データモニタリングとは
機械学習におけるデータモニタリングは、モデルが実際の環境で適切に機能しているかどうかを常に監視し、新しいデータを処理する際に正確性や信頼性が維持されることを保証するために重要です。
業務で機械学習モデルを利用する場合、過去のデータに基づき事前に検証してから適用しますが、業務を取り巻く環境は日々変化しており、その変化に応じてデータも変わっていきます。
これをデータドリフトといい、モデルが正常に機能しなくなったり、予測結果が悪化したりする問題を、データモニタリングを行うことで早期に特定することができます。
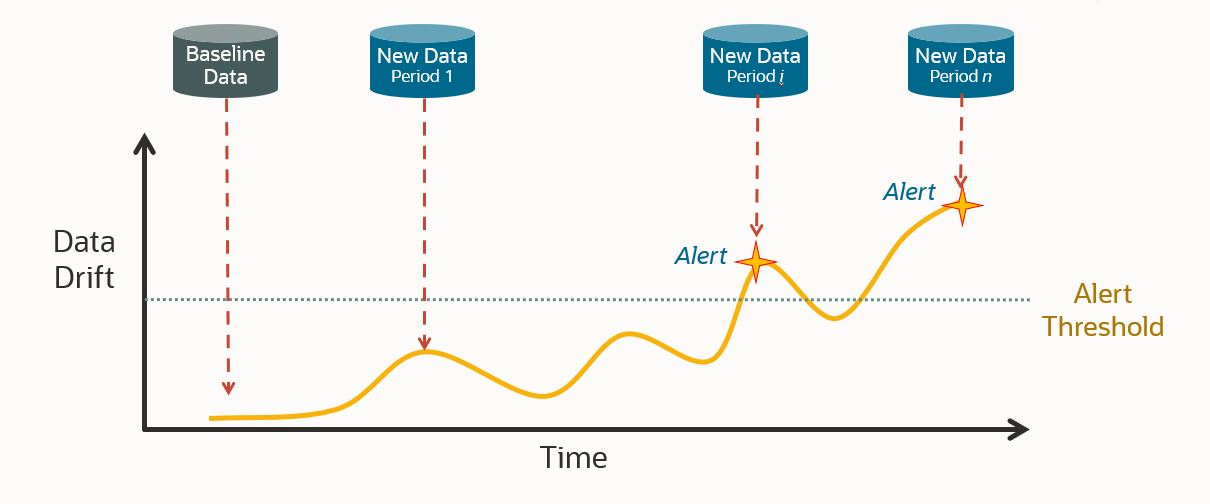
どのようにデータドリフトを検出するのか
データモニタリングは、Oracle Machine Learning(OML)サービスで利用できる新機能です。
この機能は、ベースラインのデータセットと新しいデータを比較することでデータドリフトを検出し、モデルの精度を測定することができます。また、複数期間にわたってドリフトを監視し、新しいデータを動的に追加することもできます。データモニタリングにより、各カラムの変更の影響を示す重要度値や特徴メトリクスが提供され、データのドリフトをより正確に把握できます。
実際にやってみる
それでは実際にサンプルデータを使って、データモニタリングしてみます。
今回使うデータはKaggleのHousehold Electric Power Consumptionです。この例では、4年間の電力消費量のデータセットから、ドリフトを探します。
OMLサービスはRESTインターフェースをサポートしており、エンドポイントにリクエストを送信することでデータモニタリングジョブを作成します。curlコマンドでも良いですが、今回はAPIプラットフォームのPostmanを使ってみます。
1. 前提条件
