筆者の開発経験
- C# 10年以上
- Unity 7年以上
Unityの最適化と暗号化と難読化を独学で7年かけて試行錯誤してきた筆者が考える最適化テクニックをご紹介いたします。よろしくお願いします。
暗号化と難読化は以下の記事で紹介しています。
2025/12/02 以下の内容を更新しました。
- 削除:パフォーマンスの簡易的な比較結果を削除
(余りに取って付けたようなものだったので…。
こういうのはやはりゲームの規模や使用しているアセットとの兼ね合いで変化するので、最後に信じられるのは自分のプロジェクトで計測した結果です。) - 2.最適化テクニック > 2.1.グラフィック面 に
「アップスケーリングを使用する(2025/12/02追加) ★5」を追加
想定している読者
- Unityゲームのパフォーマンスを向上させたい人
- ソースコードの可読性とパフォーマンスを両立したコーディングがしたい人
- 3Dモデルを多用するゲーム開発を考えている・進めている人
(2Dゲーム開発者でも十分参考になる情報を詰め込んでいます) -
値型と参照型の違いなど基礎知識がある人
または知識が無くても必要に応じて自力で調べて補完できる人 -
バージョン2021LTS(2021.3.*f1)~2022LTS(2022.3.*f1)を使用している人
(2020以前、2023以降でもある程度は通用しますが、Unityの機能の違いにより必ずしも最適な手法とは限らなくなります) -
Unity6を使用している人(2024/10/19追記)
本記事に書かれている内容に関してはUnity6でも通用することを確認しました。
ただ、本記事に書かれていないUnity6で登場した第三の最適化手法のほうが本記事の最適化手法を上回っている可能性も無きにしも非ずです。
結論
先に本記事の結論を簡単にまとめます。より具体的な最適化手法は本文を読み進めていただければと思います。
-
事前に指標を明確にしておく
「目標フレームレートは60FPSとする」「最大解像度は1920x1080とする」「メモリは最低8GBとする」など、具体的な値を交えた指標を予め決めておく
この軸が曖昧だと最適化の方針もブレブレになってしまう -
負荷が高い処理やGC.Allocの発生は可能な限り回避する
避けられない場合はロード画面など特定のタイミングで纏めて実行する -
複数のスレッドに分散させることができる処理は積極的に並列化する
基本的に「ゲームが重い」とはメインスレッドやレンダースレッドなどの特定のスレッドに負荷が集中している状態のこと -
最適化する場合は必ずProfilerで最適化前後のパフォーマンスを比較する
ある場所の最適化をした結果、別の場所にしわ寄せがいって総合的には遅くなっていた、という事態もあり得る
速くなってそうに見えるという感覚頼りの最適化は危険
こんな事言っといてなんですが、本記事は”筆者が以前検証した時はこうだった”という経験則をベースに話しているので、本記事自体は詳細な検証を行うことを目的としていません。
元よりこの手の記事は鵜呑みにせず、きちんと自分で裏取りをしたほうがよいと思いますが、本記事がその足掛かり程度になれれば幸いです。
-
最適化手法の多くは、作りたいゲームによって適用条件や効果が異なる
本記事の最適化手法は基本的に万人に通じるものをピックアップしているが、3Dゲームと2Dゲーム、アクション系とRPG系、スマホ向けとPC向けなど、作りたいゲームによって効果の高い最適化手法は異なってくる
全Unity開発者に見てほしい必読書
サイバーエージェントが2022年に公開した「Unityパフォーマンスチューニングバイブル」という書籍があります。
Githubからpdfをダウンロードしてすぐに見ることができます。
総ページ数は300ページもあり、パフォーマンスを最適化するための様々なノウハウが書かれていますが、パフォーマンス以外にもUnityのAssetBundleやメモリの仕様など基本的な知識が盛りだくさんです。
この一冊を熟読すれば、Unity初心者も中級者も開発効率が大幅に上がって、パフォーマンス的にも無駄のないゲーム開発ができるようになるでしょう。
とはいえ300ページの内容を全部頭に叩き込めというのは簡単な話ではないと思いますので、本記事ではこの書籍を参考文献として、筆者の経験則を交えながらパフォーマンスの最適化において重要な情報をピックアップしていきたいと思います。
覚えておきたい用語
本記事を読まれる方は以下の用語は最低限覚えていただければと思います。
GC.Alloc
Unityはガベージコレクタという機構を持っており、メモリの拡張や解放はプログラムが自動で行います。クラスのインスタンスをnewで生成したりList.Addした時などメモリを拡張する際に発生するのがGC.Allocです。詳細はUnityパフォーマンスチューニングバイブルが詳しいです。
GC.Allocは塵積でゲームに負荷を与えるため極力発生させたくないですが、ゲーム全体からGC.Allocを排除することが正義というわけではなく、無駄なGC.Allocを減らすことがパフォーマンス最適化への近道の1つとなります。
CPUバウンド、GPUバウンド
CPUに負荷が集中している状態をCPUバウンド、GPUに負荷が集中している状態をGPUバウンドと呼びます。
CPUとGPUはリンクしているので、片方だけ軽くしてももう片方に高負荷がかかっていてはパフォーマンスは改善されません。
CPUバウンドの状態ではCPU負荷を軽減すること、GPUバウンドの状態ではGPU負荷を軽減することが優先事項となります。
ドローコール・セットパスコール
オブジェクトを画面に描画する際、CPUからGPUに命令が送られます(ドローコール)。
その際、Rendererの持つMaterialの情報を必要に応じてGPUに送信します(セットパスコール)。
セットパスコールが多いとCPUに負荷がかかりますが、CPUから送られてきた情報を処理するGPUにも負荷がかかるので、セットパスコールは高パフォーマンスを維持するためのクリティカルな指標の1つとなります。

バッチング
画面内のオブジェクトを特定の条件でまとめて描画する事をバッチングと呼びます。GPUの負荷軽減において非常に大きな効果を発揮する手法です。
中でもSRP Batcherは適用条件が比較的易しくて汎用性も高く、URPやHDRPを使用するのであれば最優先で適用させることを推奨します。
(具体的な適用方法は本記事では割愛します)
1. 最適化の基本
パフォーマンスの最適化における基本事項をまとめました。
1.1. メモリとCPUとGPU
Unityのパフォーマンスを最適化するにあたって考慮しなければいけない事項は色々ありますが、まず考えなければならないのはメモリとCPUとGPUです。
※正確にはストレージもありますが重要度は他3つより低いので本記事では割愛します。
基本的にこの3つとも最小コストかつ最大パフォーマンスというのは不可能で、これらはトレードオフの関係にあります。
例えば使用メモリを削減するとCPUやGPUの負荷が上がったり、CPUの負荷を抑えようとするとGPUにしわ寄せがいったりメモリの消費が増えたり、ということになります。
なので自分がどれを優先したいかによって、最適化の最適解は変わってきます。
基本的に2Dゲームでは一般的にGPU負荷はそこまで高くないので、CPUとメモリにだけ気を遣えば最適化は充分できます。
一方で3DゲームはGPUをかなり使うので、何も考えずに高ポリゴン数の3Dモデルを使用したり3Dオブジェクトを大量に並べたりすると一気にGPUバウンドになります。
どれか1つを最適化すれば良いというものではなく、3つともバランス良く使用するように調整する必要があります。
1.2. パフォーマンスと可読性
ゲームのパフォーマンスとソースコードの可読性もトレードオフです。
コンポーネントが持っているフィールドを例に考えてみましょう。
要件は以下の通りです。
- 敵のオブジェクト1つにつき当該コンポーネントを1つ付ける
- キャラクターの表示名を変数の値として保持する
- キャラクターの表示名は外部のクラスから読み取れ、クラスの内部で読み書きできる
まずは上の要件で、パフォーマンス最強かつ可読性最悪なコンポーネントがこちらになります。
public class EnemyComponent : MonoBehaviour
{
public string charaName;
}
非常に単純なフィールド定義です。
Unity初心者はよくこうするのではないでしょうか。筆者も最初はこうでした。
publicなフィールドを持たせたので、クラスの内部からも外部のクラスからも読み書きできます。
これでは外部のクラスが誤ってこのフィールドを書き換えてしまっても気づきにくくなってしまい、非常に管理しづらくなってしまいます。
そこで使えるのがプロパティです。
値の読み取りはpublic、書き込みはprivateにします。
public class EnemyComponent : MonoBehaviour
{
public string charaName { get; private set; }
}
これで値の読み取りは外部のクラスからもこれまで通り行えつつ、クラスの内部からのみ値の書き込みが行えるようになりました。
ただしこれはパフォーマンスが少し低下します。
内部的にはprivateな変数がもう1つ作られてその変数を読み書きするため、1回分のオーバーヘッドが発生します。
つまり以下のコードと同等のパフォーマンスになります。
public class EnemyComponent : MonoBehaviour
{
public string charaName
{
get => this._charaName;
set => this._charaName = value;
}
private string _charaName;
}
これが具体的にどの程度パフォーマンスに影響するのかというと、値の読み書きを何百万回何千万回実行したところで1ミリ秒にも届きません。
なので誤差レベルです。これが許容できないほど切羽詰まった状況では根本的な設計から見直して大幅な改修をしたほうが良いと思います…。
