
はじめに
Database ActionsはAutonomous Databaseに同梱されているGUIツールです。データのロードや管理、監視を行うことのできるWebベースのインタフェースです。
AutoMLはDatabase Actionsと同様に、Autonomous Databaseに同梱されている、機械学習モデルの作成を自動で行ってくれるツールです。
今回はSIGNATEのお弁当の需要予測チュートリアルを題材に、Database Actionsでデータ分析→データ加工→モデル作成という流れで精度を高めてみようと思います。
前提条件
Autonomous Data Warehouseを作成済みであること
生データでの精度
まずは、SIGNATEのサイトからダウンロードしたtrain.csvをデータ・ソースにAutoMLでモデル作成をしてみます。
-
Oracle Machine Learning(OML) ユーザーを作成
Database Actionsのデータベース・ユーザーをクリックします。
+ユーザーの作成をクリックします。

以下の項目を入力し、ユーザーの作成をクリックします。- ユーザー名:OMLUSER
- パスワード:*********
- 表領域の割当て制限 DATA:UNLIMITED
- OMLのトグルボタンをON
- WebアクセスのトグルボタンをON

-
データのロード
OMLUSERでDatabase Actionsにログインし、データ・ロードをクリックします。

デフォルトのローカル・ファイルをチェックしたまま、次をクリックします。
train.csvをドラッグ&ドロップし、ロードを開始します。特に編集はしません。
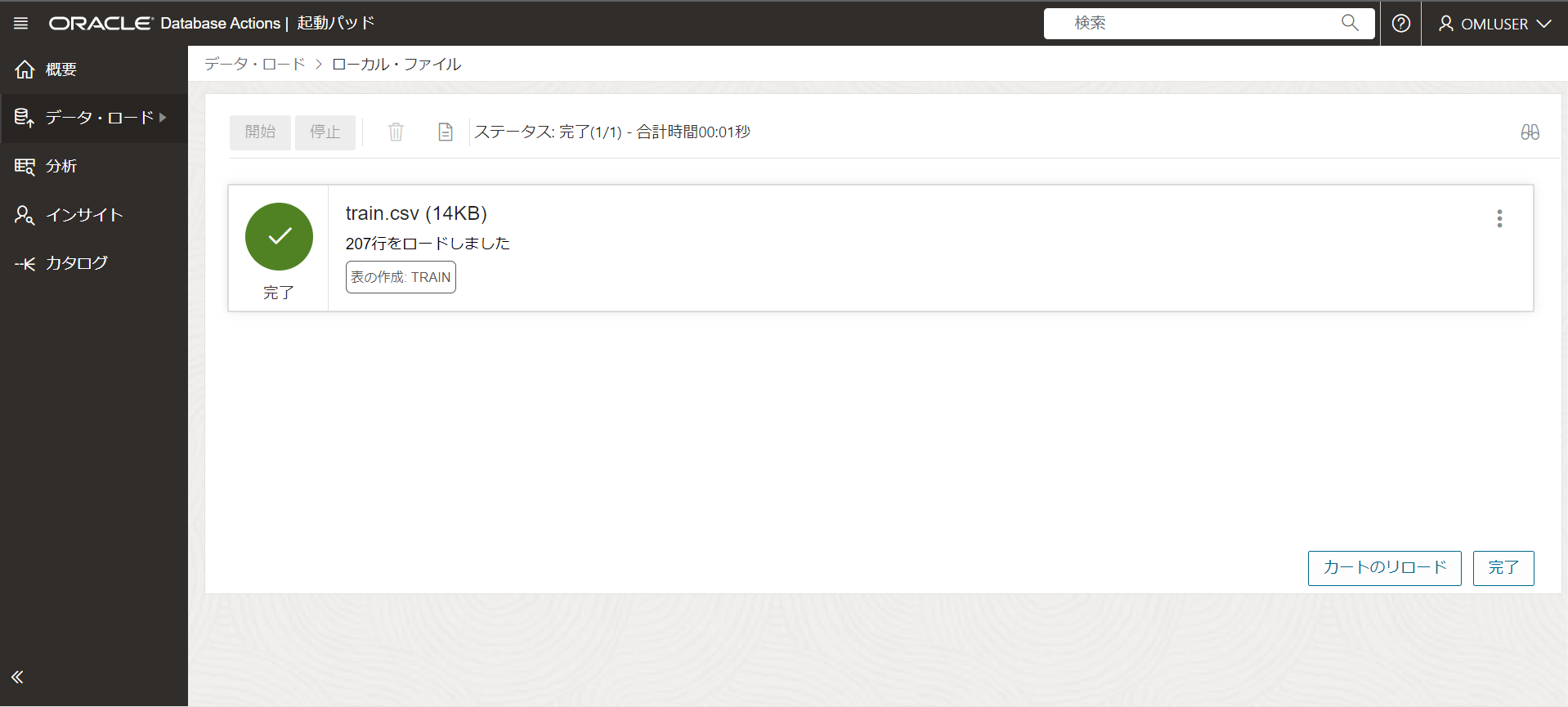
「207行をロードしました」と表示されます。
-
データの確認
ロードしたデータの確認をします。起動パッドに戻り、SQLをクリックします。

TRAIN表をSELECTします。SELECT * FROM TRAIN;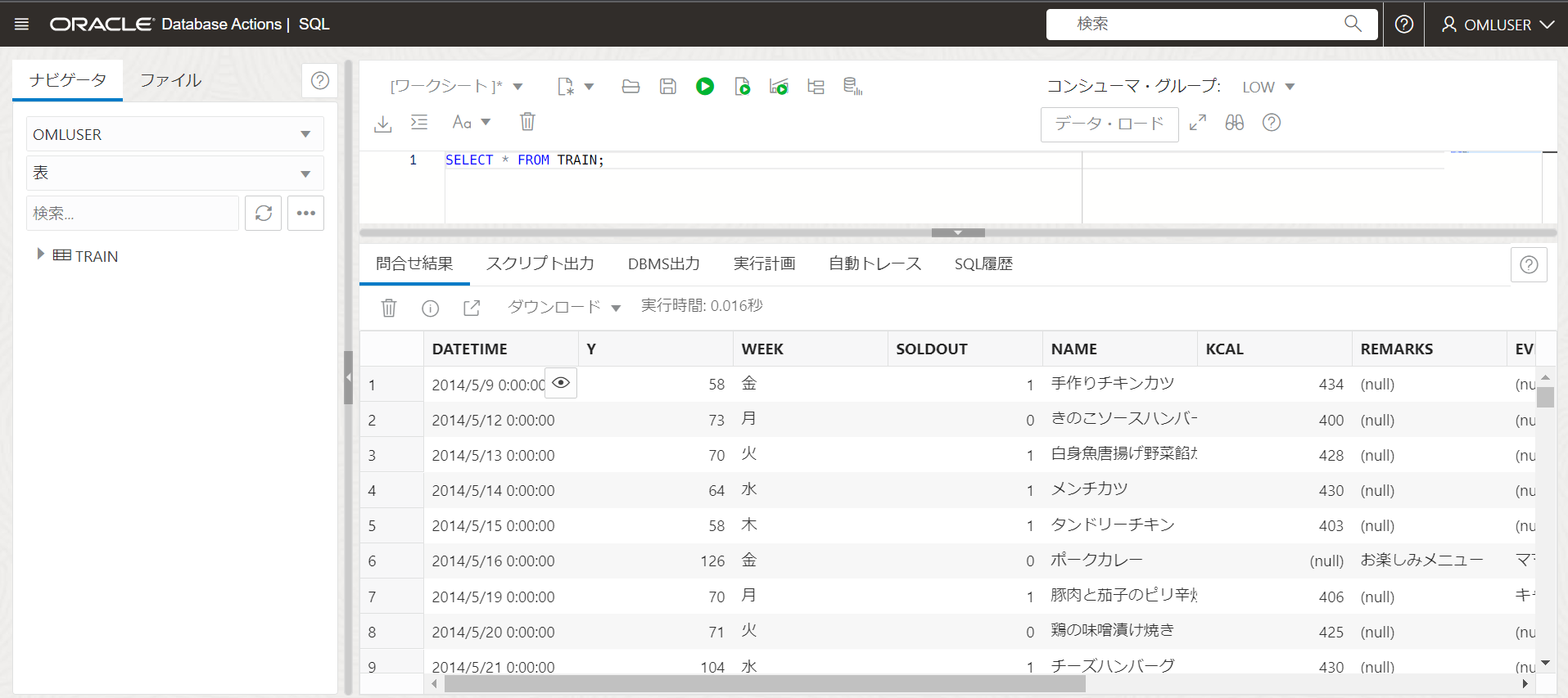
2列目のYが目的変数、つまりお弁当の売れた個数です。その他、DATETIMEやSOLDOUT(売り切れたかどうか)、nullを含むREMARKS列などがあります。 -
モデルの作成
TRAIN表から需要予測を行うモデルを作成します。起動パッドからORACLE MACHINE LEARNINGをクリックします。

