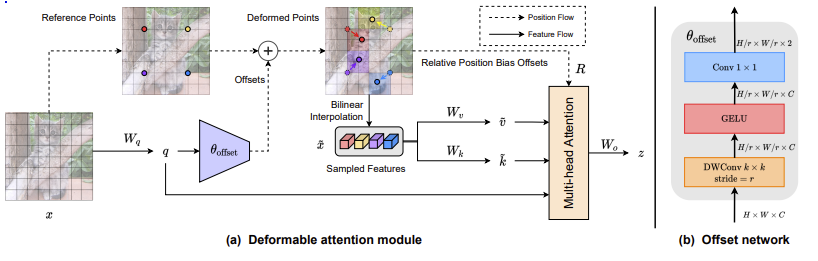
入力画像x($H \times W \times C$)として,Reference Points(参照点)を$Hg \times Wg$(Hg=H/r,Wg=W/r)個つける.rは人手で決定する値である.この図では4点あるが実際は$Hg \times Wg$個ある.
入力画像xを線形変換してq(クエリ)を獲得する.クエリをオフセットネットワークに入力する.
オフセットネットワーク
図の右に示す2つの畳み込みと間にGelU関数を使用する.
はじめに,空間情報を畳み込むDW畳み込みで,ここの畳み込みのカーネルをrにする.rは参照点の数を決める際に使用した値のrを使用する.つまり,特徴マップの空間を参照点と同じ数である$Hg \times Wg$に変換する.
チャンネル方向に畳み込む1x1の畳み込みはチャンネル数2に圧縮する.
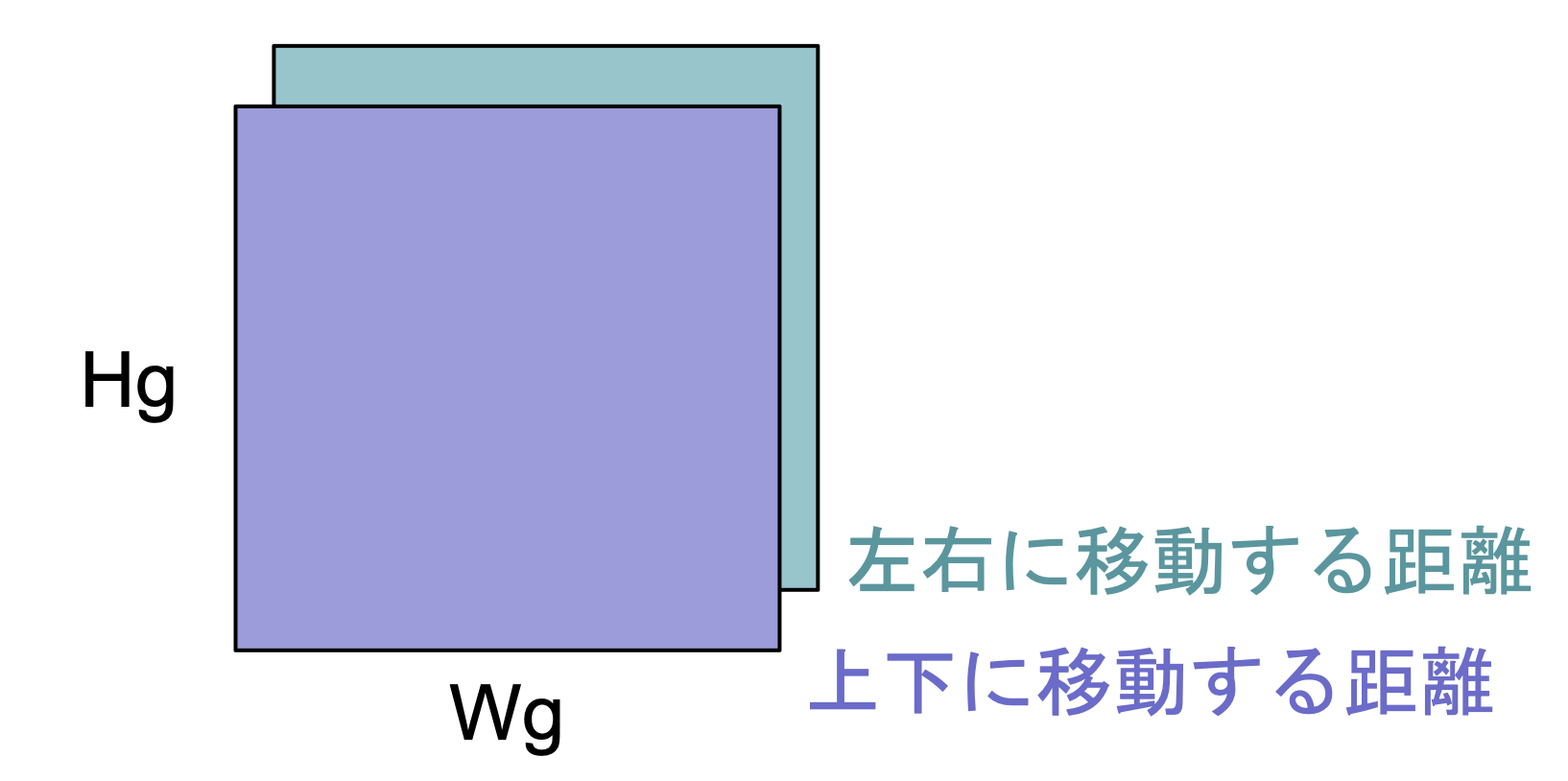
2つの$Hg \times Wg$の特徴マップにはそれぞれの参照点に対応した上下に移動する距離と左右に移動する距離の値が格納される.
キーとバリューの決定
オフセットネットワークで決定した値を使用して参照点を移動させる.
移動させた先の参照点の値をバイリニア補完で決定する.
参照点が決定した値を使用して特徴マップ$\tilde{x}$($Hg \times Wg \times C$)を作成し,$\tilde{x}$から線形変換してキーとバリューとする.
Multi-head Attention
入力のクエリ,キーバリューは以下の式で導く
q = xW_q, \tilde{k} = \tilde{x}W_k, \tilde{v} = \tilde{x}W_v
