原論文
Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer
https://arxiv.org/pdf/2108.01390.pdf
結論
重要でないトークンは削除せず雑に更新
概要
画像認識分野のViTは,高精度の認識と引き換えに,計算コストが膨大である.画像認識において,画像は,認識対象以外のオブジェクトや背景情報が含まれるためノイズの多いデータである.ViTの受容野が広い計算は,悪く言えば,認識に関係ないノイズの情報ばかりを計算してしまうことになる.CNNでは,近傍の情報を集約しているため,ノイズばかりの認識は多少軽減されている構造である.
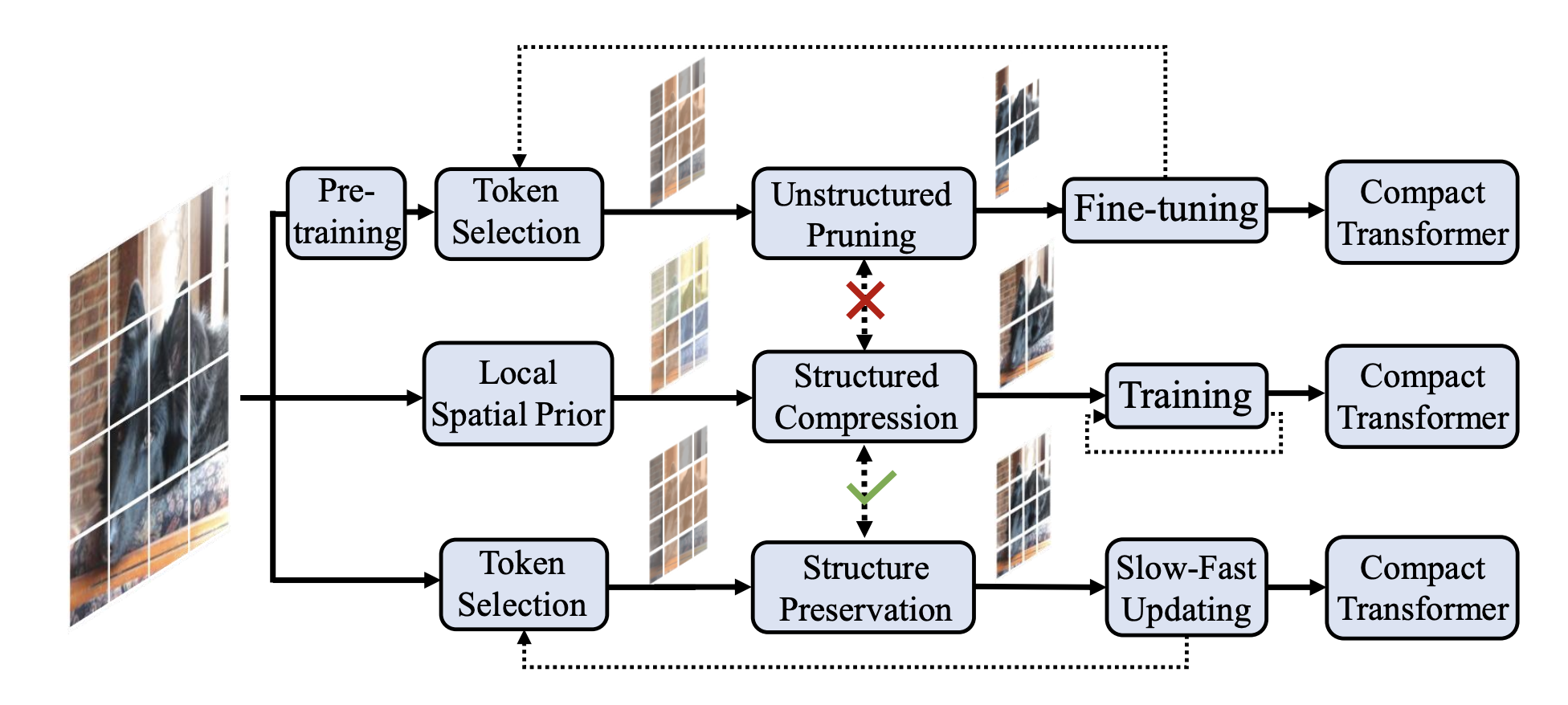
ViTの問題を解決する手法として,下図の上ルートの有効ではないトークンを削除して計算を軽くする「枝刈り」手法がある.しかし,「トークンの削除によって発生する空間構造の不完全さ」と「事前学習(pre train)が必要」であることから,良い選択ではない考える.
