今回はEqualumのアップデート検証を行ってみます。
以前検証報告をさせて頂いた、kafka+SPARK環境を独自のノウハウと技術で統合し、先進のCDCエージェント技術を駆使してエンド・ツゥ・エンドでのExactly Onceを提供するEqualumなるソリューションに関して、最近大きなアップデートが有りましたので、取り急ぎ検証と結果共有をさせて頂きます。
何が変わった??
今回のバージョンでは、今までOracleのデータベース対応だけだったレプリケーション機能が、MySQL等の他のCDC対応データベースでの利用が可能になっています。また、以前のバージョンで対応していたOracle環境同様に、オリジナルの選択肢が単に増えただけではなく、レプリケーションの着地側データベースの選択肢も選べる様になっていますので、データシステム全体のコストバランスを考えた、より適切なシステム展開をサポートする事が可能です。
では、レプリケーション機能を使ってみます。
今回の環境としては、

の構成を作ります。
まずはデータの生成部分を作ります。
ここは、過去何度も使い回しているPython環境を”得意のバラック改造”してサクッと作ります。今回の環境も常設のPython3+AnacondaをMBP上で使います。
最初に空のテーブルを3種類作成します
* 顧客系
* 取引系
* 決済系
ここも、エイヤー!でパラメータ定義をしていますので、気になられる方は適宜書き換えてください(汗)。今回は、共通キー的なカラムとして、全体を透過的に共通化しているオーダーID(Order_ID)を入れています。
# coding: utf-8
#
# MySQLにオリジナル側のCDCテーブルを作成
#
# Python3版
#
# 初期設定
import sys
stdout = sys.stdout
sys.stdout = stdout
import pymysql.cursors
# テーブル定義
# ヘッダー系情報
DC0 = "id INT AUTO_INCREMENT, ts TIMESTAMP(6), PRIMARY KEY(id, ts), Order_ID VARCHAR(15), "
# 顧客情報
DC1 = "User VARCHAR(20), Zip VARCHAR(10), Prefecture VARCHAR(10), Address VARCHAR(60), "
DC2 = "Tel VARCHAR(15), Email VARCHAR(40), Point INT, Area VARCHAR(10)"
# 取引系情報
DC3 = "Category VARCHAR(20), Product VARCHAR(20), Price INT, Units INT, Logistics VARCHAR(20) "
# 決済系情報
DC4 = "User VARCHAR(20), Card VARCHAR(40), Number VARCHAR(30), Price INT, Units INT, Payment INT, Tax INT "
# テーブル名
Table_Name = ["Rep_Demo_Usr_Table","Rep_Demo_Biz_Table","Rep_Demo_Pay_Table"]
# 作成するテーブル数
Generate_Table = 3
try:
print("オリジナル側CDCテーブル作成処理を開始")
# テーブル定義の初期化
Table_Create = []
Create_SQL = "CREATE TABLE IF NOT EXISTS " + Table_Name[0] + " ("+DC0+DC1+DC2+")"
Table_Create.append(Create_SQL)
Create_SQL = "CREATE TABLE IF NOT EXISTS " + Table_Name[1]+ " ("+DC0+DC3+")"
Table_Create.append(Create_SQL)
Create_SQL = "CREATE TABLE IF NOT EXISTS " + Table_Name[2] + " ("+DC0+DC4+")"
Table_Create.append(Create_SQL)
# MySQLとの接続
db = pymysql.connect(host = 'xxx.xxx.xxx.xxx',
port=3306,
user='xxxxxxxx',
password='zzzzzzzz',
db='xxxxxxxx',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
with db.cursor() as cursor:
Counter = 0
while Counter < Generate_Table:
# テーブルの初期化
cursor.execute("DROP TABLE IF EXISTS " + Table_Name[Counter])
db.commit()
# 新規テーブルを作成
cursor.execute(Table_Create[Counter])
db.commit()
Counter = Counter + 1
except KeyboardInterrupt:
print('!!!!! 割り込み発生 !!!!!')