- Autonomous Databaseインスタンスを作成していること ※今回はAutonomous Data Warehouse(ADW)を作成しています
- Oracle Machine Learning(OML)用のユーザー
OMLUSERを作成していること ※適切な権限付与もしておきます
2. データの準備
Kaggleサイトからダウンロードしたhousehold_power_consumption.txtというデータには、2006年から2010年までの4年間の電力消費量データが入っています。
今回は、2006年と2007年のデータをベースラインデータ(①)、2008年から2010年のデータを監視するデータ(②)とします。
①をHOUSEHOLD_POWER_BASE表として作成しました。
以下のようなデータです。
select * from HOUSEHOLD_POWER_BASE;
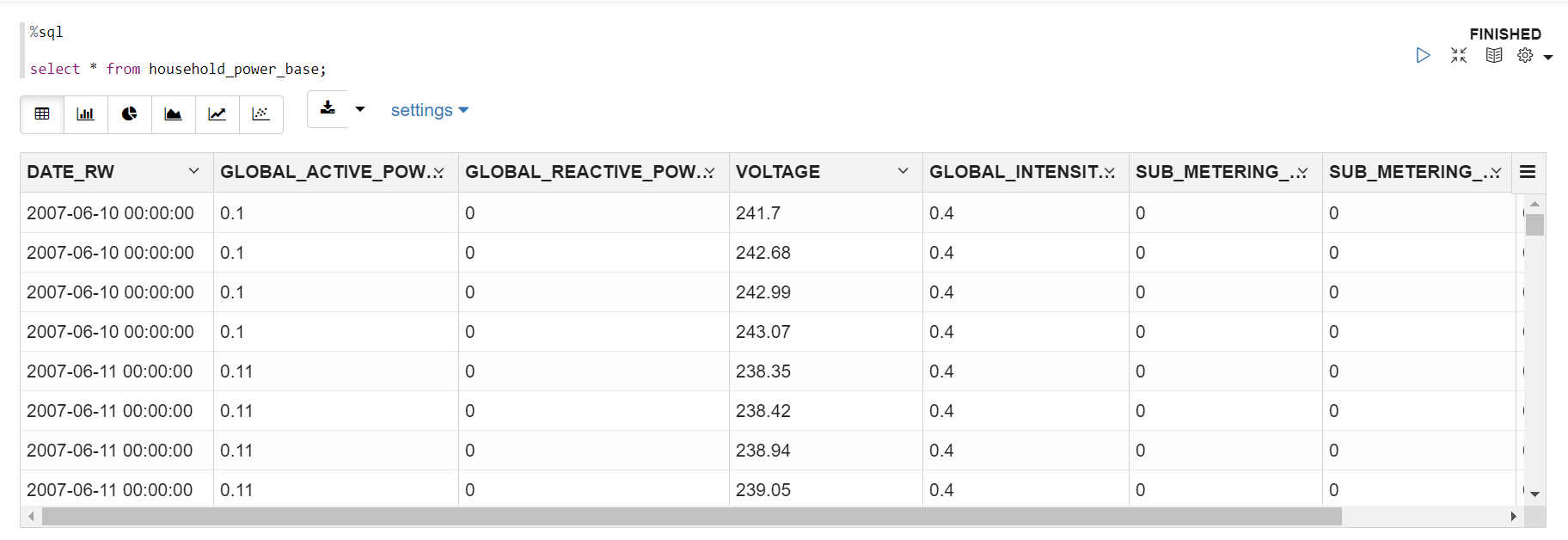
なお、元データhousehold_power_consumption.txtからdate列の日付書式をYYYY-MM-DD HH24:MI:SSに変更し、TIME列は便宜上削除しています。
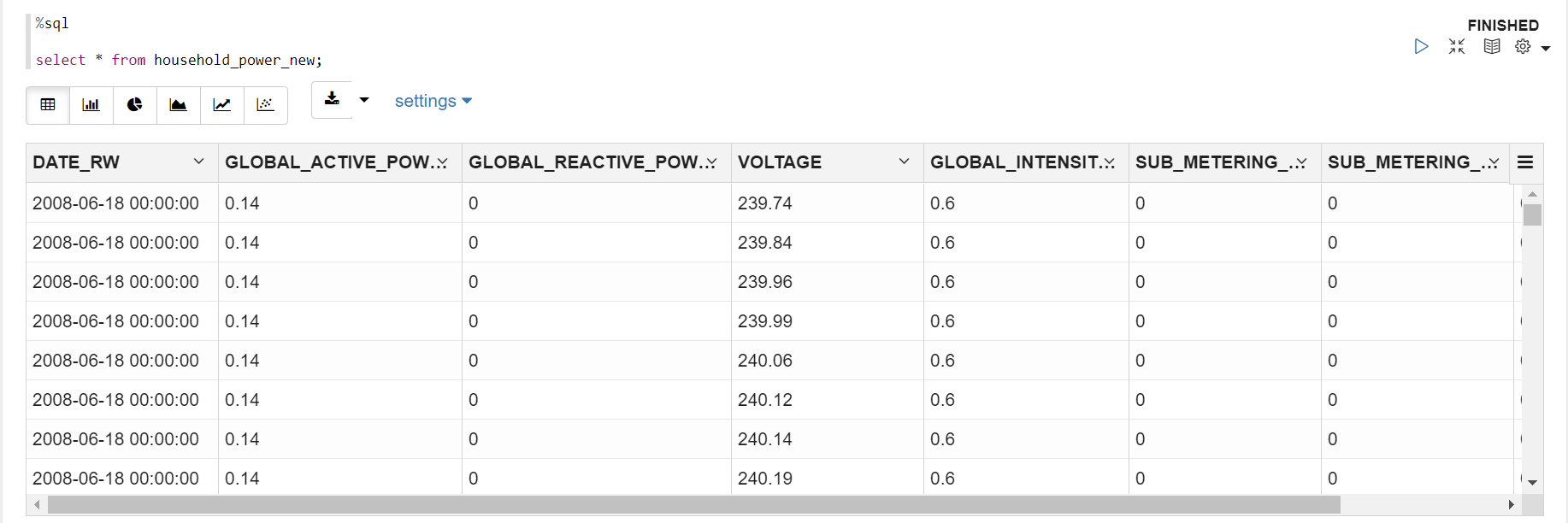
②をHOUSEHOLD_POWER_NEW表として作成しました。
以下のようなデータです。
select * from HOUSEHOLD_POWER_NEW;
3. アクセストークンの取得
データモニタリングジョブを作成するためのリクエストを送信する前に、OMLサービスからアクセストークンを取得する必要があります。そのために、/omlusers/api/oauth2/v1/token のエンドポイントにリクエストを送ります。ここでは、omlsever_token、username、password、tenantの環境変数を設定します。
