はじめに
プロジェクトセカイ(以下、プロセカ)、バンドリ!ガールズバンドパーティー(以下、ガルパ)の音楽ゲーム部分は音楽ゲームとしては不親切だといえる。
特に、プロセカに関しては譜面の難易度がチュウニズム等アーケードゲームにも劣らないにも拘らず、判定の可読性が悪すぎてALL PERFECTを狙う難易度を引き上げる要因となっている。
半年前程に一度か二度ほど判定部分の可読性を上げる要望を送ったが、何も改善が見られため自作することにした。簡単に作成するため、kerasを用いて判定部分を学習し、動画をフレーム単位で切り取り、どの部分でgreat以下が出ているかを認識することを目的とする。
使用したもの
- iPad Pro 11(2021)
- Python 3.9.4
- opencv, keras
中身
データの準備
まず、学習用データとして、自分でサンプル動画をキャプチャし、それをフレーム単位に分割し、判定部分のみを切り取る。プロジェクトセカイのプレイ画面は以下の通りになっている。(画面のサイズは1920x1342)
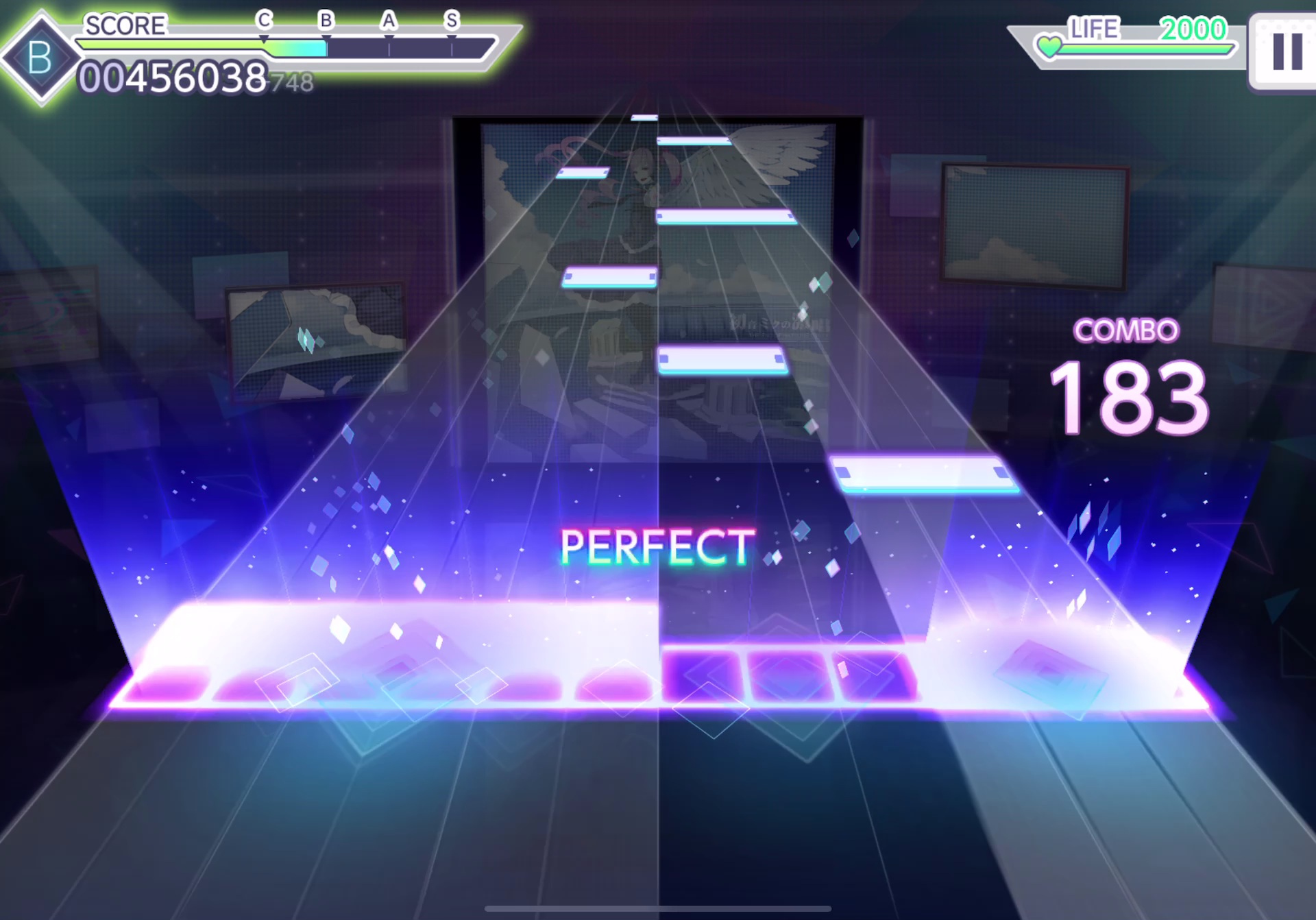
このうち、(800, 750), (1112, 850)を左上、右下として判定部分のみを切り出す。今回は, great以下が多く出るような初音ミクの消失(MAS), 初音ミクの激唱(MAS)のサビ以降の各50秒の動画を用いた。
これにより、以下の画像群が得られる。

これを手動でperfect, great, good, bad, miss, None(判定が何も表示されていない)の6つに分ける。
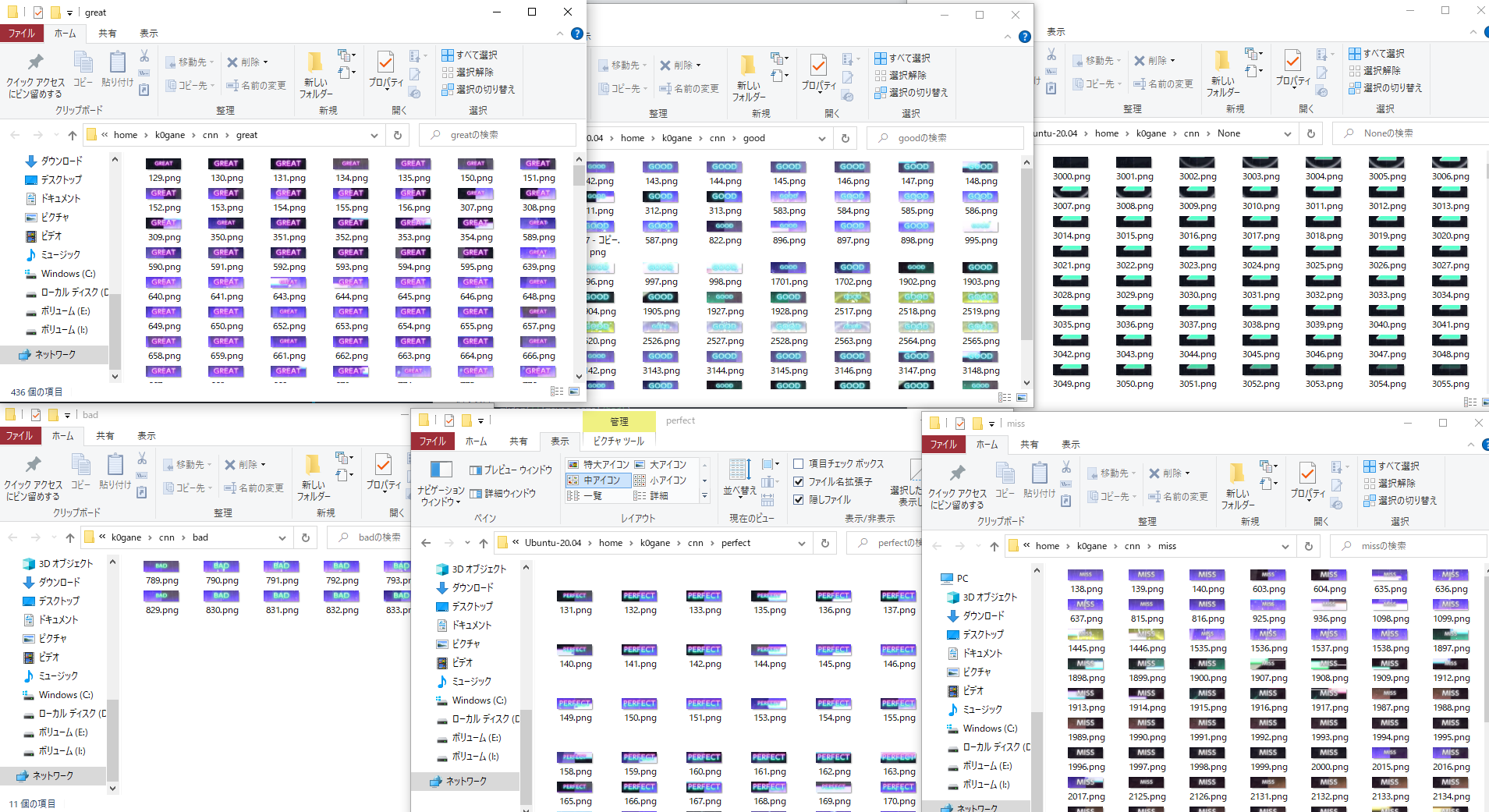
同じことを準備した動画の数だけ繰り返し、必要な学習データを得る。足りない場合はかさまし等して対応する。
学習
(参考: https://qiita.com/mainvoidllll/items/db991dc30d3ddced6250)
ライブラリ
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers.convolutional import MaxPooling2D
from keras.layers import Activation, Conv2D, Flatten, Dense,Dropout
from sklearn.model_selection import train_test_split
from keras.optimizers import SGD, Adadelta, Adagrad, Adam, Adamax, RMSprop, Nadam
from PIL import Image
import numpy as np
import glob
import matplotlib.pyplot as plt
import os
下準備
まず、画像データと分類データを読み込む。
folder = ["perfect", "great", "good", "bad", "miss", "None"]
dense_size = len(folder)
X = []
Y = []
for index, name in enumerate(folder):
print(index)
files = glob.glob(name + "/*.png")
for i, file in enumerate(files):
image = Image.open(file)
image = image.convert("RGB")
data = np.asarray(image)
X.append(data)