finally:
# データベースコネクションを閉じる
db.close()
print("オリジナル側CDCテーブル作成処理が終了")
次にデータを連続挿入する仕組みを作ります。
顧客系に関しては、実際の取引とは関係ない「単純な顧客登録のみ」が時々入ってくる様にしました。またこの割合は
if str(fakegen.boolean(40)) == "True":
の部分で40の値を変える事で可能です(詳しくは、Pythonのマニュアルにて・・(汗))
また、リアル感を追加する為に、ランダムな暇つぶし処理も入っていますので、これも適宜書き換えて頂いて結構です。
(因みに、Equalum的には一番ドSな待ち時間無しの設定でも普通に処理します・・・・・)
# coding: utf-8
#
# MYSQLの各CDCテーブルをランダムに更新する
#
# Python3版
#
# 初期設定
import sys
stdout = sys.stdout
sys.stdout = stdout
import time
import pymysql.cursors
import re
# デモで使うメタデータ定義
Category_Name = ["酒類","家電","書籍","DVD/CD","雑貨"]
Product_Name0 = ["日本酒","バーボン","ビール","芋焼酎","赤ワイン","白ワイン","スコッチ","ブランデー","泡盛","テキーラ"]
Product_Price0 = [1980, 2500, 490, 2000, 3000, 2500, 3500, 5000, 1980, 2000]
Product_Name1 = ["テレビ","洗濯機","ラジオ","ステレオ","電子レンジ","パソコン","電池","エアコン","乾燥機","掃除機"]
Product_Price1 = [49800, 39800, 2980, 88000, 29800, 64800, 198, 64800, 35800, 24800]
Product_Name2 = ["週刊誌","歴史","写真集","漫画","参考書","フィクション","経済","自己啓発","月刊誌","新刊"]
Product_Price2 = [280, 1500, 2500, 570, 1480, 1400, 1800, 1540, 980, 1980]
Product_Name3 = ["洋楽","演歌","Jポップ","洋画","アイドル","クラッシック","邦画","連続ドラマ","企画","アニメ"]
Product_Price3 = [1980, 2200, 2500, 3500, 2980, 1980, 3800, 2690, 1980, 2400]
Product_Name4 = ["洗剤","電球","贈答品","医薬部外品","ペットフード","乾電池","文房具","男性用品","女性用品","季節用品"]
Product_Price4 = [498, 198, 1980, 398, 980, 248, 398, 2980, 3580, 1980]
Table_Name1 = "Rep_Demo_Usr_Table" # 顧客管理系テーブル
Table_Name2 = "Rep_Demo_Biz_Table" # 販売・物流系テーブル
Table_Name3 = "Rep_Demo_Pay_Table" # 決済系テーブル
# 地域名ルックアップ情報(キーは都道府県名)
Area_Data={'北海道':'北海道','青森県':'東北','岩手県':'東北','宮城県':'東北','秋田県':'東北','山形県':'東北','福島県':'東北',
'茨城県':'関東','栃木県':'関東','群馬県':'関東','埼玉県':'関東','千葉県':'関東','東京都':'関東','神奈川県':'関東',
'新潟県':'中部','富山県':'中部','石川県':'中部','福井県':'中部','山梨県':'中部','長野県':'中部','岐阜県':'中部','静岡県':'中部','愛知県':'中部',
'三重県':'近畿','滋賀県':'近畿','京都府':'近畿','大阪府':'近畿','兵庫県':'近畿','奈良県':'近畿','和歌山県':'近畿',
'鳥取県':'中国','島根県':'中国','岡山県':'中国','広島県':'中国','山口県':'中国',
'徳島県':'四国','香川県':'四国','愛媛県':'四国','高知県':'四国',
'福岡県':'九州・沖縄','佐賀県':'九州・沖縄','長崎県':'九州・沖縄','熊本県':'九州・沖縄','大分県':'九州・沖縄','宮崎県':'九州・沖縄','鹿児島県':'九州・沖縄','沖縄県':'九州・沖縄'}
# 物流センタールックアップ情報(キーは地域名)
Logi_Data = {'北海道':'道央物流センター','東北':'東北物流センター','関東':'関東中央物流センター',
'中部':'甲州物流センター','近畿':'伊丹物流センター','中国':'広島臨港物流センター','四国':'讃岐物流センター','九州・沖縄':'平戸物流センター'}
# 購入ポイント情報(カテゴリ名の順番に設定
Point_Data = [0.02, 0.1, 0.03, 0.02, 0.05]
# 消費税率の設定
Tax_Data = 0.1
# 生成するデータの総数
Loop_Count = 10
# タイミング調整フラグ (0:待ち時間無し 1:1秒おき 2:ランダム)
Wait_Flag = 2
# 一定間隔の場合(システム時間で秒単位)
Sleep_Wait = 1
# ランダム間隔の場合(実態に合わせて調整)
# Base_Count = 1600000
Base_Count = 800000
# SQL情報をコンソールに表示するか否かの設定(1:表示する)
Display_SQL = 0
# 書き込み用のデータカラム
DL0 = "Order_ID, "
DL1 = "User, Zip, Prefecture, Address, Tel, Email, Point, Area"
DL2 = "Category, Product, Price, Units, Logistics"
DL3 = "User, Card, Number, Price, Units, Payment, Tax"
def Add2Pre(Address_Data):
# 都道府県情報の抽出
pattern = u"東京都|北海道|(?:京都|大阪)府|.{2,3}県"
m = re.match(pattern , Address_Data)
if m:
Prefecture_Name = m.group()
return(Prefecture_Name)
try:
print("テーブルへ連続挿入を開始")
# Fakerの初期化
from faker import Faker
fakegen = Faker('ja_JP')
Faker.seed(fakegen.random_digit())
# その他の変数
Counter = 0
Work_Count = 1
# MySQLとの接続
db = pymysql.connect(host = 'xxx.xxx.xxx.xxx',
port=3306,
user='xxxxxxxx',
password='zzzzzzzz',
db='xxxxxxxx',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
with db.cursor() as cursor:
# 検証データの生成
while Counter < Loop_Count:
# ランダムに書き込む商材の種類を選択
Category_ID = fakegen.random_digit()
if Category_ID > 4: Category_ID = Category_ID - 5