ちなみに過去の私はその1ミリ秒未満のためにこんなことをしていた時期がありました。
#region public string charaName { get; private set; }
#if UNITY_EDITOR
public string charaName { get { return this._charaName; } private set { this._charaName = value; } }
private string _charaName = null;
#else
[NonSerialized] public string charaName;
#endif
#endregion
エディタではプロパティとして動き、プレイヤーでは普通のフィールドとして動作するキモいコードです。regionのおかげでエディタ上の見栄えは大して変わらないから大丈夫だろうと思っていた頃でした。

結局管理が面倒になって辞めました。素直にプロパティを使いましょう。
…と、一例にしてはやたら長くなってしまいましたが、可読性とパフォーマンスは両立させるのが難しいというお話でした。
2. 最適化テクニック
それではいよいよ、筆者が知りえる具体的な最適化テクニックのご紹介です。
2.1. グラフィック面
グラフィック面の最適化アプローチについて、筆者なりの見解を7段階評価で紹介いたします。(★1=効果が小さい、★7=効果が大きい)
# 描画解像度を下げる ★3
例えばウィンドウサイズが1920x1080の場合、半分の960x540にすると描画面積は4分の1になります。
これによって単純にGPUメモリの使用量も大幅に下がり、描画負荷も大きく抑えることができます。
具体的にどの程度軽くなるかは環境によりますが、GPUバウンドの環境に対してはかなり効果的です。
ちなみにURPの環境では、UniversalRenderPipelineAsset > Quality > Render Scale にも注意を払う必要があります。
これを最大の2にすると描画は綺麗になりますが、例えばウィンドウサイズが1920x1080の環境では内部的に3840x2160で描画されることになってしまいます。
品質設定のバリエーションを用意するのであれば、最高品質のRenderScale:2の他に、1個2個下の品質としてRenderScale:1以下を用意するのが望ましいです。

# アップスケーリングを使用する(2025/12/02追加) ★5
本記事の初回執筆時点では筆者の眼中になかったのですが、時を経てアップスケーリングが筆者の中でかなり実用的な域に達したのでご紹介します。
「アップスケーリング」という技術を採用するメリットおよびデメリットは、簡潔に説明すると以下の通りです。
メリット
- Unity内部で処理される画面の描画面積を小さくする
→GPU負荷が大幅に下がる
デメリット
- 描画結果の画面の品質がアップスケーリング未使用時に比べて低下する
要するに内部での描画処理を一旦小さな解像度で済ませてから元の解像度に引き延ばすのがアップスケーリングです。
このアップスケーリングの利点と欠点が実際どんなものなのか、以下の記事で比較しておりますので興味があればご一読ください。
# 影の解像度を下げる ★2
3Dオブジェクトが落とす影の解像度も変更できます。URPの環境ではUniversalRenderPipelineAsset > Lighting > Main Light > Shadow Resolution です。

これはパフォーマンスへの影響はさして高くないように思います。
描画解像度など他の優先事項を全て適用したうえで更に軽くしたいといったときに影の解像度を落とすと多少は効果があるかもしれません。
# ポストエフェクトを切る ★2
ポストエフェクトは画面全体に行われる処理なので一般的に重いです。
ただ筆者の経験則だとポストエフェクト単体はオンでもオフでもパフォーマンスに大きな影響は見られませんでした。
筆者はポストエフェクトの性能検証はざっくりとしか行ってないので、情報が必要な方はちゃんと検証されたほうが良いかもしれません。
# ポリゴン数を落とす(LOD) ★3
3Dモデルはポリゴン(頂点)の集まりで構成されているオブジェクトです。スマホアプリの3Dキャラクターでは、低いもので1体数千、高いもので1体5~6万ポリゴンになります。
ポリゴン数によるパフォーマンス低下はスマホ版が特に影響を受けやすいです。画面に何万ポリゴンも表示された状態が長く続くとバッテリーの減りも早く、動作もカクつき易くなります。
GPUバウンドの環境であればPC版でもある程度効果を発揮するでしょう。
# カリングを適用する ★5
カメラの描画範囲外のオブジェクトの描画処理を省く視錐台カリング、モデルの裏面の描画を省く背面カリング、オブジェクトに遮蔽されて映らないオブジェクトの描画を省くオクルージョンカリングを適用することで、描画負荷を大きく下げることができます。
中でも視錐台カリングは比較的適用しやすくデフォルトで有効ですが、シェーダやメッシュの設定によっては適用されないことがあるので、無駄な描画が発生してないか入念にチェックしておいたほうが良いでしょう。
# バッチング(SRP Batcher)を適用する ★5
URPやHDRPの環境では、3Dオブジェクトを描画するシェーダへのSRP Batcherの適用が必須級です。
前項でも軽く触れたセットパスコールですが、バッチングを適用するとセットパスコールが減るので、CPU負荷とGPU負荷を一挙に下げることができます。
ただ、負荷を下げるという表現はよろしくありません。バッチングは当然で、バッチング不適用によるセットパスコールの上昇ひいてはCPU負荷とGPU負荷の上昇はあってはならないことという認識で臨むべきです。それくらい効果が大きいです。
# 同時に出現する3Dオブジェクト(静的オブジェクト)の数を減らす ★1
配置してから基本的に動かない3Dオブジェクトは、GPUへの負担が少ないです。
問題は数が多いのにバッチングを適用していなかったり、ポリゴン数がやたら多い場合です。
バッチングの適用やポリゴン数の削減を行いましょう。
# 同時に出現する3Dキャラクター(動的オブジェクト)の数を減らす ★3
3Dモデルのスキニング(ボーンのTransformを操作することで腕や足部分のメッシュを変形させること)はそこそこCPUに負荷のかかる処理です。
無双系のように何十体ものキャラクターが画面を暴れ回るようなゲームはスキニングの負荷が如実に表れると思うので、バッチングやLODなどの手法を織り交ぜてなるべく最適化したほうが良いです。
# 同時に出現する3Dキャラクター(動的オブジェクト)の数や種類を減らす ★7
本項を7段階評価にしたのはコレのためです。
筆者の経験上最も負荷が高くなる行為は、異なる複数種類の3Dキャラクターを大量に配置して動かすことでした。
UnityにはCPU負荷やGPU負荷を下げるためのあらゆるアプローチがありますが、複数種類のキャラクターを大量に動かすというのは非常に攻撃力が高く、ほとんどの負荷低減アプローチが通用しません。
## GPUインスタンシング
バッチングの類似機能としてGPUインスタンシングがあります。
これは同じメッシュを持つオブジェクトに対してバッチングと同じ効果を適用する機能です。
過去に試したところ2種類64体のキャラクターを同時に動かしても120FPSが安定して出るという驚異的な効果を発揮しました。

ところが種類が異なるキャラクターを何種類もとなると効果は失われ、30FPSすら維持できなくなってしまいました。
## Dynamic Batching
Project Settings > Player からチェックを入れると適用できるバッチングです。
ただし頂点数300以下という厳しい条件があるため、スキニングさせたいキャラクターにはほぼほぼ適用できないでしょう。
## メッシュ、テクスチャ、マテリアルの使用量削減
1体分のメッシュであれば、頭部分や胴部分などでメッシュが分かれていた場合に結合して1つにすることができます。スキニングはメッシュ1つ1つに対して処理が行われるのでメッシュを結合して数を減らすのも最適化において有効です。
またテクスチャの数を減らすことでメモリ使用量を抑えたりマテリアルを統合しやすくなります。
マテリアルが少ないとそれだけCPU負荷を抑えられますし、バッチング自体の負荷の抑制にもつながります。
これらの手法も複数種類のキャラクターを大量に動かしたいときは難しいです。
## DOTSへ移行する
これも一度本気で試しました。
最大の課題はDOTSはスキニングのシステムが無い点でしたが、DOTSにスキニングを導入できるアセットで対応しました。
しかしDOTSはスキニングが無いからこそ爆速を生み出している一面もあり、スキニングを導入した途端にSRP Batcherも剥がされスキニング処理自体普通に重くて全然パフォーマンスが出ませんでした…。
## BatchRendererGroupへ移行する
BatchRendererGroupというドローコール発行APIへの移行も試したことがあります。
ドローコール発行APIなので、シェーダに送る描画情報を丸々ゲーム開発者が管理することになります。
カリングやインスタンシングの管理もゲーム開発者に委ねられるので、使いこなせればURPによる従来のスキニングより軽くなるらしいです。先駆者の記事を以下に貼っておきます。
これを実際に試してみたのですが、まずAnimationClipやMeshを独自のフォーマットに作り直すというのがハードルが高く、ただでさえBatchRendererGroupの情報が少なかったのに加えてスキニングは更に情報が少なすぎて全然最適化できず、動きはしたもののパフォーマンスはSkinnedMeshRendererに勝てませんでした…。
仮にある程度の最適化ができたとしても、BatchRendererGroupはメッシュ単位での描画発行を行うとのことなので複数種類のキャラクターとなるとパフォーマンスはあまり出なさそうです。