omlserver_tokenには、OMLインスタンスのベースURLを設定します。Database ActionsのOracle Machine Learning RESTfulサービスから取得します。
一番上のREST認証トークン用のURLをコピーします。
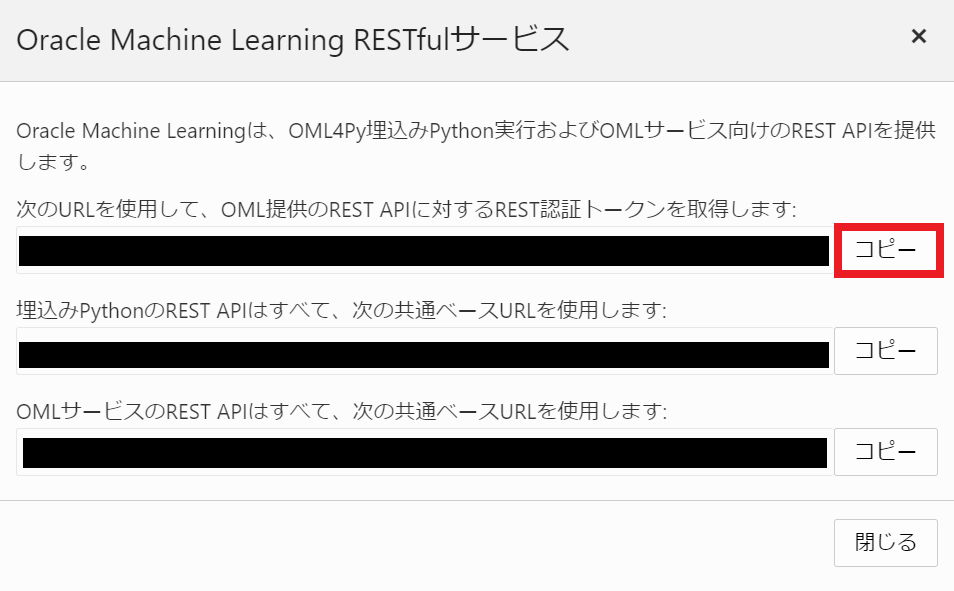
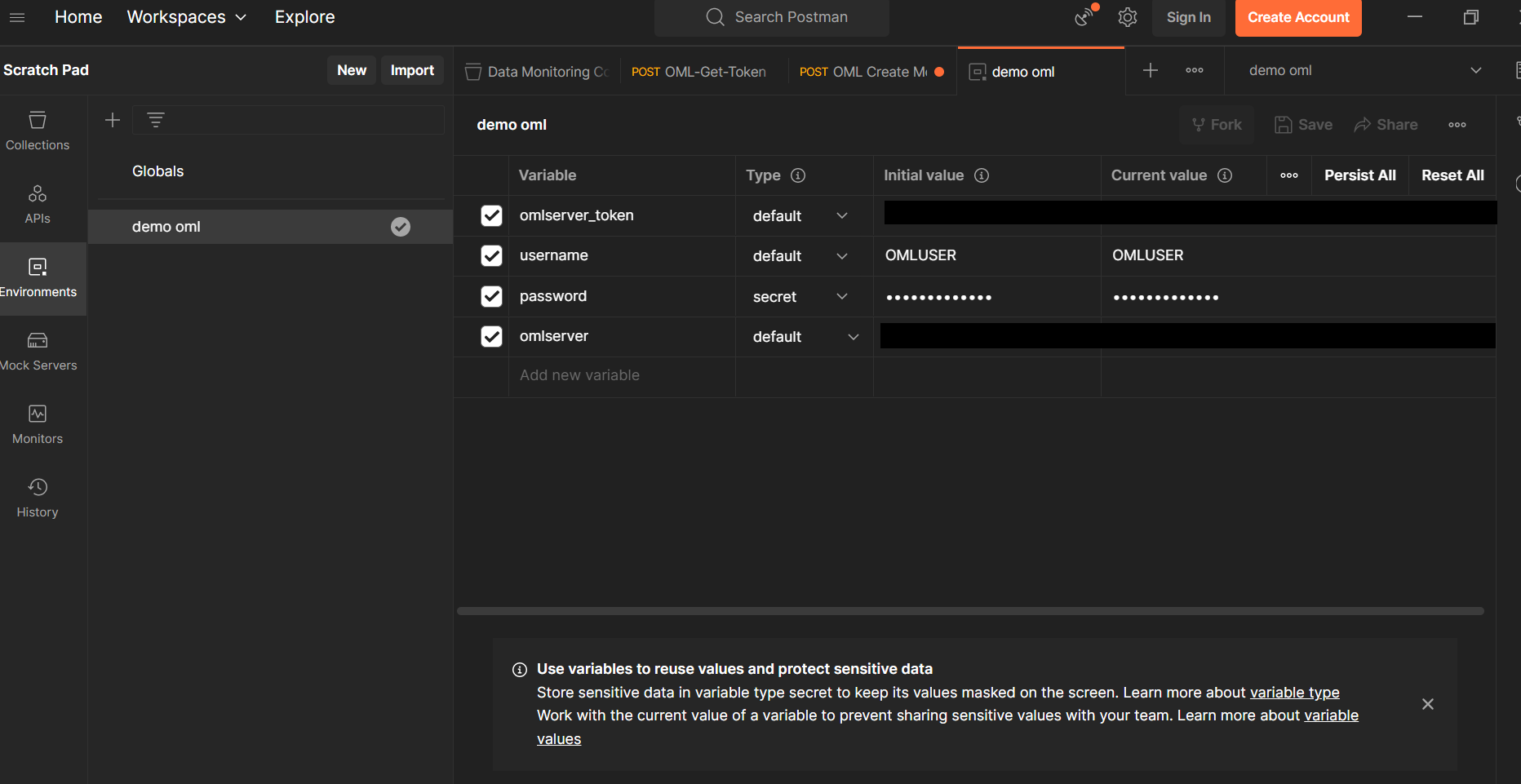
PostmanのEnvironments画面で、以下のように環境変数を設定します。
| Variable | Type | Initial value | Current value |
|---|---|---|---|
| omlserver_token | default | コピーしたURL | コピーしたURL |
| username | default | OMLUSER(OML用のユーザー名) | OMLUSER(OML用のユーザー名) |
| password | default | OMLUSERのパスワード | OMLUSERのパスワード |
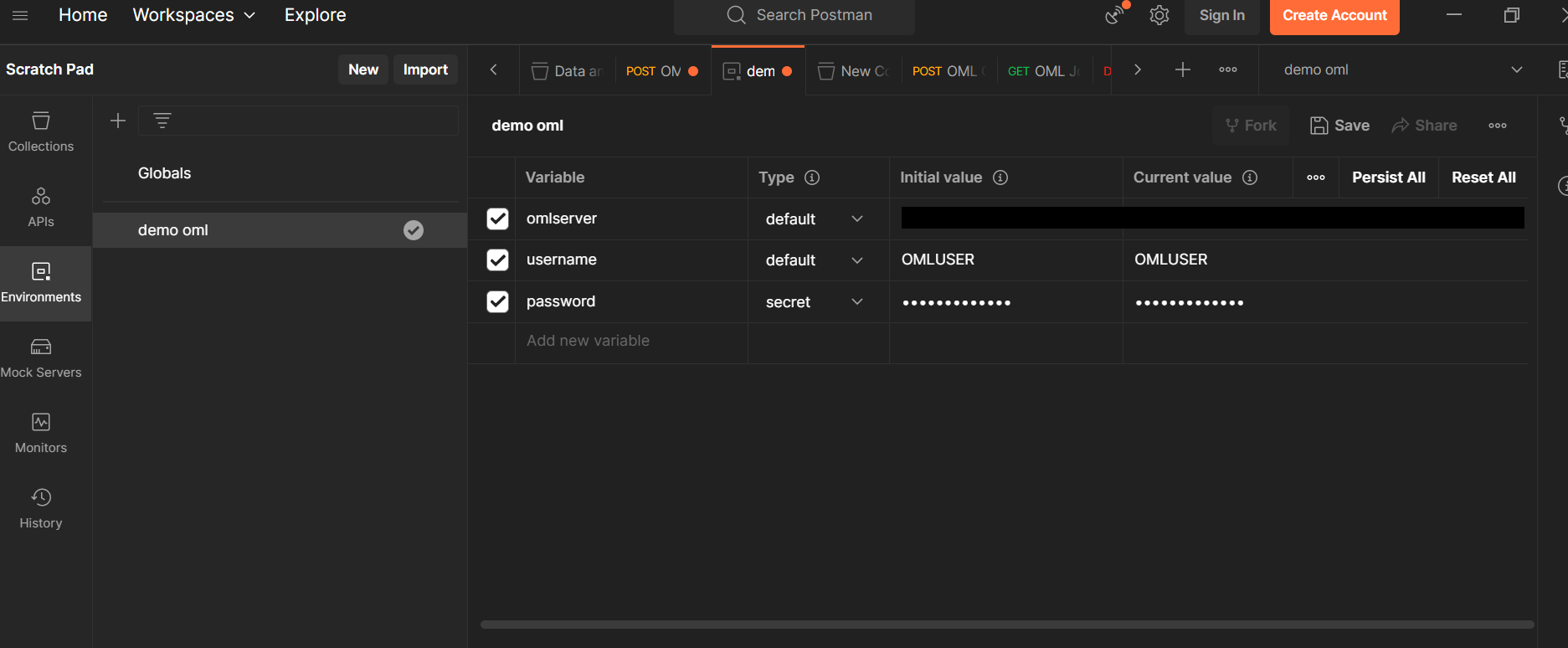
環境変数の設定後、コレクションを作成し、OML-Get-Tokenというリクエストを作成します。
以下の画像のように、{{omlserver}}api/oauth2/v1/tokenにPOSTリクエストを送信します。
その際、HeadersにはContent-Type:application/json、Accept:application/jsonを設定します。
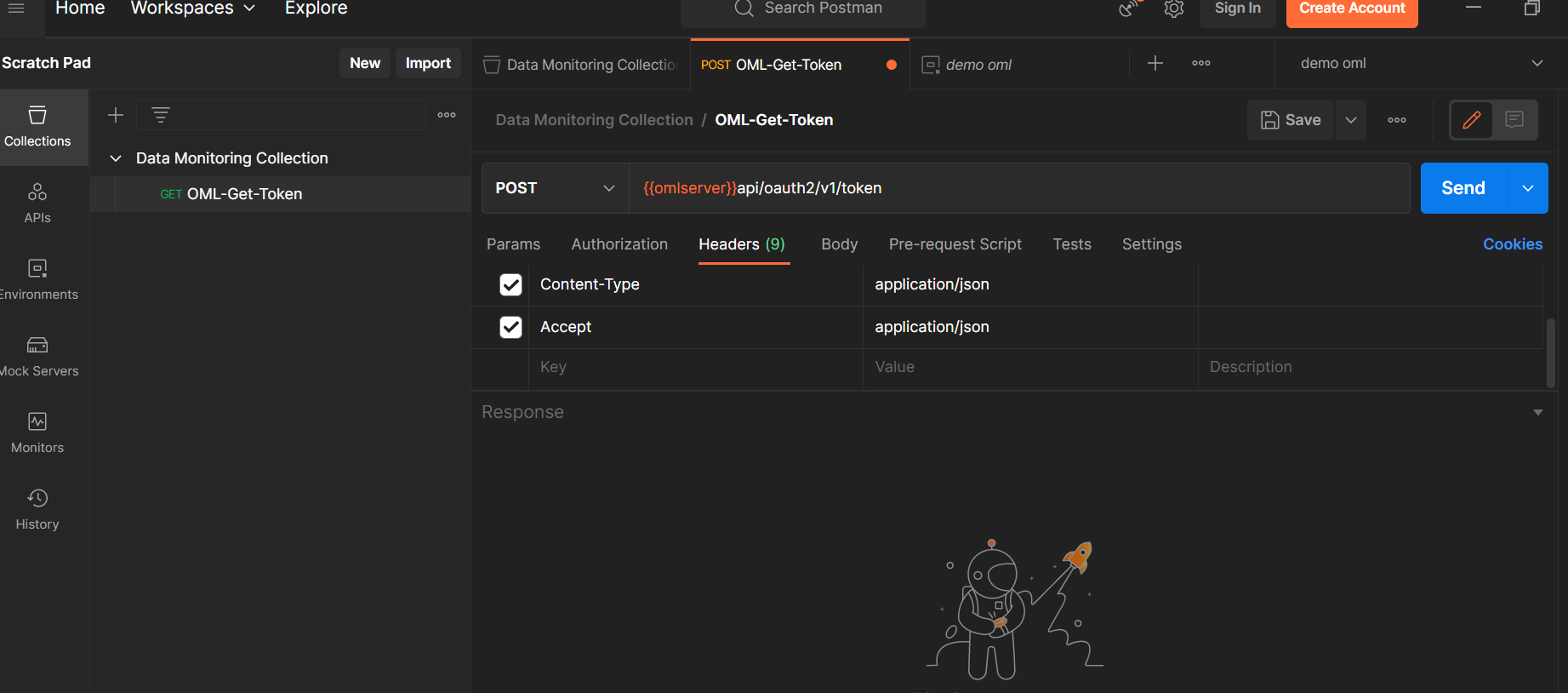
Bodyには、以下のようにraw/JSONでユーザー名とパスワードの認証情報をデータとしてhttpに送信します。