# カテゴリ名の設定
Category = Category_Name[Category_ID]
# 商品IDの設定
Product_ID = fakegen.random_digit()
# オーダーIDの情報作成
S_Counter = str(Counter)
O_Counter = S_Counter.zfill(8)
if Category_ID == 0:
Product = Product_Name0[Product_ID]
Price = Product_Price0[Product_ID]
Units = fakegen.random_digit() + 1
Point = Price * Units * Point_Data[Category_ID]
O_ID = "C00" + O_Counter
elif Category_ID == 1:
Product = Product_Name1[Product_ID]
Price = Product_Price1[Product_ID]
Units = 1
Point = Price * Units * Point_Data[Category_ID]
O_ID = "C01" + O_Counter
elif Category_ID == 2:
Product = Product_Name2[Product_ID]
Price = Product_Price2[Product_ID]
Units = fakegen.random_digit() + 1
if Units >3: Units = 3
Point = Price * Units * Point_Data[Category_ID]
O_ID = "C02" + O_Counter
elif Category_ID == 3:
Product = Product_Name3[Product_ID]
Price = Product_Price3[Product_ID]
Units = fakegen.random_digit() + 1
if Units >2: Units = 2
Point = Price * Units * Point_Data[Category_ID]
O_ID = "C03" + O_Counter
else:
Product = Product_Name4[Product_ID]
Price = Product_Price4[Product_ID]
Units = fakegen.random_digit() + 1
if Units >4: Units = 4
Point = Price * Units * Point_Data[Category_ID]
O_ID = "C04" + O_Counter
# 顧客名
User = fakegen.name()
# 支払い情報
if str(fakegen.pybool()) == "True":
Card = "現金"
else:
Card = fakegen.credit_card_provider()
Number = fakegen.credit_card_number()
if Card == "現金": Number = "N/A"
# 支払い総額と消費税
Payment = Price * Units
Tax = Payment * 0.1
# 顧客情報の設定
Zip = fakegen.zipcode()
Address = fakegen.address()
Prefecture = Add2Pre(Address)
Tel = fakegen.phone_number()
Email = fakegen.ascii_email()
# 地域名と物流センター名を取得
Area = Area_Data.get(Prefecture)
Logistics = Logi_Data.get(Area)
# 購入処理系は随時全て更新し、顧客管理のみ時々顧客登録のみを実施する
if str(fakegen.boolean(40)) == "True":
Point = 0 # 登録だけなのでポイントは無し
# 顧客登録のみのコードを設定
O_ID = "W99" + O_Counter
DV0 = O_ID + "','"
DV1 = User + "','" + Zip + "','" + Prefecture + "','" + Address + "','" + Tel + "','" + str(Email) + "','" + str(Point) + "','" + Area
SQL_Data1 = "INSERT INTO " + Table_Name1 + " (" + DL0 + DL1+ ") VALUES ('"+DV0 + DV1 + "')"
# 顧客登録のみを処理
cursor.execute(SQL_Data1)
db.commit()
# コンソールに生成データを表示
if Display_SQL == 1:
print (SQL_Data1)
else: # 通常の処理
# 挿入データ用SQLの準備
DV0 = O_ID + "','"
DV1 = User + "','" + Zip + "','" + Prefecture + "','" + Address + "','" + Tel + "','" + str(Email) + "','" + str(Point) + "','" + Area
DV2 = Category + "','" + Product + "','" + str(Price) + "','" + str(Units) + "','" + Logistics
DV3 = User + "','" + Card + "','" + Number + "','" + str(Price) + "','" + str(Units) + "','" + str(Payment) + "','" + str(Tax)
# SQLの作成
SQL_Data1 = "INSERT INTO " + Table_Name1 + " (" + DL0 + DL1+ ") VALUES ('"+DV0 + DV1 + "')"
SQL_Data2 = "INSERT INTO " + Table_Name2 + " (" + DL0 + DL2 + ") VALUES ('"+DV0 + DV2 + "')"
SQL_Data3 = "INSERT INTO " + Table_Name3 + " (" + DL0 + DL3 + ") VALUES ('"+DV0 + DV3 + "')"
# MySQLへ書き込む
cursor.execute(SQL_Data1)
db.commit()
cursor.execute(SQL_Data2)
db.commit()
cursor.execute(SQL_Data3)
db.commit()
# コンソールに生成データを表示
if Display_SQL == 1:
print (SQL_Data1)
print (SQL_Data2)
print (SQL_Data3)
# 生成間隔の調整
if Wait_Flag == 1:
time.sleep(Sleep_Wait)
elif Wait_Flag == 2:
Wait_Loop = Base_Count * fakegen.random_digit() + 1
for i in range(Wait_Loop): Work_Count = Work_Count + i
# ループカウンタの更新
Counter=Counter+1
# データの作成状況を表示
if (Counter % 10) == 0: print("途中経過: " + str(Counter) + " 個目のデータ作成を終了")
except KeyboardInterrupt:
print('!!!!! 割り込み発生 !!!!!')