ユーザー名:OMLUSERとパスワードを入力し、サインインします。
クイック・アクションのAutoMLをクリックします。
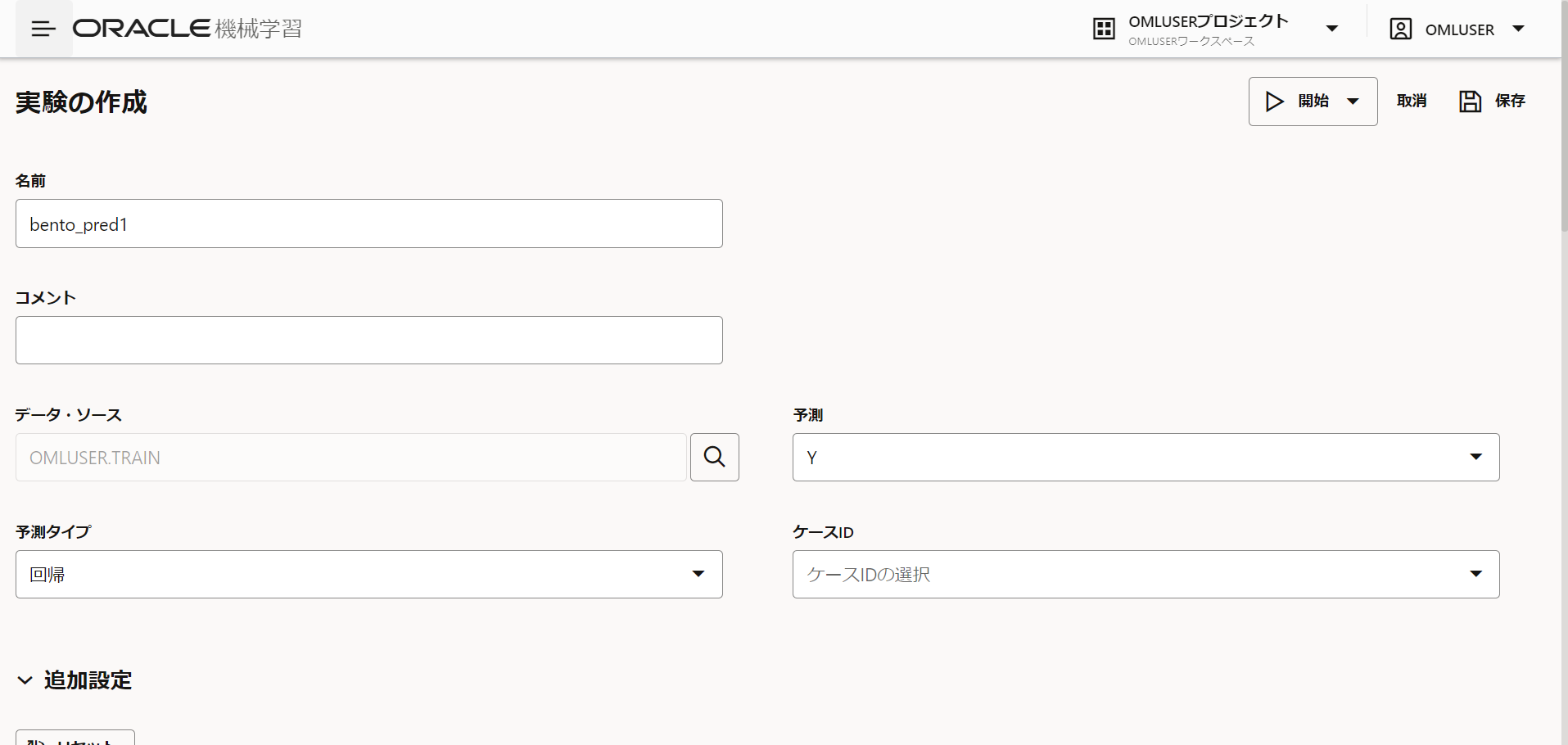
AutoML実験というページに遷移するので、+作成をクリックします。

以下のように項目を入力していきます。
名前:bento_pred1
データ・ソース:OMLUSER.TRAIN
予測:Y
予測タイプ:回帰
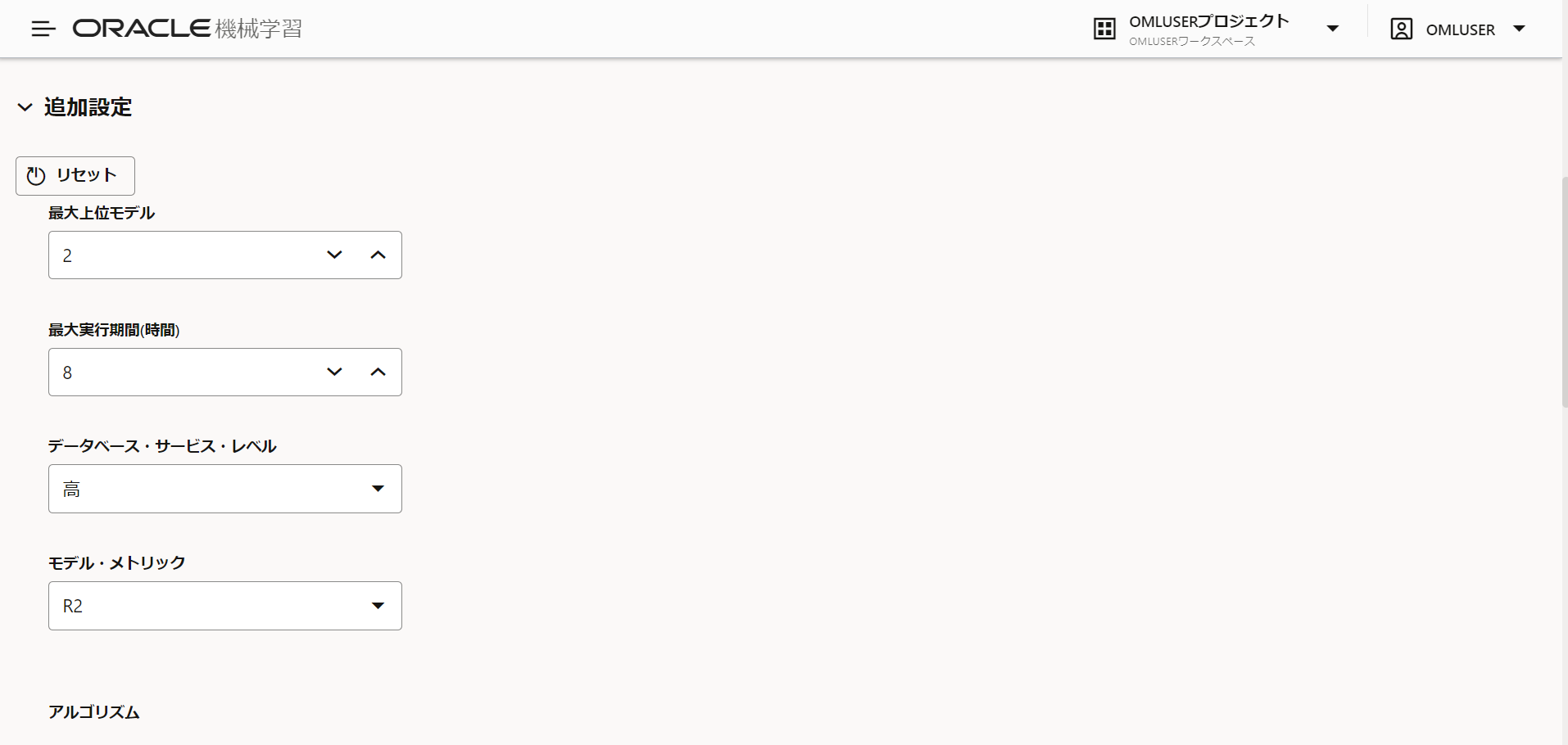
追加設定は以下です。
最大上位モデル(指定した数のアルゴリズムでそれぞれモデル作成を行う):2
最大実行期間(時間):8(デフォルト)
データベース・サービス・レベル(データベースのリソース配分):高
モデル・メトリック:R2
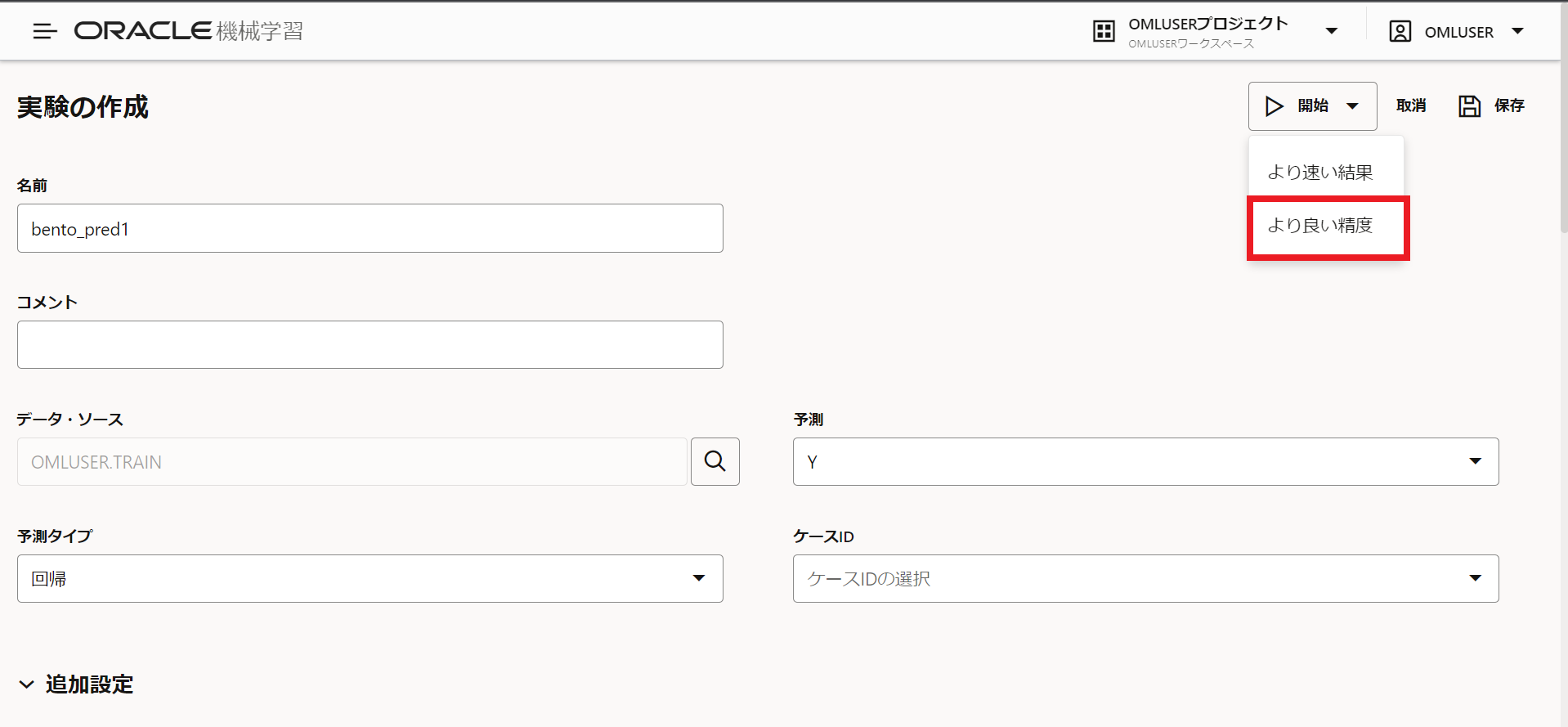
こちらで開始をクリックします。今回はより良い精度を選択します。
モデルの作成が完了しました。Support Vector Machine(ガウス)のR2は0.6160となりました。