下図の中央ルートは,受容野の広いViTの構造を制限して,ローカルな範囲で計算する.これは,情報量の多いトークンと少ない背景トークンを同じ優先度で扱う.
そこで,本論文では,学習中に有効なトークンを選択します.有効なトークンは,低速に学習します.反対に,有効でないトークンは,高速に学習します.論文では,低速,高速と表現していますが,低速はゆっくり丁寧に学習,高速は,雑に計算をあまりせずに学習します.
有効ではないトークンを完全に削除するのではなく,学習コストをかける優先順位を割り当てます.これにより,ViTの構造を保ちながら計算効率を向上させます.
調査
ViTの学習の中で注目している位置を下図に示す.5層目では,認識対象に注視しているとは言い切れないが,情報の多い位置を注目している.これが10層目になると注目位置が洗礼される.この傾向から,5層目から,注目されていないトークンは,重要度の低い(情報量が少ない)トークンとして削除することが可能であることを示す.
本論文では,有効なトークン(情報トークン)と有効ではないトークン(プレースホルダートークン)の2種類に分けて,それぞれ,低速-高速に学習(更新)される.
ViTの識別層で使用されるクラストークンが重要としているトークンを可視化しています.

方法
下図に論文手法であるEvo-ViTの構造を示す.主に,構造保存トークン選択モジュールと低速-高速トークン更新モジュールの2つの部分から構成されます.
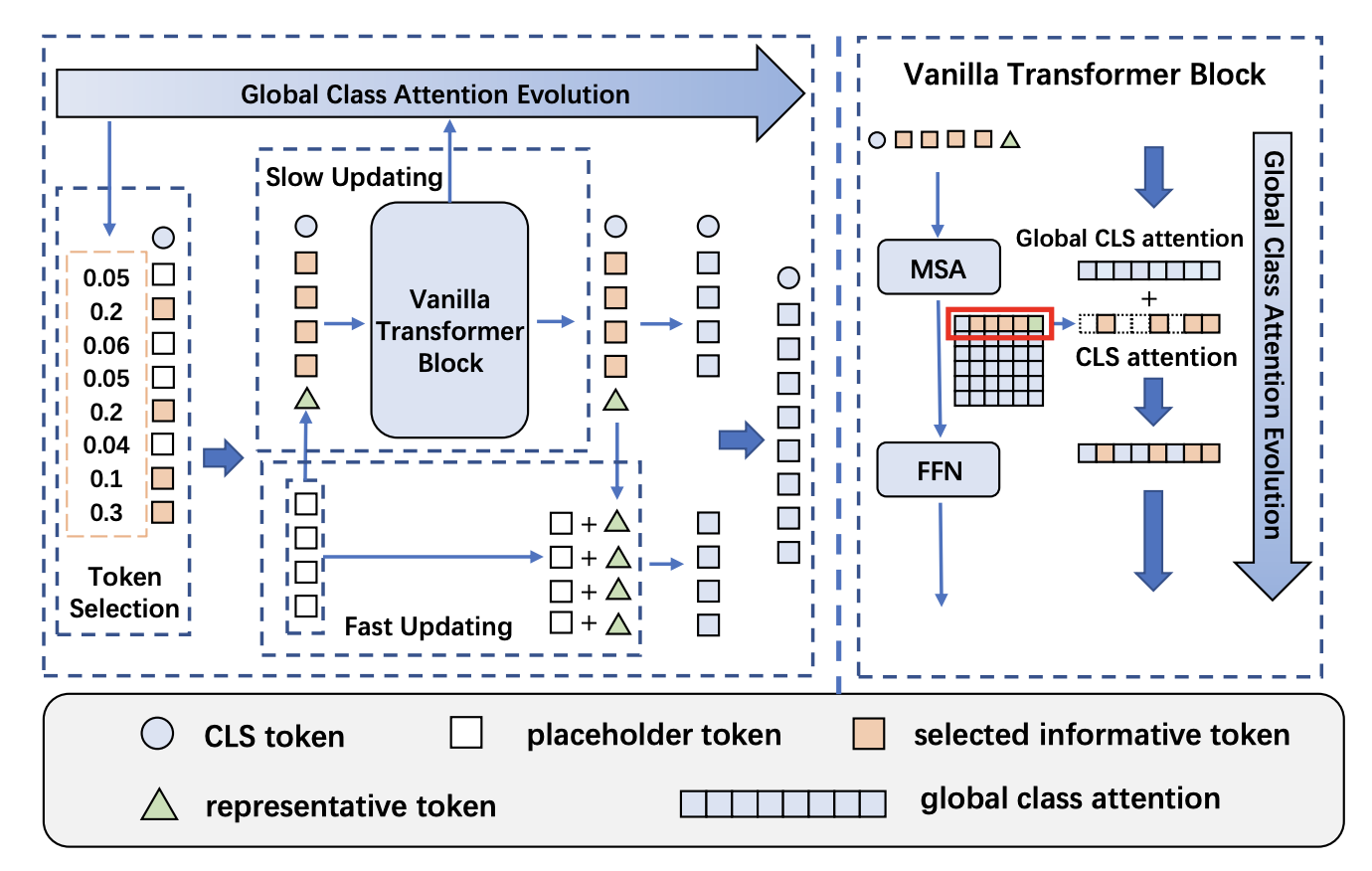
構造保存トークン選択
Evo-ViTは,全てのトークンを保存して,情報トークンとプレースホルダートークンを動的に区別することを提案します.その理由は,ViTの浅い層から中間層,特に学習初期段階において,トークンを削除することは,有効でなないからです.その理由が2つあります.