finally:
# データベースコネクションを閉じる
db.close()
print("生成したデータの総数 : " + str(Counter))
print("テーブルへ連続挿入を終了")
取り敢えずのテストを実施・・・
では、取り急ぎのテストを実施してみます。今回は仮想環境上にCDC設定済みのMySQLを立ち上げて、その上にレプリケーション検証用のデータベースを作成し、その中に3個のテーブルを作成します。
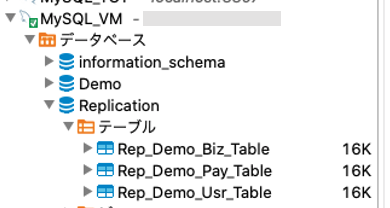
無事にテーブルが出来ましたので、今度は連続挿入の処理を走らせてみます。ここではランダム感覚で10個のデータを生成・挿入します。
「販売・物流系テーブル」

「決済系テーブル」

「顧客系テーブル」
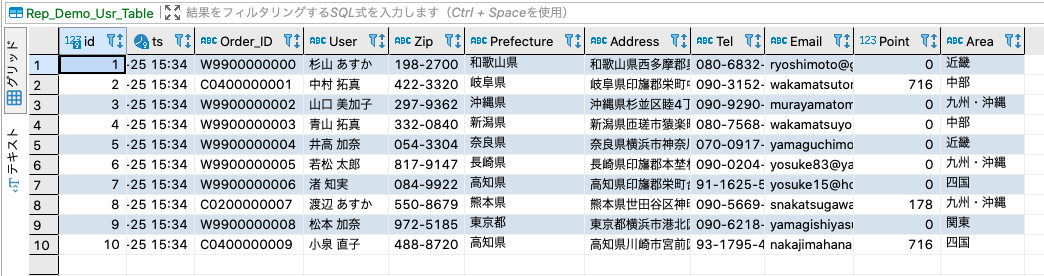