{
"grant_type":"password",
"username":"{{username}}",
"password":"{{password}}"
}
送信すると以下のようにアクセストークンが返ってきます。
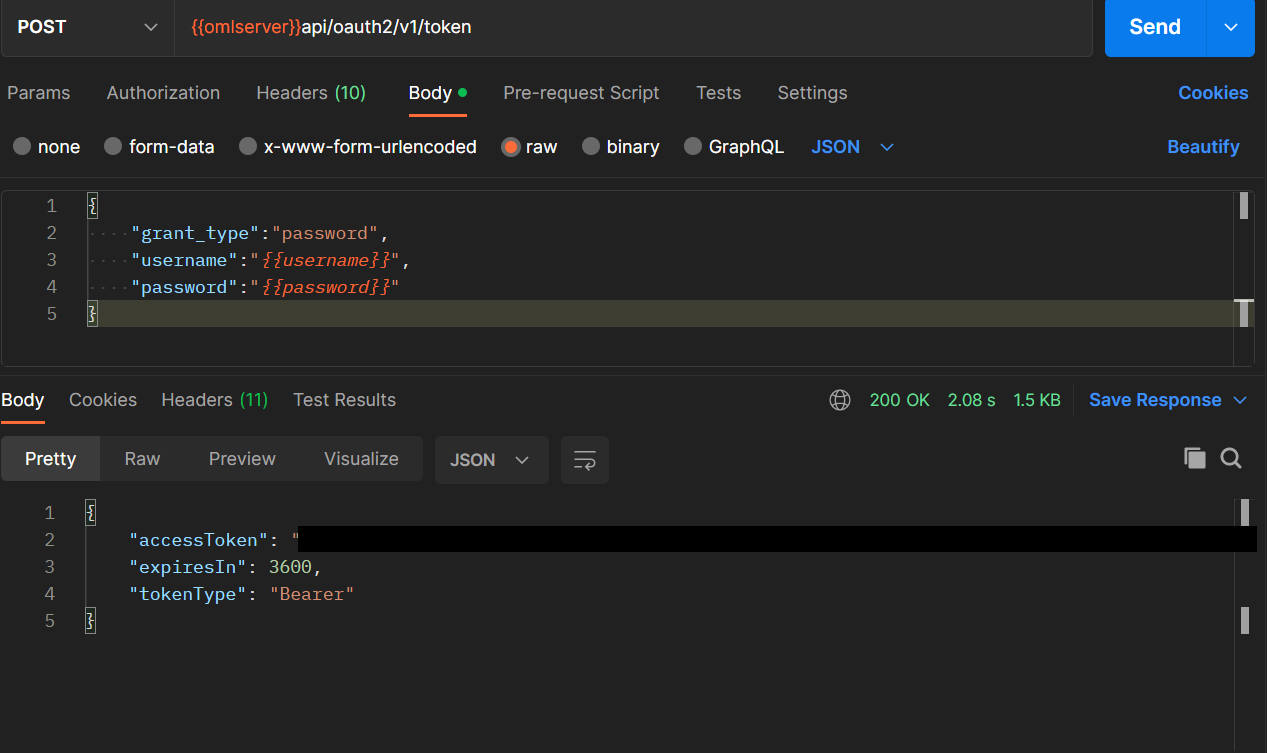
このトークンも、環境変数として保存しておくと便利です。このトークンを認証に使用する今後のリクエスト全てで、Authorizationタブにこのトークンを設定しておきます。
なお、こちらの手順をcurlコマンドで行う場合は、こちらのドキュメントを参照してください。
4. データモニタリングジョブの作成
アクセストークンができたので、OMLサービスにリクエストを送ることができます。
リクエストは共通ベースURLに送信します。
Database ActionsのOracle Machine Learning RESTfulサービスの一番下のURLをコピーします。
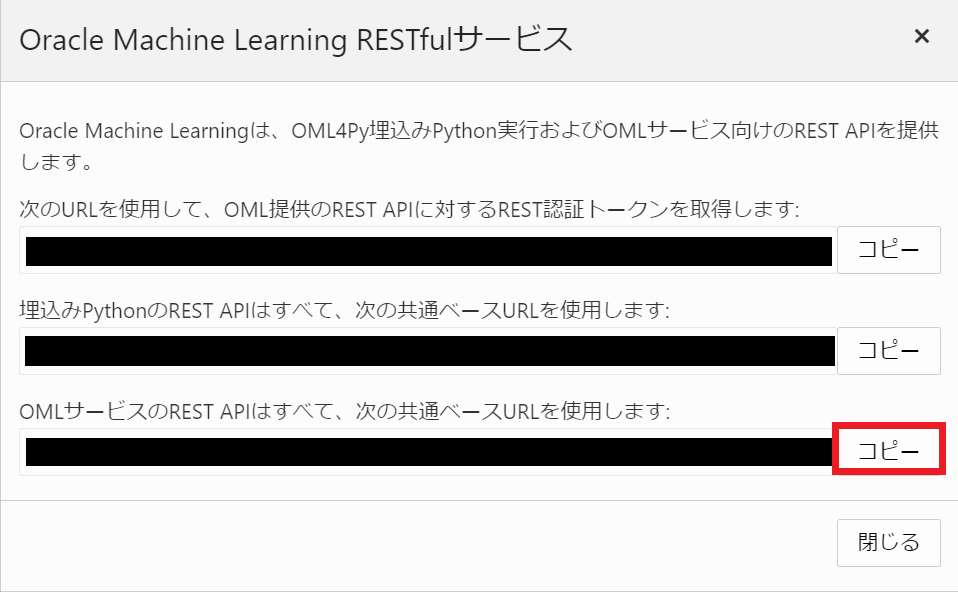
環境変数にomlserverを追加し、コピーしたURLを設定します。
このリクエストは、{{omlserver}}v1/jobsエンドポイントにPOSTリクエストとして送信します。
データモニタリングジョブに指定できるパラメータはたくさんあります。以下は、必須パラメータのリストです。オプションのパラメータについては、こちらのドキュメントを参照してください。
- jobName:ジョブの名前を指定します。
- jobType:実行するジョブの種類を指定し、データ監視ジョブの場合はDATA_MONITORINGと指定します。
- outputData:出力データの識別子を指定します。ジョブの結果は{jobId}_{ouputData}という名前のテーブルに書き込まれます。