Y.append(index)
これにより、perfect...0, great...といった形でNoneまで0-5で数値が割り振られ、これがクラスとなる。
X = np.array(X)
Y = np.array(Y)
X = X.astype('float32')
X = X / 255.0
Y = np_utils.to_categorical(Y, dense_size)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.10)
Xを0-1にし、学習用とテスト用に分割する。
モデルの準備
今回使うCNNモデル
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 100, 312, 32) 896
_________________________________________________________________
activation_6 (Activation) (None, 100, 312, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 98, 310, 32) 9248
_________________________________________________________________
activation_7 (Activation) (None, 98, 310, 32) 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 49, 155, 32) 0
_________________________________________________________________
dropout_3 (Dropout) (None, 49, 155, 32) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 49, 155, 64) 18496
_________________________________________________________________
activation_8 (Activation) (None, 49, 155, 64) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 47, 153, 64) 36928
_________________________________________________________________
activation_9 (Activation) (None, 47, 153, 64) 0
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 23, 76, 64) 0
_________________________________________________________________
dropout_4 (Dropout) (None, 23, 76, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 111872) 0
_________________________________________________________________
dense_2 (Dense) (None, 512) 57278976
_________________________________________________________________
activation_10 (Activation) (None, 512) 0
_________________________________________________________________
dropout_5 (Dropout) (None, 512) 0
_________________________________________________________________
dense_3 (Dense) (None, 6) 3078
_________________________________________________________________
activation_11 (Activation) (None, 6) 0
=================================================================
Total params: 57,347,622
Trainable params: 57,347,622
Non-trainable params: 0
_________________________________________________________________
学習
optimizers ="Adadelta"#SGD, Adagrad, Adam, Adamax, RMSprop, Nadam
epochs = 140
model.compile(loss='categorical_crossentropy', optimizer=optimizers, metrics=['accuracy'])
model.fit(X_train, y_train, validation_split=0.2, epochs=epochs)
epochを140としたのは、その前に5値分類(Noneなし)でやった時、140エポックでAccuracyがfour-nineとなったから。
出力がこちら。
Epoch 1/140
115/115 [==============================] - 363s 3s/step - loss: 1.2510 - accuracy: 0.6934 - val_loss: 0.8985 - val_accuracy: 0.7476
Epoch 2/140
115/115 [==============================] - 229s 2s/step - loss: 0.8285 - accuracy: 0.7366 - val_loss: 0.8139 - val_accuracy: 0.7476
Epoch 3/140
115/115 [==============================] - 227s 2s/step - loss: 0.7516 - accuracy: 0.7401 - val_loss: 0.7625 - val_accuracy: 0.7476
Epoch 4/140
115/115 [==============================] - 225s 2s/step - loss: 0.7387 - accuracy: 0.7216 - val_loss: 0.6967 - val_accuracy: 0.7476
Epoch 5/140
115/115 [==============================] - 222s 2s/step - loss: 0.6891 - accuracy: 0.7278 - val_loss: 0.6474 - val_accuracy: 0.7476
...
