原論文
DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
https://arxiv.org/pdf/2106.02034.pdf
結論
ViTのパラメータはとても疎である.なので,いらないトークンは削除する.
概要
画像認識分野のViTは,モデルサイズを大きくすることで,高精度えを達成するモデルである.しかし,高精度と引き換えに,スマホなどの組み込み適応できないことや,学習に膨大なコストが必要であるといった問題点が多くある.ViTの分析の中でViTの持つパラメータはとても疎であることが分かった.
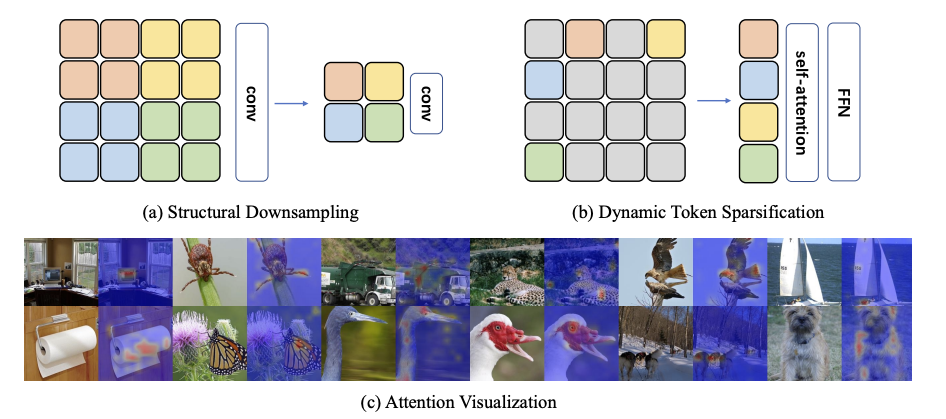
下図cを確認しても,画像分類で必要となる画素は,非常に小さく,注目されていない画素は必要でない.これは,自然言語とは異なり,画像は背景情報や認識対象以外の物体がデータに含まれていることから,認識結果に関係ないノイズが多く含まれるタスクである.
このノイズの多い画像で必要ではないトークン(画像の小領域)を動的に削減することで,計算効率の向上を目指す.
具体的には,下図bのように,必要ないトークンを階層的に何回かに分けて削減し,トークンが減ることで,SAの計算効率の向上と,学習の高速化,モデルサイズの圧縮効果が期待できる.
下図aは,CNNで採用される計算量を削減するために空間サイズを圧縮するダウンサンプリングである.CNNモデルであるResNetは,このダウンサンプリングを階層的に採用して,空間サイズを段階的に圧縮(削減)する.
この階層型を取り入れて,本手法DynamicViTでは,段階的にトークンを削減する.
このトークンの削減は,ViTの構造を持つ恩恵で高速化が可能で,トークン数が減ったとしても,各トークンの次元数が同じであれば,ViTとして機能する.
CNNの場合,とあるピクセルが削除されたとしても畳み込みを実際に高速化することはない.
各画像で,削除されるトークン数は様々で,同じバッチ内の画像間でトークン数が異なるとバッチ内で並列計算が不可能になる.なら,削除されるトークンの値を0にすると,SAのSoftmaxで悪影響が発生してしまう.
そこで,二値決定マスクに基づいて,放棄されたトークンから他のすべてのトークンへの接続を取り除く,注目マスキングと呼ばれる戦略を提案する.また,階層的に削減されるトークンの割合を制約する項を追加して学習する.
これらマスクを使用する場合は,学習中の話であり,推論時には,微分可能や学習可能にする必要がないので,各層で直接トークンを捨てることが可能で,推論速度が向上する.
方法
下図にDynamicViTの全体的なフレームワークを示す.通常のViTといくつか(3つくらいかな?)の予測モジュールから構成される.
予測モジュールには,トークンを削除する確率と保持する確率をもつ.また,予測モジュールは階層的に配置され,12層の場合には,4,7,10層目のブロック前に配置される.