- baselineData:監視するベースラインデータを含むテーブルまたはビューの名前です。(外部表も可) 監視には期間ごとに少なくとも50行が必要で、そうでない場合は解析がスキップされます。今回はHOUSEHOLD_POWER_BASE(2006~2007年のデータ)表を指定します。
- newData:ベースラインと比較するための新しいデータを含むテーブルまたはビュー名です。(外部表も可) モニタリングには期間ごとに少なくとも50行が必要で、そうでない場合は解析がスキップされます。今回はHOUSEHOLD_POWER_NEW(2008~2010年のデータ)表を指定します。
今回は以下のようにパラメータを設定しました。
{
"jobSchedule":{
"jobStartDate":"2023-04-17T00:00:00Z",
"repeatInterval":"FREQ=DAILY",
"jobEndDate":"2023-04-18T00:00:00Z",
"maxRuns":"10"
},
"jobProperties":{
"jobName":"OMLDataMonitoring",
"jobType":"DATA_MONITORING",
"jobServiceLevel":"LOW",
"inputSchemaName":"OMLUSER",
"outputSchemaName":"OMLUSER",
"outputData":"householdPowerConsumption",
"jobDescription":"Job to monitor household power consumption data",
"baselineData":"HOUSEHOLD_POWER_BASE",
"newData":"HOUSEHOLD_POWER_NEW",
"timeColumn":"Date_rw",
