モデルモニタリングとは
機械学習モデルは、時間の経過とともに性能が劣化することがあります。
劣化したモデルをそのまま使い続けることはビジネス上の損失となります。そのため、モデルの品質を長期的に追跡するモデルモニタリングは、重要なタスクとなっています。
モデルの性能劣化(モデルドリフト)が起きる原因
主に、データドリフトと、コンセプトドリフトがあります。
データドリフトについては、モデルが予測するデータの構成が変化することです。これはデータモニタリングで検出することができます。
データモニタリングについては、こちらの記事を参考にしてください。
データドリフトが起きていないのにも関わらず、モデルの性能が劣化することがあります。このような場合、一般的にはコンセプトドリフトが原因となります。コンセプトドリフトは、入力データxが同じでも、予測を定義するf(x) が変化する場合に起こります。
例えば、ある銀行で、「融資してもよい借り手」を分類するモデルを運用していたとします。1年後、経済が好転した場合、銀行は「融資してもよい借り手」の定義を変更し、より積極的に融資を行うようになります。借り手は同じで、データとしては何も変わっていません。変わったのは「融資してもよい借り手」の定義ですから、この場合はコンセプトドリフトが起きています。
どのようにモデルドリフトを検出するのか
モデルモニタリングは、Oracle Machine Learning(OML)サービスで利用できる新機能です。
この機能は、ベースラインのデータセット(モデルの訓練データ)と新しいデータを比較することでモデルドリフトを検出し、定量的に評価します。また、複数期間にわたってドリフトを監視し、潜在的なドリフトを特定することもできます。モデル内で最も影響力のある特徴量や、予測値の分布を表す統計、予測値の分布を視覚化するためのヒストグラムデータなども、ドリフト測定に加え出力されます。