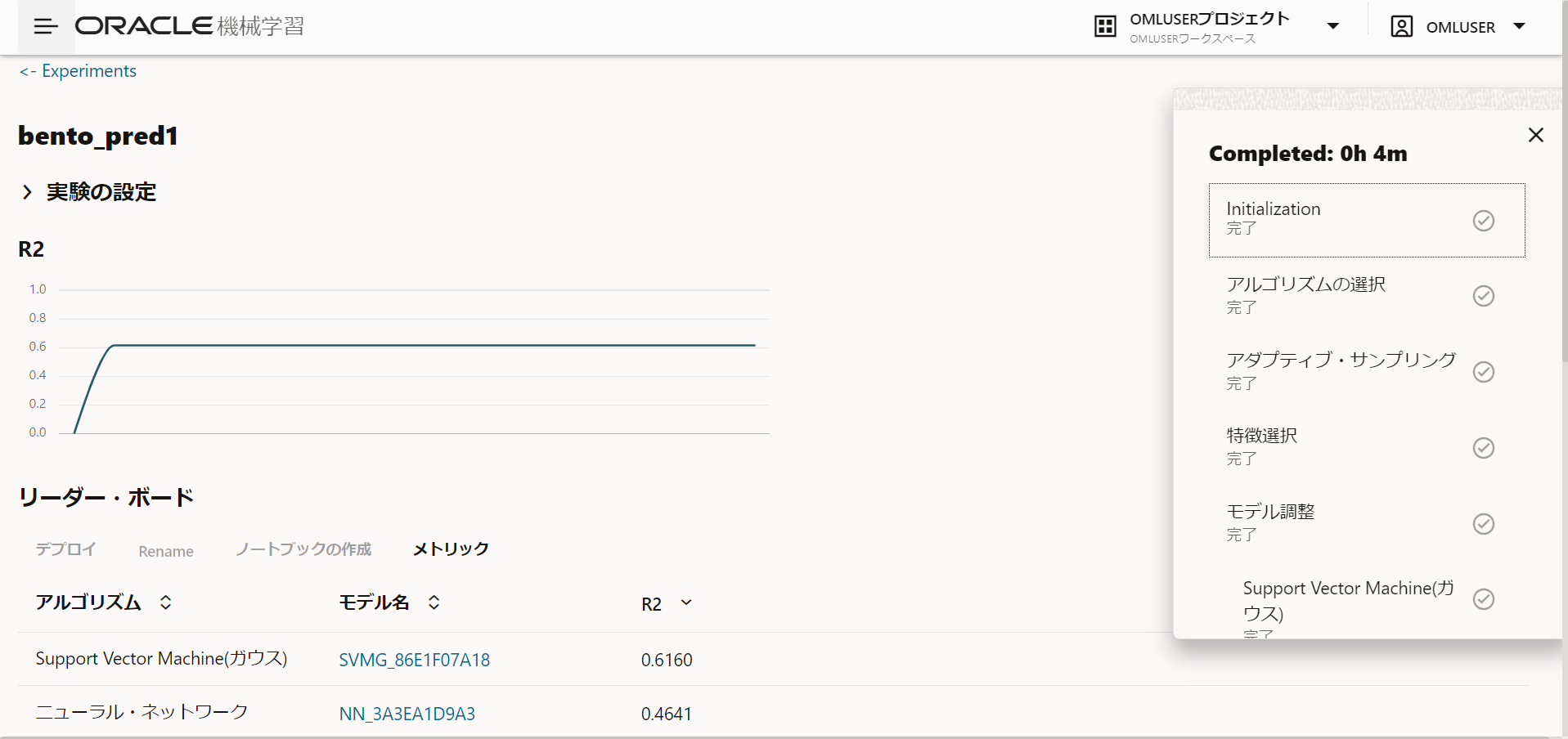
0.6160は現実的な数値ではありますが精度が高いとは言えません。
Database Actionsの各種機能を使って特徴量エンジニアリングを行うことで、この精度を上げてみようと思います。
Database Actions でデータ分析
TRAIN表の各カラムは以下になっています。
- DATETIME:日付
- WEEK:曜日(月~金)
- SOLDOUT:完売フラグ(0:完売せず, 1:完売)
- NAME:メインメニュー
- KCAL:おかずのカロリー
- REMARKS:特記事項
- EVENT:お弁当持ち込み可の社内イベント
- PAYDAY:給料日フラグ(1:給料日)
- WEATHER:天気
- PRECIPITATION:降水量。ない場合は"-"
- TEMPERATURE:気温
- Y:販売数(目的変数)
まずはDATETIMEとYに関係がないか調べてみます。
Database Actionsのデータ分析をクリックします。
分析ビューの作成をクリックします。

階層およびメジャーの作成をクリックします。

階層をクリックし、DATETIMEを追加します。