浅層と中間層は特徴表現の成長速度が速い
浅層と中間層では,特徴量の進化が活発で,最終層の特徴量と比較した際,全く異なる姿に変化します.これは,最終層で必要なトークンとそうでないトークンが全く異なる可能性あります.
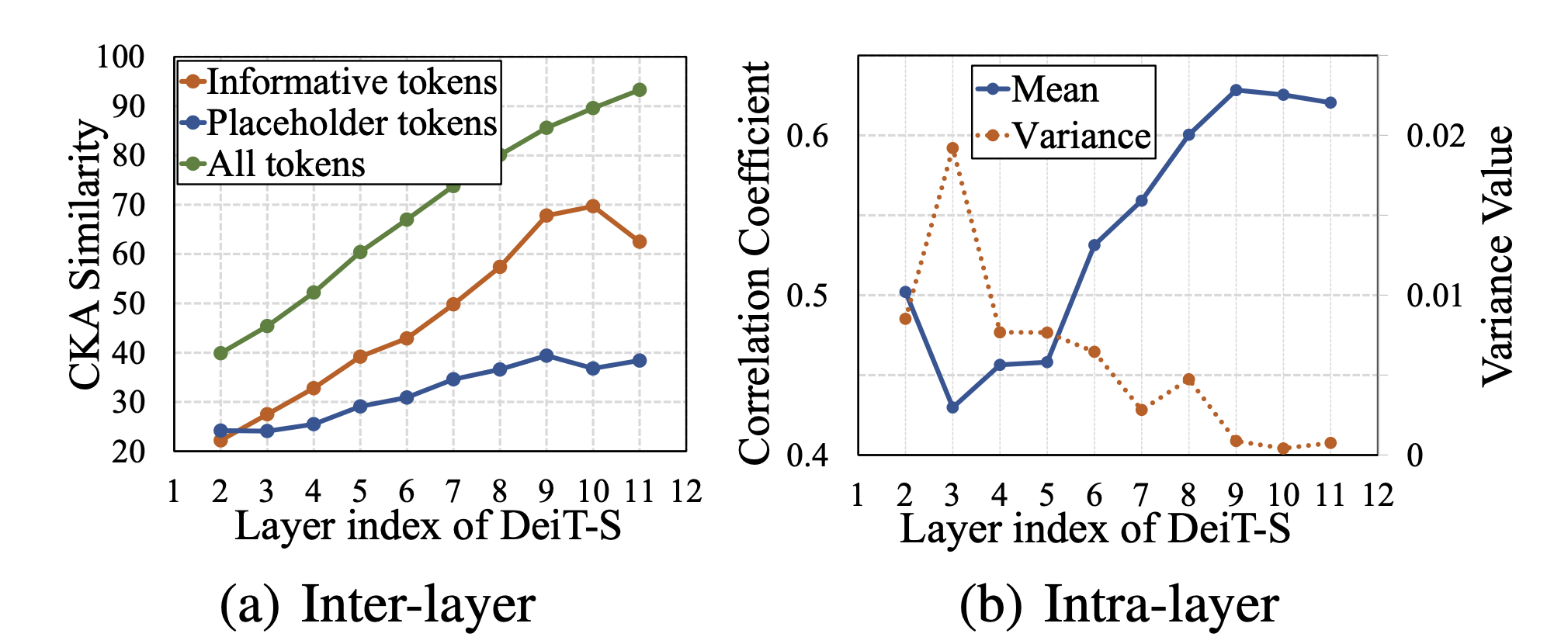
下図(a)は,最終層のクラストークンと各層のクラストークンの類似性を示します.浅い層では,特徴が一致せず,層を重ねることで最終層に類似します.これは,浅い層の表現が深層で通用しなく,トークンの削除が困難である.
例えば,浅い層では,このトークンいらないと思ってたのに,深層では,超重要だった.浅い層の段階で,トークンを削除したら,致命傷である.下図のグラフから,浅い層と深層の類似度が低い傾向から,これがあり得る.
浅い層ではトークン同士の相関が低い
浅い層では,各トークンが異なる情報を持ち,情報の共有や関連性が十分に形成されていない可能性があり,浅い層で,トークンを識別することは困難です.
下図(b)に,各層におけるトークンのクエリ間の相関性の平均と分散を示す.浅い層ではトークン間の関連性がまだ十分に形成されておらず、深い層になるにつれて関連性が高まっていることがわかります(平均が向上して,分散が低下することは,外れ値のデータが軽減され,データに一貫性が出る).
識別方法
下式に,クラストークンのアテンションウエイトを示す.これは,最終的な識別には,クラストークンを使用し,クラストークンには,どこのトークンが重要かの情報をもつ.この式に改良を加え,情報トークンとプレースホルダートークンを識別する.