## Unity2023でスキニングがバッチ化されたよ~!
メッシュが同一であることがバッチングの条件だから複数種類のキャラクターには意味ないよ~!(完)
## マテリアルの操作を減らす
これはかなり少数派なケースだと思います。
例えば、キャラクターの正面や上の向きを使ってシェーダで何らかの処理をしたいことがあります。
そういう場合、フレーム毎にMaterial.SetVectorを呼び出して値をセットします。
実はこのMaterial.Set系は地味に負荷が高いです。
具体的には30種類のキャラクターに計800個以上のマテリアルが付いていて、Material.Set系を実行しなければ130FPS出る条件下で、Material.Set系を毎フレーム実行すると70FPS前後まで下がってしまいました。
実際のゲームではキャラクター以外にも背景やエフェクトがあることを考慮すると、この低下は無視できません。
筆者はこういった値をシェーダのグローバル変数に持たせて更新回数を減らすことで、無事130FPSまで回復させることができました。
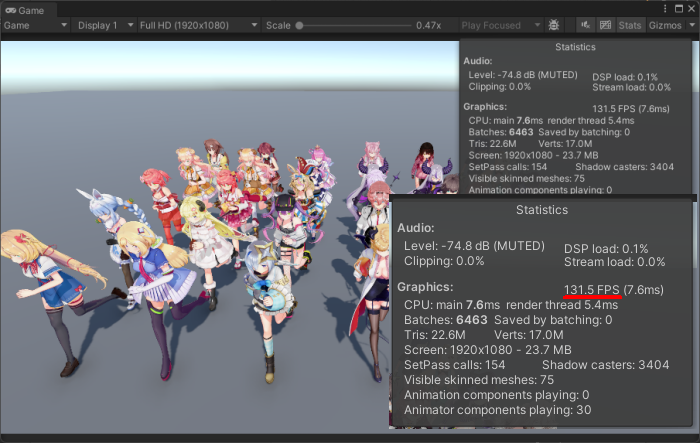
# グラフィック最適化まとめ
2、3体程度の少数のキャラクターしか画面に出ないゲームであれば、複雑な最適化を施さずともバッチングなどの基本を押さえれば一定のパフォーマンスを出せると思います。
ですがスマ○ラのような何種類ものキャラクターが大人数動き回るゲームを作ろうとしている方は、最適化の難易度がグッと上がるのでそれなりに苦戦することでしょう。
複数種類のキャラクターを大量に動かす際に有効なのはやはりSRP Batcherです。むしろコイツしか頼れないので最大限にSRP Batcherを活かしましょう。
もちろん比較的軽めのゲームでも負荷は塵積なので、ポリゴン数やクオリティ設定などに無駄があると積もり積もってパフォーマンスの低下に繋がります。
無駄をなくすことだけに注力するか、少しでもパフォーマンスを上げるために使える最適化手法は最大限に取り入れるか、明確なラインを定めてからゲーム開発に臨むべきでしょう。
# Tips. Material.Set系を毎フレーム実行してはいけない理由
こちらの記事に書かれていますが、
(SRP Batcherとは)一言でいえば、Draw Call毎にConstant Bufferを更新するという非効率な仕組みをやめたということです。これによりレンダリングに関連するCPUコストが削減されます。
とのことで、Material.Set系を実行したフレームではConstant Bufferの更新が走るので、それを毎フレーム実行するとSRP Batcherの強みが打ち消されてしまうという理屈でした。
2.2. システム面
システム面の最適化アプローチについて、筆者なりの見解を7段階評価で紹介いたします。(★1=効果が小さい、★7=効果が大きい)
# 処理の並列化(非同期化) ★7
システム面の最適化で最も意識すべきなのは、処理の並列化とGC.Allocの削減だと筆者は考えます。
まずは処理の並列化について考えましょう。
## 並列化とは?
一般的にはスレッド化やマルチスレッド処理などと呼ばれます。
Unityは通常メインスレッドと呼ばれるスレッドで処理が行われるため、リソースの読み込みやダメージ計算など全ての処理をメインスレッドで行おうとすると1フレームあたりの処理時間が長くなり、結果として規定のフレームレートを維持できなくなります。最適化の目的とは即ち規定のフレームレートを維持することなので、これは致命的です。
そのため複数のスレッドに処理を分散させて並列で処理することで、1フレームあたりの処理時間を短縮させようという考え方が並列化です。

Unityには複数種類のスレッドが存在します。メインスレッドの他に、GPUへの描画情報送信処理を担うレンダースレッドや、JobSystem等が利用するワーカースレッドなどがあります。
処理の高速化において一番手っ取り早くて効果が大きいのは並列化ですが、なんでもかんでも別のスレッドへ逃がすことはできません。
Transform.positionやGameObject.SetActive、GameObject.activeInHierarchyやTime.timeScaleなど、UnityEngineに依存しているクラスのメンバのほとんどはメインスレッドからのみアクセスでき、メインスレッド以外からアクセスしようとするとエラーになります。
Unity内部でオブジェクトの整合性を保つための制約なのでしょうが、この制約によってUnityゲームにおける並列化はかなり選択肢が少ないです。
## 非同期処理(async/await)
Unityゲーム開発者にできる並列化は、メインスレッドの処理を他のスレッドへ逃がすことです。その手法の1つがコルーチンまたはasync/awaitです。
パフォーマンス的に優れたasync/awaitとUniTaskの登場により最早コルーチンは過去のものなので(偏見)、本記事ではasync/awaitについて触れます。
例えばセーブデータのファイルを読み込みたいとします。この読み込みに1秒かかるとしましょう。セーブデータの読み込みをメインスレッドで同期的に行うと、ゲームが1秒間固まることになります。これはよろしくありません。
そこで使えるのがasync/awaitです。ファイルの読み込み処理をメインスレッドから別のスレッドへ逃がすことで、メインスレッドが固まることなくセーブデータを読み込むことができます。
private async void Start()
{
Debug.Log("非同期読み込み開始!");
await UniTask.RunOnThreadPool(() =>
{
using (FileStream fileStream = new FileStream(@"C:\save.txt", FileMode.Open, FileAccess.Read))
{
byte[] output = new byte[fileStream.Length];
fileStream.Read(output, 0, output.Length);
string text = Encoding.UTF8.GetString(output);
Debug.Log($"読み込んだ文字列は{text}です。");
}
});
Debug.Log("非同期読み込み終了!");
}
また、Resourcesの非同期読み込みに使えるResources.LoadAsyncや、AssetBundleの非同期読み込みに使えるAssetBundle.LoadFromFileAsyncなどがあります。
private async void Start()
{
AssetBundleCreateRequest request = AssetBundle.LoadFromFileAsync(@"C:\hoge.unity3d");
await request;
}
2024/11/16追記
細かい話になりますが、非同期処理と並列化は異なるものになります。
あくまでAssetBundle.LoadFromFileAsyncのようなメソッドを使うことで、マルチスレッドなAPIを非同期で使える、ということになります。
本記事では最適化手法としてこういったものが存在するということを伝えることを主目的とするため、この辺りの細かい定義等は本記事では割愛させていただきます。