分析ビューの作成が完了したら、DATETIMEとYの折れ線グラフを表示してみます。
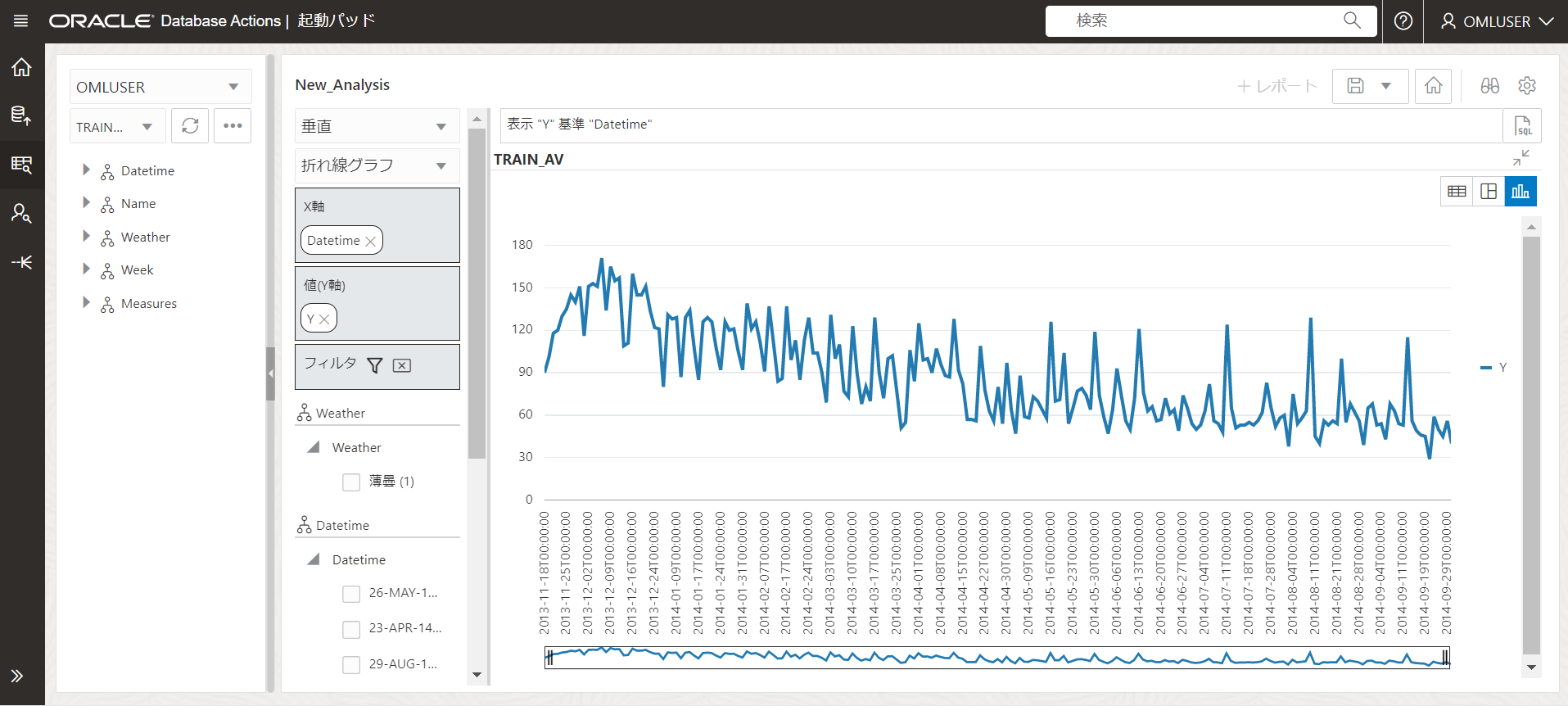
所々スパイクがあるものの、月日が経つにつれYが減少していっていることが分かります。
経過日数がYに影響を与えている可能性が高そうです。
ということで、経過日数を表すDAYS列を追加します。
ALTER TABLE TRAIN ADD (DAYS NUMBER);
UPDATE TRAIN T1
SET DAYS = (SELECT COUNT(*) FROM TRAIN T2 WHERE T2.DATETIME <= T1.DATETIME);
COMMIT;
他の特徴量についても見てみます。
分析ビューの編集で、階層の追加でREMARKSを追加し、更新します。

X軸をRemarks、Y軸をYとする棒グラフのレポートを作成します。

Remarks列がお楽しみメニューのときに売上数(Y)が増えていることが分かりました。
ということでRemarks列がお楽しみニューかどうか判別するFUN列を追加します。(特徴量をあまり増やさないようにRemarks列は削除しています。)
