原論文
P2T: Pyramid Pooling Transformer for Scene Understanding
https://arxiv.org/abs/2106.12011
関連研究
Vison Transformerの解説
https://qiita.com/wakanomi/items/55bba80338615c7cce73
PVTの解説
https://qiita.com/wakayama_90b/items/77c4c6857210b73e24b8
CNN+ViTモデルの傾向【サーベイ】
https://qiita.com/wakayama_90b/items/96bf5d32b09cb0041c39
結論
ViTの計算量削減のためにキーとバリューをPyramid Poolingと畳み込みを使用してダウンサンプリングする.
概要
ViTの問題点として,計算量が膨大である問題点がある.それを解決するために,P2Tは,キーとバリューをダウンサンプリングする.ダウンサンプリングにはPyramid Poolingと畳み込みを使用する.
モデル構造
モデル構造として,4ステージの階層型モデル構造を採用している.最初の処理はに$7 \times 7$の畳み込みを採用して特徴抽出を行う.これは,局所的な認識の補助と特徴量のダウンサンプリングで計算量の削減効果がある.


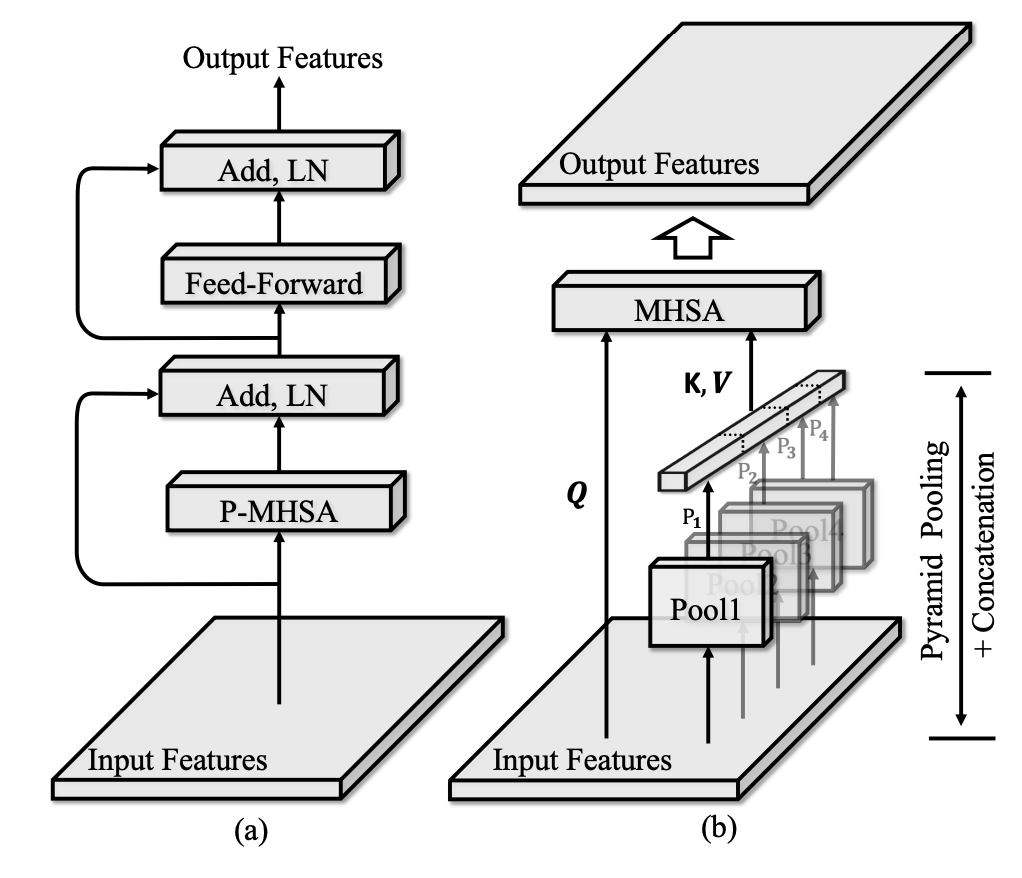
Pyramid Pooling Transformer
Pyramid Pooling Transformerの構造としてViTのTransformer encoderと同様な構造を持つ.
左の図から空間認識のSA,チャンネル方向認識のMLPを交互に認識する構造である.
右の図では,KとVのダウンサンプリングのためにをPyramid Pooling+畳み込みをする.
KとVをダウンサンプリングすることで計算量の削減する.
Pyramid Poolingは以下のurlで解説します.
https://qiita.com/wakayama_90b/items/c023816fc8481b4f9fbb
まとめ
今回はViTのKとVをPyramid Poolingで計算量削減【P2T】について解説した.
KとVのダウンサンプリングで計算量を削減する.ダウンサンプリング方法は,様々あるのでその1種にPyramid Pooling+convがある.