"startDate":"2008-01-01T00:00:00Z",
"endDate":"2010-12-31T00:00:00Z",
"frequency":"Year",
"threshold":0.8,
"caseidColumn":null,
"featureList":[
"Global_active_power", "Global_reactive_power", "Voltage", "Sub_metering_1", "Sub_metering_2", "Sub_metering_3"
],
"recompute":false
}
}
送信すると、以下のようにjobIdが返ってきます。
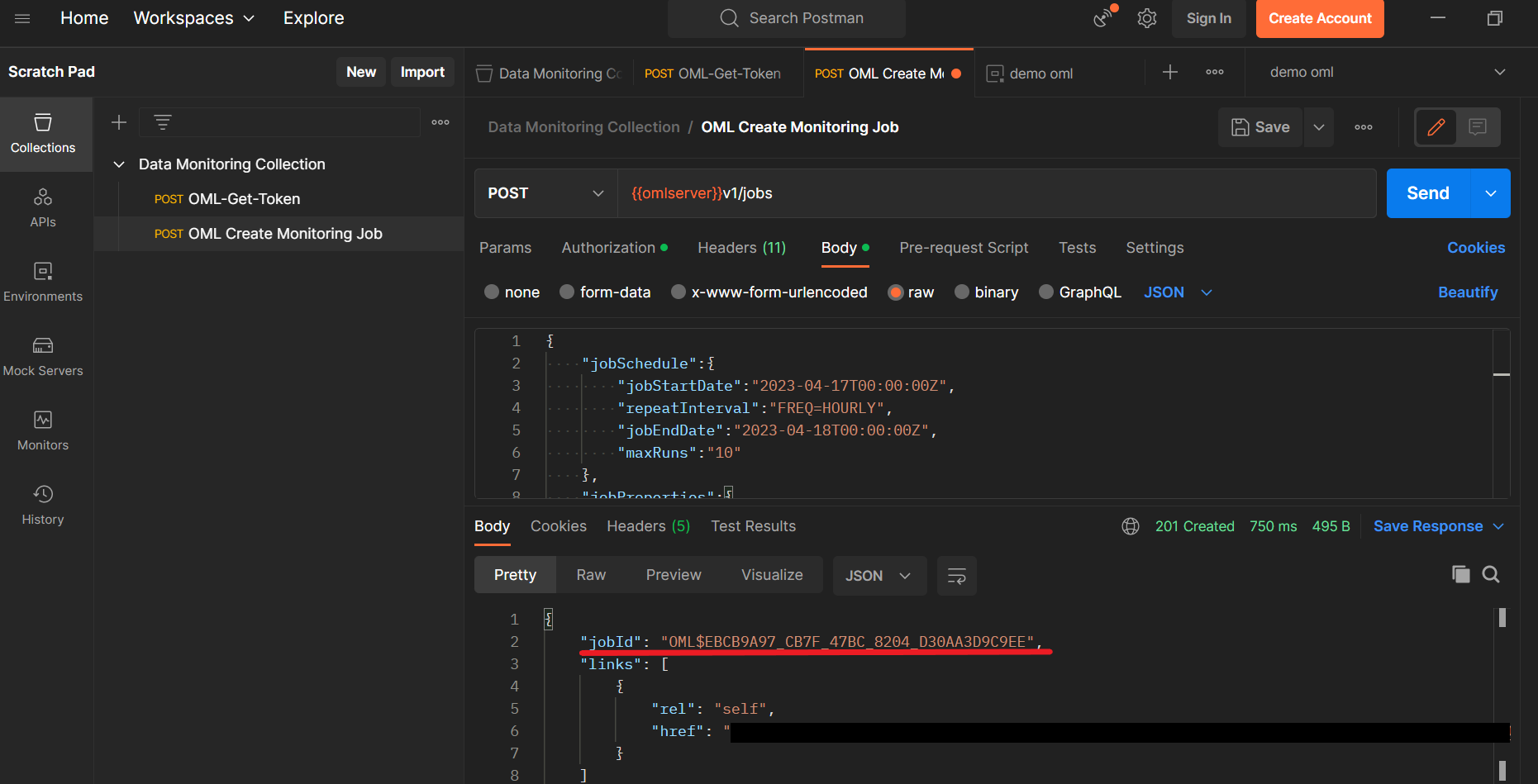
jobIdは、ジョブの詳細の表示や更新などに使用する必要があるため、環境変数として保存しておきます。
5. ジョブの詳細の表示
作成したジョブの詳細を確認するには、{{omlserver}}v1/jobs/{{jobid}}にGETリクエストを送信します。
ジョブリクエストで設定したパラメータと、ジョブが一度でも実行された場合はその最後の実行に関する情報が表示されます。

6. ジョブの実行
作成したジョブに対して、以下のアクションを実行することができます。
- RUN:すぐにジョブを1回実行します。ジョブの動作をテストする場合に実行します。
- DISABLE:ジョブの状態をENABLEからDISABLEに変更します。変更すると、ジョブがスケジュールに従って実行されなくなりますが、RUNアクションでは実行することができます。
- ENABLE:ジョブの状態をDISABLEからENABLEに変更し、再びスケジュールに従って実行されます。
- STOP:現在実行中のジョブを停止させます。ジョブが実行中でない場合は、エラーが返されます。