(中略)
...
Epoch 136/140
115/115 [==============================] - 219s 2s/step - loss: 0.0228 - accuracy: 0.9936 - val_loss: 0.0247 - val_accuracy: 0.9946
Epoch 137/140
115/115 [==============================] - 218s 2s/step - loss: 0.0173 - accuracy: 0.9949 - val_loss: 0.0239 - val_accuracy: 0.9956
Epoch 138/140
115/115 [==============================] - 217s 2s/step - loss: 0.0153 - accuracy: 0.9954 - val_loss: 0.0222 - val_accuracy: 0.9956
Epoch 139/140
115/115 [==============================] - 219s 2s/step - loss: 0.0204 - accuracy: 0.9952 - val_loss: 0.0226 - val_accuracy: 0.9946
Epoch 140/140
115/115 [==============================] - 222s 2s/step - loss: 0.0172 - accuracy: 0.9968 - val_loss: 0.0239 - val_accuracy: 0.9946
Accuracy:0.9968でloss:0.0172なのでかなり良いモデルが生成されたと言える。
生成したモデルは使いやすいように保存する。
model_json_str = model.to_json()
open('mnist_mlp_model.json', 'w').write(model_json_str)
model.save_weights('mnist_mlp_weights.h5');
試しに一度適当な画像でテストをしてみる

↑を用いる。
test_data = []
for name in ['1714', '2385', '1702', '793', '1446', '3206']:#perfect, great, good, bad, miss, Noneの順番
test_data.append(np.asarray(Image.open(f'mini_test/{name}.png').convert("RGB")))
td = np.array(test_data)
td = td.astype('float32')
td = td / 255.0
model.predict_classes(td)
>array([0, 1, 2, 3, 4, 5])
実際に使用する
こちらの動画をテストデータとしてみる
最後までALL PERFECT、敢えてラストに2great, 1goodを出している。
以下の関数を作成した。
def judge_analysis(movie_name):
os.mkdir(movie_name)
n = 0
cap = cv2.VideoCapture(f'{movie_name}.mp4')
while True:
is_image,frame_img = cap.read()
if is_image:
left, right, top, bottom = 800, 1112, 750, 850
td = frame_img[top : bottom, left : right]
td = cv2.cvtColor(td, cv2.COLOR_BGR2RGB)
td = np.array([td])
td = td.astype('float32')
td = td / 255.0
td = model.predict_classes(td)[0]
if(0 < td < 5):
if(td == 1):
try:
os.mkdir(f'{movie_name}/great')
cv2.imwrite(f"{movie_name}/great/{n}.png" , frame_img)
except:
cv2.imwrite(f"{movie_name}/great/{n}.png" , frame_img)
elif(td == 2):
try:
os.mkdir(f'{movie_name}/good')
cv2.imwrite(f"{movie_name}/good/{n}.png" , frame_img)
except:
cv2.imwrite(f"{movie_name}/good/{n}.png" , frame_img)
elif(td == 3):
try:
os.mkdir(f'{movie_name}/bad')
cv2.imwrite(f"{movie_name}/bad/{n}.png" , frame_img)
except:
cv2.imwrite(f"{movie_name}/bad/{n}.png" , frame_img)
elif(td == 4):
try:
os.mkdir(f'{movie_name}/miss')
cv2.imwrite(f"{movie_name}/miss/{n}.png" , frame_img)
except:
cv2.imwrite(f"{movie_name}/miss/{n}.png" , frame_img)
n += 1
else:
break
great以下が検出されたframeの画像を保存するものである。
judge_analysis('alive')
実際に生成されたファイルの中身は以下の通り。
- alive/great

- alive/good

誤検知があるが、概ね正しく出力ができている。誤検知がある理由として、good以下の学習量が少ないということが考えられる。
まとめ
今までは、キャプチャしたものを自分でスロー再生してgreat以下が出た場所を特定していたため、かなり手間だったがこの手法を用いることにより自動化できるためより容易になる。ただまだ誤検知等Errorが出るため、特にgood以下の学習用データを増やして改良させていきたい。