## AssetBundleの読み込みの並列化
なお、暗号化されたAssetBundleを読み込むためにAssetBundle.LoadFromStreamAsyncを使われている方も多いと思いますが、AssetBundle.LoadFromStreamAsyncを介して呼び出されたStream.ReadはPreloadManagerというスレッドで同期的に行われます。
AssetBundleの復号処理を行うのは大抵の場合Stream.Readなので、結果として AssetBundle.LoadFromStreamAsyncを使うとAssetBundleは並列で読み込むことができません。
メインスレッドではないのでゲームが固まることはありませんが、暗号化された大量のAssetBundleの読み込みを並列化することはできないということです・・・。
(AssetBundle.LoadFromFileAsyncとAssetBundle.LoadFromMemoryAsyncなら並列化は可能ですが、暗号化されたAssetBundleの読み込みにはどちらも適していません)
## JobSystem+Burst
何がなんでもUnityのAPIへのアクセスをメインスレッド限定にしたかったUnityチーム(偏見)によって捻り出された(と筆者は思っている)のがBurstコンパイラです。
仕組みはやはりUnityパフォーマンスチューニングバイブルが詳しいので割愛しますが、BurstでコンパイルすればIL2CPP並みに処理速度が上がります。
ただし何でもかんでもBurstコンパイルできるわけではなく、非常に強い制約があります。
それは値型しか使えないことです。Burstコンパイルの対象にできるのはJobSystemに則った構造体(Job)のみで、このJobの中で値型しか使えないのはもちろん、Jobの外にあるクラスへのアクセスも禁じられています。
アクセスすると警告やエラーが出てしまい、Burstコンパイルも適用されません。
この制約によってUnityのAPIへのアクセスもほとんどできないため使い道自体あまりないかもしれません。幸い特別にTransformのpositionやrotationへアクセスする手段は用意されているので、Burstと相性が良いのは精々揺れ物システムくらいでしょうか。
[BurstCompile]
private struct SampleJob : IJob
{
[ReadOnly]
public NativeArray<float> m_inputA;
[ReadOnly]
public NativeArray<float> m_inputB;
[WriteOnly]
public NativeArray<float> m_output;
public void Execute()
{
for (int i = 0; i < this.m_inputA.Length; i++)
{
this.m_output[i] = this.m_inputA[i] * this.m_inputB[i];
}
}
}
Burstで使用可能なコレクションとしてNativeArrayがあります。NativeArray自体は構造体ですが内部的にC++側のメモリ領域に固定長配列を保持しています。
また、1回のジョブの実行で同一のNativeArray変数に読み書きを両方するのもタブーなので、実質的にReadOnly属性とWriteOnly属性も必須となります。
JobSystem+Burstの詳細については本記事では割愛しますが、Burstコンパイルされた処理はワーカースレッドという数十個も用意されるスレッドで並列実行されてくれるので効果は絶大です。元より値型しか扱わないのも相まって超爆速になります。
筆者が検証したところ、30体のキャラクターにスカートや髪等の揺れ物システムを通常通り実装して1フレームあたり16ミリ秒かかったところ、JobSystem+Burstに移行したら1フレームあたり5ミリ秒まで短縮することができました。しんどかった……。
なお、JobSystemはメインスレッドを起点にしてワーカースレッドに処理を分散させた後、メインスレッドに必ず戻る必要があります。同一フレーム内で実行開始から実行終了まで完結させないといけないので、複数のフレームに跨ぐことはできません。そのためJobSystem+Burstは1フレームに収まる処理にしか使えないという制約もあります。
## 積極的に並列化しよう!
というわけで、並列化はパフォーマンスの高速化において重要なファクターです。最適化とは重い処理を軽くすることだけではなく、速さを追求するのもまた最適化です。
ただしご紹介した通りUnityは何かと制約が強いので、具体的に何が並列化できるか調べてどの程度速くなるかをしっかりと検証する必要があります。
# ヒープ確保(GC.Alloc)の削減 ★7
システム面の最適化において処理の並列化と同じくらい強く意識すべきなのはGC.Allocの削減だと筆者は考えます。
## スパイク
前項では、
並列化を行わないとどうなる?
→メインスレッドが渋滞する
→ゲームが一瞬固まる
でしたが本項では
GC.Allocの削減を行わないとどうなる?
→スパイクが発生する
→ゲームが一瞬固まる
です。
スパイクとは何らかの重い処理が瞬間的に行われてメインスレッドが停止することで、即ちゲームが一瞬固まります。
例えば3Dのシューティングゲームで無秩序に弾の3Dオブジェクトを生成しまくるとGC.Allocが大量に発生して、メモリに溜まったガベージを整理しようとGC.Collectが走ることでスパイクは発生します。
また、UnityEngine.Object.Instantiateもかなり重たい処理です。GameObjectの生成自体も負荷が高いですが、GameObjectにアタッチされたRenderer系が持つMaterialのインスタンス化も地味にコストが高いです。これらもスパイクの要因となります。
GCはメインスレッドで処理されるため、並列化で別スレッドに逃がすことはできません。UnityにはIncremental GCというGC.Collectの負荷を分散させる機能がありますが、これは従来1フレームで行われていたGC.Collectを複数フレームに跨がせているだけなので、メインスレッドが逼迫した状態が発生することに変わりはありません。
## GC.Allocとの付き合い方
GC.AllocはUnityゲーム開発者の敵ですが、撲滅することはできません。発生の原因であるクラスのインスタンス化なしでゲームは作れませんし、メモリの拡張や解放を自動でやってくれるのがGCでありUnityの仕様なので、コイツとうまく付き合っていかなければいけません。
最適化を追求してきた筆者としては、GC.Allocとの一番うまい付き合い方は以下の通りだと思います。
-
重い処理(アセットの読み込み、Instantiateなど)はロード画面などで纏めて実行する
ゲーム開発において重たい処理を避けて通ることはできません。かといってゲーム内で戦いが白熱している真っ最中にドデカいGameObjectをInstantiateなんて真似をするわけにもいきません。なのでゲームが固まってよいタイミングでドサッとまとめて重たい処理を片付けてしまうのが得策です。固まってよいタイミングとして真っ先に挙げられるのはロード画面です。アウトゲームからインゲーム、インゲームからアウトゲームへ移行する際のロード画面で必要なAssetBundleを全部読み込んで全部Instantiateします。処理が済んだら最後に明示的にSystem.GC.Collect();を実行して、メモリを綺麗にしてから次の画面に遷移しましょう。