上手くデータが分類されて、3種類のテーブルが出来ている事が確認出来ました。
いよいよEqualumの登場!
この画面は、以前検証報告させて頂いたEqualumと「殆ど同じ」になりますが、今回のレプリケーション機能の対応拡大に伴い、2箇所大きな追加・変更が有ります。
まずは右上の部分

左側のメニューバー部分
になります。
レプリケーションの設定をしてみる。。。
まずは、左側のメニューバーからレプリケーションを選択します。
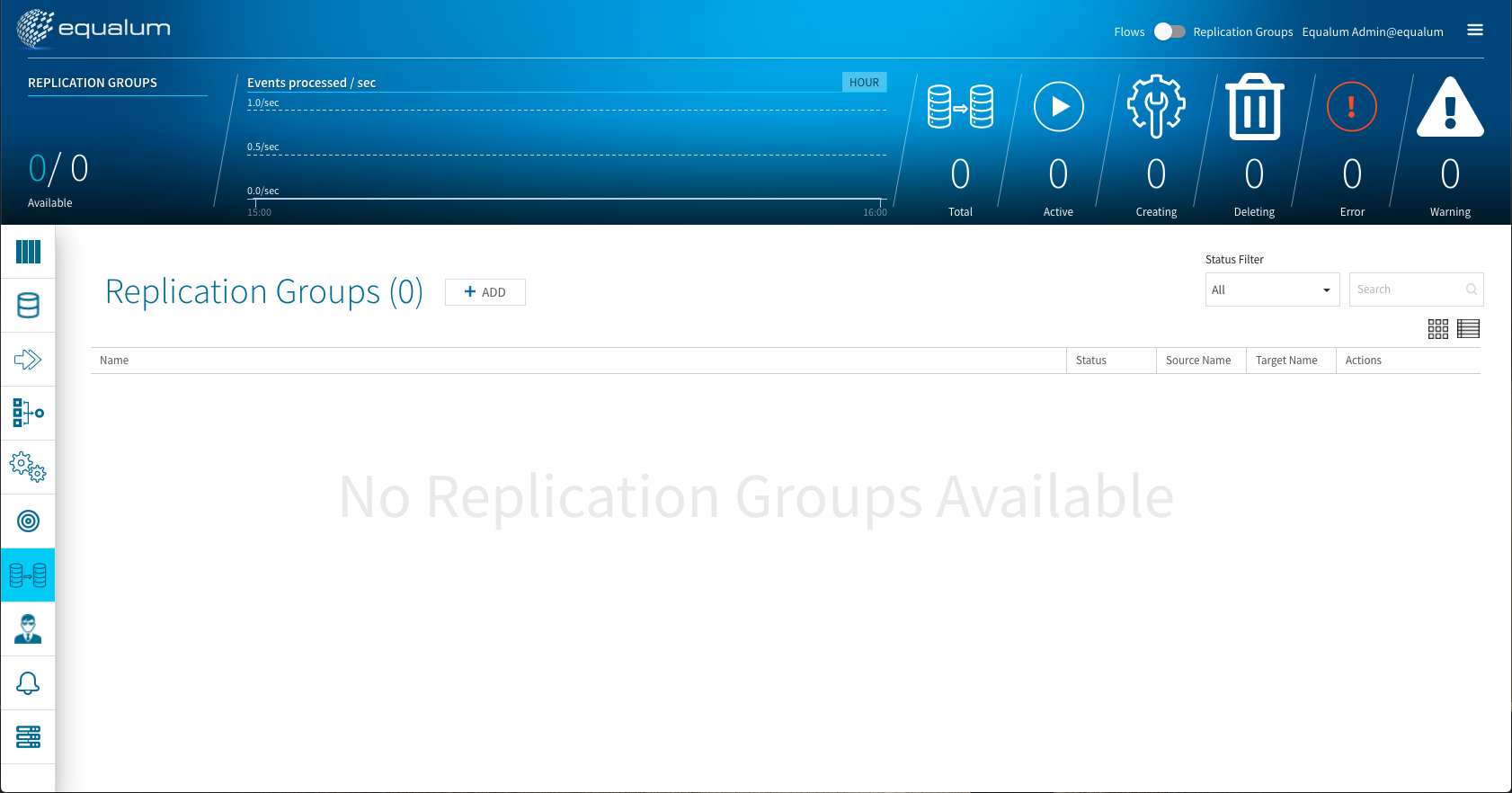
+ADDボタンを選択します。
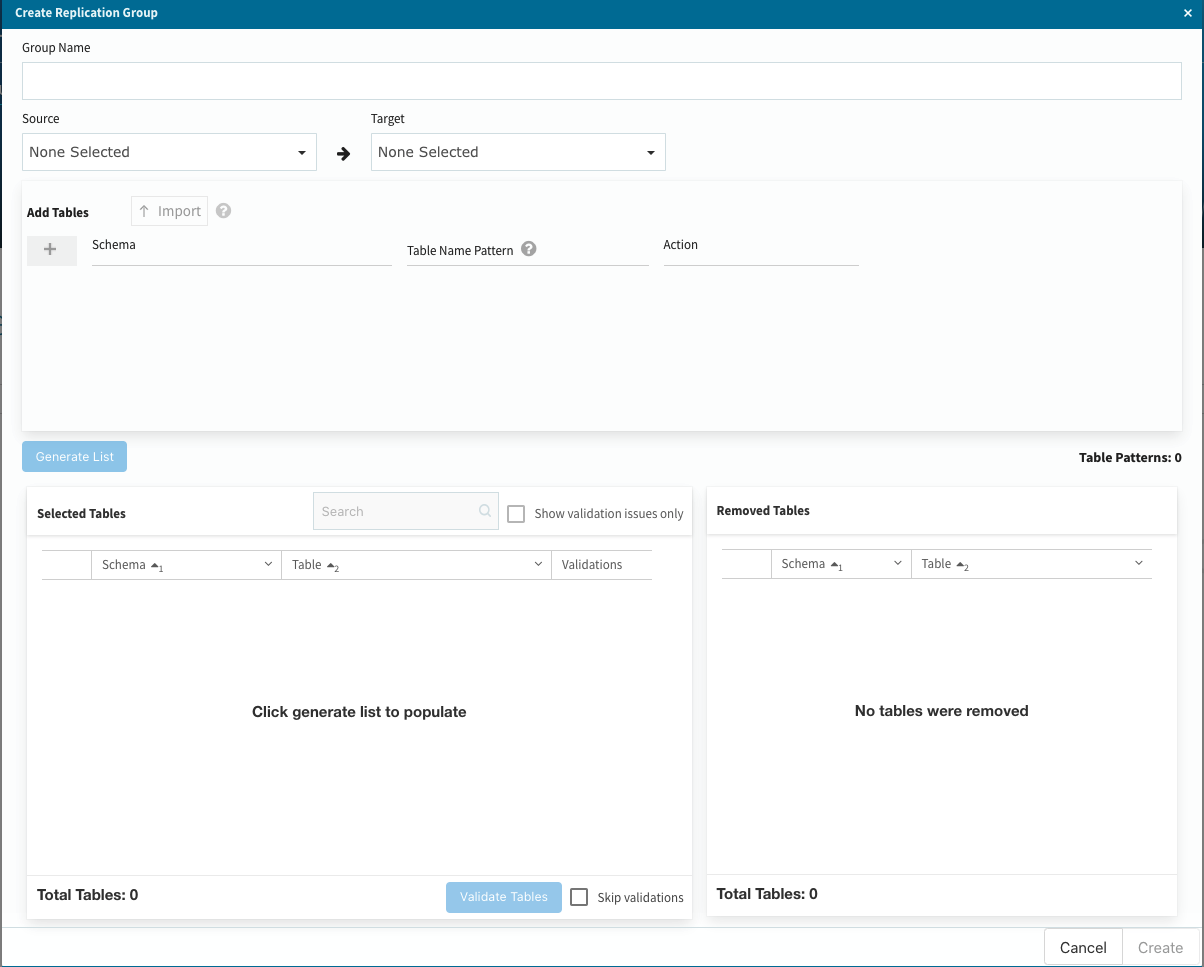
あとは、上から順番に必要項目を選択・設定していけば終了です。
(1)グループ名を設定してソースとターゲット、その他の項目を設定
(2)Add Tablesの下に**+ボタンが有るので選択します。

