原論文
CMT: Convolutional Neural Networks Meet Vision Transformers
https://arxiv.org/abs/2107.06263
日本語解説
ViTとCNNを組み合わて精度と速度を向上させたCMTを詳細解説!
https://deepsquare.jp/2021/07/cmt/
関連研究
Vison Transformerの解説
https://qiita.com/wakanomi/items/55bba80338615c7cce73
CNN+ViTモデルの傾向【サーベイ】
https://qiita.com/wakayama_90b/items/96bf5d32b09cb0041c39
結論
ViTにCNNアーキテクチャをたくさん組み込んで,局所的な認識と計算量の削減の補助をする.
概要
ViTの問題点として,局所的な認識が苦手である問題点がある.物体検出やセグメンテーションタスクでは,物体の細かな認識を必要としているため,ViTをそれらのタスクに応用するには,局所的な認識を補助する構造を組み込む必要がある.そこで,局所的な認識が得意な畳み込み(LPU)を組み込んで,畳み込みとSAを交互に行い精度向上を期待する.また,FNNを畳み込みに置き換える.さらに,計算量削減のために,キーとバリューをダウンサンプリングする.また,FNNを畳み込みに置き換える.
モデル構造
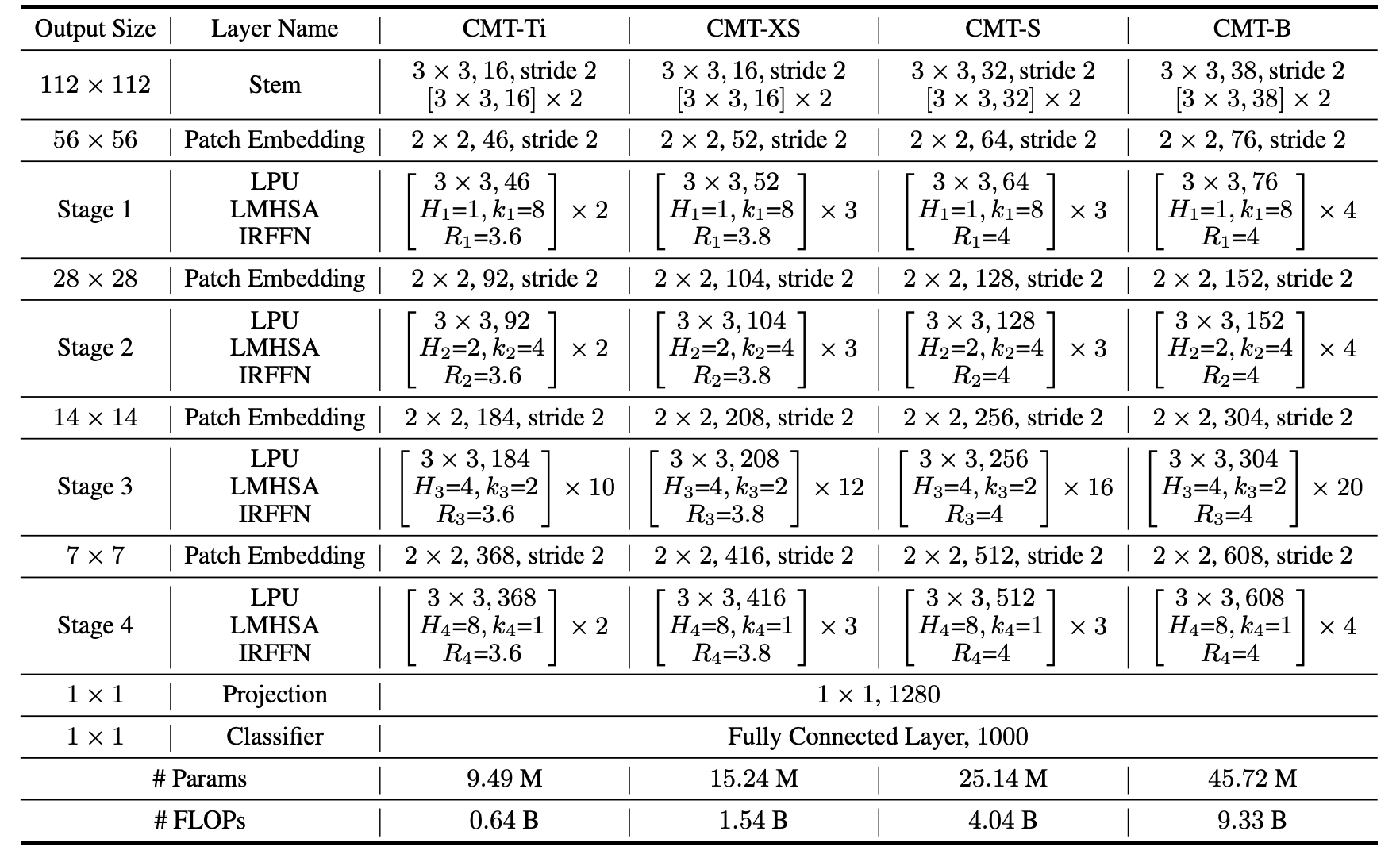
CMTは4ステージの階層型モデル構造を採用する.初めの処理として,パッチ特徴量変換で畳み込み層を採用し,畳み込み層の出力をViTの入力としている.これにより,ViTの苦手な局所的な認識の補助をする.また,ここの畳み込み層で特徴量をダウンサンプリングすることでViTの計算量を削減する.