実際にやってみる
実際にサンプルデータを使って、モデルモニタリングしてみます。
使うデータと前提条件とアクセストークンの取得までの手順は、データモニタリングの記事と同様なので、こちらを参照してください。
1. ベースとなる予測モデルの作成
アクセストークンができたので、OML サービスにリクエストを送ることができます。
今回は、2006-2007年のデータを使って回帰モデルを構築し、GLOBAL_ACTIVE_POWER変数を予測します。
そして2008-2010年のデータの予測モデルのモニタリングを行います。
Oracle Machine Learningユーザー・インタフェースからAutoMLをクリックします。
実験の作成から以下のように指定します。
- 名前:GLOBAL_ACTIVE_POWER_Regression
- データ・ソース:OMLUSER.HOUSEHOLD_POWER_BASE
- 予測:GLOBAL_ACTIVE_POWER
- 予測タイプ:回帰

より速い結果をクリックし、実行します。
モデル作成が終了し、最も精度の高いニューラル・ネットワークを選択し、以下のようにモデルのデプロイを行います。
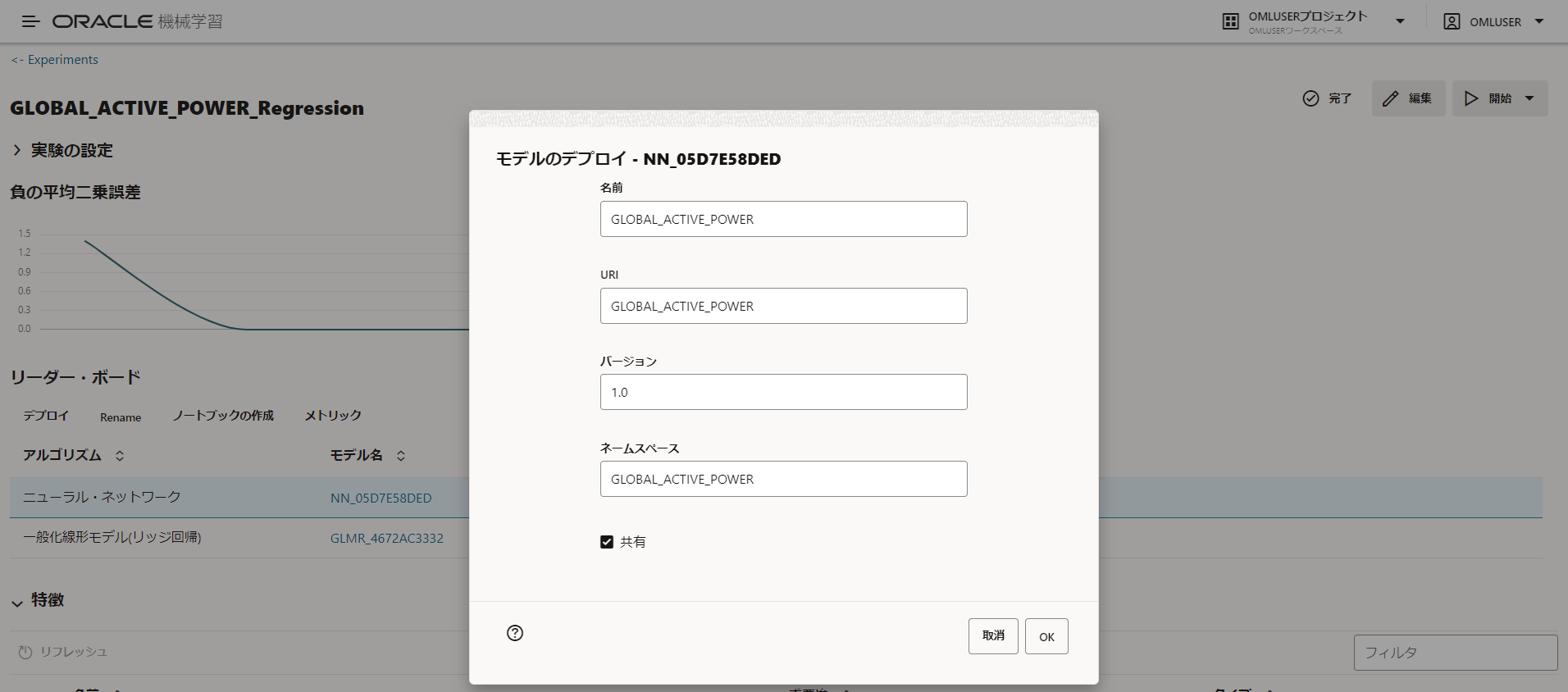
モデルのデプロイ完了後、{{omlserver}}v1/modelsエンドポイントにGETリクエストを送ることで、デプロイされているモデルの一覧とその情報を見ることができます。
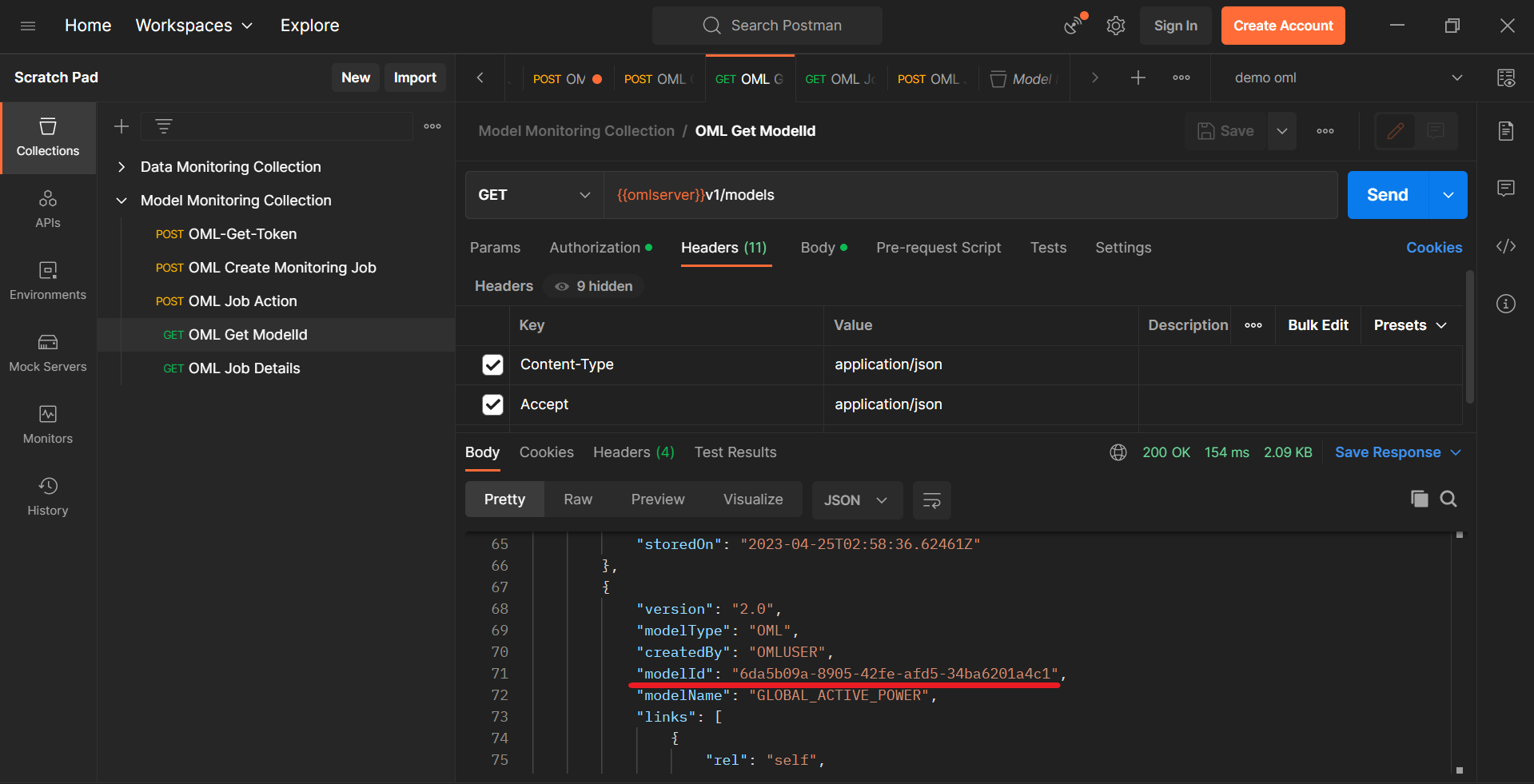
上のように、GLOBAL_ACTIVE_POWERのmodelIdを取得できます。
