この記事はディップ Advent Calendar 2023の22日目の投稿です!
1.はじめに
私は現在、生成AI(OpenAI API)を利用した求人情報を紹介するサービスの立ち上げに開発リーダーとして携わっています。その中で、バックエンド開発における、「クリーンアーキテクチャ+生成AI」の知見が溜まってきたので、それを紹介します。
背景
弊社(ディップ株式会社)では「バイトル」、「はたらこねっと」など、求人情報サービスを自社で開発・運営しています。
その中で、AIエージェント事業という生成AIを活用した求人紹介機能の開発が進んでおり、2023年内にバイトル(Web版)の中でのリリースを目指しています。
生成系AI技術の活用・実用化により雇用創出の可能性を広げる取り組みとして開発を開始した新たな事業です。これにより従来の「大量の求人情報から検索する・選ぶ」方法から「対話しながら最適な仕事に出会える」方法へと進化し、採用率を大幅に高めていくことを目指しています。
(参考) 検索型→対話型へ 生成系AIを活用し雇用創出に新たな可能性をディップ、「AIエージェント事業」開発を開始
このサービスでは、具体的な機能の例として、生成AIを用いた以下のような機能を実現します。
- 仕事紹介文の生成
- ユーザ入力から特徴情報を抽出
- 文脈の属性判断
など
本記事では、生成AIプロダクトの開発をする中で使用したアーキテクチャを紹介した後、具体的な実装を見ながら、その実装に至ったポイントを紹介していきます。
こんな人・プロジェクトにおすすめ
- OpenAIを使ったプログラムは書いたことがあるが、例外処理や拡張性、保守性の高く書きたい。
- 開発者やデータサイエンティスト・プロンプトエンジニア複数人での開発のため、責任分解をして改修コストを減らしたい。
- 大量アクセスが想定されるサービスのため、GPTの不安定さからシステムを守りたい
こんな内容は対象外
- 手軽にOpenAIをPythonで触りたい人向けの内容
- この記事では保守性が高くなるような設計&製品レベルのエラー処理などがサンプルコードに書かれているので、手軽にOpenAIを触りたい場合はここまでやる必要はないと思います。
- プロンプトの内容・プロンプトエンジニアリングの内容
- この記事では具体的なプロンプトの内容には触れません。
開発環境
- Python FastAPI
- OpenAI API(GPT 3.5)
- Langchainは使っておりません
- PydanticV2とバージョン競合を起こすため(執筆時点)
2.クリーンアーキテクチャについて
筆者の考えるクリーンアーキテクチャについての詳細およびレイヤーの役割については以下の記事でまとめています。
大事なのは以下の2点です。
- レイヤーに分離することで、関心事の分離を行う
- 依存性は内側だけに向かっていなければならない
この記事では生成AIアプリケーションを作成するためのコアとなるモジュールを紹介していきますが、それらはクリーンアーキテクチャの何らかのレイヤーに属しています。そのレイヤーの役割を把握しておくと理解がしやすいかと思います。
3.OpenAI APIを使うための導入
1. OpenAI APIを使うためにはOpenAI Pythonライブラリをインストールします
pip install openai
2. APIキーを取得します
ここからAPIキーを取得し、環境変数に登録します。
以降のサンプルプログラムでは、
os.environ.get("OPENAI_API_KEY")
でAPIキーを取得できる前提で話を進めます。
4.設計の全体像
この記事では一番単純な例として、ユーザーからの入力をGPTに投げて、その回答を返すAPIを考えます。
全体の流れを図示すると次のようになります。
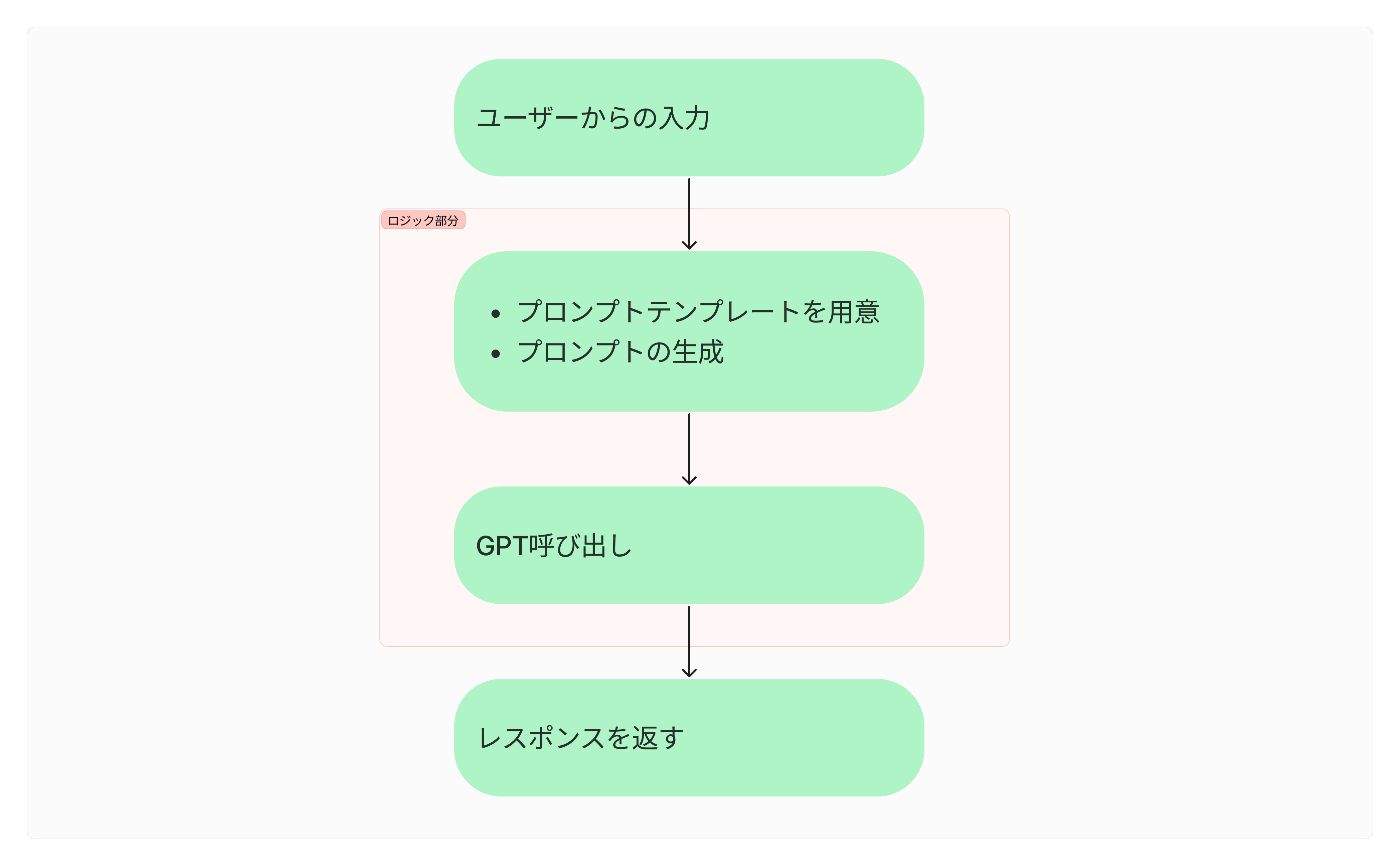
その流れをレイヤーごとに分けると次の図のようになります。
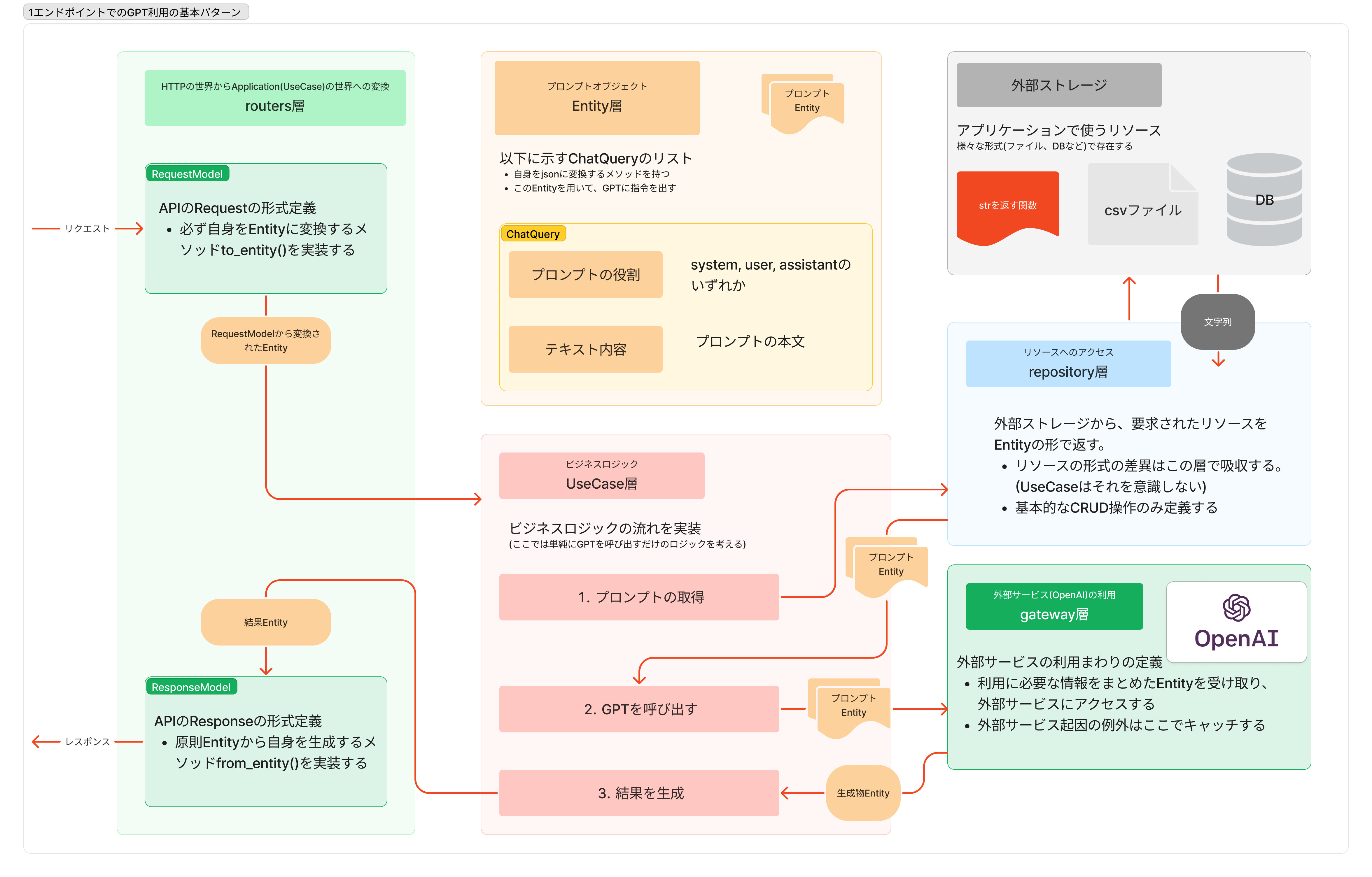