クラストークンが注目しているk個のトークンを情報トークン.残りはプレースホルダートークンとして扱う.
A_{\text{cls}} = \text{Softmax}\left(\frac{q_{\text{cls}} \cdot K^T}{\sqrt{C}}\right),
上図(a)のような層を超えてクラストークンの関連性がないと悪影響が発生してしまうことから,異なる層のクラストークン間の類似性を向上させるため,層を超えて進化するグローバルクラストークンを提案する.
グローバルクラストークンを下式に示す.前層のクラストークンから,今の層のクラストークンを更新する(学習可能なα付き残差接続のように,前層の情報を考慮する).
これにより,クラストークンの連続性と一貫性を高め,上図のような各層で急激な値の変化を軽減します.これは,浅い層の段階で,プレースホルダートークンの識別が可能になることを示す.
A_{\text{cls}, g}^{(k)} = \alpha \cdot A_{\text{cls}, g}^{(k-1)} + (1 - \alpha) \cdot A_{\text{cls}}^{(k)},
低速-高速トークン更新
Evo-ViTの構造図を下に示す.オレンジが情報トークン,白がプレースホルダートークン,青丸がクラストークン(グローバルクラストークン),緑の三角が代表トークンである.代表トークンとは,多くのプレースホルダートークンから1つに集約されたトークンである.
これにより,情報トークンは,エンコーダ(Transformer Block)で通常の学習通りに丁寧(低速)に更新され,プレースホルダートークンは,代表トークンの更新値を持って雑(高速)に更新される.