ALTER TABLE TRAIN ADD (FUN NUMBER);
UPDATE TRAIN
SET TRAIN.FUN = CASE TRAIN.REMARKS WHEN 'お楽しみメニュー' THEN 1 ELSE 0 END;
COMMIT;
ALTER TABLE TRAIN DROP COLUMN REMARKS;
Weather列についても同様に見てみます。
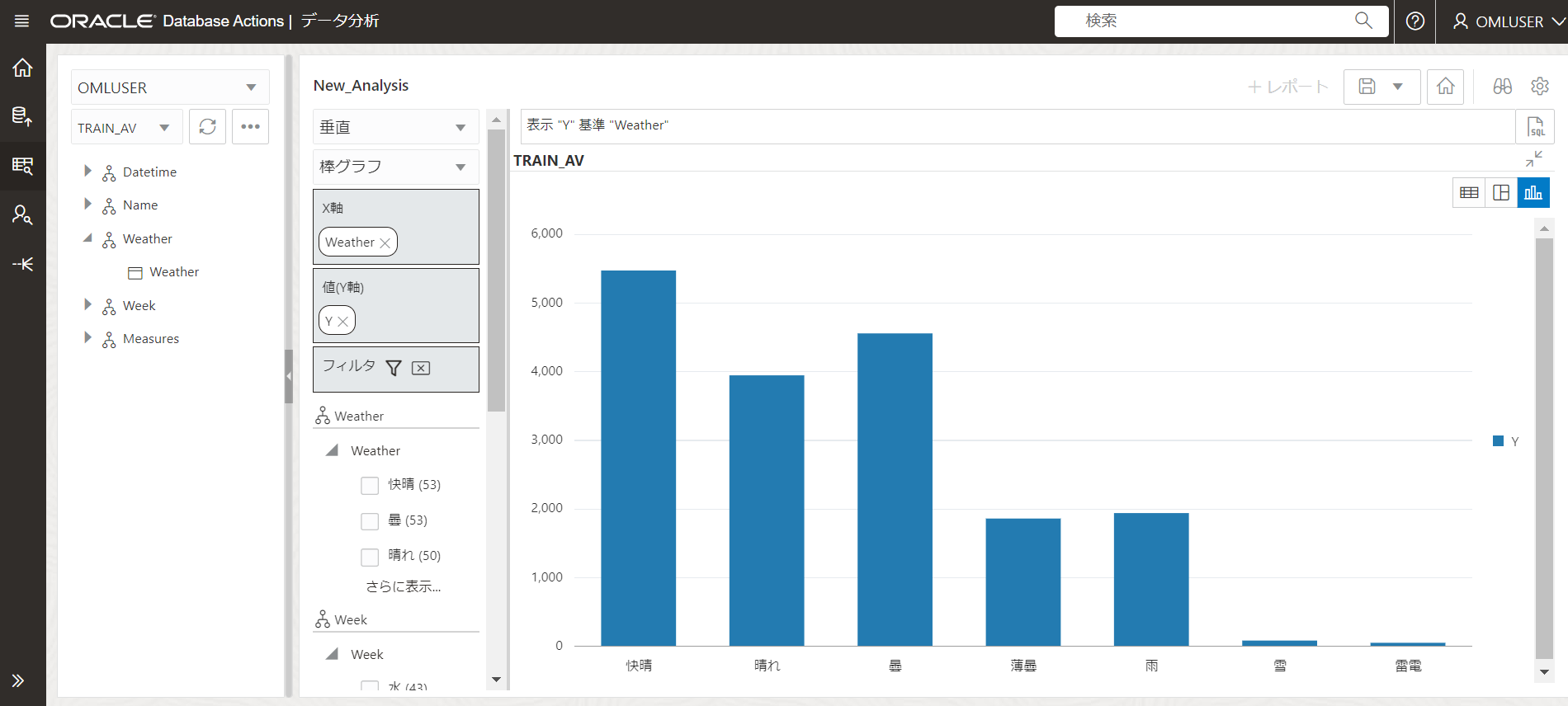
Weatherが快晴、晴れ、曇の日と、それ以外の天気の日で売上数(Y)に大きな差があります。
ということで、Weather列が快晴、晴れ、曇の日は0、それ以外の日は1とするRAIN列を新たに追加します。
ALTER TABLE TRAIN ADD (RAIN NUMBER);
UPDATE TRAIN
SET RAIN =
CASE WHEN WEATHER IN ('快晴', '晴れ', '曇') THEN 0 ELSE 1 END;
COMMIT;
ALTER TABLE TRAIN DROP COLUMN WEATHER;