-
GC.Allocが発生する処理はなるべく一回だけ実行されるようにする
GC.Allocが発生しうるすべての処理をロード画面だけで行うこともまた不可能です。初めてメニュー画面を開いたときや初めてステージをクリアした時など、何らかのインスタンスを生成してGC.Allocが発生してしまうタイミングは随所にあります。であればGC.Allocの発生回数を減らす方向で検討するしかありません。具体的には実行結果や生成結果をキャッシュして二回目以降に流用する仕組み(オブジェクトプーリング) を構築します。
詳細は後述のオブジェクトプーリングの項まで読み進めていただければと思います。
-
毎フレーム実行される処理ではGC.Allocを一切発生させない
これもまた徹底すべきです。前の2つはいかにも最適化を意識した設計という感じですが、毎フレームGC.Allocを発生させるのは無駄でしかありません。
小さなGC.Allocでも毎フレーム発生させ続ければ塵積で蓄積していって、やがてGC.Collectによるスパイクが意図しないタイミングで発生してしまいます。
毎フレームゼロアロケーションを意識すれば自ずと綺麗なソースコードになるでしょう。
# MonoビルドではなくIL2CPPビルドを適用する ★6
従来はC#のソースコードをILという中間言語に変換するMonoビルドしか選択肢がありませんでした。この中間言語を実行時に.NET Frameworkによってランタイムで機械語に変換するため処理速度はそこまで速くありませんでした。
そこで登場したのがIL2CPPです。本来は64ビット対応のために作られた機構のようですが、これによりC#のソースコードはC++を介してネイティブコードに変換されるため、処理が非常に高速になります。
IL2CPPが爆速だというのは言わずと知れた周知の事実だと思うので(偏見)、詳細は本記事では割愛します。
Project SettingsからポチポチッとIL2CPPに変更するだけなので、さほど難しくないでしょう。

ちなみに処理の高速化という観点では、IL2CPP Code Generationは「Faster runtime」一択で、C++ Compiler Configurationは「Master」一択です。Unity公式もリリースビルドはMasterを推奨しているようです(Unityパフォーマンスチューニングバイブルからの受け売り)。

# オブジェクトプーリング ★4
前述の通りGC.AllocはUnityゲーム開発者の敵であり、クラスのインスタンスの生成やUnityEngine.Object.InstantiateはGC.Allocを発生させます。
GC.Allocとの付き合い方としてGC.Allocの発生回数を抑えることを挙げましたが、このために有効なのがオブジェクトプーリングと呼ばれる手法です。
その名の通り生成したオブジェクトをプールして何度も使い回します。GC.Allocが発生するのは最初にクラスをnewする時だけになるので、GC.Allocの発生回数を大きく抑えることができます。ただしこれは生成したインスタンスがメモリに残り続けるということなので、メモリとのトレードオフでもあります。闇雲に多用しないほうがいいでしょう。
# インライン化 ★2
効果が大きな最適化手法は粗方紹介してしまったので、後は地道にコツコツと最適化を重ねていくしかありません。
具体的にとなると星の数ほどあるので(あっ★2のことじゃなくて比喩表現のほうです)本記事だけでは紹介しきれないのですが、一つピックアップするとなったら筆者はインライン化をピックアップします。
インライン化とは関数で外出しにしていた処理を呼び出し元の関数の中に取り込むことです。
public void Hoge()
{
for (int i = 0; i < 1000000; i++)
{
this.Fuga(false);
}
for (int i = 0; i < 1000000; i++)
{
this.Fuga(true);
}
}
private void Fuga(bool flag)
{
// 何か処理
}
例えば上のようなロジックがあったとします。
Hoge関数の中で、Fuga関数を100万×2回呼び出しています。
このような実装の場合、Fuga関数を呼び出す200万回分のオーバーヘッドが発生します。
このオーバーヘッドを排除するのがインライン化です。
public void Hoge()
{
for (int i = 0; i < 1000000; i++)
{
// 何か処理(Fuga関数で行っていたもの)
}
for (int i = 0; i < 1000000; i++)
{
// 何か処理(Fuga関数で行っていたもの)
}
}
インライン化すると上のようなコードになります。
Fuga関数で実行していた処理をHoge関数の中で実行するようにしました。
これで200万回分のオーバーヘッドがなくなりました。
ただ、可読性などの観点から何でもかんでもインライン化というわけにもいきません。
そこでソースコードの時点ではインライン化せず、IL2CPPでインライン化を促すMethodImpl(MethodImplOptions.AggressiveInlining)というものが存在します。
public void Hoge()
{
for (int i = 0; i < 1000000; i++)
{
this.Fuga();
}
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private void Fuga()
{
// 何か処理
}
ただしこれは名前の通り積極的なインライン化をコンパイラに促しているだけで、Fuga関数の処理があまりに複雑すぎるとインライン化されません。
具体的にどの程度のコードまでならインライン化されるかというのは一概に言えないのですが、if文やfor文などが多いとインライン化されづらくなるようです。
→2024/11/16追記
ちなみにMethodImpl(MethodImplOptions.AggressiveInlining)はC#をコンパイルする時点でも積極的なインライン化を促してくれますが、IL2CPPだと効果がより強力になります。
また、関数内の処理の大きさもオーバーヘッドに影響するため、必ずしもインライン化することが処理速度の向上に繋がるとは限らないようです。
# システム最適化まとめ
コーディングする際は処理の並列化とGC.Allocの削減を強く意識するとパフォーマンスをグッと最適化することができます。
ただし何事も基本的にはナニかとナニかのトレードオフなので、作りたいゲームの要求スペックや目標フレームレートなどによってどの程度最適化すべきかも変わってきます。
また、最適化にこだわりすぎると開発速度が遅くなってしまいます。締め切りがあるプロジェクトではある程度の妥協の必要なので、その辺りを諸々考慮したうえで最適化の方針を決めてからゲーム開発に臨みましょう。
2.3. 最適化手法の殴り書き
前項までで登場しなかったものの、(筆者的に)地味に看過できなかった最適化手法を以下に殴り書きしていきます。
重要度としては★3~★1相当の情報が中心です。
本記事の初回投稿後に思い出したものがあれば適宜追記していきます。
# UnityのAPIは重い
詳細を見る
GameObject.activeSelfやTransform.localPosition、Component.GetComponentなどのUnityのネイティブ領域で実装されたクラスのメンバは基本的に重いです。
