検索すれば出てくると思ってたら同じ現象を見つけられませんでした。
のでメモメモ。
PC環境はwindows10です。
3秒でわかる今回の問題
# オュケ・ー・フ,*,*,*,*,*
すもも フセサ・ー・フ,*,*,*,*,*
オュケってなんだ!
フセサってなんだ!
補足:Mecab導入手順
一応こういう環境で導入しました。
github経由のmecab使ってるってだけです。
1.下記ページから64bitにビルドしたMecabを入手
https://github.com/ikegami-yukino/mecab/releases
2.下記ページ参考にSHIFT-JISとUTF-8の辞書を入れる
MeCabをPythonとRで使う-Windows10-64bit
3.下記ページを参考にNEologdをSHIFT-JISとUTF-8にコンパイル
Windows10でRMeCabの辞書にNEologdを使うには(Linuxはいれない)
やりたかったこと
形態素解析をして、不要な単語を除去しようと「名詞・動詞・形容詞」に絞って抽出したところ……

いげたは名詞に入らないと思うのですが!
(単語は検証用に抜粋しました)
つまるところ名詞とされる記号を記号と認識してほしかった。
調べたところ、そもそものMecabの設定で記号がサ変接続と認識されるらしいです。
辞書変換すればいいとのことで、下記ページを参考にレッツ辞書変換。
参考:WindowsでMeCab辞書にエントリーを追加する
dic\ipadic\unk.def
dic\ipadic-UTF8\unk.def
(RとPythonの両刀使いでなければipadicだけだと思います)
上記の2つの辞書の9行目くらいを下のように変更します。
保存場所によっては上書き禁止なので、編集するときはデスクトップにでもコピーしたものをぽちぽちします。
SYMBOL,1283,1283,17585,名詞,サ変接続,*,*,*,*,*
↓
SYMBOL,1283,1283,17585,記号,一般,*,*,*,*,*
そのうえで、管理者としてコマンドプロンプトを起動。
(通常のコマンドプロンプトだとpermission errorが出るので注意)
上記の変更を加えたフォルダに移動して下記コマンドをそれぞれ実行。
# dic\ipadicで実行
..\..\bin\mecab-dict-index -f shift-jis
# dic\ipadic-UTF8で実行
..\..\bin\mecab-dict-index -f utf-8
そうしてコマンドプロンプトからmecabを起動し、「#すもも」を入力すれば……
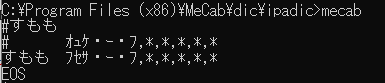
オュケってなんだ! フセサってなんだ!
原因調査
文字化けしているようですが、あまり見たことないタイプです。
UTFの文字化けならダイヤのはてなマークなんですけども。
文字化けテスターという文字化けを意図的にしてくれるサイトで調査したところ……。
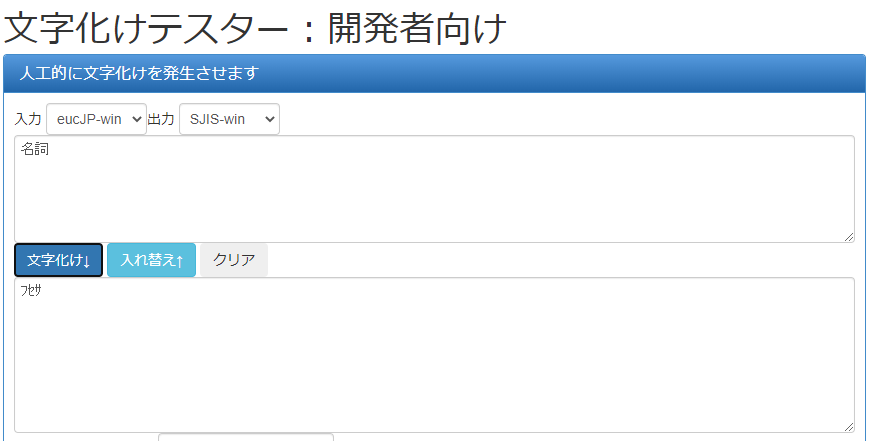
こいつだ!!
つまりエンコードがうまくいってない様子。
だったらこうすれば!
# dic\ipadicで実行
..\..\bin\mecab-dict-index -f euc-jp -f shift-jis
いでよ「#すもも」
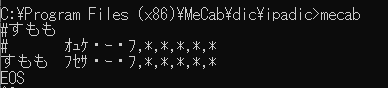
ドウシテ……
再度辞書を入れなおして再チャレンジしてもだめでした。
こうして迷宮入りに。
ポジティブに考えればいげたが「フセサ」じゃないので辞書は効いてるってことなんですけども……。
路頭に迷ってこんなことをしました
# dic\ipadicで実行
..\..\bin\mecab-dict-index -f shift-jis -f euc-jp
で、「#すもも」
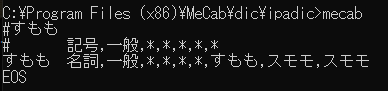
あれっっっ!!!
うまくいきました。
NEOlogdで辞書作る時の引数が「-f もとの辞書の文字コード -f 作成される辞書の文字コード」という順番だったので勘違いしていたようですね?
……そもそも公式ページ見ても引数の詳細がよくわからなかったのですが。
つまり「mecab-dict-index -f 作成する辞書の文字コード -f もとの辞書の文字コード」みたいなコマンドが正解ということなんだと思いました。
めいびー。
UTF-8の辞書変換
コマンドプロンプト上でうまーくmecabが動いてるように見えますが、UTF-8もうまーく表示されてしまいました。
SHIFT-JIS以外はコマンドプロンプトで文字化けするはずなのでUTF-8指定で変換したつもりの辞書がSHIFT-JISだということです。
pythonで使うためには辞書もUTF-8ではないといけないので下記を参考にUTF-8版を再構築。
参考:WindowsでNEologd辞書を比較的簡単に入れる方法-システム辞書編
EmEditor というソフトで
すべてエンコードを指定して保存→文字コード:UTF-8(BOM付き)→改行コード:LFのみ
のように辞書フォルダ内にあるCSVを一括変換します。
それから下記のコマンドを実行。
# dic\ipadic-UTF8で実行
mecab-dict-index -f utf-8 -t utf-8
これでUTF-8の辞書が出来たはず。
mecabrcを一時的に下に書き換えて……
;6行目
dicdir = $(rcpath)\..\dic\ipadic-UTF8
;8行目
userdic = C:\Program Files (x86)\MeCab\dic\NEologd\NEologd.20200521-u.dic
mecab -Dで文字コードを確認。