CMT Block内の処理には以下の3つの処理が組み込まれており,特徴抽出を行う.
- 局所的な空間認識(Local Perception Unit)
- 大局的な空間認識(Lightweight Multi-head Self-attention)
- チャンネル方向の認識(Inverted Residual Feed-forward Network)
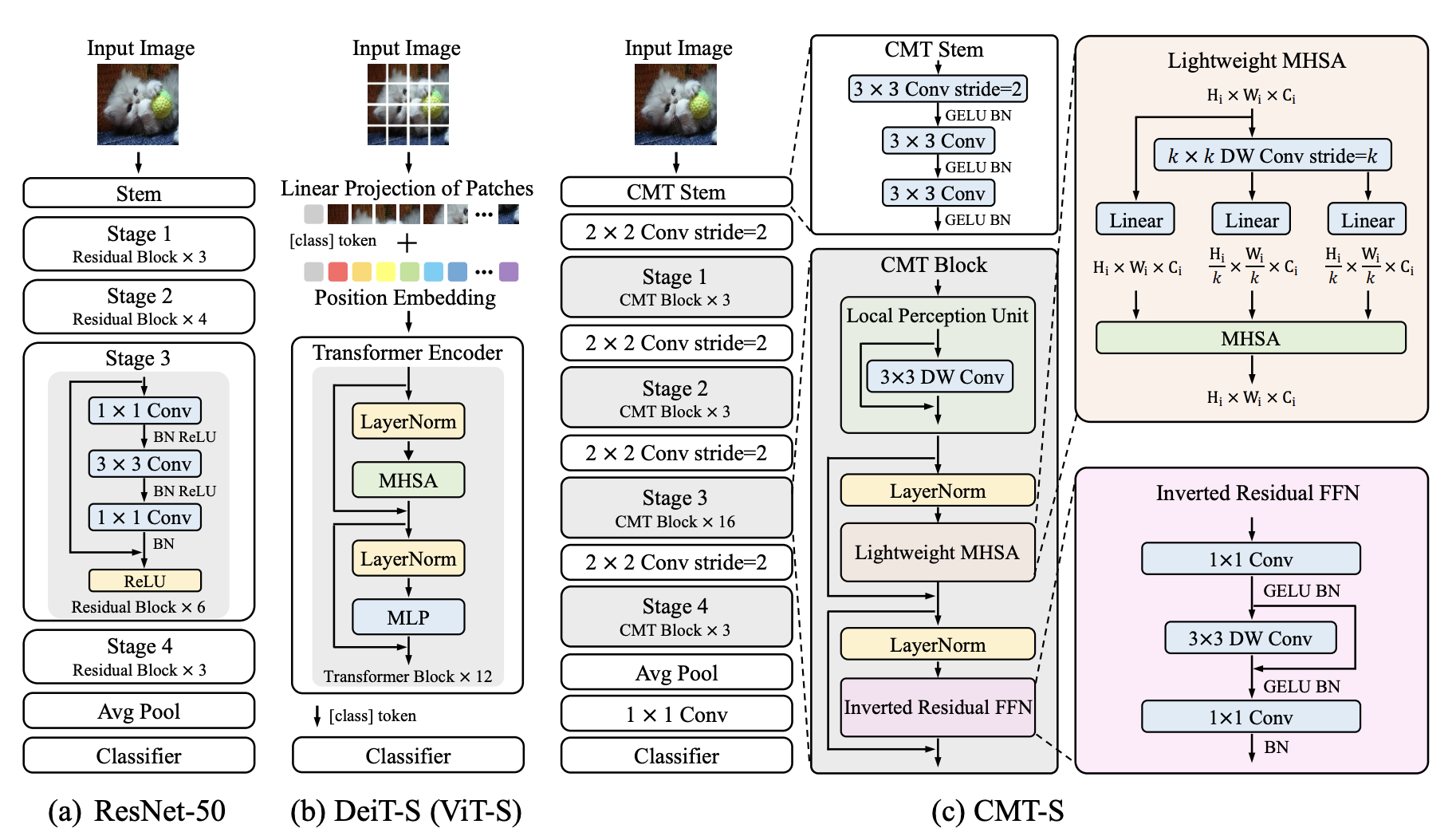
Local Perception Unit(LPU)
ViTの問題点として,局所的な認識が苦手である.それは,パッチに分割してパッチ間の類似度計算(SA)を行うので,パッチ内の認識ができないことにある.局所的な認識を補助するために,畳み込み層をSAの前に追加する.これによって,局所的な認識の畳み込みと,大局的な認識のSAを交互に処理することによって性能向上を目指す.Local Perception UnitにはDWConv(Depthwise Separable Convolution)とスキップ接続で構成されている.DWConvは空間方向の畳み込み.