self attentionは以下の式に示す.BはDeformable relative position biasを示し,swinにも使われる相対的位置バイアスを使用する.
z^{(m)} = \mathrm{Softmax} \left( q^{(m)} \tilde{k}^{(m)^T} / \sqrt{d} + \phi (\tilde{B};R) \right) \tilde{v}^{(m)}
実験結果
画像分類(ImageNet-1K),物体検出(COCO),セグメンテーション(ADE20K)タスクにおいて従来手法を超える精度を達成する.
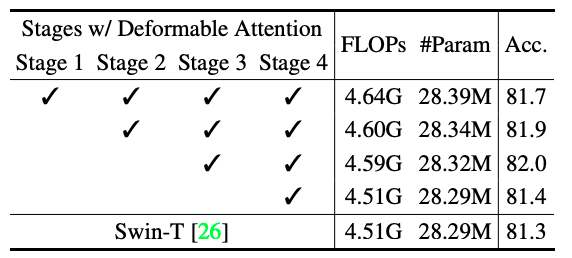
Deformable Attentionの採用するステージ
ImageNet-1kの分類タスクのDeformable Attentionの採用するステージで
ステージ3,4に採用することで精度が高いことがわかる.
可視化実験
上段にDAT,下段にSwinの参照点を可視化例を示す.下段では,正方形に参照点になり,前景と背景の区別ができない.上段では,キリンに参照点が移動し,さらに,別のキリンにも注意を払う.
Swinのサーフボードでは,クエリに対してほとんどがサーフボードを参照できていないことがわかる.
認識対象に参照点が寄ることにより,計算量を削減しながらより優れた認識を行う.

まとめ
今回はDeformable Attention Transformer(DAT)した.
Deformable Attention Transformer(DAT)は変形可能な受容野を使用してself-attentionを行うことで,ViTと比較して計算量の削減や優れた認識を行うモデルであり,様々なタスクで精度向上を見せた.
ViTの問題を解決するような取り組みは今後もされてくると思うので,頑張ろう!