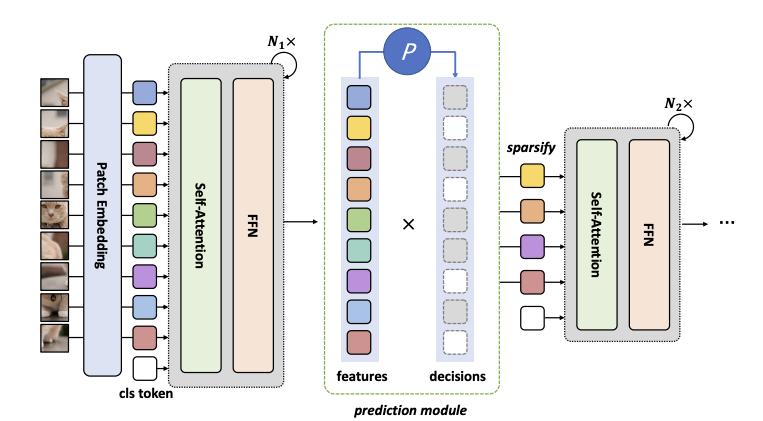
予測モジュール
各トークンを削除するかほじするかを2値の決定マスクD$({0,1})^N$を保持する.ここでN=HW.簡単のためにクラストークンを省略するが,実際には保持する.
決定マスクDは全ての要素を1に初期化し,更新する.決定マスクの式を以下に示す.
$z_{\text{local}}$は,ViTのMLPのようにトークン内の情報を共有する.$C'$は$C$より小さいサイズで,論文では$C'=C/2$になる.
z_{\text{local}} = \text{MLP}(x) \in \mathbb{R}^{N \times C'}
AggはGAP(Global Average Pooling)で空間方法のNを1つの平均値に置き換える.
z_{\text{global}} = \text{Agg}(\text{MLP}(x), \hat{D}) \in \mathbb{R}^{C'}
$z_{\text{local}}$($N \times C'$)と$z_{\text{global}}$($N \times C'$)をC方向にcat(連結)する($N \times C$).
z_i = [z_{\text{local}_i} , z_{\text{global}_i}] \quad \text{for } 1 \leq i \leq N
決定マスクの元となる$\pi$($N \times 2$).この2は,削除する確率と保持する確率を持つ.
\pi = \text{Softmax}(\text{MLP}(z)) \in \mathbb{R}^{N \times 2}
$\pi$を使用して,決定マスクDを更新する.
\hat{D} \leftarrow \hat{D} \odot D
Attention MaskingによるEnd-to-End最適化
二値決定マスクDを得るためのπからのサンプリングは微分不可能であり,学習の妨げとなる.これを克服するために,確率πからのサンプリングにGumbel-Softmax手法を適用する.
Gumbel-Softmaxの出力は,0か1で出力される.その期待値は$\pi$に等しい.また,Gumbel-Softmaxは微分可能であるため,学習が可能である.
D = \text{Gumbel-Softmax}(\pi)^*,1 \in \{0, 1\}^N
学習中にトークンを削減する場合に,各画像によって,削減されるトークン数が異なる.そのため,同じバッチ内で並列計算が困難になる.そのため,トークン数を変えずに,削減されたトークンとその他のトークンの相互作用を減らす必要がある(推論時には,トークンを削除しても良い).
マスクDを用いて,削減するトークンの値を0にした場合,下式のSAのSoftmaxで他のトークンに悪影響を与えてしまう可能性がある.
A = \text{Softmax}\left(\frac{QK^T}{\sqrt{C}}\right)
マスキングを行うためのマスク行列$G_{ij}$の定義.$G_{ij}$は,トークン間の関係性を示す行列であり,トークン$i$とトークン$j$の関係がマスクされるかどうかを決定する.
また,$G_{ij}=1$(クラストークン)と$i=j$(同じトークン)の場合は無条件で保持される.
G_{ij} = \begin{cases}
1, & \text{if } i = j \\
\hat{D}_j, & \text{if } i \neq j
\end{cases}
マスクされたsoftmaxの式.$G_{ij}$によって,削除されたトークンが他のトークンを関係を持たないようにする.
\tilde{A}_{ij} = \frac{\exp(P_{ij})G_{ij}}{\sum_{k=1}^N \exp(P_{ik})G_{ik}}
P = \frac{QK^T}{\sqrt{C}} \in \mathbb{R}^{N \times N}
学習と推論
DynamicViTの学習には,パラメータの更新と,トークンの削減率が目標に近づくような学習が必要である.
クロスエントロピー.正解ラベルとの誤差を最小化する.
L_{\text{cls}} = \text{CrossEntropy}(y, \bar{y})
自己蒸留.最終層(識別層)前の状態で,保持されているトークンに対して,教師モデルとの誤差を最小化する.