LPU(x) = DWConv(x) + x
Lightweight Multi-head Self-attention(LMSA)
ViTの問題点として,計算量が膨大なことがある.これを解決するために,キーとバリューをダウンサンプリングする.ダウンサンプリング方法にDWConvを採用する.(他モデルでも同じようにダウンサンプリングする手法がある.畳み込みの他に線形射影や,プーリングを使用している場合もある.)また,位置情報を保存する,相対的位置バイアス(B)を追加する.
クエリ,キー,バリューの変換(キー,バリューはダウンサンプリング)
Q = xW_q \\
K=DWConv(x)W_k \\
V=DWConv(x)W_v
ダウンサンプリングされたSA(LMS)の計算
LMSA(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d}}+B)V
Inverted Residual Feed-forward Network(IRFFN)
ViTは通常,FNNにMLPが採用されていた.
MLP(x) = GELU(XW_1 + b_1)XW_2 + b_2
IRFFNは3x3DWConvを1x1Convに挟まれるような構造である.また,スキップ接続の位置を変更している.
IRFFN(x) = Conv(F(Conv(x))) \\
F(x) = DWConv(x) + x
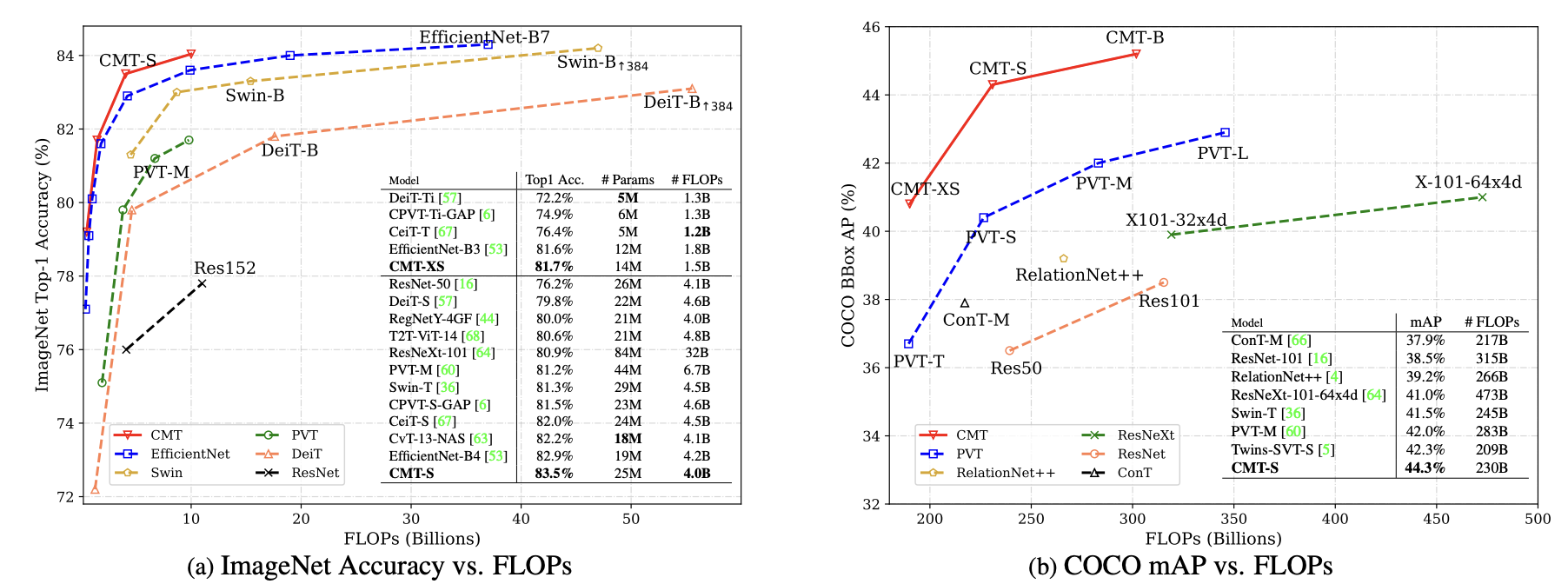
実験結果
画像分類,物体検出,セグメンテーションで良い結果.
考察
ViTにCNNアーキテクチャを組み込む派生モデルは多くあり,CMTは組み込める場所のほぼ全てに組み込んでいる.畳み込みとSAを交互に特徴抽出することは良い傾向である.
ViTの構造に畳み込みを入れすぎても大丈夫なんだなと感じました.
まとめ
今回は,ViTにCNNをたくさん組み込んだモデル【CMT】について解説した.ViTにたくさん畳み込みを組み込むと性能が向上することが分かった.