(3)必要項目を選択・入力します。今回はRepxxxxxという形でテーブル名を統一していますので、Rep%と設定しました。この部分は、その他の省略形式もサポートしていますので、関連するテーブルを一気に選択・設定する際に便利な機能になります。
(4)Generate Listボタンを選択すると、先程の条件に適合するテーブルが自動的に選択されますので、問題がなければValidate Tableを選択して接続確認します。
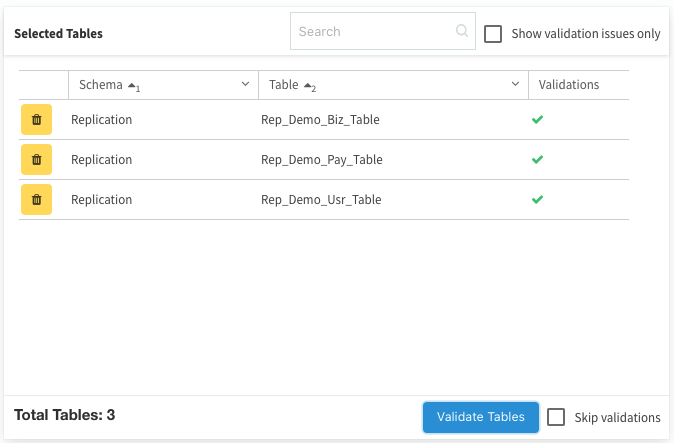
無事に整合性が取れていると判断された場合には、緑色のチェックマークが付きますのので、右下のCreate**ボタンを押して登録します。(万が一この様な警告が出た場合は、ターゲット側に同じ名前のテーブルが無いかどうかを確認してください。)
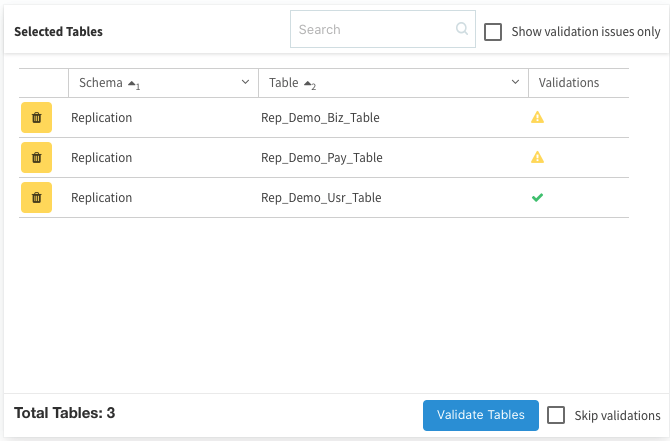
では検証開始!