2. モデルモニタリングジョブの作成
{{omlserver}}v1/jobsエンドポイントにPOSTリクエストとして送信します。
モデルモニタリングジョブに指定できるパラメータはたくさんあります。以下は、必須パラメータのリストです。オプションのパラメータについては、こちらのドキュメントを参照してください。
- jobName:ジョブの名前を指定します。
- jobType:実行するジョブの種類を指定し、モデル監視ジョブの場合はMODEL_MONITORINGと指定します。
- outputData:出力データの識別子を指定します。ジョブの結果は{jobId}_{ouputData}という名前のテーブルに書き込まれます。
- baselineData:監視するベースラインデータを含むテーブルまたはビューの名前です。(外部表も可) 監視には期間ごとに少なくとも50行が必要で、そうでない場合は解析がスキップされます。今回はHOUSEHOLD_POWER_BASE(2006~2007年のデータ)表を指定します。
- newData:ベースラインと比較するための新しいデータを含むテーブルまたはビュー名です。(外部表も可) モニタリングには期間ごとに少なくとも50行が必要で、そうでない場合は解析がスキップされます。今回はHOUSEHOLD_POWER_NEW(2008~2010年のデータ)表を指定します。
- modelList:先ほど取得したmodelIdsで識別される監視対象モデルのリストです。20モデルまで指定可能です。
今回は以下のようにパラメータを設定しました。
{
"jobSchedule":{
"jobStartDate":"2023-04-27T00:00:00Z",
"repeatInterval":"FREQ=DAILY",