また、日付列であるDATETIME列は、2023/5現在AutoMLでは扱えないDATE型であるため、DATETIME列はNUMBER型のYEAR列とMONTH列に分割します。
ALTER TABLE TRAIN ADD (YEAR NUMBER, MONTH NUMBER);
UPDATE TRAIN SET YEAR = EXTRACT(YEAR FROM DATETIME), MONTH = EXTRACT(MONTH FROM DATETIME);
ALTER TABLE TRAIN DROP COLUMN DATETIME;
最後に、いくつかの列で欠損値があるので、SQLで補完しておきます。
-- KCAL列がNULLの場合、平均値で補完
UPDATE TRAIN
SET KCAL = (SELECT TRUNC(AVG(KCAL), 0) FROM TRAIN)
WHERE KCAL IS NULL;
-- PAYDAY列がNULLの場合、0で補完
UPDATE TRAIN
SET PAYDAY = 0
WHERE PAYDAY IS NULL;
-- EVENT列がNULLの場合、'なし'で補完
UPDATE TRAIN
SET EVENT = 'なし'
WHERE EVENT IS NULL;
COMMIT;
モデル作成
特徴量エンジニアリング後、再度AutoMLでモデル作成を行ってみます。
結果は以下のようになりました。
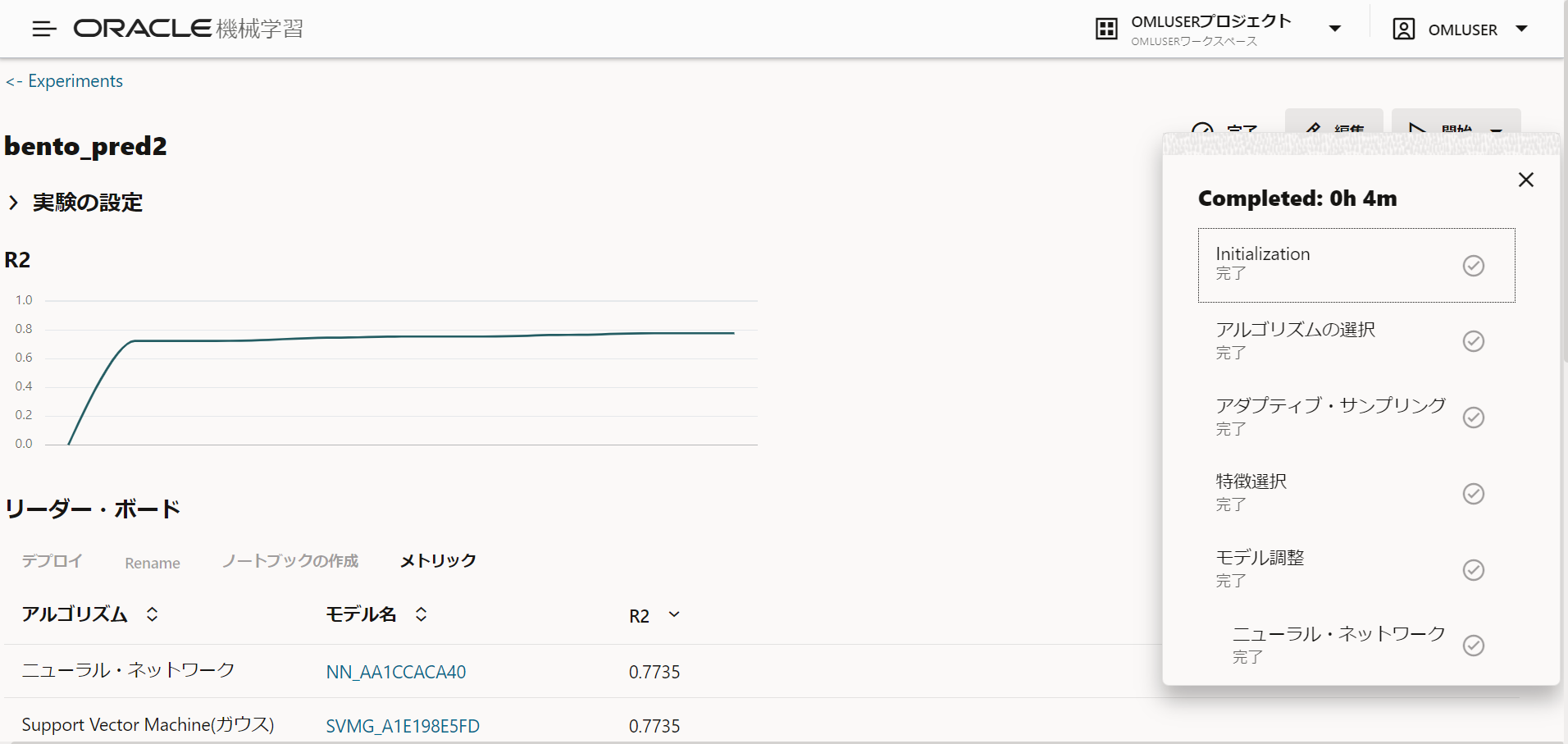
80%には満たないですが、生データと比べると16%精度が上がりました。
より細かいデータ分析をしていけば、さらに精度は上げることができます。
まとめ
今回、作業としては、Database Actionsでデータロード→データ分析でデータの傾向把握→SQLで特徴量追加→モデル作成で完結しています。
Autonomous Databaseに付随しているDatabase Actionsは、データのロード・分析・データ変換などデータ活用に役立つ機能が一つにまとめられています。
さらに、同じく付属ツールであるOracle APEXでは今回のモデルを使った需要予測を行うWebアプリまで作成できます。
簡単すぐにデータベース運用、およびアプリ開発ができるのでぜひ試してみてください。
[Autonomous DatabaseはAlways Freeでも利用可能です!]
https://www.oracle.com/jp/cloud/free/