ことの発端
Twitterのデータ収集はしていましたが、その後はほったらかしにしていました。
で、久しくデータを見たらfav0の出会い系の謎の市町村ツイートがわんさかわんさか……。
実際にTwitter検索かけてもばりばり見つかりました。
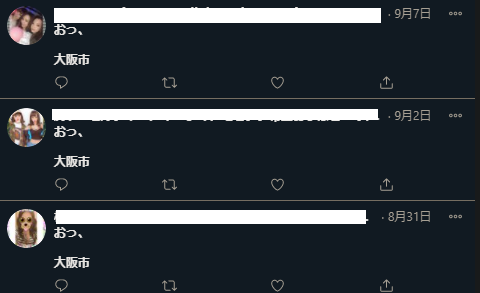
ユーザ名はさすがに卑猥すぎて隠しました……。
なんだこの謎の単語は……前までもうすこし文章だったろ……?
そして以前まで特定の単語を指定して、それがヒットしたらサヨナラとしてたんですけど、この文字数だと指定できる共通単語もありません。
ので正規表現でどかんと削除します。
ソース
動作確認のサンプルごとドカン。土管。
ざっと見たところ呟きのパターンとしては
①「平仮名1文字」「平仮名もしくは句読点」「市町村名」
②「平仮名3文字」「記号」「市町村名」
この2つなので、該当するものを空白に置換してから空白行を削除します。
データはデータフレームに入ってるのでそこでなんとか、えんやこらします。
地味に久しぶりのpythonタイム。すぐ終わりましたが。
import pandas as pd
import re
DF_samp=pd.DataFrame({'col_0': {'row_0': "おー大阪市", 'row_1': "おっ、大阪市aaa", 'row_2': "おっ、大阪市"},'col_1': {'row_0': 3, 'row_2': 4, 'row_3': 5},})
cols=DF_samp.col_0
cols0=cols.str.replace("[ぁ-ゟ][ぁ-ゟ][!-/:-@?[-`{-~。、~ー…\].+[町|村|市]$|[ぁ-ゟ][ぁ-ゟ!-/:-@?[-`{-~。、~ー…\].+[町|村|市]$", '')
DF_samp.col_0=cols0
DF_samp.dropna(subset=['col_0'])
これで該当する謎文章だけ駆逐出来ました。
ヤッタネ。
そこの代入いるんですかって声が聞こえる気がしますが長いの嫌なので……。
そして今
これBOT担当者に見られたら新たなパターンが来るのかもしれないと気づいてしまった……。
その時はその時ですが。
なにはともあれ効率よくブロックできる世の中になりた~い!
まあツイート収集してるのはAPIなので今回のこれはブロック関係ないんですけどネ。