これらのリクエストは、{{omlserver}}v1/jobs/{{jobID}}/actionエンドポイントにPOSTリクエストとして送信されます。
一度実行するため、BodyにはRUNを指定します。
{
"action":"RUN"
}
リクエストに成功すると、以下のように204レスポンスが返ってきます。
7. データモニタリングジョブの出力確認
最後にデータモニタリングの結果を見るために、OMLノートブックでその結果を保持するテーブルを表示します。このテーブルは<jobId>_<outputData>というテーブル名で、jobIdはジョブに関連するID、outputDataはジョブリクエストでユーザーによって定義されます。
select START_TIME, END_TIME, FEATURE_NAME, THRESHOLD, HAS_DRIFT, round(DRIFT, 3) as DRIFT, round(IMPORTANCE_VALUE, 3) as IMPORTANCE_VALUE, FEATURE_METRICS
from OML$EBCB9A97_CB7F_47BC_8204_D30AA3D9C9EE_householdPowerConsumption
where IS_BASELINE = 0
order by START_TIME;
各列の説明については、こちらのドキュメントを参照してください。
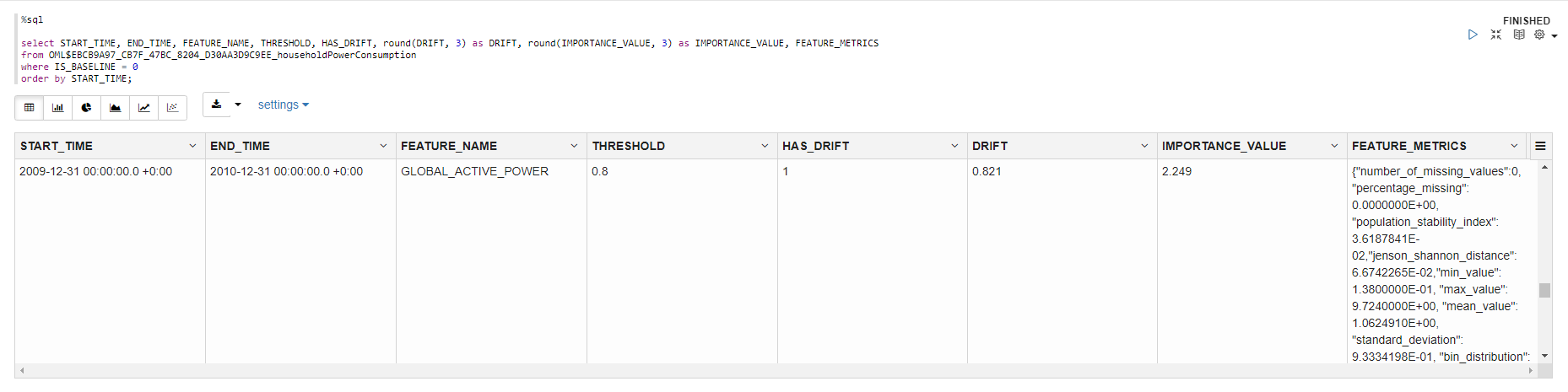
上の画像では、GLOBAL_ACTIVE_POWER列の出力行を、モニターされた最後の年である2010年について見ています。ドリフト値0.821は閾値0.8を上回っているため、この列でドリフトが発生したことがわかります。2.249のIMPORTANCE_VALUEは、この列がこの期間のこのデータセットのモデルにおいて非常に重要な予測因子であることを示しています。