L_{\text{distill}} = \frac{1}{\sum_{b=1}^B \sum_{i=1}^N \hat{D}_{b,S_i}} \sum_{b=1}^B \sum_{i=1}^N \hat{D}_{b,S_i} (t_i - t'_i)^2
KLダイバージェンス.大規模な教師モデルの予測値との誤差を最小化する.
L_{\text{KL}} = \text{KL}(y \| y')
各ステージのトークン削減率が目標のpに近づくように損失計算する.
S段階の目標削減比率のセット$\rho$.B はバッチサイズであり,Sはトークン削減のステージ数.
L_{\text{ratio}} = \frac{1}{BS} \sum_{b=1}^B \sum_{s=1}^S \left( \rho(s) - \frac{1}{N} \sum_{i=1}^N \hat{D}_{b,s_i} \right)^2
上記式の損失をいい感じに組み合わせた損失を示す.$\lambda_{\text{KL}}=0.5$,$L_{\text{distill}}=0.5$,$\lambda_{\text{ratio}}=2$に設定する.
L = L_{\text{cls}} + \lambda_{\text{KL}} L_{\text{KL}} + \lambda_{\text{distill}} L_{\text{distill}} + \lambda_{\text{ratio}} L_{\text{ratio}}
推論中には,削減率を目標に忠実に従って削減する.保持確率が高い順にソートして,高い順から保持されて,他のトークンは削除する.
I_s = \text{argsort}(\pi^*,1)
結果
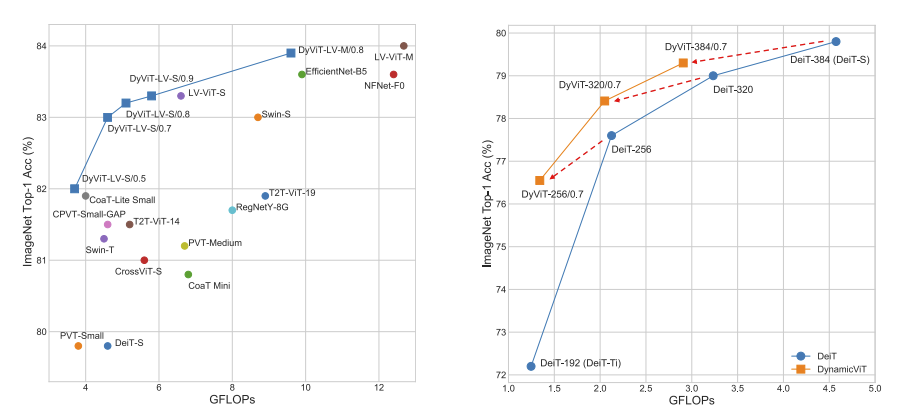
モデルは,4ステージの3段階でトークンを削減する.各ステージで削減率$\rho$は設定される.$\rho$=0.1の場合に,全てのトークンの10%が保持される.次のステージでは,その10%の10%が保持されます.
下図の左では,他手法と比較しても,計算効率がよく,早い計算速度で高精度を達成する.また,右では,次元数と精度の比較で,DeiTの256次元とDyViTの320次元は,計算速度が同じで,DyViTの方が精度高い.
矢印で見たら,同じ次元数で高速.
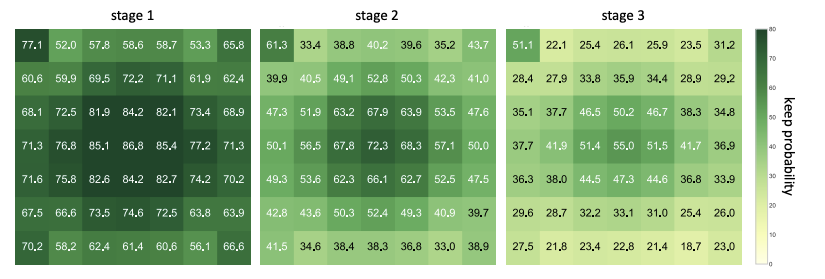
各ステージで削減されはパッチを確認すると,段階的にパッチが削減され,認識対象が残るような傾向がある.

各ステージで空間情報の保持確率を可視化する.認識対象があると思われる中心に保持確率が高いことがわかる.保持確率が段々低下することには,ステージ3では,ほとんどのトークンを削減しようとしてるから,相対的に保持確率は小さくなってる.
まとめ
今回は,ViTのパラメータはとても疎である【DynamicViT】について解説した.ViTは疎なので,いらないトークンは削減してもあまり問題ないことが分かった.