代表トークン
重要ではないトークン(プレースホルダートークン)は,各トークン個別に処理のではなく,1つの代表的なトークンに集約される.集約する方法は,Linearや畳み込み,Poolingなどで集約する.
x_{\text{rep}} = \phi_{\text{agg}}(x_{\text{ph}}),
結果
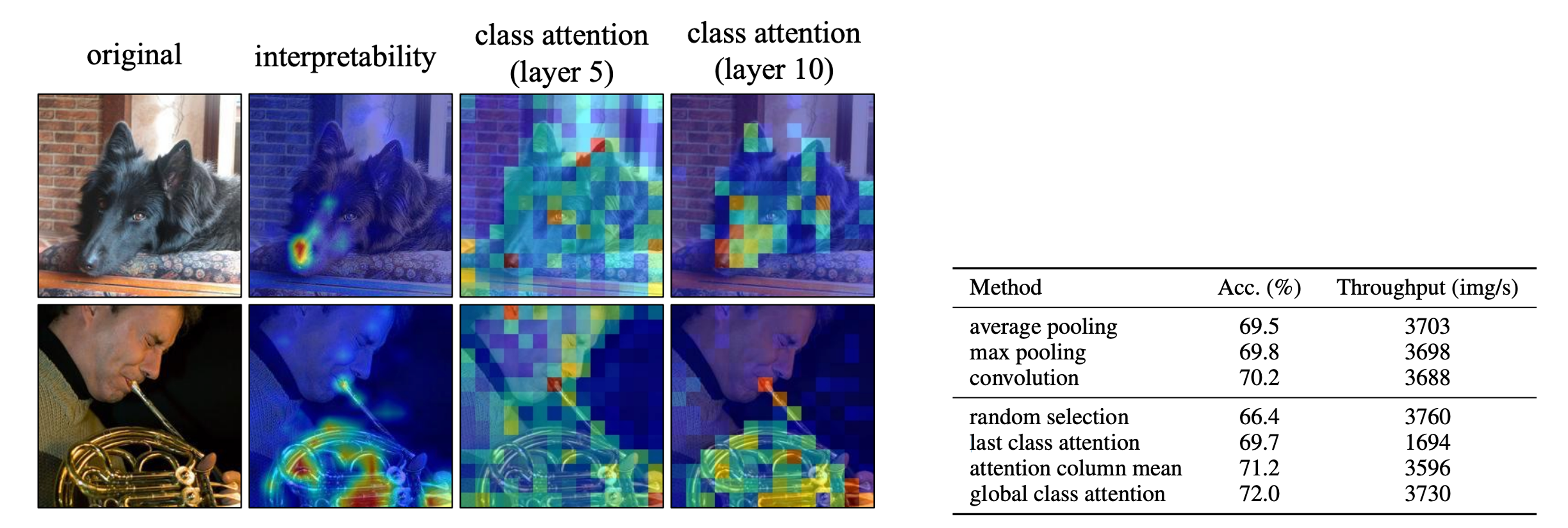
重要でないトークンを可視化する.左下のバットは層を重ねることで,よりバットが情報トークンに綺麗に分離される.

最終層のクラストークンは認識対象にのみ注目(interpretability)をしているが右下の表から,通常のクラストークンを使用すると精度低下する傾向がある.可視化という観点からクラストークンは背景情報に影響されない認識で有効であるが,識別では有効ではない.これは,識別で多少の背景情報を考慮している可能性がある.
今回提案したグローバルトークンは,すべての層を一貫したクラストークンであるため,浅い層で捉えた背景情報の表現をもつ.そのため,通常のクラストークンと比較して,グローバルトークンを使用した分類精度が向上する.