続いて、その年ごとの各特徴量の重要度を確認してみます。
select START_TIME, FEATURE_NAME, round(IMPORTANCE_VALUE, 3) as IMPORTANCE_VALUE
from OML$D7117C86_DF22_4C52_B530_8B44E84A3B1D_householdPowerConsumption
where IS_BASELINE = 0
order by START_TIME;
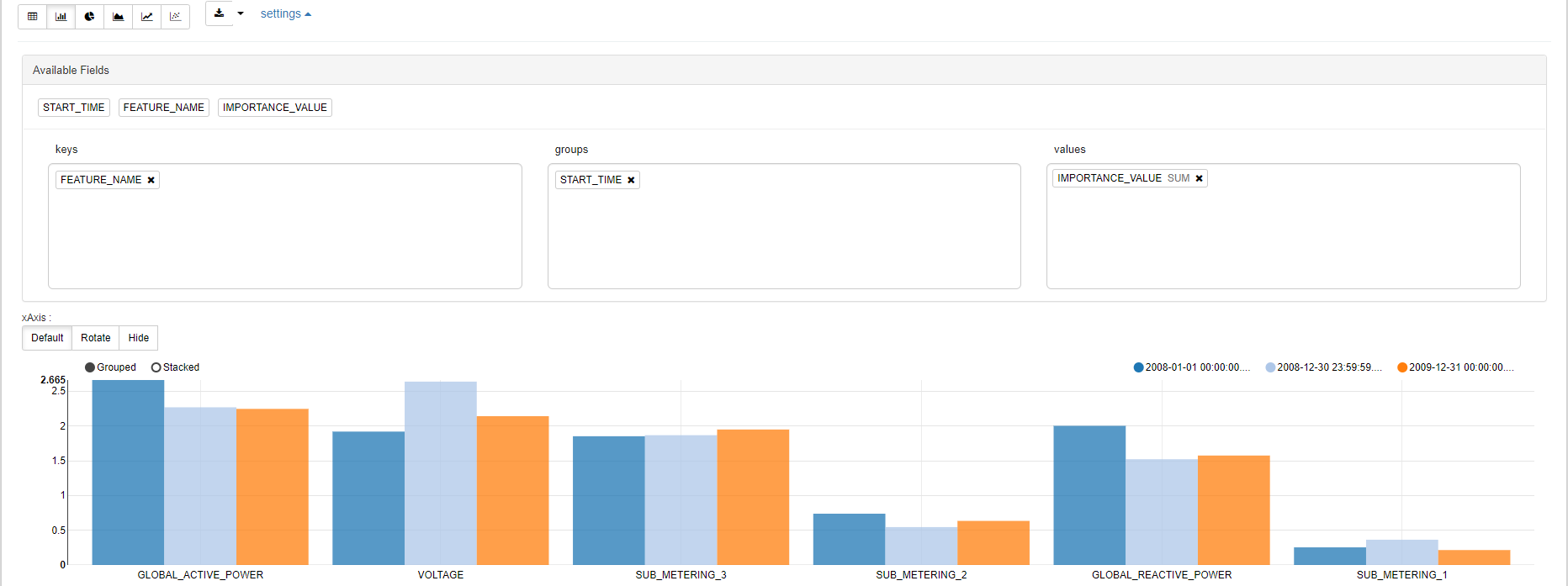
上の画像は、結果をグラフで可視化したものです。これを見ると、どの列が最も重要な予測因子であるか、またその重要性が時間の経過とともにどのように変化したかがわかります。
最後に、その年ごとのDRIFT値の変化を確認してみます。
select START_TIME, round(DRIFT, 3) as DRIFT
from OML$D7117C86_DF22_4C52_B530_8B44E84A3B1D_householdPowerConsumption
where IS_BASELINE = 0
order by START_TIME;
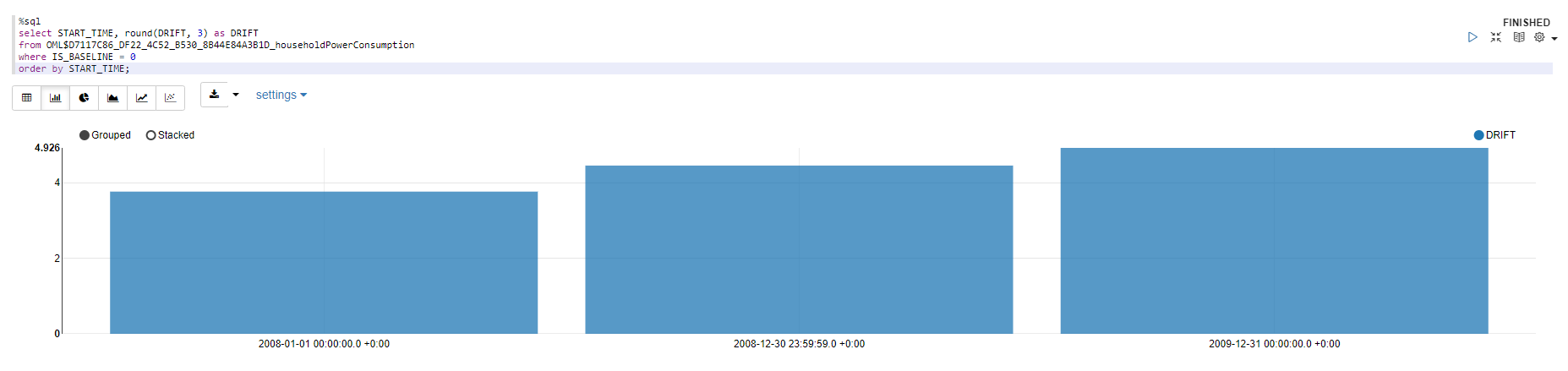
上の画像から、毎年データがどんどんドリフトしていることが分かります。
まとめ
本記事では、Oracle Machine Learning(OML)の機能であるデータモニタリングによるデータドリフト(データの変化)を検出する方法をご紹介しました。機械学習や予測分析のモデル訓練時のデータと、本番環境でのデータの概念や統計的分布が、時間経過によって変わってきてしまうことは多々あります。モデル運用においてドリフトは重要となる概念なので、活用していきましょう。