以降の章では
- OpenAIモジュール(緑)
- プロンプトモジュール(オレンジ)
- プロンプト取得モジュール(青)
- ロジック本体(赤)
の順番で詳細を紹介していきます。
5.OpenAIモジュール(gateway層)
私のプロジェクトでは外部サービスへのアクセスは全てgateway層として切り出し、そのサービスに関わる処理をまとめて書いています。
その中で、OpenAIへのアクセスとして、具体的には以下のようなモジュールを定義しています。
from abc import ABCMeta, abstractmethod
import openai
import openai.error
import src.gateway.errors.errors as errors # エラー定義 詳細は割愛
from src.entities.chat_query import ChatQueryList
openai.api_key = os.environ.get("OPENAI_API_KEY")
class AbstractOpenAI(metaclass=ABCMeta):
"""OpenAIを使うための抽象クラス
モックに本実装と同様のインターフェイスを持たせるために抽象クラスを用意してある。"""
@abstractmethod
def create_response(self, messages: ChatQueryList) -> str:
raise NotImplementedError
class OpenAI(AbstractOpenAI):
"""OpenAIを使うためのクラス"""
def __init__(self, model="gpt-3.5-turbo-0613", max_tokens: int = 350):
self.model = model
self.temperature = 0.0
self.max_tokens = max_tokens
def create_response(self, messages: ChatQueryList) -> str:
"""GPT呼び出し
Args:
messages (ChatQueryList): GPTに渡すメッセージ decode後はlist[{"role": "user", "content": "アドベントカレンダーの期限が迫っている"}]
Returns:
str: GPTからのレスポンス
"""
try:
response = openai.ChatCompletion.create(
model=self.model,
messages=messages.decode(),
temperature=self.temperature,
max_tokens=self.max_tokens,
)
except openai.error.Timeout:
raise errors.GPTTimeoutError()
except openai.error.APIError:
raise errors.GPTAPIError()
except openai.error.APIConnectionError:
raise errors.GPTAPIConnectionError()
except openai.error.InvalidRequestError:
raise errors.GPTInvalidRequestError()
except openai.error.AuthenticationError:
raise errors.GPTAuthenticationError()
except openai.error.PermissionError:
raise errors.GPTPermissionError()
except openai.error.RateLimitError:
raise errors.GPTRateLimitError()
except Exception:
raise errors.GPTOtherError()
response_str: str = response.choices[0]["message"]["content"]
return response_str
ポイント
- OpenAIクラスをインスタンス化することでGPTが利用できます。その時、OpenAIのモデルやMaxトークン数を指定することができるようにしてあります。
- メソッドとしては、GPT呼び出しのためのメソッドを定義していて、プロンプトEntityを受け取って、GPTの回答をstrとして返します。プロンプトEntity(ChatQueryList)は次章で説明します。
- OpenAIから起きうる例外を細かく定義しています。これにより、システムエラーが起きた時、GPT起因なのかそれ以外なのかが分かります。
- 生成AIはランダムな出力という性質上、テストがしにくい。それを解決するために使う抽象クラスを定義している。
エラー処理について
起きうるエラーについてはopenAIの公式ページに載っています。
特に起きやすかったのが、RateLimitErrorでこのエラーは
- 分間トークン数 or 分間リクエスト数の上限を超えた場合
- クレジットが足りなかった場合
に発生するものでした。(クレジットが足りないというのは盲点になりがち)
except句の中には、エラーが起きた時の処理を書けば良いのですが、ここではそのエラーに対応する自作例外であるerrors.XxxxxErrorをraiseしています。
抽象クラスについて
OpenAIを使ったUseCaseのテストをする時に、本当に生成AIが叩かれてしまうと、予測不可能な文章が生成されてしまい、テストしにくいということが起こります。
それを防ぐためにはこのクラスをモックする必要があり、そのモック先のクラスにも同様のインターフェイスを持たせるために、抽象クラスを用意しています。
その他、抽象クラスを定義するメリットとして、FastAPIのDependsと利用することで、OpenAIに依存したロジックのテストや改修をする時に、影響範囲をOpenAIと切り分けることができます。(8章に利用例があります)
運用保守の観点で実装しているものなので、なくてもOpenAIクラスとしては問題なく機能します。
6.プロンプトモジュール(Entity層)
from enum import Enum
from src.entities.base import EntityBaseModel
class ChatRole(str, Enum):
"""OpenAI APIの/v1/chat/completionsにおける、messagesの各要素がもつroleを表現するクラス
cf. https://platform.openai.com/docs/api-reference/chat/create
"""
system = "system"
user = "user"
assistant = "assistant"
class ChatQuery(EntityBaseModel):
"""OpenAI APIの/v1/chat/completionsにおけるmessagesの要素を表現するクラス
"""
role: ChatRole
content: str
def decode(self) -> dict:
return {"role": self.role.value, "content": self.content}
class ChatQueryList(EntityBaseModel):
"""OpenAI APIの/v1/chat/completionsにおけるmessagesを表現するクラス
"""
queries: list[ChatQuery]
def decode(self) -> list[dict]:
return list(map(ChatQuery.decode, self.queries))
ChatRoleクラス(Chatメッセージの種類)
ChatRoleとして役割を列挙しています。