これらは可能な限りC#側でキャッシュして使いまわしたほうがよいです。
# インスタンス化したUnityオブジェクトは最後に必ずDestroy
詳細を見る
Unityはネイティブメモリとマネージドメモリという2つのメモリ空間を持っています。
Unityのエンジン側で読み込まれたリソースはネイティブメモリに置かれ、C#側で読み込まれた文字列やバイナリデータなどはマネージドメモリに置かれます。

例えばComponent.GetComponentはネイティブメモリからコンポーネントの実体を取得して、取得結果(アドレス情報)をマネージドメモリに返します。

それをUnityEngine.Object.Destroyすると、ネイティブメモリにあるコンポーネントの実体は破棄されますが、マネージドメモリのアドレス情報は破棄されません。
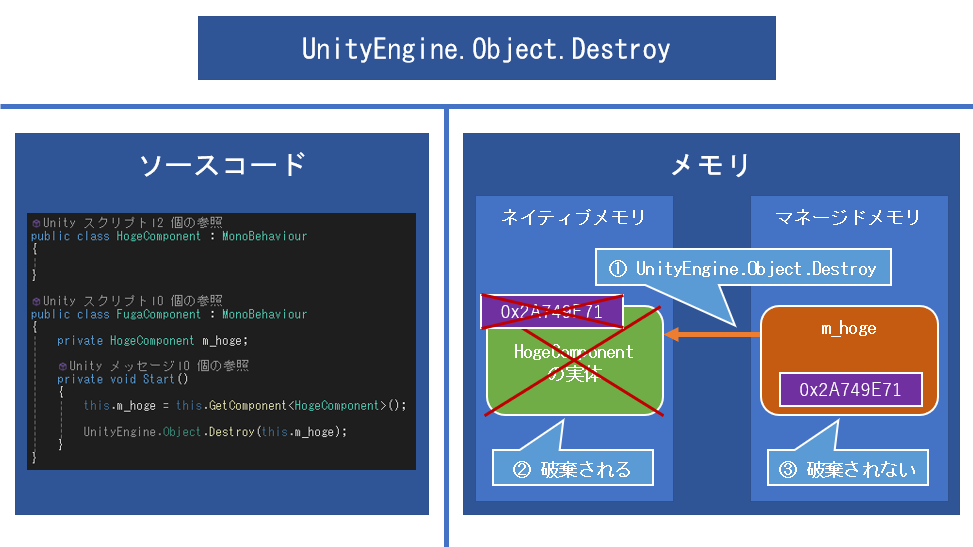
この状態になったUnityEngine.Objectは、UnityEngine.Object == nullはtrueを返すものの、マネージドメモリにはアドレスが残り続けてるという中途半端な状態になります。
(ちなみにUnityEngine.Object is nullはきっちりアドレスに対してnullチェックを行うためfalseを返します)
この中途半端な状態のまま放置すると、参照が生きていてガベージコレクションの対象にならないため、メモリにゴミが残り続けてしまうことになります。これがDestroyしたUnityオブジェクトの変数にはちゃんとnullを代入しようと言われる所以です。
特にRenderer.materialsにアクセスするだけで勝手にインスタンスが複製されるマテリアルはDestroyを忘れがちです。Profilerを確認して、確実に破棄できているかチェックしましょう。
# Start、Update、LateUpdateの使用は最小限に
詳細を見る
Unityのイベント関数は地味にコストが高いうえに、何も意識せずゲームを作るとUpdate関数を持つコンポーネントがいつの間にか500個や1000個にもなってしまいがちです。
1000個にもなってくると、環境によっては2~3ミリ秒ほどかかってしまうため削りたいところです。
オススメの方法としては、ゲームオブジェクトを統括するマネージャークラス(シングルトン) を1つ用意して、そこから下の細かなオブジェクトの参照を保持しておきます。
もちろんシングルトンが全てのオブジェクトの参照を直接持つという意味ではなく、シングルトンの下に比較的大きな役割のオブジェクトがあって、その下に小さな役割のオブジェクトがあるといったようにツリー構造にして、適切な親子関係を構築していきます。
そしてUpdateとLateUpdateはシングルトンのみ実装します。シングルトンの下に置いた細かなオブジェクトはUpdateHogeやLateUpdateHogeなどの関数を実装して、シングルトンからソイツらを呼び出します。
こうすることでUnityイベントの呼び出し回数は合計でシングルトンの1回のみになり、その下のオブジェクトは通常のメソッドのオーバーヘッドのみになるため一気に軽量化できます。
また、Unityのイベント関数はGameObjectがアクティブだと常に走ってしまうため、意図しないタイミングでイベントが発火するのを防いでイベントを管理することにも繋がります。
# ラムダ関数の扱い
詳細を見る
ラムダ関数は一度生成されたらキャッシュされるものとそうでないものがありますが、ソースコード上でその条件を満たしているかどうかはぱっと見では分かりづらいです。
なので自動キャッシュはあてにせず自分でキャッシュする仕組みを作ったほうが確実でしょう。
筆者はSourceGeneratorを活用してラムダ関数をキャッシュする仕組みを実装しています。
実際にはラムダ関数ではなく普通のメソッドを用意します。
[RoslynCreateLambdaMethod(RoslynDeclearAccessibility.Private, RoslynActionTypeDefine.Action)]
private void OnHogeComplete()
{
// 何か処理
}
/// <summary>This method is genarated from <see cref="OnHogeComplete"/></summary>
private Action ActiOnHogeComplete
{
get
{
if (_ActiOnHogeComplete == null)
{
_ActiOnHogeComplete = OnHogeComplete;
}
return _ActiOnHogeComplete;
}
}
private Action _ActiOnHogeComplete = null;
上のようなSourceGeneratorの生成コードにより、ActiOnHogeCompleteを使用すれば初回のみGC.Allocが発生して2回目以降のアクセスはキャッシュを参照しつつ、OnHogeCompleteをこれまで通り使用することができます。
# CanvasのオブジェクトはGameObject.SetActiveではなくCanvasGroupで管理する
詳細を見る
Canvasのオブジェクトに対してのGameObject.SetActiveはUIの再構築処理が走って通常のGameObjectに比べて重いため、CanvasGroupのalphaやblockRaycastsで実質的なアクティブ状態を変更するのが望ましいです。
詳細はUnityパフォーマンスチューニングバイブルなどをご参照ください。
# 物理演算を最適化する
詳細を見る
Physics.RaycastAllはGC.Allocが発生するのでPhysics.RaycastNonAllocを使おう、というのは割と有名な話だと思います。
他にも衝突判定を行うレイヤーのマトリクスを設定するなどでも最適化が可能です。
詳細はUnityパフォーマンスチューニングバイブルなどをご参照ください。
# Particleの数を減らす
詳細を見る
Particleの数が多いとCPUにもGPUにも負荷がかかります。
詳細はUnityパフォーマンスチューニングバイブルなどをご参照ください。
ちなみに筆者はエフェクトの大半はUnityアセットストアで調達していますが、Unityアセットストアのエフェクトの多くは1つのParticleをMeshで生成しつつグラフィカルな表現をシェーダに任せていて、パフォーマンス的に優しい作りのものが多いです。
# 文字列の取り扱い
詳細を見る
stringもまたGC.Allocを発生させやすく取り扱いに注意です。
筆者はFastStringとStringBuilderTemporaryを融合した改変ライブラリを作って使用しています。
パフォーマンスはFastStringと同等で使い勝手もよく大変重宝しています。
▼FastString
https://baba-s.hatenablog.com/entry/2017/12/27/083200
▼StringBuilderTemporary
https://baba-s.hatenablog.com/entry/2017/12/11/090000
# for文とforeach文 どっちが良い?
詳細を見る
基本的にはfor文のほうが速いです。一方でforeachのほうが速いこともあるようです。Unityパフォーマンスチューニングバイブル曰く、Listはfor文が速いですが配列はforeach文に分があるようです。
