原論文
- MaxViT: Multi-Axis Vision Transformer
https://arxiv.org/abs/2204.01697
日本語解説
- [論文メモ] MaxViT: Multi-Axis Vision Transformer
https://ninhydrin.hatenablog.com/entry/2022/04/07/095517
関連研究
Vison Transformerの解説
https://qiita.com/wakanomi/items/55bba80338615c7cce73
CNN+ViTモデルの傾向【サーベイ】
https://qiita.com/wakayama_90b/items/96bf5d32b09cb0041c39
Swin Transformerの解説
https://qiita.com/wakanomi/items/8fcedaaae7c8f4d94abd
結論
SwinのようなローカルなSAとそのwindowの分割方法を工夫したグローバルなSAをするViT
概要
ViTモデルはCNNモデル(カーネルサイズの範囲の特徴抽出)と比較して機能的バイアス(近い画素は関係が深い)が小さい.そのため,性能を向上させるために大量の学習データと膨大な計算量が必要がある.ViTの派生モデルとしてSwin Transformerがあり,Swinはself-attentionの処理の範囲を制限するWindowを採用し,計算量を削減し,ImageNet-1kでも精度向上した.しかし,Windowに制限したことによって大局的な認識を失うことになった.
近傍バイアスと大局的な認識,計算量の削減でImageNe-1kでの高精度を目指す.
MaxViTはMBConv,Block Attention,Grid Attentionのモジュールを使用して,目的を達成しようとする.
モデル構造
Swinのような4ステージの階層型構造で,最初の処理(Stem)に畳み込みを採用(パッチ特徴量をConvにする目的)する.
MaxViT BlockはMBConv,Block Attention,Grid Attentionで構成され,ステージ間のダウンサンプリングは,MBConvのDepthwise Convのストライドを2に設定する.

MBConv
MBConvはその後に行われる処理で大局的な認識を行うので,近傍バイアスの獲得のために畳み込み処理を行う.
SE(Squeeze and Excitation Networks)
空間情報を圧縮(Excitation)して,$1 \times 1 \times C$の特徴マップにGAP(Global Average Pooling)で変換し,2層のNN(ニューラルネットワーク)を通して,各チャンネルの特徴マップの重みとする.最後に圧縮する前の特徴マップに重み付けする.
また,DepthwiseConvはconditional position encoding (CPE)とのような役割をするため,位置埋め込みを行なっていない.

Block AttentionとGrid Attention
Block AttentionはSwinのように特徴マップを4つに分割し,受容野を制限して各色の範囲でSAの処理を行い,近傍バイアスと計算量の削減する.Grid Attentionは特徴マップの4分割の方法を工夫して広域の情報を捉えるように各色の範囲でSAの処理をする.

認識受容野
MaxViTの受容野を下図で示し,緑の広い受容野と青の制限された受容野の範囲を考慮する.近傍バイアスを持ちながら大局的な認識も行う.また,受容野がスカスカなので,計算量が削減される.

実験
画像分類
ImageNet-1kではパラメータや計算量を削減して従来手法を上回る性能になった.
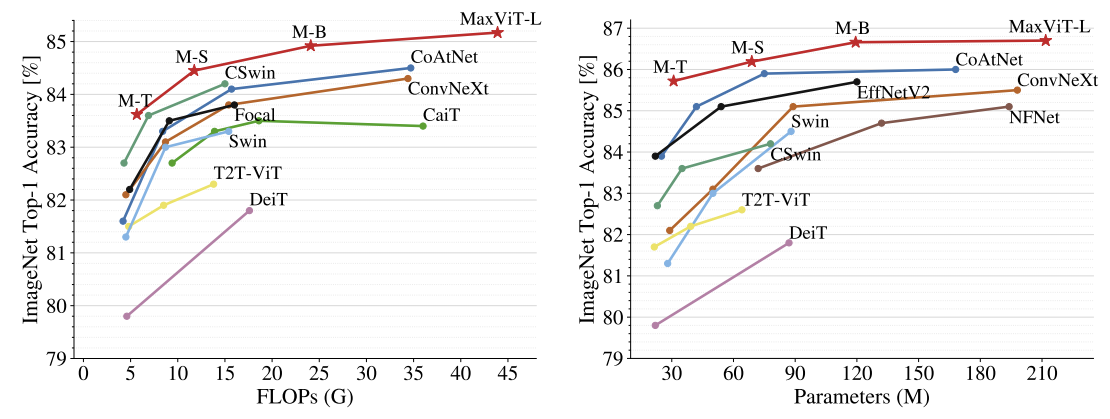
また,ImageNet-21kのデータセットも従来手法を上回る.

MaxViT Blockの3つのモジュールの順番
MaxViT BlockはMBConv,Block Attention,Grid Attentionで構成されており,畳み込み,ローカルなSA,グローバルなSAで,ステージの後半につれてグローバルな認識にすると精度が向上する.

考察
この傾向はステージの前半に畳み込み,後半にSAが重要な役割と一致している.CNNのカーネルサイズ問題があるように,SAの受容野と畳み込みの受容野で様々な受容野で認識して問題を解消し,精度が向上するのかなと思う.
まとめ
今回は,ローカルとグローバルの両方でSelf-AttentionするViT【MaxViT: Multi-Axis Vision Transformer】について解説した.MaxViT BlockにMBConv,Block Attention,Grid Attentionのモジュールを使用することで性能向上した.