"jobEndDate":"2023-04-28T00:00:00Z",
"maxRuns":"10"
},
"jobProperties":{
"jobName":"Active_Power_Monitoring",
"jobType":"MODEL_MONITORING",
"jobServiceLevel":"LOW",
"inputSchemaName":"OMLUSER",
"outputSchemaName":"OMLUSER",
"outputData":"Global_Active_Power_Mnitor",
"jobDescription":"Job to monitor model predicting household power consumption data",
"baselineData":"HOUSEHOLD_POWER_BASE",
"newData":"HOUSEHOLD_POWER_NEW",
"timeColumn":"Date_rw",
"startDate":"2008-01-01T00:00:00Z",
"endDate":"2010-12-31T00:00:00Z",
"frequency":"Year",
"threshold":0.10,
"caseidColumn":null,
"performanceMetric":"MEAN_SQUARED_ERROR",
"modelList":[
"6da5b09a-8905-42fe-afd5-34ba6201a4c1"
],
"recompute":false
}
}
送信すると、以下のようにjobIdが返ってきます。

jobIdは、ジョブの詳細の表示や更新などに使用する必要があるため、環境変数として保存しておきます。
3. ジョブの詳細の表示
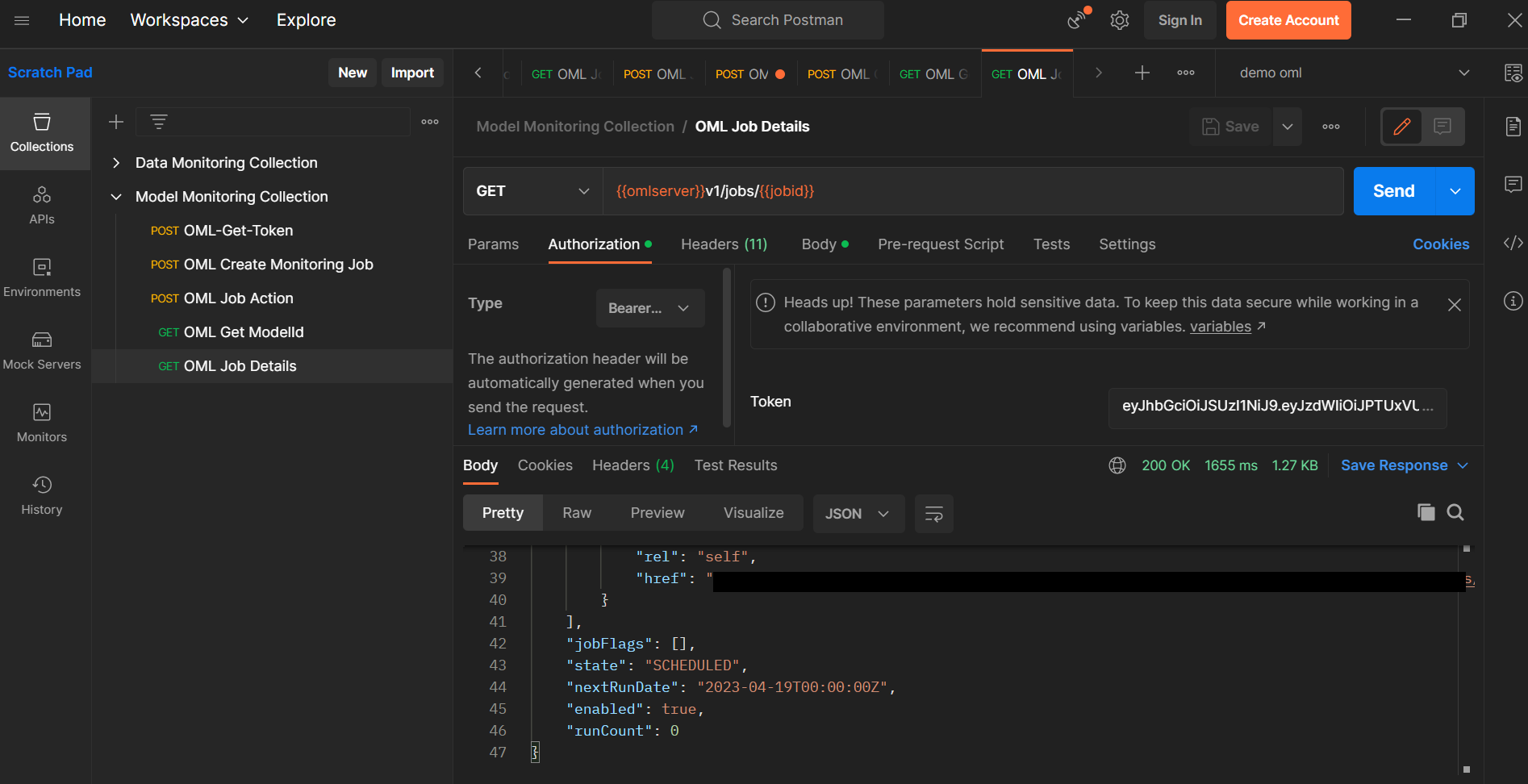
作成したジョブの詳細を確認するには、{{omlserver}}v1/jobs/{{jobid}}にGETリクエストを送信します。
ジョブリクエストで設定したパラメータと、ジョブが一度でも実行された場合はその最後の実行に関する情報が表示されます。
4. ジョブの実行
作成したジョブに対して、以下のアクションを実行することができます。
- RUN:すぐにジョブを1回実行します。ジョブの動作をテストする場合に実行します。
- DISABLE:ジョブの状態をENABLEからDISABLEに変更します。変更すると、ジョブがスケジュールに従って実行されなくなりますが、RUNアクションでは実行することができます。
- ENABLE:ジョブの状態をDISABLEからENABLEに変更し、再びスケジュールに従って実行されます。
- STOP:現在実行中のジョブを停止させます。ジョブが実行中でない場合は、エラーが返されます。
これらのリクエストは、{{omlserver}}v1/jobs/{{jobID}}/actionエンドポイントにPOSTリクエストとして送信されます。
一度実行するため、BodyにはRUNを指定します。
{
"action":"RUN"
}
リクエストに成功すると、以下のように204レスポンスが返ってきます。
5. モデルモニタリングジョブの出力確認
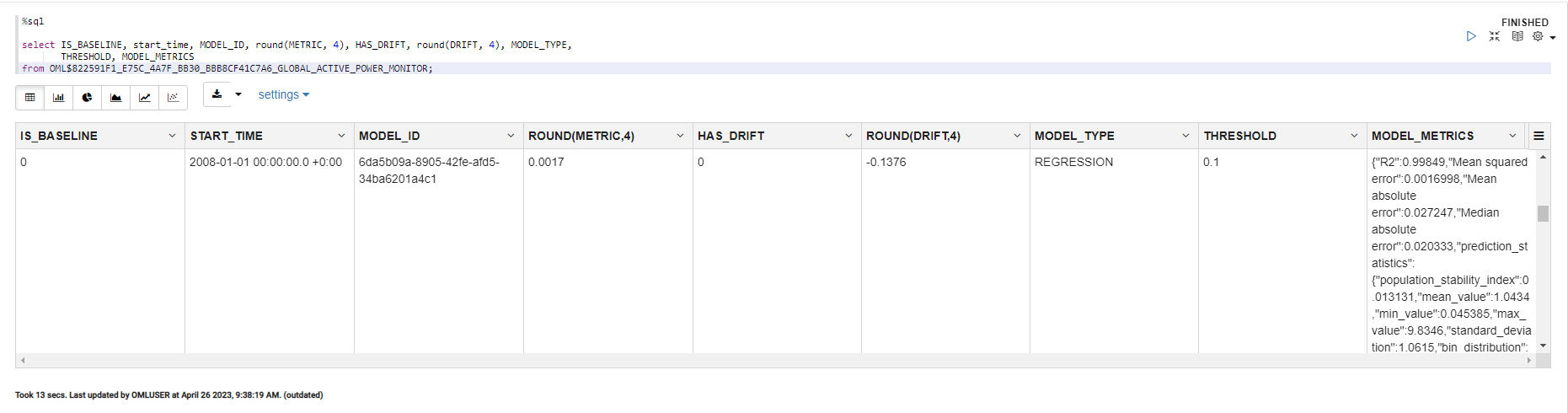
最後にモデルモニタリングの結果を見るために、OMLノートブックでその結果を保持するテーブルを表示します。このテーブルは<jobId>_<outputData>というテーブル名で、jobIdはジョブに関連するID、outputDataはジョブリクエストでユーザーによって定義されます。