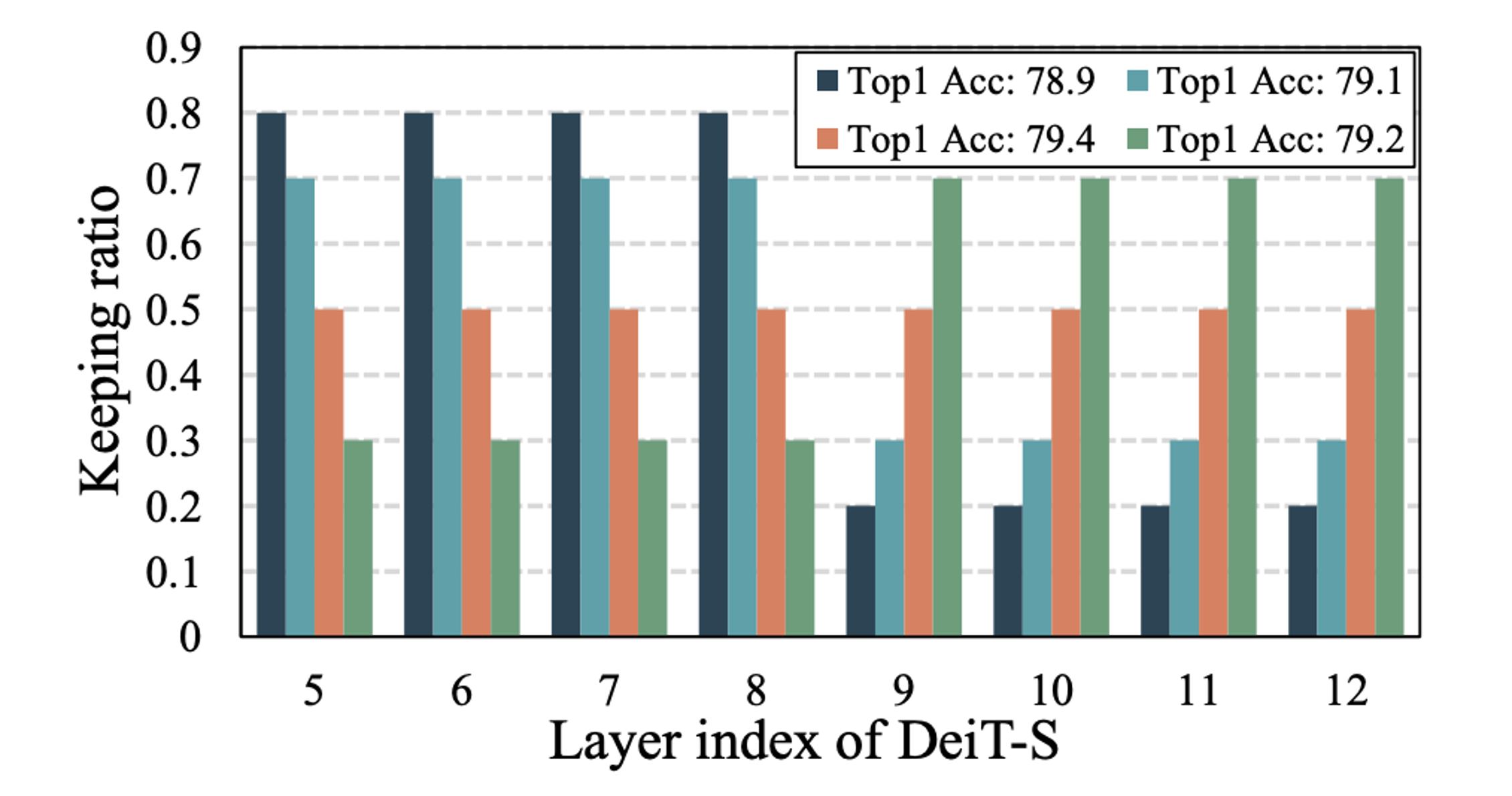
トークンを重要なトークンとそうでないトークンに分ける割合を設定する.結果として,0.5(50%)の一定の割合でトークンの重要度を識別することが良い.本しゅほうで提案しているグローバルトークンは,浅い層から深層まで一貫した表現を目指している.そのため,全層で一貫した割合で識別した方が良い結果が得られたのではないかと考える.
まとめ
重要でないトークンは削除せず雑に更新【Evo-ViT】について解説した.ViTのトークンを削減して計算量を削減しよう.