公式ドキュメントを読むと、全部で5つの役割があるようです。
実際には、systemプロンプトとuserプロンプトしか使いませんでした。
ChatQueryクラス(単体のプロンプト)
このクラスはプロンプト単体を表すもので、上で定義したChatメッセージの種類とメッセージ本体を持ちます。
ChatQueryListクラス(一連のChat内容)
このクラスは上のChatQueryクラスをリストとして持っており、OpenAIクラスに投げる時のEntityになります。
実際にopenaiで使う時には辞書型にする必要があるので、decodeメソッドを実装しています。
EntityBaseModel(Entityの基底クラス)
EntityBaseModelはプロジェクト内の全てのEntityに継承させているクラスで、pydanticのBaseModelを継承元としています。Entityインスタンスにさまざまな効果を与えられるもので、ここではイミュータブルにする設定をして使っています。(クリーンアーキテクチャでは原則Entityはイミュータブルであることが望ましいとされている)
7.プロンプト取得モジュール(repository層)
プロンプト取得のrepositoryの役割としては、外部ストレージからリソース(プロンプト本文)を取得して、それをプログラムで使える形(上で説明したChatQueryListクラス)にしてUseCaseに返すことです。
例として、システムプロンプトとユーザープロンプトの2つを取得して返すコードを示します。
from src.entities.chat_query import ChatQuery, ChatQueryList, ChatRole
from src.repository.prompt.call_gpt_box.human_prompt import load_human_prompt
from src.repository.prompt.call_gpt_box.system_template import load_system_prompt
class CallGptPrompt:
"""GPTを呼び出してタスク型以外のことをさせたい際に利用されるプロンプトを作成する"""
def generate_gpt_prompt(self, user_input_text: str) -> ChatQueryList:
"""
Args:
user_input_text(str): ユーザーが入力したテキスト
Returns:
ChatQueryList: 生成されたプロンプト
"""
system_prompt: ChatQuery = self._generate_call_gpt_system_prompt()
human_prompt: ChatQuery = self._generate_call_gpt_user_prompt(user_input_text)
return ChatQueryList(queries=[system_prompt, human_prompt])
@staticmethod
def _generate_call_gpt_user_prompt(user_input_text: str) -> ChatQuery:
"""ユーザープロンプトの生成
Args:
user_input_text (str): 入力されたテキスト
Returns:
ChatQuery: 生成されたヒューマンプロンプト
"""
prompt: str = load_human_prompt(user_input_text)
return ChatQuery(role=ChatRole.user, content=prompt)
@staticmethod
def _generate_call_gpt_system_prompt() -> ChatQuery:
"""システムプロンプトの生成
Returns:
ChatQuery: 生成されたシステムプロンプト
"""