select START_TIME, END_TIME, round(METRIC, 3) as METRIC, HAS_DRIFT, round(DRIFT, 3) as DRIFT, THRESHOLD, MODEL_METRICS
from OML$822591F1_E75C_4A7F_BB30_BBB8CF41C7A6_Global_Active_Power_Mnitor;
これを棒グラフで図示すると以下のようになりました。
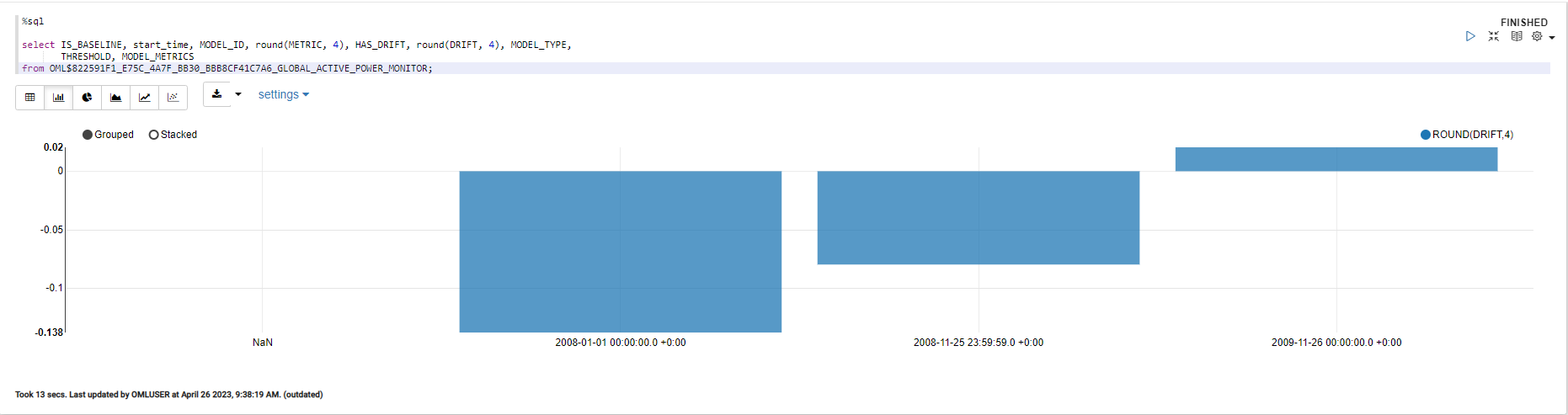
2006年と2007年のデータで学習したモデルに対して、2008年~2010年のデータでモデルドリフトが発生するか、というモデルモニタリングですが、2008年のデータはDRIFT値が -0.138となっています。
ベースラインのデータを使った予測モデルの精度よりも、2008年のデータで作成した予測モデルの精度の方が高い場合に、DRIFT値が負の値になります。
逆に、新しいデータで作成した予測モデルの精度の方が低くなった場合に、2010年データのように、DRIFT値が正の値になります。
今回は閾値(threshold)を0.10、つまり予測モデルの精度が10%劣化した際にDRIFT値を検出するように設定しており、閾値よりDRIFT値が低かったため、DRIFTは検出されませんでした。
このように、Oracle Machine Learning サービスでは、作成した予測モデルが新しいデータに対しても想定していた精度で予測が可能か、劣化しないかを監視するためのモデルモニタリング機能を利用できます。
まとめ