無事に設定・登録が完了すると、管理画面にEqualumが自動生成したFLOWとして3個のストリーミング・レプリケーションが確認出来ます。
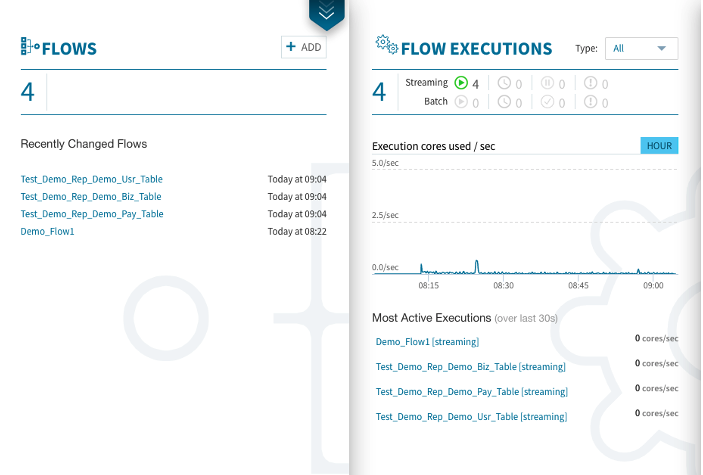
まずは、DBeaverを使ってスタートの状況を確認します。
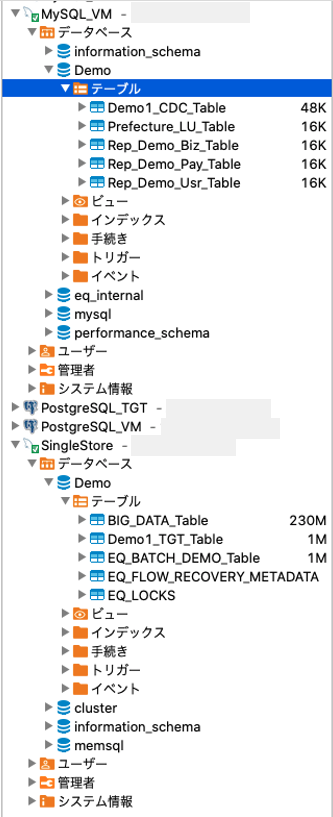
空っぽのテーブルが、先程のPythonスクリプトで作成され、この段階ではターゲットのSingleStore側には何も変化は有りませんが、先程の連続挿入スクリプトを走らせると、ターゲット側にテーブルが作られてデータがストリーミングでレプリケーションされます。
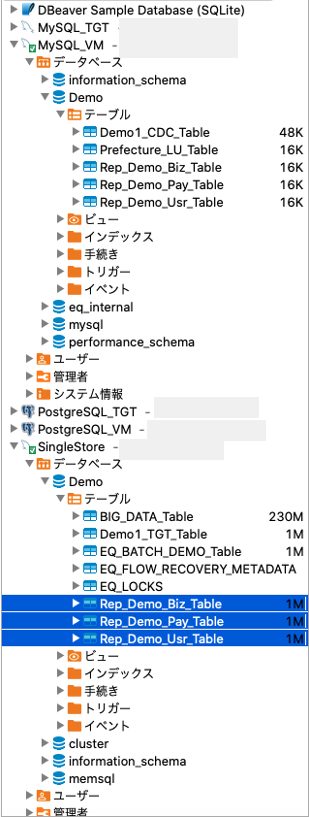
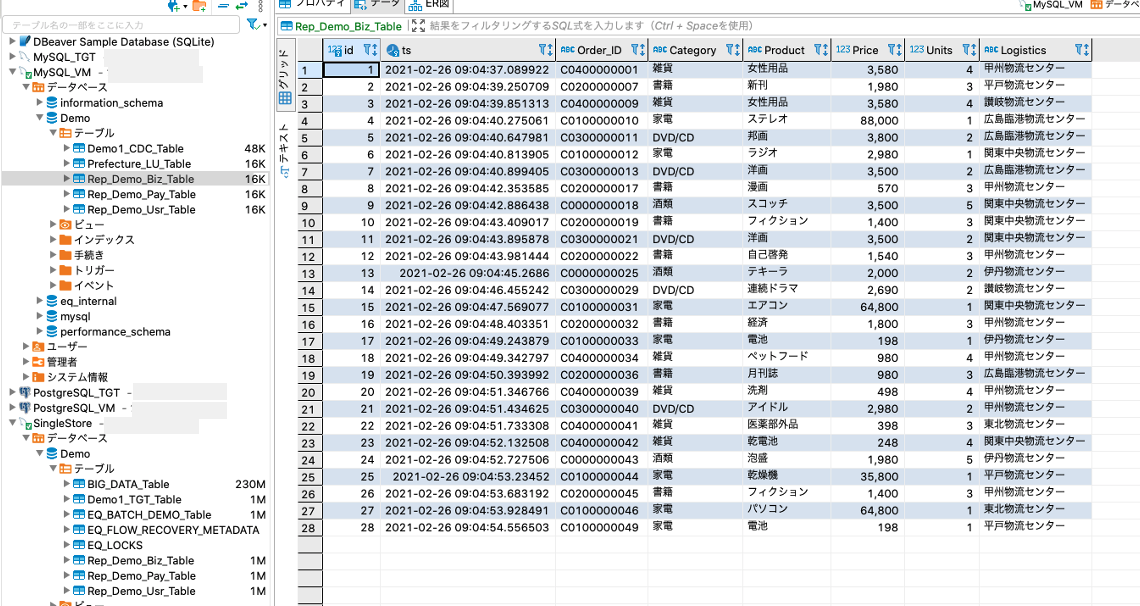
念の為に、DBeaverで確認してみます。
ソース側のテーブル
ターゲット側のテーブル
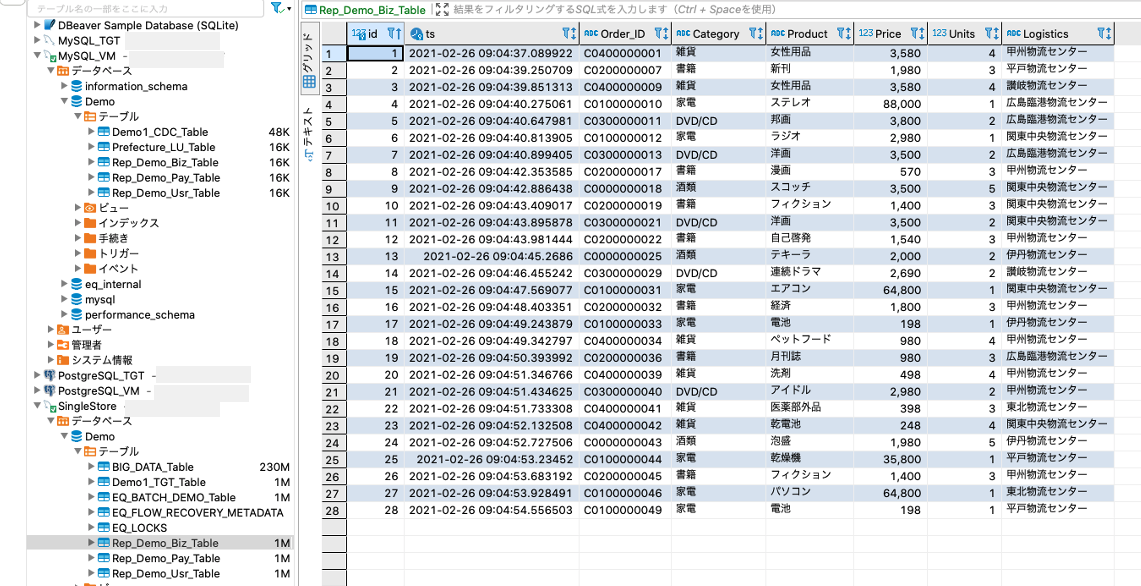
無事にレプリケーションが行われている様です。
今回のまとめ
今回は、Equalumのレプリケーション機能についての簡単な動作検証を行いました。以前の記事を読まれた方で”勘の良い方”はピン!ときたかもしれませんが、Equalumの場合途中のFLOW処理を入れなければ、基本的にはレプリケーションと同じ”様な”動作になります。もちろん、上流側のソースDBがCDCストリーミングをサポートしていれば、”ほぼ同じ”様な動作を手組みで作る事も可能なのですが、現実的なレプリケーション環境を考えると、命名規則に則ったテーブル名設定や、それらのリレーションを保持する為にテーブルをグループ化して管理しなければならない・・といった要求仕様が出てきます。