okですね。
コマンドのpythonからも……

あれ、出来てない……?
両方文字化けすると思ったのですけども、文字コード本当に統一されているのか。
ちょっと検証。
・・・
pycharmにて文字化けせずに認識されていることを確認。
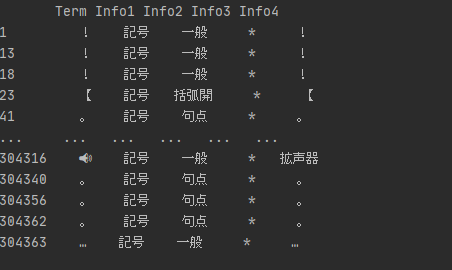
いげたはちょうど見当たりませんが、システム辞書が文字化けてエラー起きることを危惧してたので、その点は大丈夫なようです。
ふう。
蛇足
ただのモヤモヤなのですが。
最初はRでmecabを使おうと思って、mecab公式サイトからダウンロードした辞書に対して同様のサ変対策処理を行ったのですが、そのときは文字化けしませんでした。
……気がするのですがなんでだろう。記憶が曖昧です。
32bitと64bitが関係あるとかないとかは検証してないので分かりませんが。
上記の公式サイトから落としたmecabを使おうとするとpythonで「32bitだよ!」みたいにエラー吐かれてキレ散らかすので、64bitにビルドされたものを持ってきたほうが無難ですね。