prompt: str = load_system_prompt()
return ChatQuery(role=ChatRole.system, content=prompt)
プロンプトを関数として持っておくメリット/デメリット
メリット
- この例のヒューマンプロンプトのように、ユーザー入力を簡単にプロンプトの内容に関与させられる
- データの読み込みが発生しないため、高速にプロンプトを取得することができます。
デメリット
- プロンプトチューニングをする時に、コードに修正がかかるということやプロンプトエンジニアがコードを触る必要があること。
- プロンプトの種類が増えたときにその数だけ関数が増える。(ディレクトリ構造で管理するしかない)
8.ロジック本体(UseCase層)
単にGPTにユーザーの入力を投げるだけのロジック例です。
from src.entities.chat_query import ChatQueryList
from src.gateway.open_ai import AbstractOpenAI
from src.repository.prompt.call_gpt_prompt import CallGptPrompt
from src.use_cases.base import UseCaseBaseModel
class CallGPTUseCase(UseCaseBaseModel):
"""GPT呼び出しUseCase"""
@classmethod
def call_gpt(cls, request_message: str, open_ai: AbstractOpenAI):
"""GPTにメッセージを投げる
Args:
request_message (str): GPTに投げる文章
Returns:
str: GPTからのレスポンス
"""
messages: ChatQueryList = CallGptPrompt().generate_gpt_prompt(request_message)
# GPT呼び出し・生成
result_str = open_ai.create_response(messages=messages)
return result_str
ポイント
- use_caseではロジックに必要な流れのみ書かれている
- OpenAIの例外処理や呼び出しなども、適切な場所に書いてあるため、1行で済む
- できるだけ、use_caseはロジックの流れがわかるように記述する。細かい処理は他のレイヤーに役割を任せられないかを考える。
- UseCaseは外部のリソースの形式を知る必要がない
- プロンプトがテキストファイルなのか、関数の返り値なのかを気にすることなく、ChatQueryList(Entity)として扱える。
- openAIのオブジェクトを外部化している(依存性注入)
- 本番で使うもの、テストで使うものを外から指定でき、ロジックとOpenAIの影響範囲を切り分けている。
今回のUseCaseは単純なものを想定しましたが、実際のUseCaseはGPTのレスポンスを使って何をするとか、DBから情報を取ってくるとかもう少し複雑になります。
9.余談
生成AIを使ったプロダクトを年内にリリースする。を目標にチーム一丸となって開発を進めてきました。
私自身、生成AIを使ったプロダクトの開発経験が無い中で、手探りで進んできました。
負荷テストとして大量のアクセスをすると、OpenAIはタイムアウトを起こしたり、リクエスト上限がきたりと、不安定な挙動を起こし大変な思いをしましたし、出力が変わるシステムをどうテストすれば良いのかといった問題にもぶつかりました。
そんな生成AIを使いこなすために、生成AIプロダクト関連の記事や参考書を読んでも、実際の運用に足る情報が書いてあることは少なかった気がしています。
やはり0から実装して試行錯誤をする経験はとても勉強になりますね。
この記事の内容が、部分的にでもどこかのプロダクトにとってプラスになることがあれば嬉しいです。
参考