今回Oracle環境以外に横展開を始めたEqualumのレプリケーション環境では、出来るだけ利用者の負担を減らす方向で、レプリケーションに合わせた機能追加などを行い、通常メニューとして利用出来る様になりました。
また、冒頭にも書かせて頂いた通り、同じデータベース同志でなければレプリケーション出来ない!という仕様でも有りませんので、用途やコスト見合いで柔軟に構成を選択する事が可能です。
さて次回は・・・・
次回は、今回検証出来なかった、レプリカ側に対してPythonを使った簡単な即時可視化の仕掛けを入れて、利活用を意識した検証を行いたいと思います。もちろん、シンプルなBCP対応!という事であれば、今回の検証で十分ご検討頂けるかと思いますが、逆に「取り敢えず現場から全部持ってきて、それから考える!(ETL的処理は会議室で考える!系)というアプローチも否定できませんので、(この辺は、Equalumが稼働するサーバ・クラスターの構成にも関係しますが・・・)興味本意半分以上ではありますが、可視化ツールの作成から作業を行ってみたいと思います。
謝辞
本検証は、Equalum社の公式バージョン(V2.23)を利用して実施しています。
この貴重な機会を提供して頂いたEqualum社に対して感謝の意を表すると共に、本内容とEqualum社の公式ホームページで公開されている内容等が異なる場合は、Equalum社の情報が優先する事をご了解ください。