ですがIListやIReadOnlyListのようなEnumeratorが実装されてないインターフェースでforeachするとGC.Allocが発生します。これはもうfor一択でしょう。
IReadOnlyDictionaryもforeachするとGC.Allocしてしまうので、一時的にDictionaryに戻してforeachするかGC.Allocを受け入れるしかありません。
またUnityのAPIは重いので、例えば以下のような実装はNGです。
Renderer[] renderer = this.GetComponent<Renderer>();
for (int i = 0; i < renderer.materials.Length; i++)
{
renderer.materials[i].SetFloat("_Hoge", 0f);
}
この例ではRenderer.materialsをfor文の回数だけ呼び出すことになってしまいます。for文の前にRenderer.materialsを変数に代入して使いましょう。
# enumやstructをキーにしたDictionaryやHashSetはNG
詳細を見る
これは意外と気づきにくい罠です。DictionaryのキーやHashSetの値にenumを使用すると、重複チェックの際にボックス化(→GC.Alloc)が発生します。
structの場合は重複チェックの際に全てのフィールドの値を走査して同値性を確認する処理が走り、これもまた高コストです。
対処は簡単で、DictionaryやHashSetをnewする際にIEqualityComparerを実装したクラスを渡してあげます。
public class EnumComparer<T> : IEqualityComparer<T>
where T : struct, IConvertible, IFormattable, IComparable
{
public static readonly EnumComparer<T> Default = new EnumComparer<T>();
private EnumComparer()
{
}
public bool Equals(T a, T b)
{
return a.GetHashCode() == b.GetHashCode();
}
public int GetHashCode(T value)
{
return value.GetHashCode();
}
}
Dictionary<HogeType, FugaClass> m_hogeFugaMap = new Dictionary<HogeType, FugaClass>(EnumComparer<HogeType>.Default);
→2024/11/16追記
改めてUnity2022で計測してみたところボックス化は発生していませんでした。
Dictionary.Addの初回実行時、IEqualityComparer<T>を実装したDictionaryとそうでないDictionaryのGC.Allocに48Bの差があり、これをボックス化と勘違いしていました。申し訳ない…。

▲ Dictionary.Addの初回実行時、IEqualityComparer<T>無しが196B、有りが148B
初回のDictionary.Add実行時はGC.Allocが発生しますが、2回目以降は綺麗にゼロアロケーションです。
ただし、structはIEquatable<T>を継承してEqualsとGetHashCodeを実装する必要がある点にはご注意ください。
これを忘れないためにIEqualityComparer<T>を実装するんだ、というマイルールを設けるのもありかもしれません。
# List<T>.AddRangeの多用は避けるべき
詳細を見る
List<T>.AddRange(IEnumerable<T>)は、内部で引数のIEnumerable<T>をforeachしているのでGC.Allocが発生します。
別の項でも書きましたが、Enumeratorが実装されてないインターフェースでforeachするとGC.Allocが発生します。
拡張メソッドを作って対応しましょう。
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static List<T> AddRangeEx<T>(this List<T> list, T[] collection)
{
for (int i = 0; i < collection?.Length; i++) list.Add(collection[i]);
return list;
}
上の例は配列版ですが、他にもList版、HashSet版などを作ってしまってもよいかもしれません。
# Unityオブジェクトのnullチェックのコードを簡略化 (2024/9/26追加)
詳細を見る
これはどちらかというと可読性の向上になるのですが、例えば以下のようなコードがあるとします。
if (transform != null)
{
transform.Rotate(0f, 10f, 0f);
}
上のようなコードを簡略化したいとき、従来はNull条件演算子を使います。
transform?.Rotate(0f, 10f, 0f);
普通のクラスに対してNull条件演算子を使うのは問題ありませんが、TransformなどのUnityオブジェクトに対してNull条件演算子を使うのはご法度です。
DestroyしたUnityオブジェクトに対してUnityEngine.Object == nullするとtrueを返しますが、変数自体は生きてるのでUnityEngine.Object is nullやNull条件演算子はnull扱いしてくれません。
詳細は本記事の「インスタンス化したUnityオブジェクトは最後に必ずDestroy」をお読みください。
そこでDestroyしたオブジェクトに対してもNull条件演算子が使えるように一工夫します。
まず以下のような拡張メソッドを作成します。
public static class Extensions
{
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static T GetSafe<T>(this T component) where T : UnityEngine.Object
{
return component != null ? component : null;
}
}
そしてUnityオブジェクトでNull条件演算子を使う際はこうします。
transform.GetSafe()?.Rotate(0f, 10f, 0f);
これだけです。
これでUnityEngine.ObjectがDestroyされていてもGetSafe関数を通した後は完全なnullを返すので、Null条件演算子が正常に動作するようになります。
また、MethodImpl(MethodImplOptions.AggressiveInlining)を付けているのでIL2CPPビルドすればGetSafe関数のオーバーヘッドも無くなります。
# UnityEngine.Object.InstantiateAsyncを有効活用する (2024/9/26追加)
詳細を見る
2022.3.20f1からUnityEngine.Object.InstantiateAsyncが追加されました。
UnityオブジェクトのInstantiateは重いですが、InstantiateAsyncを使えばオブジェクト生成時のスパイクをある程度緩和できるでしょう。
特にこのInstantiateAsyncには、指定したUnityオブジェクトを同時にいくつ生成するかというオプションを指定できるため、背景オブジェクトのような同一のオブジェクトが複数あるようなものを一斉に生成したい時にInstantiateAsyncを使うと効率が良いです。
ただしこれもやはり複数種類のキャラクターの生成に対しては効き目が弱いです。
実はMaterialの複製も地味にコストが高く、何十個何百個ものMaterialの生成は負荷が高いです。
しかもRenderer.materialsにアクセスしたら強制的にメインスレッドでMaterialがInstantiateされるという恐ろしい仕様なので、事前にMaterialをInstantiateAsyncしておくような手が使えません。
仮にできたとしてもInstantiateAsync自体は並列化できないので、300種類のMaterialがあれば単純計算で1フレーム1回InstantiateAsyncすると最低300フレームかかります。
ちなみにGameObjectに適当なコンポーネントをアタッチしてAwakeメソッド内でRenderer.materialsにアクセスするとかいう小賢しい手も通用しません。AwakeメソッドはInstantiateAsyncの管轄外です。
というわけでMaterialの複製は並列化も非同期化もできません。 3Dモデルが持つMaterialの総数を可能な限り減らしておいたほうがよいでしょう。
# プロパティ VS メソッド (2024/9/26追加)
詳細を見る
プロパティは内部的にはメソッドと同じ扱いなのでパフォーマンスも同じです。
どちらを使ってもオーバーヘッドがありますが、[MethodImpl(MethodImplOptions.AggressiveInlining)]を付ければIL2CPPでインライン化を促してくれます。
if文やfor文が多いなど複雑なロジックだとインライン化されづらいですが、付けておいて損はないでしょう。
(正確にはdllの容量やメモリ消費が少し増えるようですので、気になる方は要検証です)
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public void Hoge()
{
// 何か処理
}
public string Fuga
{
[MethodImpl(MethodImplOptions.AggressiveInlining)]
get { /* 何か処理 */ }
[MethodImpl(MethodImplOptions.AggressiveInlining)]
set { /* 何か処理 */ }
}
というわけで性能面ではどちらも変わらないので、可読性を考慮して使い分けるのがベストです。
# Vector3.zeroやQuaternion.Eulerなどの速度 (2024/10/8追加)
詳細を見る
実はVector3系やQuaternionの変数や関数は、Unityのバージョン2019の時点ではUnity標準のものを使うより自前で実装して使うほうが若干速いです。
とはいえその差は何百回も実行して数ミリ秒と実質誤差程度なので、2019時点でもあまり気にする必要はありませんでした。
最近のUnityは最適化されているので、少なくとも2022時点ではUnity標準の変数や関数と全く変わらなくなりました。
# Unityのメモリ(ヒープ)拡張の仕様 (2024/10/8追加)
詳細を見る
Unityでは一度確保されたメモリが解放されることはありません。
GCによってアプリ内では解放されるので、解放した領域に別の値を入れるなどアプリ内で再利用することはできます。
しかし例えば一瞬でも1GBのファイルを読み込んでしまうと、その後にnullを代入しても1GB増えた分のメモリ領域はUnityアプリが終了するまでUnityアプリが掴んだままになります。
Unityが使えるメモリ領域には上限があるので(具体値は一概には言えないがプラットフォームにより異なる)、こまめに変数をnullにしていてもメモリリークが起こらないわけではないということです。
ここで軽くUnityのメモリが拡張されていく流れをご説明します。

例えば上の画像のように2つの変数にそれぞれ4バイトの値と3バイトの値が入っているとします。
この時点で使用しているメモリは合計7バイトです。
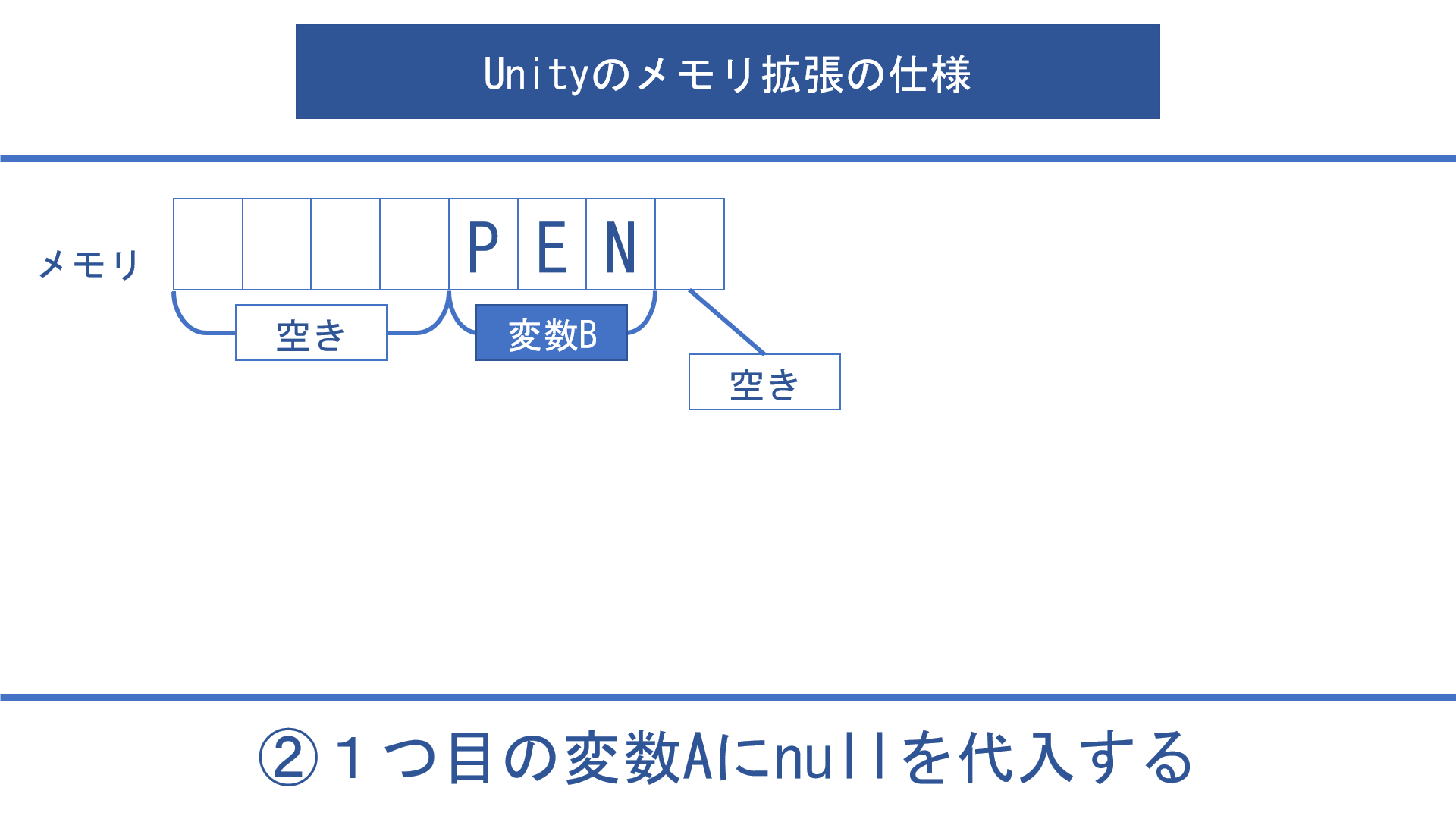
ここで4バイトの値が入っていた変数Aにnullを代入すると、その部分のメモリは解放されます。
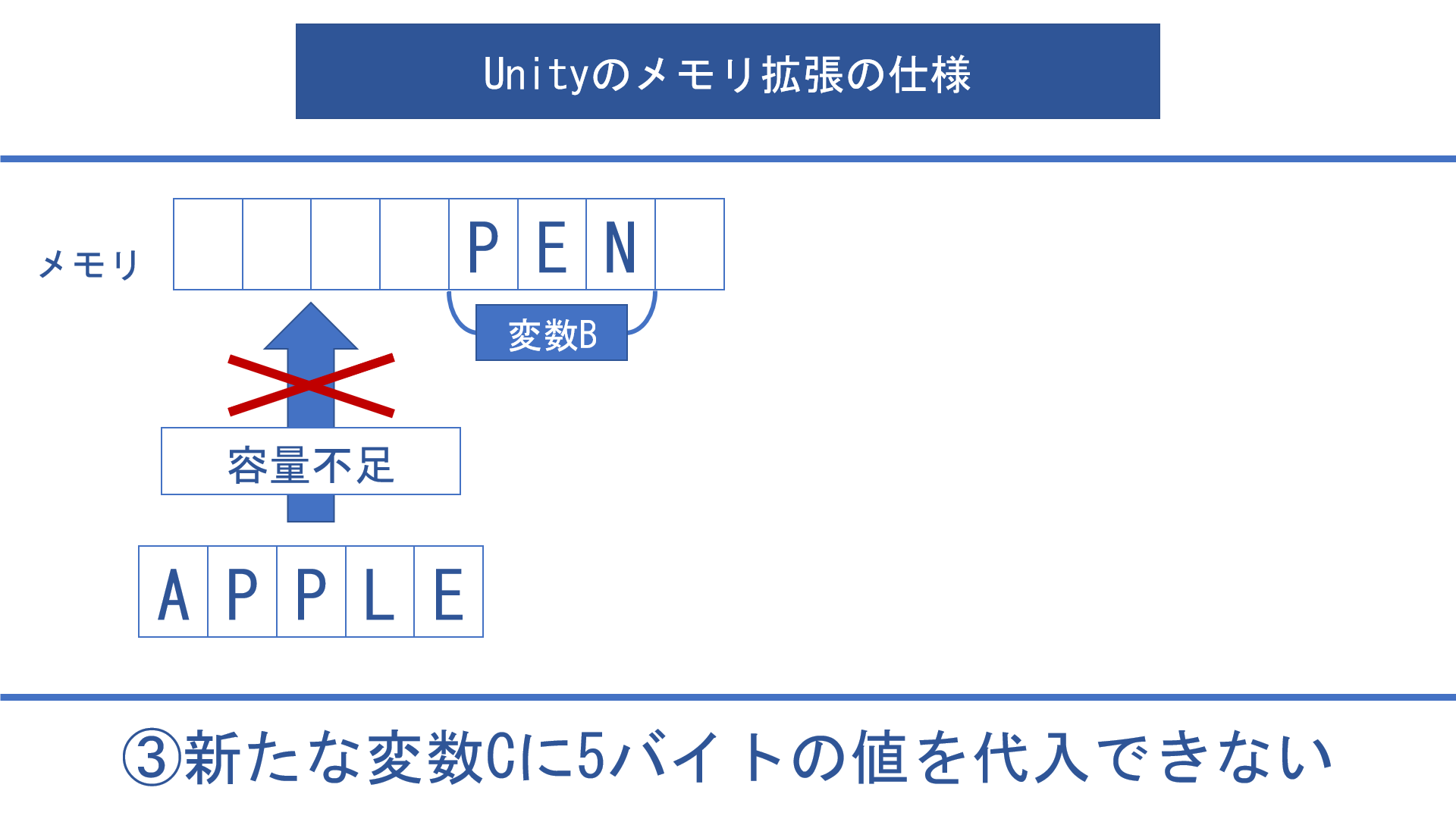
そこに新たに5バイトの値を代入しようとなった時、この例では空き領域は計5バイトありますが値を代入できません。
空き領域はメモリ上で連続している必要があります。
この例だと連続している空き領域は4バイトと1バイトだけなので、5バイトの値を格納することができません。
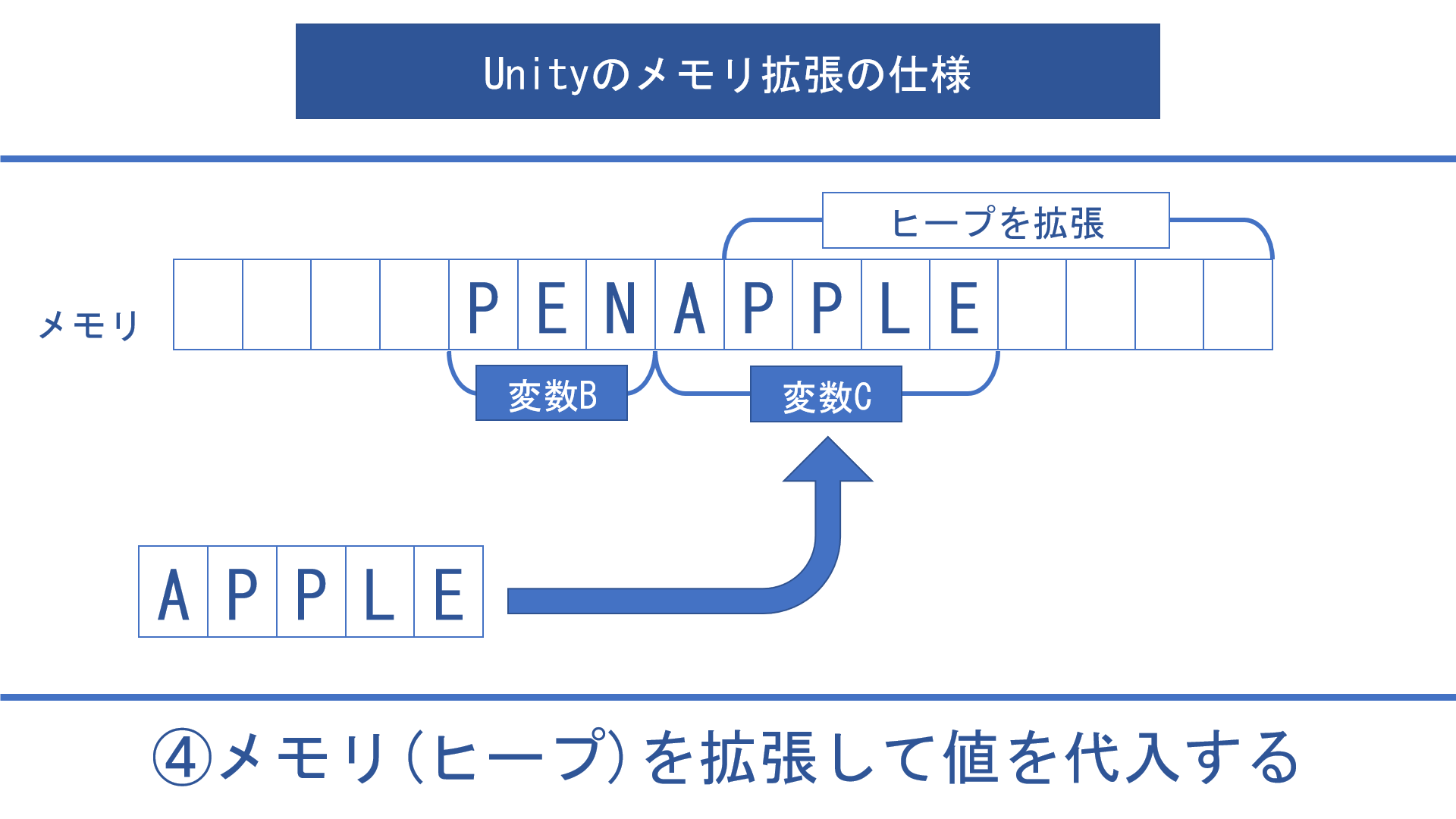
そこでUnityはヒープの拡張を行い新たにメモリ領域を確保します。
これによって5バイトの値を代入することができるようになります。
このようにメモリに格納する値は、メモリ上の連続したスペースに配置する必要があるという性質があります。
これを知ったところでUnityゲーム開発者としてはどうすることもできないのですが、メモリの最適化を考えるうえで知っておくべき知識の1つではあるでしょう。
# IL2CPPのNullチェックと境界チェックの無効化による最適化 (2024/11/16追加)
詳細を見る
IL2CPPにはNullチェックと配列の境界チェックを無効化する方法があります。これを使うと処理がより高速になりますが、Nullチェック無効で値がnullだった場合や境界チェック無効で配列の範囲外のインデックスを参照した際に通常とは異なるエラーの発生の仕方になります。
怖いのでこのエラーを引き起こしたことはないですが、内部的にエラーが起こりつつ表面上は正常な動作が継続してしまって内部の値が恐ろしいことになったり、アプリが強制終了したりしそうです。
詳細はこちらの記事をご参照ください。
▼IL2CPPのオプションについて
https://unityletsgo.hatenablog.com/entry/2020/04/28/175224
# こちらも参考になります
3. 総括
最適化はそれ自体がゲーム開発においてコストなので、最適化手法のコストパフォーマンスを考慮したいところです。
効力は手法によってピンキリで、めちゃくちゃ神経質になって詰めてもパフォーマンスの改善が微々たる手法から、簡単なボタン操作やたった数行の変更だけで劇的にパフォーマンスを向上させられる手法まで種々様々です。
最初にも述べましたが、最適化の最適解は作りたいゲームの要件によって異なってきます。
2Dゲームに対してゴリゴリGPU向けの最適化を施すのはほぼ時間の無駄ですし、3DのハイクオリティなゲームなのにGC.Allocの管理を全然してなければ本来ギリギリ遊べるはずだった人を切り捨てることになってしまいます。
本記事でご紹介させていただいた最適化手法もあくまで「筆者が考えた最強の最適化手法」くらいに捉えたうえで、本記事が自分に合った最適化を見つけるキッカケになれれば幸いです。